你已成功为应用程序集成人工智能能力,初期演示效果堪称卓越,JSON数据结构也精准返回。彼时,你满怀信心地将其部署至生产环境,甚至生出一种“技近乎道”的成就感。不过,现实的反馈却迅速打破了这份乐观——用户的投诉接踵而至:
“图表数据为空”
“时间线逻辑混乱”
“内容区域满是‘TBD’占位符”
这正是AI生成JSON在实际生产场景中的真实写照:其输出并非总能保持稳定可靠。相关研究数据也印证了这一结论:在多类任务测试中,大型语言模型生成有效JSON的成功率约为82%。这意味着,平均每5次请求中,就会出现1次应用程序无法直接使用的无效数据。
笔者主导开发了一款名为SlideMaker的AI演示文稿生成工具,该工具可自动生成包含图表、时间线、漏斗图在内的30余种内容类型的幻灯片。在累计完成5万余次生成任务、日均处理500-600次请求的实践基础上,我们精准定位了AI生成JSON的核心错误类型,并构建了一套可在用户感知前拦截问题的验证体系,将整体可靠性提升至95%以上。
问题本质:JSON模式≠模式合规性
第一需要厘清一个极具误导性的认知误区:当你在GPT-4、Gemini或Claude等模型中启用“JSON模式”时,其仅能保证输出内容的语法有效性——括号匹配、引号转义规范、可被解析器正常读取,仅此而已。
该模式完全无法保障以下核心要求:
-
业务所需的关键字段完整存在
-
字段值的数据类型严格匹配预期
-
枚举类字段的取值符合预设选项范围
-
数据逻辑与业务场景的一致性
这种“语法合规但逻辑失效”的问题,往往会对生产应用造成致命影响:JSON解析过程不会抛出任何错误,但前端接收到的对象缺失半数核心字段,最终导致功能异常,且问题排查难度极大。
AI JSON的四类典型错误
通过对数千次失败案例的深度分析,我们将AI JSON的错误归纳为以下四大类型:
1.字段缺失
当你明确要求返回标题、正文、图片关键词三个字段时,模型可能仅返回标题与正文。无语法错误,仅字段缺失,却会直接导致图片加载器崩溃。
2.类型错误
模式定义要求返回数值型数组 [10, 20, 30] ,模型却返回字符串类型数据 “10, 20, 30” 。数据格式符合JSON语法规范,但会造成图表渲染异常。
3.枚举值无效
若预设 chart_type 的取值范围为 bar (柱状图)、 line (折线图)、 pie (饼图),模型可能会自主生成 horizontal_bar (水平柱状图)这一未定义值,导致图表库无法识别。
4.语义逻辑错误
这是最隐蔽的一类错误:JSON结构完整、字段类型正确,但数据逻辑完全违背业务常识。
以下为生产环境中的真实案例——一个数值逆向递增的漏斗图:
{
“type”: “funnel”,
“stages”:
[{“label”: “Visitors”, “value”: 100},
{“label”: “Leads”, “value”: 250},
{“label”: “Customers”, “value”: 500}
]
}
该JSON在语法层面毫无瑕疵,但漏斗图的核心特征是数值逐层递减,此类语义错误完全超出了语法验证的覆盖范围。尽管模型具备漏斗图的概念认知,但在生成过程中往往无法严格遵循这一逻辑约束。
四层验证堆栈:构建95%可靠性的核心方案
第一层:全量字段校验——摒弃对模型的盲目信任
AI JSON的首要验证原则是:验证所有内容。切勿默认模型会严格遵循指令,必须逐一校验业务所需字段的存在性与非空性。
def validate_required_fields(slide, required_fields):
errors = []
for field in required_fields:
if field not in slide or not slide[field]:
errors.append(f”Missing required field: {field}”)
return errors
该逻辑看似简单,却是保障数据可用性的关键前提。
类型特异性(Type-Specific)验证
不同内容类型的幻灯片,其字段要求存在显著差异,需为各类内容定制专属验证规则:
VALIDATION_RULES = {
“chart”: {
“required_fields”: [“title”, “chart_type”, “chart_data”, “body”],
“min_data_points”: 3
},
“timeline”: {
“required_fields”: [“title”, “diagram_data”],
“min_events”: 4,
“max_events”: 6
},
“funnel”: {
“required_fields”: [“title”, “diagram_data”],
“min_stages”: 3,
“max_stages”: 5
}
}
然后创建一个验证器注册表:
VALIDATORS = { “chart”: ChartValidator,
“timeline”: TimelineValidator,
“funnel”: FunnelValidator,
“bullet_points”: BulletValidator,
}
def validate_slide(slide):
slide_type = slide.get(“type”, “bullet_points”)
validator = VALIDATORS.get(slide_type, DefaultValidator)()
return validator.validate(slide)
每个验证器均内置对应内容类型的专属校验逻辑,无需人工干预即可完成精准验证。
第二层:语义验证——拦截逻辑层面的隐形错误
多数验证系统止步于字段与类型校验,而这恰恰是生产级错误的主要藏身之处。即便字段完整、类型正确,仍需验证数据逻辑与业务场景的一致性。
以下为核心内容类型的语义验证规则及其必要性:
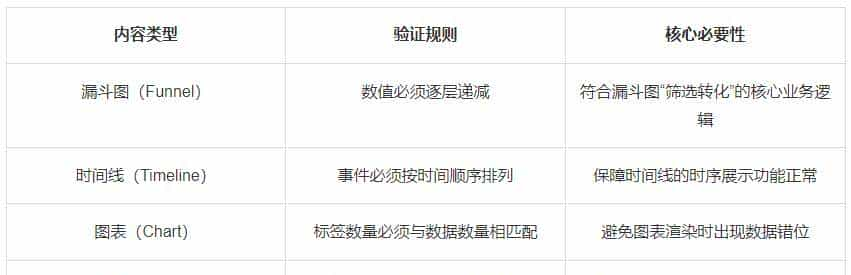
漏斗图语义验证示例
def validate_funnel(slide):
stages = slide.get(“diagram_data”, {}).get(“stages”, [])
# Check minimum stages
if len(stages) < 3:
return False, “Funnel requires at least 3 stages”
