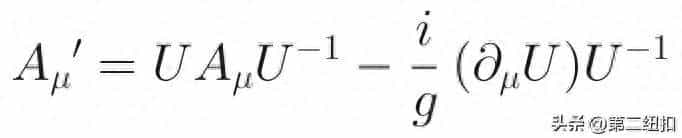当归
接下来的日子也是一如既往的累,数不尽的课程、报告、论文一度让沈惜凡的情绪低到了极点,她早就被告知康奈尔是“剥夺四年睡眠时间的大学”,但是真正体验那种痛苦的滋味只有自己知道。
一月的天气忽然变冷,阴风嗖嗖的刮的厉害,原本人来人往、热闹喧嚣的学校,忽然变得安静异常,仿佛和这样的天气相互映衬似的,她整个人也变得阴郁、忧愁。
还有两天就是中国的农历新年,但是在大洋彼岸的纽约小镇却没有任何过节的气氛,没有红灯笼,没有鞭炮,没有来来往往采购年货的人群,没有饺子、汤圆。
没有家人,没有祝福,也没有他的陪伴,度日如年。
伊萨卡的天空泛着青灰色,涩涩的,有着下雪的预兆却没有出现 片雪花,沉沉的挤压在她心头上。这样的天,真的是很孤单、寂寞。
这样的天,只适合沉沉的睡去,而不是在教室里team work讨论枯燥的策划方案。
她不由锁起了眉头,忽然一个声音传了进来,“Serena,对这个策划你有什么见解?”
脑袋中有一瞬间的空白,思绪被拉回到了面前的资料上,她整理了一下思绪,缓缓开口,从国际连锁酒店文化到管理,最后又补充了一些中国酒店管理的理念。
团队负责人想了一会,点点头,“说的不错,不过一般很少看到你发言。刚才你提到的酒店文化,有几个点很不错,这样吧,下次的discussion 你做group leader,可以不?”
望着组员们期许的目光,她尴尬的笑笑,应承下来。
星期五还有一门考试,下周要开始新的课程准备,Career Tracks的论文还没有完成,目前又添了一个lead discussion,简直是雪上加霜。
结束了小组会议,劳累的身体和浮躁的情绪让她有些崩溃。
回到宿舍后,给自己泡了一杯茶,呆呆的坐在窗口,桌上摊着大堆的参考资料,却不知道从何下手,顺手打开电脑,MSN、QQ上祝福不断,以前的同事、好友纷纷发着美丽的图片,温馨或搞笑的新年祝福语布满了屏幕。
原来今天是除夕夜。
可是却没有收到何苏叶的祝福,也许他目前还在研究所,也许晚上也不会回去的。他早就告知她课题进入关键,也许没有那么多时间陪她,请她谅解,那时候她虽然有些小小的失落,但是依然告知他让他放心,由于研究工作最重大。
她打电话回家,耳边是惊雷的鞭炮声,沈妈妈扯着嗓子喊,“凡凡,妈妈、爸爸好想你的,你爸这几天一直念叨你没完,你外公他们问你什么时候回来。”
她听了鼻子一酸,连忙答应,“还有半年就回来了,很快的。”
沈妈妈叹气,“算了不说了,大过年的,凡凡,今天晚上记得要吃饺子,你们那不会连这个都没有吧,汤圆呢?对了,你们那能收到春晚么?”
当然不能说这里什么都没有,沈惜凡连忙点头,“好、好,都有,妈你放心吧,我会吃的好好的!春晚也有,网上在线直播。帮我跟外公他们拜年,恩,就这样,挂了呀!”
放下电话,脑中尽是过年的图画,她记得去年除夕夜,喝多了莫名其妙的跟何苏叶说了自己都无法考证的话,那时候一家人团团圆圆、热热闹闹,多幸福。
忽然室友喊她,“Serena,有你的快递,刚才我忘了告知你,在厨房的桌上。”
她好奇极了,急忙站起来去取,仔细看了一下地址和姓名,却惊奇的发现发件人那里写的是何苏叶的英文名字。
小心翼翼的拆开那个不大的盒子,映入眼帘的是一个小巧的饰品,黑色的大颗水晶旁镶着密密麻麻的白色小水晶,在昏暗的灯光照射下,散发出夺目耀眼的光芒。
取出来才发现原来是一个丝巾扣,和自己之前摔坏的那个惊人的类似,她想起自己那天晚上何苏叶安慰失落的她说,后来再买一个好了。
她那时候的回答是,这是奶奶送给我的,几十年前从法国带的,目前跑遍美国都不知道会不会有了,算了吧。
可是他却为自己找来了如此类似的。
盒底还有他的留言,“农历新年快乐,注意身体,好好休憩。”
嘴角不禁扬起了一丝弧度,甜蜜、窃喜,她小心的把丝巾扣装回礼盒中,然后拿起那张快递单,看着上面熟悉的字迹,轻轻的触摸,似乎还有他的余温。
连忙跑到电脑前给他留言,打了几个字又删了,总是找不到合适的词语形容自己的心情,最好只好写道,“新年快乐,丝巾扣很美丽,谢谢你,我很喜爱。还有,注意休憩,不要太劳累。”叹了一口气,眼光不由的飘回了包装精美的小盒子。
她抿起嘴,轻轻笑起来——这样一个小东西,究竟花了他多少时间去寻找。
窗外依然是青灰色的沉沉暮色,可是那些盏盏亮起的明灯让她感到温暖,橘色的灯光穿透黑夜的迷茫,和桌前那盏交相辉映,仿佛彼岸遥望的恋人。
可是QQ上那个头像却很久都不曾跳动,她有了短暂的希望然后又是长久的失望。
那么只能把那份思念埋在心底,用工作学习麻木自己。
星期五的考试颇不顺利,沈惜凡总是觉得耳畔有人在唱歌,搅得她心神不宁,一连几个专业单词都拼不出来,最后匆匆忙忙交了试卷,能否通过只能听天由命。
星期六的小组discussion虽然比较顺利,但是答辩期间她被组员刁钻尖刻的问题问的近几崩溃,最后只能草草收场。
她的论文也出了问题,尽管之前已经在挑灯夜战了数个晚上,把所有能查找的资料都用上了,咬着牙把论文改了再改。但是交上去的时候导师摇摇头,大笔一划,“不够专业!”
