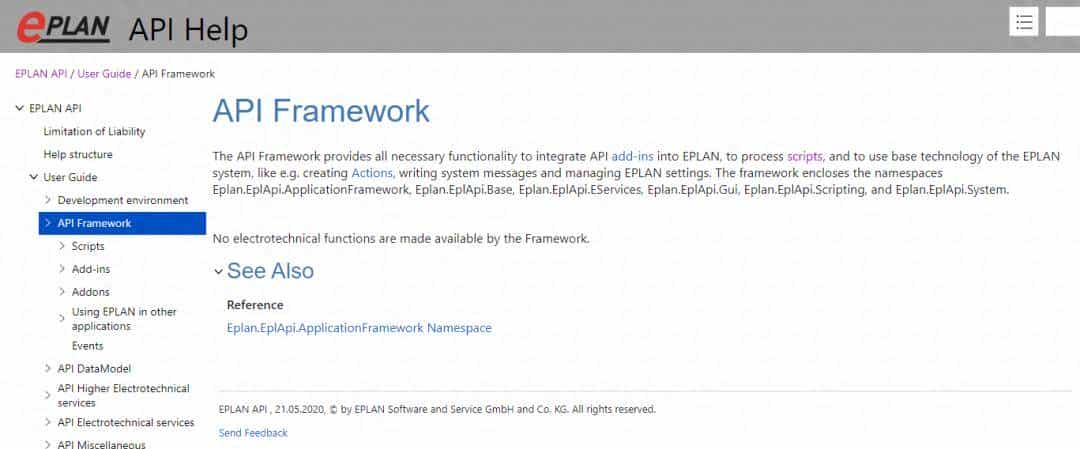
在基于 RAG(检索增强生成)的大语言模型应用中,文本分块是至关重大的预处理步骤。虽然固定大小、递归、语义、基于文档和智能体分块等基础策略已被广泛应用,但一些高级技术可以显著提升检索精度、上下文保留能力和特定任务的性能表现。
本文将通过真实案例、实现要点和可视化图解,全面解析 9 种高级文本分块策略,协助你根据具体场景选择最适合的方案。
学完记得来 EasyQZ 测试一下你的掌握程度哦!
1. 滑动窗口分块(Sliding Window Chunking)
适用领域:医疗病历
核心概念:通过以指定的重叠量在文本上移动固定大小的窗口,创建重叠的文本块,确保块边界之间的上下文连续性。
工作原理:
- 定义窗口大小(如 500 词)
- 定义重叠大小(如 100 词)
- 在文档上滑动窗口,创建共享内容的文本块
案例:
一份 10,000 词的病历采用 500 词窗口 + 100 词重叠进行分块:
- 块 1:第 1-500 词(患者 1 月 5 日因急性呼吸窘迫入院… 生命体征:血压 140/90,心率 88,病情稳定…)
- 块 2:第 401-900 词(… 生命体征:血压 140/90,心率 88,病情稳定…[重叠部分] 开始采用皮质类固醇治疗方案…)
- 块 3:第 801-1300 词(… 开始采用皮质类固醇治疗方案…[重叠部分] 患者血氧饱和度改善…)
应用场景:超级适合总结或提取患者纵向病史,避免跨章节丢失上下文。重叠部分确保在块边界提及的病情、药物和治疗方案保持上下文关联,在跟踪患者病情进展时防止信息丢失。
实现提议:根据上下文重大性调整重叠比例 —— 密集的病历采用 20% 重叠率,普通文档采用 10%。
2. 自适应分块(Adaptive Chunking)
适用领域:法律合同
核心概念:创建大小可变的文本块,在遵守 token 限制的同时尊重文档的自然边界,而非强制严格的大小限制,能够适应内容结构。
工作原理:
- 设置目标 token 范围(如 800-1200 tokens)
- 识别自然断点(条款、章节、段落)
- 创建最大化 token 使用量且不分割逻辑单元的文本块
案例:
包含多个章节的法律合同:
- 第 3 章:付款条款(1,150 tokens)3.1 客户应向承包商支付…(380 tokens)3.2 逾期付款将产生罚款…(290 tokens)3.3 所有付款不可退还…(250 tokens)3.4 付款争议应通过… 解决(230 tokens)
→ 整个第 3 章作为一个完整文本块(1,150 tokens),而非在条款中间分割。
应用场景:在保持条款完整性的同时最大化 LLM 上下文窗口利用率。防止法律条款被分割到多个文本块中,避免在合同分析、合规检查或问答任务中产生误解,对维护法律准确性至关重大。
实现提议:使用 AST 解析或正则表达式模式检测章节边界(如 “SECTION X:”、编号条款)。
3. 基于实体的分块(Entity-Based Chunking)
适用领域:新闻档案
核心概念:根据句子提及的实体对句子进行分组,创建以实体为中心的文本块,而非顺序文本块。
工作原理:
- 对文档执行命名实体识别(NER)
- 分组提及一样实体的句子
- 为每个主要实体创建单独的文本块
案例:
一篇科技行业新闻文章:
原文:
[1] 埃隆・马斯克昨日宣布了一项新的 AI 计划。
[2] 特斯拉在活动中发布了 Model Y 改款车型。
[3] SpaceX 成功发射了星舰试飞任务。
[4] 这位亿万富翁表达了对 AI 安全的担忧。
[5] 马斯克的公司持续创新。
[6] SpaceX 工程师报告创纪录的性能表现。
基于实体的分块结果:
- 块 1(埃隆・马斯克):整合句子 1、4、5
- 块 2(SpaceX):整合句子 3、6
- 块 3(特斯拉):句子 2 单独成块
应用场景:完美适用于以实体为中心的知识库或 AI 驱动的查询检索。当用户询问 “埃隆・马斯克本周做了什么?” 时,所有相关提及已预先分组,便于高效检索和生成响应,显著提升针对实体查询的检索精度。
实现提议:使用 spaCy 或 Hugging Face 的 NER 模型,思考使用共指消解处理代词(如 “他”→”埃隆・马斯克”)。
4. 基于主题的分块(Topic/Theme-Based Chunking)
