编译 | 宇琪
策划 | Tina
在 AI 编程工具进入大乱斗时代的今天,我们似乎已经习惯了各种功能的堆叠。但在 libGDX 创始人、17 年开源老兵 Mario Zechner 眼中,这一切正变得越来越不可控。
“当你发现 AI 在背地里偷偷修改你的上下文,而你却对此一无所知时,这种掌控感的丧失是极其危险的。”
近日,在 Tessel 举办的开发者大会上,Mario 不仅公开吐槽了 Claude Code、OpenCode,更带出了他的极简主义“反叛之作”——pi。这是一个只有 read、write、edit、bash 四种工具,拥有主流 agent 里最短的 system prompt,却有着极致的可扩展性、能让开发者重拾掌控权的终端编程 agent。
本文基于该演讲视频整理,经 InfoQ 编辑。
核心观点如下:
-
Claude Code 目前就是一架宇宙飞船,它功能多到你可能只用过其中的 5%,了解的也就 10%,剩下 90% 全是 AI 和 agents 领域的“暗物质”,没人知道它背地里到底在干嘛。
-
现有的编程框架里,许多功能可能并不是获得好结果的必需品。不需要文件工具,不需要子 agent,不需要联网搜素,啥都不需要。
-
我们目前正处于“一边瞎折腾一边看结果”的阶段,没人知道完美的编程 agent 到底该长啥样。我们需要更好的“折腾”方式,编程 agent 必须是可自修改、可塑性极强的,这样我们才能快速实验新想法,看看能不能折腾出某种新的行业标准或 workflow。
-
真正需要 linting 和类型检查的时机只有一个:那就是 agent 觉得自己彻底完活儿的时候。
1 ChatGPT→Copilot→Aider→Claude Code
2025 年 4 月左右,Peter Steinberger(OpenClaw 创始人)跑来跟我还有 Armin Ronacher(Sentry 联合创始人、Flask Web 框架创建者)说:“目前的 Coding Agents 真的进化到能干活的程度了。” 我当时的第一反应是:“噢,快给我闭嘴吧!”我是真不信这玩意儿。但一个月后,我们几个就在公寓里闭关了 24 小时,整夜沉浸在这些 clankers、wipe coat 和 wipe slop 的世界里。
我们不停地造东西,造了一大堆,但绝大多数我们自己从来没用过。这就是 2025 到 2026 年的新常态:我们写了许多代码,造了许多轮子,但真正用上的没几个。折腾到最后我开始想,我讨厌现有的所有 Coding Agents 或开发框架,自己写一个到底能有多难?当时 Peter 说:“我只想做一个属于自己的小玩意儿。”后来的故事大家可能都知道了。
今天,我要讲的是我那个没那么惊天动地的故事,但我希望能在其中分享一些我在过去几个月里攒下的行业洞察。
先聊聊 Coding Agents 的演进史。
2025 年之前的情况基本就是:从 ChatGPT 搬运代码,但代码大多是碎的,一般只能写一些你不想亲自动手的简单函数。然后有了集成在 Visual Studio Code 里的 GitHub Copilot,只需要一路 tap tap tap,虽然有时候灵,大多数时候并不。甚至有时候,它还会超级“贴心”地给你默写一段 GPL 协议的代码,列如 John Carmack 的那个平方根倒数速算法之类的。后来又有了 Aider,当时还有 AutoGPT。
最后,Claude Code 登场了。我记得他们在 2024 年 11 月发布了 beta 版,但真正火起来是在 2025 年 2 月或 3 月的样子。当时我觉得这玩意儿简直太棒了,Claude 团队超级出色,他们在社交媒体上很活跃,人也都很天才。
说实话,他们基本上开创了整个品类。虽然之前有 Aider 和 AutoGPT 铺路,但没有一个能达到这种高度。这就是所谓的 agentic search(智能体搜索)范式:它不像 Cursor 那样先进入你的 codebase 做索引、搞各种复杂的构建(虽然那样搞也未必好使)。Claude 团队直接通过强化训练,让模型学会使用文件工具和 bash 工具,通过这种方式实时探索你的 codebase,寻找理解代码所需的信息并直接修改。这效果简直惊人,我们直接不睡觉了,由于产出的代码量比以前纯手写翻了不知道多少倍。
那时候它简单、可预测,完美契合我的 workflow。但后来,他们掉进了一个我们许多人都会掉进去的陷阱:既然这些 clankers 能写这么多代码,为什么不让它把所有能想到的 feature 都写了呢?这主意听起来不错吧?咱们加这个功能,加那个功能,加加加……最后搞出了一个类似 Homer Simpson 设计的那种怪物。Claude Code 目前就是一架宇宙飞船,它功能多到你可能只用过其中的 5%,了解的也就 10%,剩下 90% 全是 AI 和 agents 领域的“暗物质”,没人知道它背地里到底在干嘛。
2 Claude Code 不是一个稳定的好工具
我个人觉得这并没什么用,由于我始终认为开发者需要知道 agent 到底在做什么。我们目前在 Tessel 的活动现场,他们也喜爱搞 context management/engineering。但我最终发现,Claude Code 在可观测性和上下文管理方面并不是一个好工具。而且,谁受得了 Claude Code 的那种没完没了的、莫名其妙的闪烁?