是关于行政管理的理论,她立刻感到无语,管理专业的理论知识太抽象,连她自己有时候都读不懂,毕竟她不是管理专业科班出身,浅易一点的又被说成不够专业。
沈惜凡彻底的没了脾气,乖乖的回到图书馆继续找资料,看着看着就觉得眼前的字母都在跳动,一行看下去都不知所云,困意涌上,身体也不受控制的向前倾。
正在困倦和迷糊的边缘徘徊,一不留神,脑袋磕到厚实的书缘处,疼的她倒抽冷气,人倒是彻底的清醒了。
摸摸被磕到的痛处,打算继续看书,只听见背后传来窃笑声,她转头一看,原来是林忆深,背着包捧着几本书站在她身后,眼睛却一直盯着她的论文。
沈惜凡连眼皮都不想抬,沉重的叹气,“返工中,请勿打扰。”
林忆深也不离开,粗粗的翻遍了论文,然后问道,“哪里出问题?”
“Operations Management的理论部分!”她无力的撑着脑袋,手上的笔漫不经心的转着,“导师说不专业,不专业!我要是专业的话我就不念MMH,改念MBA了。”
林忆深笑起来,“就这么一点小事,你怎么不早说呢,或许你就没把我这个科班出身的师兄放在眼里。这个理论知识对你们要求是太高了,对我们来说是小菜一碟。这样,你把论文拷给我一份,我来看看。”
沈惜凡一想也是,凭她一己之力想把论文理论部分尽善尽美几乎是不可能完成的任务,点点头,当下就把所有的资料统统拷给了他。
林忆深看着她呆滞的眼神,叹气,“究竟熬了几天的夜,你们导师也忒不讲人情了,算了,我马上去看,你先回去睡觉,改好了我去找你。”
她只觉得很累,浑身提不出一丝力气,仍是强打精神,自娱自乐,“这几天接连考试、论文,我都觉得我像老了十岁似的。”
林忆深没好气,“像刚从地下挖出来的,好了,快回去吧,晚点时候我去找你。”
她点点头,背起包,挥挥手走出图书馆。一路上,彻骨的寒冷像一张大网将她严严实实地裹住,冷到及至,抬头看天,伊萨卡青灰的天光越来越暗,似乎要下雪了。
林忆深看着她离去的背影,轻轻叹气,坐回原来的位置,拿出电脑,坐在一旁的朋友半晌才回神,“那个女孩子乍看之下跟你女朋友挺像的!”
“什么女朋友,我啥时候有女朋友了!”他一脸狐疑的望着室友。
“嘿!别不承认,上次圣诞节时候来找你的那个,小巧玲珑的。”
“那不是我女朋友,都说了跟你没关系了。”再次对上朋友质疑的眼神,他叹一口气,“三言两语也说不清楚,总之我也有错,OK!”
朋友不依不饶的继续八卦,“你以前说的那个小师妹不会就是刚才那个女生吧,怪事,两人看起来真的挺像的!”
林忆深指指电脑,“工作,工作,别再嘀咕了,小心报告完成不了挨骂!”
一觉不知道睡了多久,只觉得周身滚烫,但是下意识的又觉得冷的发抖,沉沉浅浅的梦境,一片空白,却仍保留着一点清醒的意识在现实之中。
她只知道室友来开门了又走了,然后耳边听见细碎的“倏倏”的声音,轻柔的,似乎是落雪的旋律。
许久之后,门铃急促的响起,沈惜凡一下子清醒了,睁开眼,屋子里黑暗不见光,摸索了半天才穿好鞋子,脚刚着地只觉得头嗡嗡的震的发痛,门外有人喊,“沈惜凡,在不在!”
