一、项目核心:全栈AI研究助手的工业化蓝图

Google开源的
gemini-fullstack-langgraph-quickstart 并非普通Demo,而是一个可直接复用的生产级Agent框架。它用React前端+LangGraph后端构建了一个动态研究助手,其核心创新在于:
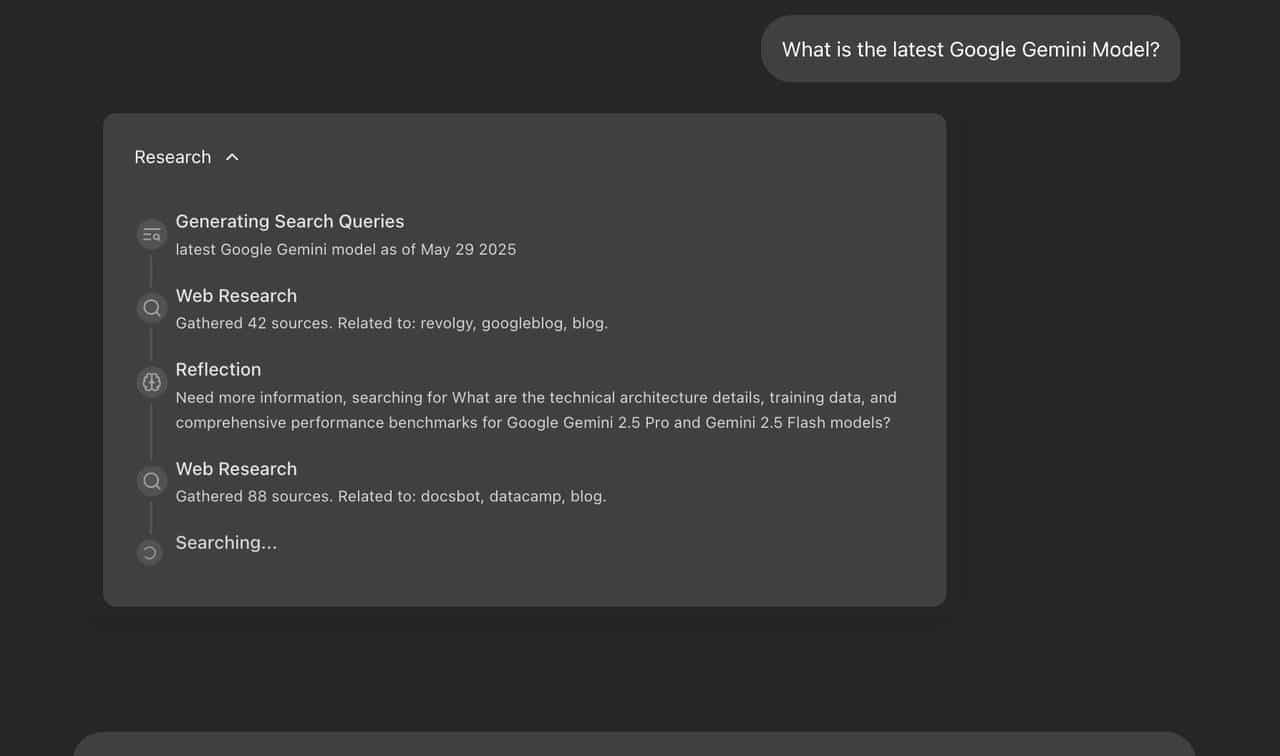
- 动态搜索词生成:Gemini 2.5分析用户问题后,自动生成多角度搜索查询(如问“可再生能源趋势”会拆解为太阳能技术、储能突破等子查询);
- 反思型工作流:通过LangGraph的循环机制,AI会判断信息缺口并迭代优化搜索策略,模拟人类研究员的思考逻辑;
- 引用可追溯:所有结论均附带来源链接,支持学术级可信度验证;
- 开箱即用架构:前端用Vite+React热更新,后端FastAPI+LangGraph,Docker Compose一键部署
技术颠覆点:传统Agent开发需从零搭建流程编排,而该项目直接提供了模块化流水线,开发者只需替换组件(如搜索API/反思策略)即可定制垂直领域助手。
二、LangGraph如何重构Agent开发范式
▍ 解决传统Agent的两大痛点
- 黑盒决策 → 可视化流程
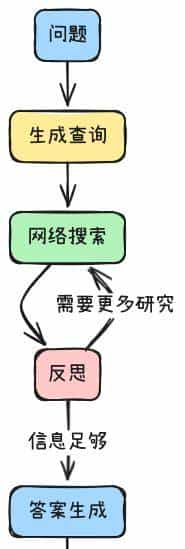
LangGraph将Agent拆解为节点(Node)和条件边(Edge),例如:
- 生成查询 → 执行搜索 → 反思知识缺口? → 是则循环,否则生成答案
- 开发者可直接调试每个节点状态,告别“为什么AI这么做”的困惑
- 无状态碎片化 → 持久化记忆
内置Redis存储对话历史、Postgres管理任务队列,支持任务暂停/恢复/人工干预,这对企业级长周期任务(如竞品分析报告)至关重大。
▍ 性能优化实践
- 流式响应:前端实时显示AI“思考过程”,避免用户等待焦虑;
- 搜索强度分级:通过配置max_round参数平衡深度与效率(低:3轮, 高:10轮);
- 异步工具调用:并行执行多个搜索任务,提速50%+。
三、手把手实战:构建行业研究助手
▍ 三步定制化(以金融分析为例)
python
# 步骤1:替换搜索源(增加财经数据库)
# 修改 backend/agent/research.py 中的 search_tool
from langchain_community.tools import BraveSearch
tools.append(BraveSearch(api_key="YOUR_KEY"))
# 步骤2:强化反思逻辑
# 在 agent/research.py 的 _should_continue() 中增加:
if "financial risk" in state["query"]:
return "generate_queries" # 强制多轮迭代
# 步骤3:自定义输出格式
# 修改 frontend/src/components/AnswerDisplay.jsx
const formatAnswer = (data) => (
<div>
<h3>行业评级:{data.rating}</h3>
<Chart data={data.trends} />
</div>
);▍ 部署到生产环境
bash
# 1. 配置环境变量
echo "GEMINI_API_KEY=your_key" >> .env
# 2. 启动Docker集群(自动挂载Postgres+Redis)
docker-compose up --build
# 3. 访问前端
open http://localhost:5173/app⚠️ 避坑指南:
若需处理PDF/PPT等文件,可集成Unstructured提取文本;高并发场景需用Celery替代LangGraph内置任务队列。
四、对AI应用开发的深远影响
- Agent开发平民化:
过去需数月搭建的科研Agent,现可1天完成原型,中小企业也能部署AI研究员; - 技术栈标准化:
LangGraph成为Agent编排层实际标准,开发者不再重复造轮子; - 动态信息革命:
传统RAG依赖静态知识库,而实时搜索+反思机制让AI拥有“主动学习”能力。
开发者寄语:
与其焦虑AGI何时到来,不如用这套框架解决今天的实际问题——列如自动撰写竞品报告、学术文献综述,甚至帮你分析下周该买哪只股票。
感谢关【AI码力】, 准备规划一个Langchain,LangGraph专题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...