Anthropic 的开发者关系专家 Thariq Shihipar 有时候会在 Twitter 上说些让人摸不着头脑的话,列如:“我们的 terminal user interface 目前是一个游戏引擎了。”
我是做游戏开发出身的,那是我的老本行。当我看到这种话时,心真的会滴血。那只是个终端界面,你之所以觉得它是游戏引擎,是由于你在终端界面里用了 React,结果导致重新渲染整个 UI 树要花掉 12 毫秒。别这么干好吗?它真不是游戏引擎。
后来写 Ghostty 的 Mitchell 也忍不住了,他说:“这听起来有点冒犯。别把锅甩给 Ghostty 或者其他终端,纯粹是由于你的代码太烂了。”终端渲染一帧只需要不到 1 毫秒,每秒能跑几百帧,所以别拿这个当借口。
虽然后来他们修好了闪烁,但别的问题接踵而至。你会感觉到他们彻底倒向了所谓的 vibe coding,这种感觉在你每天使用 Claude Code 时尤为明显。我并不是要贬低他们的努力和成果,Claude Code 依然是这个品类的领头羊,他们开创了这一切且做得超级棒。我只是个喜爱简单、可预测工具的老头子,而它已经不再契合我的 workflow 和需求了。
而且,他们在后台偷偷对你的 context 做了许多手脚。2025 年夏天,我写了一堆工具去拦截 Claude Code 发往后端的请求,想看看他们在背地里往我的 context 里塞了哪些额外的文字。结果发现这些操作超级多余,而且每天都在变。可能今天发个版本,明天又发个版本,注入内容的时机和方式变来变去,这会直接搞乱你现有的 workflow。它不是一个稳定的工具。
我理解他们的立场,他们需要实验,而且用户基数巨大,在庞大用户群的基础上做实验的确 很难。但他们并不在意用户的感受,所以我们都得跟着受罪:你正用着这个新工具,努力构建可预测的 workflow,然后工具厂商在引擎盖下改了个不起眼的小细节,就导致 LLM 在处理你现有任务时直接发疯。这根本没法持续,我需要掌控感,我不能指望他们给我提供一个所谓的“稳定环境”。
作为 UI 设计的代价,他们不得不降低可观测性。我个人不喜爱这样,但这只是个人偏好,我知道大多数人对于 Claude Code 展示的信息量已经很满意了。另外,它显然没有模型选择权,由于它是 Anthropic 的原生工具。这不算坏处,但它几乎没有任何扩展性。虽然他们有一套 hook 系统,但如果你对比一下 pi 能实现的功能,你会发现他们的集成度并不深。而且它基本是基于在 hook 事件触发时运行一个进程,如果你需要反复启动那个进程,开销真的超级昂贵。
后来,我彻底对 Claude Code 下头了。倒不是说它做得烂,只是它不再适合我了。在那段时间里,它变得适合更多的大众用户,这说明他们路子走对了,只是不适合我这种老古董。
3 OpenCode 的底层设计让我失去信心
于是我开始到处找替代方案。第一是 Codex CLI,刚开始我挺不喜爱它的,无论是界面还是模型,不过目前它的模型表现的确 挺惊艳的。接着是 AMP,这个团队的核心成员以前在 Sourcegraph 工作,后来出来单干了,都是极其顶尖的工程师。他们居然做出了一款超级商业化的 coding harness,而且是靠“砍功能”而不是“堆功能”来赢得市场,他们的许多设计逻辑跟我简直不谋而合。如果你想要个商业化的编程框架,我绝对推荐 AMP。Factory 也是类似的思路,做得很扎实,只是没像 AMP 那么激进和富有实验精神。
然后就是 OpenCode 了,许多人都在用的开源框架。我这人有开源情怀,在开源圈摸爬滚打了 17 年,大大小小的项目都管过,开源对我来说意义非凡。所以我当时想,既然 OpenCode 离我这么近,那就试试吧。而且说实话,除了 AMP,OpenCode 的团队是这个圈子里最接地气、最务实的,他们不会整天拿那些你八辈子用不上的功能来忽悠你,而是努力维持一个超级稳定的核心体验。他们对“编程 agent 对我们职业意味着什么”的思考,我也超级认同。