是林忆深——她应了一声,跌跌撞撞的去开门,只见林忆深站在门外,头发上滴着水,微微的喘着气,“怎么目前才应门,宿舍又没有灯,我以为你出什么事了。”
她迷迷糊糊的“恩” 了一声,“怎么,下雨了?”
“是下雪了!”林忆深进了门,顺手按下了开关,屋子里一片明亮,沈惜凡眯起眼睛望向窗外,“真的下雪了呀!”
他笑笑,举起手里的资料,“整理好了,你看一下,不懂的我给你解释,省得导师要是问起来你答不出来,那就惨了。”
沈惜凡呼出一口气,如释重负,“师兄,我保证后来逢年过节的给你供红鸡蛋,烧三炷香!顺便再来点腊肉、香肠的,你不是素食主义者吧!”
“贫嘴!”林忆深伸手戳她的脑袋,谁知手指触碰处的温度竟然超出正常的高,缩回手连忙问,“沈惜凡,你是不是发烧了?”
她摸摸脑袋,点点头,“怪不得我觉得冷的,原来真的有一点发热。”
“躺床上去!”林忆深眉头皱起来,“这么大人了一点自觉性都没有,都不知道好好照顾自己,你导师到底怎么折腾你的,熬了几天夜?”
“我没事,不过有一点发热,干嘛那么大惊小怪!”沈惜凡倔脾气又上来了,“我快给我看看论文,我晚上还要改,明天交呢!”
话音未落,她觉得一阵眩晕,心跳快的承受不住,只觉得血管急速的膨胀,只好按住心口,缓一口气才好一些。
林忆深吓坏了,“沈惜凡,我怎么了,没事吧,要不要去医院,先躺下再说!”
她点点头,“ 我去躺一下,缓缓气,心脏不舒服。”
宾夕法尼亚大学CVI研究所。
实验室、资料室一片通明,数据在电脑屏幕上一排排的滚动,模拟图像一页页飞速而过,时不时有各种语言的抱怨声传出,“错了,又错了!该死的数据!”
何苏叶全神贯注的看着电脑,忽然右眼一阵狂跳。
也许是太累了,半个多月差不多只睡了三天不到,连躺在床上都是奢侈,更不要说是睡觉了,为了出课题的研究结果,所有人都拼了命的干,而他也很长时间没有和沈惜凡联系了。
不是不想,是不能。
猛然,电话铃远远地在响,寂静中,就像在耳边,一遍又一遍,不知怎么老是没人接。就像有千言万语要说说不出的焦急。
隔壁有人喊他,“何,你的电话!”
他心里一惊,连忙站起来,接起来后是一个熟悉的声音,隐忍中有些怒气,“何苏叶,你到底在忙些什么?”
他有些惊讶,更多的是担忧,“林忆深!怎么了,出什么事?”
“沈惜凡发烧,心脏不舒服,到底是怎么回事,要不要送医院去?”
职业的本能一下子让他想起那些糟糕的疾病,脑中刹时一片空白,凉意滑过身体,此刻,就像有一块巨大的石头在心头上狠狠地砸过,摇晃了一下,觉得那样的惶恐,嗓音一下子变得干哑,“她目前在宿舍吗,除了这些有没有呕吐、呼吸困难这类的症状?”
“暂时没有别的症状,她目前躺在床上,已经睡着了,我今天看到她脸色特别差,像是熬了好几天的夜。”
长长的松了一口气,那根紧张的弦还是不肯放松,“我知道了,我马上就过去!”
林忆深愣了一下,“我们这里下大雪,再说这么晚了……”
话音还没落,就被何苏叶斩钉截铁的声音打断,“没事,帮我看着她,一旦有情况就立刻送医院,我马上就过去!”
挂了电话,他发现自己的手心出了一层薄汗,手脚像是冻僵了一样,活动了好几下才有知觉,匆匆交代了一下自己工作的进度,拿起大衣就出了研究所。
天空一片阴郁,压在他心头,他呼吸不由得乱了方寸,心里只有一个念头,沈惜凡,千万别出事,千万不要,我马上就到。
无边无际的黑暗和孤独,耳边是呼呼的阴风和落雪的声音。时间在她昏睡的意识中变得迢迢无期,梦境中那个人走在漫天大雪中,依然是那样好看的眉目,可是周身散发出拒人千里之外的冰冷气息,毫无生气。
她拼命的跑向他,一种冷彻心扉的惶恐紧紧抓住她的思绪。她觉得他们之间的距离很近,近到伸手可及;可是怎么也触不到他的人,眼睁睁的看见他整个人慢慢的消失,连脚印都消失不见,仿佛不曾来过。
她呼喊他的名字,她乞求他不要丢下她一个人,空间中弥漫着绝望的思念。
天地茫茫,没有任何回应,眼前只有深白色的雪依然飘落,沙哑又凄厉的风声令人钻心耳痛,只剩下自己一个站在雪地中,不知归处。
连眼泪都不知道如何流出,似乎已经麻木。
缓缓地,一字一字地,她听见那焦急、低醇的嗓音,“丫头,快醒醒,怎么了?”