# Check values decrease (this is the semantic part)
values = [stage.get(“value”, 0) for stage in stages]
for i in range(1, len(values)):
if values[i] >= values[i-1]:
return False, “Funnel values must decrease at each stage”
# Check for flat funnels (all same value)
if len(set(values)) == 1:
return False, “All stages have identical values”
return True, None
时间线语义验证示例
def validate_timeline(slide):
events = slide.get(“diagram_data”, {}).get(“events”, [])
if len(events) < 4:
return False, “Timeline needs at least 4 events”
# Check chronological order
years = []
for event in events:
year_str = event.get(“year”, “”)
# Extract numeric year (handles “2020”, “Q1 2020”, “Jan 2020”)
year = extract_year(year_str)
if year:
years.append(year)
if years != sorted(years):
return False, “Timeline events must be in chronological order”
return True, None
此类校验能够精准识别“语法完美但逻辑失效”的问题,而这类问题是JSON模式完全无法覆盖的。
第三层:占位符内容校验——解决“懒惰模型”问题
部分场景下,模型会因“惰性”生成结构合规但无实际意义的占位符内容,例如:
{
“title”: “Key Benefits”,
“bullet_points”: [
{“title”: “Benefit 1”, “body”: “Details to be added…”},
{“title”: “Benefit 2”, “body”: “TBD”},
{“title”: “Benefit 3”, “body”: “…”}
]
}
禁用内容列表
FORBIDDEN_CONTENT = [
“tbd”,
“todo”,
“placeholder”,
“…”,
“xxx”,
“fill in”,
“to be determined”,
“coming soon”,
“insert here”,
“details about”,
“information about”,
“content about”,
“lorem ipsum”
]
def check_forbidden_content(text):
text_lower = text.lower()
for forbidden in FORBIDDEN_CONTENT:
if forbidden in text_lower:
return False, f”Contains placeholder content: '{forbidden}'”
return True, None
扫描所有文本字段
需对标题、正文、项目符号等所有文本字段进行全面校验,避免遗漏:
Def validate_content_quality(slide):
errors = []
# Check title
title = slide.get(“title”, “”)
valid, error = check_forbidden_content(title)
if not valid:
errors.append(f”Title: {error}”)
# Check body
body = slide.get(“body”, “”)
if body:
valid, error = check_forbidden_content(body)
if not valid:
errors.append(f”Body: {error}”)
# Check bullet points
for i, bullet in enumerate(slide.get(“bullet_points”, [])):
bullet_body = bullet.get(“body”, “”)
valid, error = check_forbidden_content(bullet_body)
if not valid:
errors.append(f”Bullet {i+1}: {error}”)
return len(errors) == 0, errors
第四层:智能重试循环——基于错误上下文的精准修正
重试机制的核心误区在于:使用一样提示词重复请求,往往会得到一样的错误结果。模型产生错误的根源在于提示词未能清晰传递约束条件,或模型在生成过程中偏离了核心需求,盲目重试无法解决本质问题。
错误上下文注入策略
当验证失败时,需将具体错误信息精准注入重试提示词,引导模型针对性修正:
def generate_with_retry(prompt, max_retries=2):
for attempt in range(max_retries + 1):
response = call_llm(prompt)
try:
data = json.loads(response)
is_valid, errors = validate_slide(data)
if is_valid:
return data
# Build retry prompt with specific errors
if attempt < max_retries:
error_context = ”
“.join(f”- {e}” for e in errors)
prompt = f”””
Previous attempt failed validation:
{error_context}
Please fix these specific issues and regenerate.
