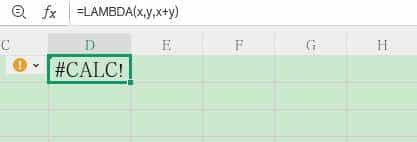
代码没问题,点真机调试会报错:
index.js:1 TypeError: Cannot read property 'getLaunchOptionsSync' of undefined
at Object.eval (wx.js:24)
at __webpack_require__ (bootstrap:81)
at Object.0 (main.js:27)
at __webpack_require__ (bootstrap:81)
at checkDeferredModules (bootstrap:47)
at Array.webpackJsonpCallback [as push] (bootstrap:34)
at eval (main.js:2)
at C (eval at Ce.t.call.document (runtime.js:1), <anonymous>:3:5787)
at n (eval at Ce.t.call.document (runtime.js:1), <anonymous>:3:4741)
at eval (app.js:5)
ye @ index.js:1
index.js:1 TypeError: Cannot read property 'getAppBaseInfo' of undefined
at getLocaleLanguage (index.js:468)
at Object.eval (index.js:479)
at Object.eval (vendor.js:2543)
at __webpack_require__ (bootstrap:81)
at Object.33 (index.js:21)
at __webpack_require__ (bootstrap:81)
at checkDeferredModules (bootstrap:47)
at Array.webpackJsonpCallback [as push] (bootstrap:34)
at eval (index.js:2)
at C (eval at Ce.t.call.document (runtime.js:1), <anonymous>:3:5787)
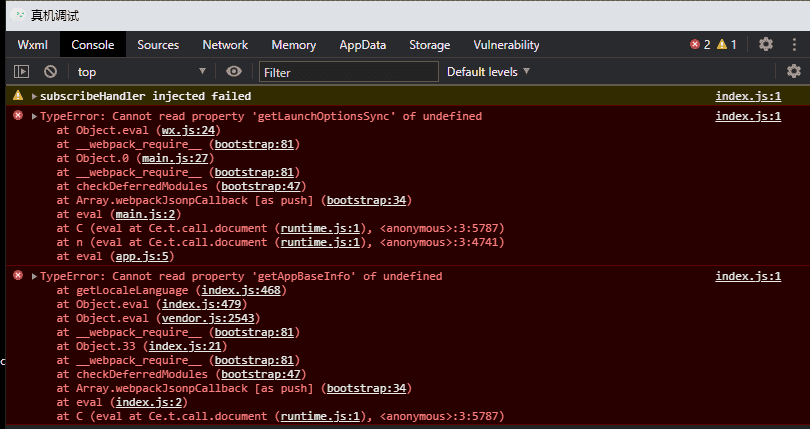
解决方案:这是开发工具的bug,如果点的是真机调试,就点预览试一下;如果点的预览报错,就点真机调试。就可以用
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...