带着些许微温的液体从眼角滑落,跌入发鬓里,迷蒙的视线中,男人蹙着眉头,眼睛里写满了担忧和焦虑。
什么都说不出来,只是眼泪不受控制的就流了下来,不仅仅是由于刚才那个噩梦,这么多天的抑郁和思念,全数发泄。他的怀抱还是一如既往的温暖,她当时只有一个念头,为什么在他面前她总是那么脆弱、那么爱哭。
窗外的大雪,把整个夜空染成了一片秀丽的青色,像是白鸟的翅膀上最柔细的羽毛优雅的飘洒下来,秀丽的无法形容。
世界上的一切变得生动、秀丽,只是由于眼前这个男人,一瞬间,她终于知道他有多重大。
等她平静下来,何苏叶才问道,“究竟几天没睡觉了,你这个是虚劳发热,刚才林忆深电话里描述你的情况时候真把我吓了一跳。”
“林忆深?”沈惜凡瞪大眼睛,“他打电话给你的,他怎么认识你?”
“由于我是他表舅的三姑的儿子的堂哥的表弟——”林忆深推门进来,笑嘻嘻的接口,“没想到吧?我俩还是有点亲戚关系的。”
沈惜凡求助的看着何苏叶,他点点头,“实则我也不清楚我们俩是什么辈份,但是基本上就是那个情况。”
难怪以前在酒店看到他们俩亲密交谈,而林忆深和她说起“ 你男朋友”的时候总是带着狡黠的笑意,原来是这样——她仔仔细细打量眼前两个人,“还真有些神似!”
林忆深笑笑,“正牌男友来了,我这个师兄也要走了,省的做电灯泡。”
何苏叶按住沈惜凡,“你先躺着,我去送他。”
走到楼梯口,林忆深挥挥手,“不用送了,好好照顾她吧,不用太感谢我!”
何苏叶笑起来,有些歉意有些宽慰,真诚的说,“谢谢你。”
林忆深抿起嘴,欲言又止,最后轻轻的叹了一口气,“算了、算了,该说的出国之前我们俩都说清楚了,希望你别忘了!”
他眼睛清亮,声音虽轻,但是掷地有声,“我会给她幸福的。”
林忆深眯起眼睛看着楼外的大雪,一抹笑容留在嘴边,隽永绵长,如释重负。
回去后,沈惜凡便问起来,“林忆深怎么找到你的,你宿舍不是没有电话吗?”
他轻描淡写的说,“他找了熟识的人直接去研究所找我的。”
沈惜凡垂下头,“对不起,何苏叶,我真是个惹麻烦的家伙,真对不起。”
猝不及防,一个轻柔的吻落在她的额角,温情无限,他轻撩起她的额发,直直的看进她的眼里,“应该是我说对不起。”
本是宁静、温馨的一刻,却偏偏她的肚子唱起了空城计,她尴尬的不行,何苏叶笑着揉揉她的乱发,嘱咐道,“把衣服穿好了,吃饭了。”
也许是刚发过烧,白粥入口一点味道也没有,她只是吃了半碗就再也咽不下了,何苏叶不让,“再吃一点,一会还要吃药,胃里空空的对药的吸收不好。”
她顿时好奇,“吃什么药,我这样需要吃药吗,不是热度已经退了?”
“你这是虚劳发热,我不是告知你不要那么拼命了吗?原来身体就不好,目前一折腾更差!”何苏叶提起病症就有些心焦,眉头皱的更深了。
她有些好奇,“我这回要吃什么药呢?”
“归脾汤,补益心脾、益气生血,里面有黄芪、茯苓、白术、甘草、龙眼、当归、远志、木香、枸杞子。”何苏叶叹气,“先去睡一会,好了我叫你起来喝药。”
“可是,这些药从哪里来的?美国也有中药吗?”
“唐人街就有中国药店的,中医在那里很受华人欢迎。对了,今天是中国的大年初三,我去唐人街那里的时候还很热闹。”
她轻轻笑起来,有些孩子气,“那里有没有糖葫芦、热气腾腾的饺子和汤圆,会不会有舞龙舞狮表演,还有对联、福字!”
“想家了,是不是?”何苏叶拉过她的手,“如果想去的话我带你去看,但是还是国内的新年有气氛。”
沈惜凡却觉得心中一动,话到嘴边却不知道如何表达,只是轻轻的捏起那个叫当归的一味药,放在手心,轻轻说,“再等半年,我就和它一样,那你呢?”
“傻丫头!”何苏叶宽慰的笑起来,“你说呢?”