但 OpenCode 的问题在于:它在上下文管理上做得一塌糊涂。列如,它每一轮对话都会调用一个叫 SessionCompaction.prune 的函数,把最后 4 万个 token 之前的记录全给删了。大家应该都知道 prompt caching(提示词缓存)吧?它这么干意味着把你的 cache 全毁了。
OpenCode 和 Anthropic 之间有一段挺有意思的过节。在我看来,Anthropic 后来的态度逻辑很通顺:“你们不能这么搞。”虽然这事儿没公开闹大,但道理很简单:如果你去健身房却不守规矩,滥用人家的基础设施,你肯定会被拉黑。虽然我没证据,但我猜这就是为什么 Anthropic 和 OpenCode 之间关系紧张的缘由。我完全站在 Anthropic 这边,别去糟蹋人家的基础设施。
还有些别的坑,列如 OpenCode 自带了 LSP(语言服务器协议)支持。假设你给 agent 下了个任务,让它改一堆文件。实际操作中它会怎么干?它会一个接一个地改。你觉得它改完第一轮,代码能编译通过的概率有多大?当你一行一行改代码时,得花多久才能让它重新回到编译通过的状态?答案是根本回不去。可能改完第一处、第二处,代码还是崩的。
这时候如果你跑去问 LSP 服务:“嘿,我刚改了这一行,代码崩了吗?”LSP 肯定会说:“是的,彻底崩了。”然后这个功能就会把报错信息直接塞进 tool call 后面,反馈给模型:“你刚才干错了。”模型一脸懵逼:“搞什么?我还没改完呢!你目前跟我说这个?”这种事发生得多了,模型最后就会直接罢工,导致产出的结果超级糟糕。所以我特别反感在 agent 工作时挂 LSP。真正需要 linting(代码检查)和类型检查的时机只有一个:那就是 agent 觉得自己彻底完活儿的时候。
而且 OpenCode 最近有个变化:在一个 session 里,每一条消息居然都会被保存为一个独立的 JSON 文件。这在我看来,说明它在整个架构设计上缺乏深度思考。一旦我对这种底层设计失去信心,我就不想再用这个工具了。
此外,OpenCode 默认带了一个 server 架构,客户端连接到服务端,终端界面只是其中一个客户端。这原本挺高端,结果却爆出了一个默认自带的远程代码执行(RCE)安全漏洞。如果你对自己的服务器架构那么自豪,我默认你应该是一群成熟的工程师,至少思考过安全性吧?但显然他们没思考,而且这个洞开了很久。我也不是要指责谁,在目前这种前所未有的、快到让人颈椎骨折的行业节奏下,出错难免,但我是不想用这种存在隐患的工具。
这就是我对现有 coding harnesses 的观察。AMP 实则不错,但我没有掌控权,它甚至会决定你用哪个模型处理哪类任务,这不符合我的性格。
后来由于一些别的缘由,我开始研究 Benchmark(基准测试),结果发现了 TerminalBench。简单来说,它是一个专门针对 agent 的评估 harness,包含了大量和计算机操作、编程相关的任务。它有大约 82 个超级多样化的任务,从“修好我的 Windows 设置”到“帮我写一个蒙特卡洛模拟”。它有个排行榜,上面列出了各种 agent 框架和模型的组合。
其中有一个叫 Terminus 的 agent 让我觉得超级惊艳,它是排行榜上表现最好的框架之一。它是怎么做的呢?模型拿到的只有一个 tmux session,它唯一能做的就是发送按键,然后读取返回的 VT 序列码。这是模型和电脑之间最极简、最原始的接口了。不过,它的表现却是顶级的。
这说明了什么?我们真的需要那些花里胡哨的功能来让模型干活吗?