Original request:{prompt}”””
except json.JSONDecodeError as e:
if attempt < max_retries:
prompt = f”””
Previous response was not valid JSON.Error: {str(e)}
Please return ONLY valid JSON with no markdown or extra text.
Original request:{prompt}”””
# All retries exhausted
return None
该策略的核心优势在于,重试提示词包含三项关键信息:具体的验证错误列表、明确的修正指令、原始的业务请求内容,可将首次生成成功率从85%左右提升至重试后的95%以上。
重试预算与优雅降级机制
需为重试机制设置明确的次数上限,避免无限循环:
MAX_RETRIES = 2 # 总计尝试3次
def should_retry(attempt, error_type):
if attempt >= MAX_RETRIES:
return False
# Some errors aren't worth retrying
if error_type == “rate_limit”:
return True # Wait and retry
if error_type == “context_too_long”:
return False # Need to reduce input, not retry
return True
当所有重试均失败时,需执行优雅降级策略:
-
切换为更简单的输出类型
-
返回部分有效结果并附带错误提示
-
记录失败案例供人工审核优化
重试机制并非简单的错误处理手段,而是整个AI生成流程的核心组成部分。
附加策略:约束家族——解决输出同质化问题
部分问题无法通过常规验证机制解决,例如输出内容同质化:当要求生成10页幻灯片时,模型可能返回5页结构类似的对比类幻灯片。尽管每页JSON均通过验证,但整体内容缺乏多样性,用户体验较差。
约束家族配置
将功能类似的内容类型归为同一“家族”,限制每个家族在单次生成任务中仅能出现一种类型:
CONSTRAINT_FAMILIES = {
“comparison”: [“comparison_split”, “before_after”,”pros_cons”],
“highlight”: [“big_number”, “stat_highlight”, “quote”],
“steps”: [“numbered_steps”, “process_flow”],
“data”: [“chart”, “table”]}
def check_family_constraints(slides):
used_families = {}
for slide in slides:
slide_type = slide.get(“type”)
for family, types in CONSTRAINT_FAMILIES.items():
if slide_type in types:
if family in used_families:
return False, f”Multiple {family} types: {used_families[family]} and {slide_type}”
used_families[family] = slide_type
return True, None
该策略可在无需人工干预的前提下,保障输出内容的多样性。
完整验证流程整合
以下为整合四层验证逻辑的核心函数:
def validate_ai_output(slide, verbosity=”balanced”):
“””
Complete validation pipeline for AI-generated JSON.
Returns (is_valid, error_list)
“””
errors = []
# Layer 1: Required fields
slide_type = slide.get(“type”, “unknown”)
rules = VALIDATION_RULES.get(slide_type, {})
for field in rules.get(“required_fields”, []):
if field not in slide or not slide[field]:
errors.append(f”Missing: {field}”)
# Layer 2: Type-specific semantic validation
validator = VALIDATORS.get(slide_type)
if validator:
valid, semantic_errors = validator().validate(slide)
if not valid:
errors.extend(semantic_errors)
# Layer 3: Content quality (forbidden patterns)
valid, quality_errors = validate_content_quality(slide)
if not valid:
errors.extend(quality_errors)
return len(errors) == 0, errors
生产环境调用流程
def generate_slide(topic, slide_type):
prompt = build_prompt(topic, slide_type)
result = generate_with_retry(prompt, max_retries=2)
if result is None:
# Log failure, use fallback
log_generation_failure(topic, slide_type)
return create_fallback_slide(topic)
return result
思维模式转变:验证是产品的核心组成部分
需明确一个核心认知:验证并非事后的错误处理手段,而是产品功能的核心组成部分。
大型语言模型本质上是一个概率性生成系统,错误输出是其固有特性。验证层的核心价值,在于将模型输出的“概率性混乱”转化为“确定性可靠输出”。JSON模式仅仅是验证流程的起点,而非终点。
在SlideMaker的实践中,经过5万余次生成任务的迭代优化,我们实现了以下核心指标:
-
首次生成成功率:85%-90%
-
智能重试后成功率:≥95%
-
用户可见故障发生率:<2%
这正是演示原型与成熟产品之间的本质区别。
生产部署必备:验证清单
在将AI生成JSON部署至生产环境前,请务必完成以下验证配置:
-
为每类输出类型配置独立的必填字段校验规则
-
开发具备语义校验能力的类型化验证器
-
构建占位符内容扫描机制,覆盖所有文本字段
-
实现基于错误上下文注入的智能重试逻辑
-
设定合理的重试预算,避免无限循环
-
设计重试失败后的优雅降级方案
-
配置约束家族策略,保障输出内容多样性
核心原则:永远不要轻信模型的输出,必须通过系统化验证确保数据有效性。
如果你正致力于基于AI生成结构化数据构建应用,我十分期待了解你在验证环节遇到的独特挑战与解决方案。
原文标题:Why Your AI JSON Always Breaks (And How to Fix It),作者:Gourav
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...