当归,当归——“游子疲惫当归乡, 最念老屋居高堂”,她不禁的爱上了这个名字。
那么究竟是那位古人为这味中药起了这样的名字,是日夜盼儿归的慈母,还是念夫当归的思妇,但是不管是谁,那样一份心意、一种思念直达心底。
也许是真的累坏了,也许是中药的作用,困意很快涌上,朦胧中感觉有人在她唇边轻轻落吻,她轻笑一声,又睡过去。
于是,一夜无梦。
第二天,她是被晨光唤起的。
漫天的白色,密阳照在积雪上,发出 圈淡淡的晕光,那么的洁雅,那么的无瑕。沈惜凡轻轻的舒了一口气,浑身说不出的轻松。
可是,这么大的雪,何苏叶昨晚是怎么赶来的。
厨房传来阵阵香味,是醇厚的米香,一下子打断了她的思绪,她连忙拖着鞋子跑去厨房,发现何苏叶正端着碗筷,看到她便问,“起来了呀,目前感觉怎么样?”
她摸摸前额,松了一口气,“没事 ,目前精神也好多了,你做的什么呀,好香的!”
“是蔬菜粥。”何苏叶顺手揭开锅盖,引得沈惜凡满足的深吸了好几口气,他不由的笑起来,“丫头,别陶醉了,快去洗漱一下吧。”
蔬菜粥入口清爽香醇,一碗不够又添了一碗,而何苏叶只是含笑的看着她,“不用吃那么急,小心胃不舒服。”
由于是他亲手做的,所以吃起来格外的香。
他为自己做了那么多事,却觉得不够,觉得对她不够好,而自己总是心存芥蒂,对两个人的未来时时害怕、担忧、焦虑,而这次的病也是心魔中生。
那些繁重的课业真的不算什么,苦行僧似的自虐式生活只是可耻的孤独感作祟。原来她是害了相思病,由于想念,才孤独,才害怕,才浮躁,才无助,才失控,而他是医她的药。
如果欠了他许多的爱,那么就用一生的时间去偿还。
她放下筷子,望着他的眼神执拗、坦率,轻轻的告知他,一字一顿的,“何苏叶,我想,想跟你永远在一起。”
拿着筷子的手微微颤了一下,然后就是碗筷相碰的清脆声音,他的眼睛里浮出了一种复杂的情绪,欣喜、感动、或是别的什么,沈惜凡看不出这是什么,只任由他站起来走到自己面前,然后轻轻的搂住。
何苏叶在她耳畔只说了一个字, 却觉得比任何山盟海誓更动人,更真诚。
他说道,“好!”
承诺一生。
这个冬天,异地他乡,她终于懂得,爱的世界里终会有幸福相随,爱的世界里终会有天长地久、相濡以沫。
她在如斯的锦绣年华中遇见他,爱上他,然后决定于他相守。
年华至此,圆满已无叹息。
(全文完)
番外,桂花
刚完成一个手术,紧张的神经终于松懈下来,何苏叶舒了一口气顺手推开办公室的窗户。
微风拂面,不远处传来阵阵花香,他仔细辨认,原来是桂花。沈惜凡一直都喜爱桂花,清晨,午夜,在微凉的雨后,鹅黄色一簇一簇并没有什么重量铺在枝头,淡香抑或浓郁,即使无风,也能深深的沁入心脾。
新摘的桂花,用蜂蜜腌制,放到冬天可以用来做桂花汤圆,甜蜜醉人。
这时候护士来敲门,“何医生,请你准备一下,马上去照相。”
他微微一愣,看护士指指胸牌,立刻就清楚了,已经换了一家医院,这是必然的程序。
他脱下白大褂,对着镜子理了一下头发,忽然想起了一件事。
那是他们结婚前去科室发喜糖,等他出来的时候发现沈惜凡怔怔的站在科室门口,他好奇,顺着她的目光看过去,原来是宣传栏上自己的照片。
她看看照片再看看自己,下结论,“还好你不太上镜,不然患者多半是冲着你来的。”
他觉得奇怪,“很难看吗,怎么那么多人说你不上镜?”
“不是!”她笃定,“还是看真人更帅一点,别不知足了,何医生,你已经很帅了。”
他噗哧笑出来,“是吗,没感觉呀!”
沈惜凡抿起嘴微微笑,“ 我第一次见到你的时候,感觉就是惊艳,医院里怎么会有那么帅的医生,连我都不敢信任自己的眼睛。”
“呵,小丫头你一提起我就想起来了,那次我写处方的时候我一直盯着我望,我感觉你不是看我写什么药的,你说你那时候干什么呢?”
“呃——看你名字呀,不过那时候没看见,只看到一个‘主治医生’。”
“处方上不是有么?”