适用领域:研究论文
核心概念:利用语义类似度和聚类算法,将段落按潜在主题分组,即使它们在原始文档中不连续。
工作原理:
- 为每个段落 / 章节生成嵌入向量
- 应用聚类算法(K-means、HDBSCAN)对类似内容分组
- 从语义相关的段落创建文本块
案例:
一篇包含 50 个段落的研究论文:
原始顺序:
段落 1:神经网络介绍
段落 2:数据集描述
段落 3:强化学习背景
段落 4:NLP 预处理步骤
段落 5:神经网络架构细节
…
基于主题的分块结果:
- 主题 1 – 神经网络:整合段落 1、5、11、18、25、33、41
- 主题 2 – 强化学习:整合段落 3、7、12、19、27、35、43
- 主题 3 – NLP 方法:整合段落 4、8、13、20、28、36、44
应用场景:支持基于主题的总结和检索。用户可以查询 “告知我这篇论文中的 NLP 方法”,获取所有相关内容的整合结果,即使这些内容分散在文档各处。超级适合文献综述、研究综合和定向信息提取。
实现提议:使用 sentence-transformers 生成嵌入向量,尝试不同的聚类算法(已知主题数量时用 K-means,自动检测时用 HDBSCAN)。
5. 混合分块(Hybrid Chunking)
适用领域:软件文档
核心概念:在流水线中组合多种策略,利用每种方法的优势。
工作原理:
- 依次应用多种分块策略
- 每种策略优化前一种策略的输出
- 常见组合:递归 + 语义 + 基于实体
案例:
API 文档处理:
步骤 1 – 递归分割:按标题(##)和段落分隔符(
)分割
步骤 2 – 语义分组:在每个章节内分组相关指令
步骤 3 – 实体保留:确保函数 / 类名不被分割
应用场景:为 AI 助手提供准确的代码相关答案。结合结构感知(段落)、语义关系(相关概念)和实体保留(函数名),提供全面上下文,生成既技术准确又语义连贯的文本块。
实现提议:顺序很重大!一般顺序为:结构→语义→实体。针对你的领域测试不同组合。
6. 任务感知分块(Task-Aware Chunking)
适用领域:代码分析和问答系统
核心概念:根据 LLM 将要执行的下游任务调整分块策略。
工作原理:
- 定义目标任务(总结、搜索、问答)
- 应用特定于任务的分块规则
- 一样内容,针对不同任务生成不同的文本块
案例:
一个包含 1000 行代码的 Python 代码库:
- 任务:总结 → 策略:小而有意义的块,每个函数 20-30 行
- 任务:搜索 / 检索 → 策略:描述的语义类似度,块大小为函数签名 + 文档字符串
- 任务:问答 → 策略:模块 / 类边界,块大小为 100-200 行(整个类)
应用场景:针对下游 LLM 任务定制分块。摒弃 “一刀切” 的策略,根据是对代码进行总结、搜索还是问答来调整分块策略,显著提升特定任务的性能指标。
实现提议:创建包含特定任务参数的分块配置文件,思考为同一语料库针对不同用途建立索引时使用不同策略。
7. HTML/XML 标签分割(HTML/XML Tag-Based Splitting)
适用领域:Web 内容和抓取的文档
核心概念:利用 HTML/XML 结构确定分块边界,尊重文档的层次组织。
工作原理:
- 将 HTML/XML 解析为 DOM 树
- 定义分割标签(如<h2>、<section>、<div>)
- 提取每个结构边界内的内容
案例:
博客文章 HTML:
html
预览
<article>
<h1>机器学习完全指南</h1>
<h2>引言</h2>
<p>机器学习彻底改变了...</p>
<p>本指南涵盖基本概念...</p>
<h2>监督学习</h2>
<p>监督学习算法...</p>
<div class="example">
<h3>示例:线性回归</h3>
<p>线性回归预测...</p>
</div>
</article>
分块结果:
- 块 1:引言部分
- 块 2:监督学习部分
- 块 3:无监督学习部分
应用场景:超级适合将结构化 Web 内容输入 LLM 进行总结、问答或内容提取。通过尊重 HTML 层次结构保留网页的逻辑结构,确保章节完整且上下文连贯。
实现提议:使用 BeautifulSoup 或 lxml 进行解析,思考嵌套标签 ——<h3>应创建子块还是与<h2>父块保持在一起?