“我怎么知道呀,医生的字都是龙飞凤舞的,还是打印版的清晰,再说,万一你给我开错药了,我好方便投诉。”
他立刻无语,沈惜凡笑眯眯的握住他的手,“说笑的,那时候怎么会怀疑你的医术呢,说了一大堆的专业术语一下子就把我镇住了,心里就觉得你这个医生挺可靠的。”
看到何苏叶脸庞酒窝的痕迹,她又补充道,“不过那时候你老是板着脸,很严肃的样子,我以为你走冷酷路线的,没想到原来你一笑就会岔气,看上去好小的样子。”
何苏叶也忍不住笑起来,“ 我实习时候导师老是说我看上去太小了,给不了病人安全感,然后就把邱天跟我分在一起, 说是,用邱天衬托我的稳重。没想到邱天那家伙突然洗心革面整一天严肃的不行,连我都不敢笑出来了,最后两人回到宿舍,笑了好长时间。”
沈惜凡眨眨眼睛,“原来你的严肃是这样练出来的呀,果然一个成功的男人背后都会有一个成功的男人。”
忽然电话铃响起来,是何爷爷催他们回去吃饭,临走的时候沈惜凡还不忘多看了照片几眼,然后悄悄地跟他商量,“何苏叶,下次照相的时候照丑一点!”
他那时候毫不犹豫的答应她,“我尽量吧!”
照完相之后,几个医生护士围在电脑前面看效果,摄影师拿起资料夹,确认了一下,然后跟他说,“何医生,你是军人吧,这里规定要穿军装的照片。”
何苏叶面露难色,“军装放在家里,一般上班的时候不穿的。”
摄影师笑笑,“没事,明天还有一批,到时候你再来重新照吧。”
他点点头,“麻烦你了,谢谢。”
他回到办公室收拾东西准备回家的时候,接到沈惜凡的电话,“何苏叶,今天晚上我们同学聚会,我不回去吃饭 。”
“好的,那我就去爷爷家了,散了之后打电话给我,我去接你?”
“不用了,我们说好都不许带家属的,没关系,我又不是小孩子了。”
他只好嘱咐,“少喝一点酒,早点回来,如果打不到车就打电话给我,知道不?”
那厢沈惜凡大笑,“我身份证都办了十几年了,不是未成年少女了 ,何医生!”
还没停车就闻到淡淡的花香,原来是爷爷家的桂花开了,雨水冲刷的翠绿枝叶格外精神,那点点鹅黄还不具规模,有的还似小米粒,或者细小的花苞,心里倏地就欣欣然起来。
刚下车就看到何守峥在院子里面,几天不见竟似长高了许多,看到他还是那么黏糊,“小叔叔,快来,快来,那个大一点的花苞,帮我摘下来,我够不着。”
他好奇,“摘这个做什么呀?”
“用蜂蜜酿起来,妈妈教的。”
他不由得笑起来,“我帮你摘,你再帮我拿一个篮子。”
“难道说小叔叔也要做,外公家还有上次酿好的,在厨房的小橱柜里放着。”
“是呀,你小婶婶喜爱吃桂花酿汤圆。”
何守峥撇撇嘴,“是沈姐姐,喊小婶婶让我总感觉她很老似的。”
何苏叶打趣,“你不是一直叫我小叔叔,怎么不感觉我很老的?”
何守峥郑重的点点头,“你本来就不年轻嘛,跟沈姐姐结婚就是老牛吃嫩草!”
一大瓶的蜂蜜桂花,连缝隙中都能闻到清雅的馨香。
一家人在一起吃饭,不知怎么的话题就扯到了孩子上,原本何苏叶只是专心的吃饭,冷不防被长辈们问道,“苏叶,你和惜凡啥时候准备要孩子,两个人都不小了。”
他一口饭噎在嘴里,勉强的吞下去,尴尬的笑笑,“我们两都很忙的,暂时还没思考。”
何爷爷笑起来,“话是这么说 ,可是有个孩子才算是完整的家, 你看你堂姐一家多好,何守峥那么机智,多讨喜。”
何守峥一脸欣喜,“小叔叔的孩子,那我不是比他大了,太好了, 终于可以翻身了。”
不是没有思考过孩子的问题,而是沈惜凡一直不想那么早要,而自己虽然很看重家庭,但是工作实在是很忙,在调去军区总医院前不是手术就是加班,连晚上睡觉时候也会被急救的电话吵醒,由于这个缘由,他也不是很想要孩子。
既然结婚了,有了家庭和孩子了,就得负起责任,他一直是那么想的。
不过目前既然两个人都安定下来了,这件事也应该提上日程了。
改天找个机会跟她说说,如果不愿意就算了,这种事还是顺其自然。
回家的路上,下起了小雨,由于路上堵车,足足花了一半多的时间才到家。
从楼下看去,家里的灯已经亮了,明黄的光线透出来,让他心里暖暖的,和以往一样,他知道家里有她在等。
打开门,迎面而来的是淡淡的酒香味,他微微皱眉,看来沈惜凡又喝了不少的酒。
可是客厅的灯亮着,却不见人影,他喊了几声也没有人应,拧开关紧的卧室的门,发现沈惜凡呆呆的坐在床上,拖着脑袋,对着衣柜微微笑。
也许是酒精的缘故,她的脸透出撩人的绯红,明媚的意态流露在她的眼角、眉梢,看到他进来,努努嘴,声音甜腻撒娇,“老公,把这件衣服穿上去给我看看。”
他定睛一看,大感意外,“军装?目前穿做什么?”
“让你穿就穿嘛——”沈惜凡眯起眼睛,“我还没见你穿过呢,你们医院目前怎么不规定穿军装了呀?”
顺手接过她递来的衣服,他解释,“只有那些主任才穿的,要不就是实习医生,目前军区总医院外聘的人员许多,不是专业的分不出行货还是水货。”
换好制服,他顺手拿起领带,却被沈惜凡按住了,“这条配军装不好看,下次我重新给你买一条深蓝色的,我上次去看的那条VERSACE不错,当时觉得没配的衣服,目前看看配这个就极好。”
何苏叶笑笑,“看完了吧,我可以换下来了,不过我可不可以好奇的问一句,为什么突然要我穿军装?”
“今天听她们说男人穿制服最帅的,然后我就想起咱爸,穿起军装真是帅——足见当年的英俊潇洒。” 站在床上,低下头靠近何苏叶的脸,呼出撩人的淡淡酒气,“没想到 穿起来比他还帅,本来就生的那么撩人,没想到,呵呵——”
他笑起来,对上她灼灼的目光,“老婆你过奖了,目前可以——”
话音未落,猝不及防的,温柔的、略带占有欲的唇堵住了他的话,她的唇里有葡萄酒的香味,让人迷醉。两个人毫无缝隙,急促的喘息和身体里的起伏,肌肤相亲,就像暴风卷起的惊涛骇浪,唇齿之间的相互进犯,像一场火爆又艳丽的战争。
可是他突然想起一个重大的事,气息不稳的询问,“今天…..”
灯光下横波潺潺的眼眸对他做着无语的诱惑,沈惜凡笑起来,甜美中带着一丝狡黠,“算了,不管了,顺其自然就好了……”
好吧,他理智的最后一根弦应声而断,那就顺其自然。
似乎眼前有明黄的阳光跳跃,何苏叶不由得睁开眼睛,撑起手臂去看手表,身边的人不自在的动了两下,然后眯起眼睛,懒懒的问,“几点了 ?”
“还早呢,你今天不是不用上班,再睡一会吧。”
沈惜凡蹭了蹭枕头,拉紧被子,梦呓似的吐出一个字,“累——”然后又沉沉的睡过去。
他爱怜的凝视了她好一会,忍不住在她唇角上印上一吻,穿好衣服去做早饭。
桂花酿汤圆,虽然不是这个季节的甜品,但是早上伴着桂花香来上一碗,实在是一件很奢侈的事,可惜这样的美食却只能自己独享。
留了一碗在微波炉里,贴了张字条告知她早餐,然后折回卧室去取军装。
昨晚也许是酒精的作用,小丫头出乎意料的主动,不过庆幸的最后关头是两人还有些残存的理智,没有亵渎了这件军装。
取了军装,叠好装进袋子里,忽然想起前几天堂姐让沈惜凡代买东西的发票,只好折返回卧室,轻轻的唤醒她,“那张发票呢,堂姐催了好几次。”
沈惜凡迷迷糊糊的答道,“我的钱包里面,自己去拿。”
钱包里面塞满了各种卡片,他找了好半天才看见那张发票,卡在两张信用卡之间抽不出来,小心的把取出来,却发现连带着一张照片掉了出来。
他拾起一看,哑然失笑,原来是自己在以前医院胸牌上的工作照,被她戏谑的称为“不上相,扭曲”的那张照片。
口是心非的小丫头,既然不好看干嘛要随身带着,还不告知他,偷偷的藏起来。
如果她早说 ,自己可要挑一张最好看的让她随身带着,列如自己,钱包里夹的必定是她最美丽的那一张。
算了, 这张暂时没收好了。
第二批照相的都是军医,一清色墨绿色的军装,好几个实习护士赞叹,“帅死了,男人还是穿制服好看!”
他最后照,照完后,摄影师指着电脑上照片问他,“何医生,用这张吧?”
他笑笑,“还是那张吧,这张能不能私下拷给我?”
摄影师觉得奇怪,自己审美眼光得到了怀疑,忙追问,“我觉得这张效果比那张好。”
何苏叶礼貌的笑笑,“是呀,所以才用那张的。”
口袋里的手机微微震动,打开一看是沈惜凡的信息,“何苏叶,你今天拿发票的时候有没有看到有一张一寸照片。”
他存心想逗逗她,“什么照片?没看到呀。”
一会儿信息又来了,他都可以想象的到她的着急,“完了,不会是昨天被哪个色女给抢走 ,还是弄丢了,你确认没看到吗?”
“什么照片,很重大吗?”
“怎么不重大,是你的照片唉,完了——”
他在心里暗笑,安慰她,“我回去再给你一张好了,我们医院正在照新的工作照。”
“记得把那张最帅的留给我,工作照还是用比较不帅的。”
他笑起来,顺手穿起白大褂,刚拿起手机回信息,她的信息又来了——
“今天晚上早点回来 ,我会做桂花百合莲子汤,记得要早点回来哦!”