8. 代码特定分割(Code-Specific Splitting)
适用领域:软件开发
核心概念:使用抽象语法树(AST)解析或特定于语言的模式,在逻辑边界(如函数、类或模块)处分割代码。
工作原理:
- 将代码解析为 AST(抽象语法树)
- 识别代码单元(类、函数、方法)
- 在这些自然边界处创建文本块
案例:
一个 500 行的 Python 文件:
- 类 UserManager(第 1-45 行)→ 块 1
- 类 DataProcessor(第 47-120 行)→ 块 2
- 函数 main ()(第 122-180 行)→ 块 3
- 函数 helper_function ()(第 182-200 行)→ 块 4
应用场景:对代码总结、自动文档生成或 LLM 辅助代码审查至关重大。每个块都是完整、语义明确的代码单元,可以独立分析。防止在类或函数实现过程中分割,避免丢失关键上下文。
实现提议:使用特定于语言的解析器:Python 使用 ast 模块,多语言支持使用 Tree-sitter,简单情况使用正则表达式。
9. 正则表达式分割(Regular Expression Splitting)
适用领域:日志分析
核心概念:使用模式匹配基于可预测的文本模式(如时间戳、分隔符或标记)识别分块边界。
工作原理:
- 定义边界的正则表达式模式
- 每当匹配到模式时分割文本
- 每个块以匹配的模式开头
案例:
包含 10,000 条记录的服务器日志文件:
原始日志:
plaintext
[2025-01-15 10:23:45] INFO: 用户john@example.com登录成功
[2025-01-15 10:24:12] ERROR: 数据库连接失败 - 30秒后超时
[2025-01-15 10:24:15] INFO: 正在重试数据库连接...
正则表达式模式:(d{4}-d{2}-d{2} d{2}:d{2}:d{2})
分块结果:每个日志条目作为独立文本块。
应用场景:将结构化日志块输入 LLM 进行异常检测、故障排除或日志总结。每个条目包含时间戳和上下文,便于按时间顺序跟踪问题。可以通过按时间窗口或严重程度分组进行增强。
实现提议:常见模式:
- 时间戳:(d{4}-d{2}-d{2}.*?) 或 d {4}/d {2}/d {2}
- 章节标记:^={3,} 或 ^-{3,}
- 自定义分隔符:^### 或 ^***
快速选择指南
根据需求选择合适的策略:
- 需要跨边界保留上下文?→ 滑动窗口
- 处理法律文档?→ 自适应分块
- 构建知识库?→ 基于实体或主题
- 处理源代码?→ 代码特定或混合
- 同一内容有多种用途?→ 任务感知分块
- 结构化数据(HTML / 日志)?→ HTML/XML 或正则表达式
- 复杂技术文档?→ 混合(递归 + 语义 + 实体)
实现最佳实践
- 从简单开始:先使用基础策略,根据需要增加复杂度
- 衡量性能:跟踪检索精度、响应质量指标
- 思考成本:复杂策略(实体、主题)需要更多计算资源
- 测试块大小:针对你的 LLM 上下文窗口尝试不同大小
- 验证边界:手动审查样本块确保质量
- 版本控制:跟踪分块策略变更及其影响
- 监控漂移:内容类型变化时,定期重新评估
总结
高级分块策略超越了简单的文本分割,创建了上下文感知、任务优化和结构合理的文本块。通过理解这 9 种技术及其适用场景,你可以显著提升 LLM 应用的性能、检索精度和用户体验。
关键在于将分块策略与你的特定领域、内容类型和下游任务相匹配。不要犹豫,尝试组合多种方法(混合分块)或创建定制策略,以满足你的独特需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...