“知道了,必定。”
从门诊绕去住院部,穿过一片绿地,馥郁的桂花香味飘过来,他抬头一看只见前面有细小的花瓣细雨般纷纷杨扬,轻轻落下,那是成片的桂树,商量好了般同时盛开,香气充盈周身的空气中。
伸手去接住这些细碎的花瓣,他憧憬着下一个花季的到来,也许那时候,会有属于他完整的三口之家。
林的番外
桌上的咖啡已经凉了好久,直到触到冰凉的杯缘他才反应过来,头也不抬的唤秘书小姐,“Lucy,a coup of coffee,thanks!”
却没有预想的人出现,林亿深疑惑的看看四周,空无一人,再看看桌上的钟,原来已经下班了两个小时了,而自己完全沉浸在数字和报告里。
苦笑了一声,站起身准备收拾东西,桌上的喜帖安安静静的躺在一隅,红得让他嫉妒。无意中向外望了一眼,这个城市流光溢彩,春天初始,却没有丝毫的萧瑟之气,华灯绿水、流云繁星,天上人间,竞相辉映。
仿佛永远清醒,却永远孤独。
那时候温微总是习惯在公司留到很晚,然后一个人跑去顶楼的天台上,华灯初上的繁华商业区就在自己的脚下,一片灯海,无限繁华。她喜爱看夜幕中灯光闪烁,这样让她感到安心和平静。
那个夜晚,跟以往似乎没有什么不同,温微端着咖啡坐在顶楼,刚想起身就听到身后有脚步声传来,蓦然回首,只见林亿深站在灯光的阴影里,挺拔强劲透出一丝寂寥和难得的温情,可是却让她觉得不真实,林亿深离她更远了,抑或是更近了。
他走到她身边坐下,“孤单又寂寞的城市,虽然很秀丽。”
温微笑起来,“在绝望中寻找希望!”
林亿深哈哈大笑,温微也笑起来,她把手指张开,有细碎的流光透过,她眯起眼睛笑,他也看着她,两人都隐隐的觉得气氛有些不一样。
最后还是一起去吃了饭,蟹粉排鸡腰、菊花黄鱼羹、松江鲈鱼、干贝莴苣,几乎全是沪菜的招牌菜。
温微夹了一块鱼肉送进嘴里,笑起来,“林经理,你是上海人?”
他摇摇头,“难道说你不是上海人?”
她愣了一下,随即点点头,“是呀,我从小到大一直在上海,直到总公司把我派到这里。”
林亿深宽慰的笑笑,“这些菜做的还有没有家乡的味道,我不是上海人,所以不清楚。”
一股暖流涌上心头,她拿着筷子的手顿了一下,含糊的说了一句,“做的很正宗,谢谢。”
她实则早就暗暗留心上了这位全公司有名的总经理,三十出头,钻石单身帅哥一枚,康奈尔Business Administration博士出身,没有绯闻,为人正派。许多人说跟他说话时候都有一种被尊重的感觉,他光光是微笑就让人如沐春风。
后来才知道原来林亿深在留学之前是酒店的公关部经理,那样一个圆滑的职业,需要面对各式刁难的客人,而目前仅仅是对着一群训练有素下属和以礼相待的客户,自然是轻车熟路。不过他也有发火的时候,冷冰的一张脸,不怒而威。
而她仅仅见过一次。
那是他们财务部出的错误,她被本部派来的第二天,刚进办公室,便看见林亿深铁青着脸,负着手站在财务部经理前,在场的人没有敢出声,气氛冷的像腊月里飘雪。
所有人都不知道那一天是怎么度过的,战战兢兢的大气都不敢出,林亿深走后半个小时不到她就被秘书小姐请到经理室,林亿深背对着她站在晨光之中,她注意到了桌上一份辞职报告和一份任命书,而那份任命书赫然写着她的名字——财务部经理。
她立刻就被吓到了,整理了一下思路,“总经理,我来了。”
他转过身,表情又变得柔和,仿佛什么事都没有发生过一样,只是指指那份任命书,“温小姐可以接受吗?”
毫不犹豫的摇头,得到的是林亿深询问的眼神,她郑重的开口,“论学历和资历这个职务都不应该属于我,况且我才来,并不熟悉这里的情况。”
林亿深笑起来,眉头舒展更显得英气十足,“不熟悉的会变成熟悉,财务经理不需要事必躬亲,只需要调兵遣将,况且——”他顿了一下,“公司需要的是认真的员工,这点我超级信任温小姐,由于——”他却不接着说下去,只是看着她的眼神坦率真诚。
好一个“信任”,她立马就被俘虏了,拿着那份任命书郑重点点头,“好的,我接受。”
后来她才知道,林亿深是有看人的直觉,四年的酒店工作已经练就了他的火眼,按公司总机小姐的话说就是“混过的,啥样人物没见识过,在他面前我们都太简单了。”
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...