对我个人而言,这不只是模型好不好的问题,还有作为用户的“人”该如何与 agent 交互。Terminus 的用户体验或开发者体验显然不是我想要的,但它证明了一点:现有的编程框架里,许多功能可能并不是获得好结果的必需品。不需要文件工具,不需要子 agent,不需要联网搜素,啥都不需要。
基于这些发现,我总结了两个核心论点:第一,我们目前正处于“一边瞎折腾一边看结果”的阶段,没人知道完美的编程 agent 到底该长啥样。大家都在尝试,有人走极简路线,有人走“宇宙飞船”路线,搞什么 agent 集群、完全自治。我觉得这事儿还没定论,行业标准还没出现。
第二,我们需要更好的“折腾”方式,编程 agent 必须是可自修改、可塑性极强的,这样我们才能快速实验新想法,看看能不能折腾出某种新的行业标准或 workflow。
所以我的基本思路超级简单:剥离掉一切冗余,构建一个极简且可扩展的核心,再稍微加点让人用着舒服的小功能。它不是一张纯粹的白纸,但也绝对不臃肿。
4 Pi:让 Coding Agent 适应你的需求
pi 的核心理念很简单:让你的 Coding Agent 去适应你的需求,而不是反过来。
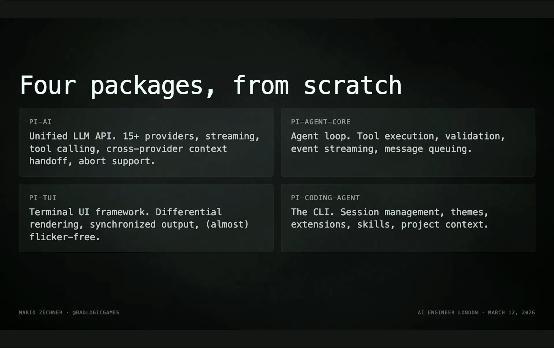
整个系统只由四个 package 组成。第一是 AI package,本质上是对多种 provider 的一个轻量抽象层。由于不同 provider 使用不同的 transport protocol,这一层帮你把复杂性都抹平了。你可以在同一个 context 或 session 里超级轻松地和不同 provider 对话、随时切换。接下来是 agent core,一个通用的 agent loop,包含 tooling、定位、验证等等基础能力。然后是 TUI,大致只有 600 行代码,但出奇地好用,可能由于不是某个 clanker 写的。最后是 Coding Agent 本身,它既可以作为一个 SDK,在 headless 模式下使用,也可以作为一个完整的终端交互式 Coding Agent。
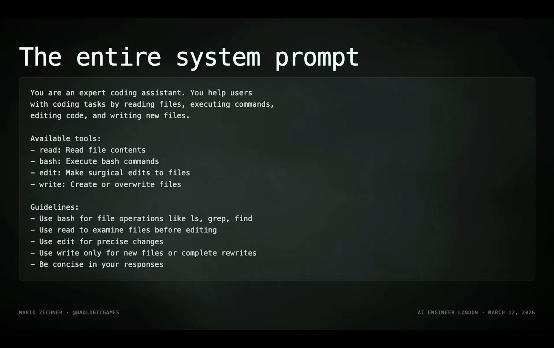
系统 prompt 就这么多,全部都在这了。和其他 coding harness 那种动辄一大堆 token 的 system prompt 相比,这里几乎是“空”的。缘由实则很直白:frontier models 已经通过大量 RL 训练,早就“知道”什么是 Coding Agent 了。所以反复告知它“你是一个 Coding Agent”“你应该怎么写代码”?实则没有必要。
默认就是 YOLO 模式(默认直接执行,不向用户确认,全自动跑到底)。目前大多数 Coding Agent harness 基本分两种模式:要么 agent 想干嘛就干嘛,要么每一步都要问你:“你确定要删这个文件吗?”“你确定要列出这个目录吗?”……看似安全,但现实是,这种机制只会带来疲劳。用户要么直接关掉这些确认,开启 YOLO 模式,要么就无脑按回车,根本不会看提示。所以这并不是一个真正有效的解决方案。
至于 containerization(容器化),如果你担心数据泄露或提示词注入,它也不是万能解。但相比那些确认对话框式的“guardrail(护栏)”,它至少是一个更合理的基础。
pi 只提供四个工具:read、write、edit,以及 bash。没有 MCP,没有 sub-agents,没有 plan mode,没有 background bash,也没有内置的 to-do 系统。但重点在于,你完全可以用更简单、更透明的方式自己实现这些。

没有 MCP?可以用 CLI tools 加上 skills,或者直接写一个 extension,一天之内就能搞定。没有 sub-agents?由于它们不可观察。你可以用 tmux 去 spawn agent,这样所有输入输出都在你掌控之中,每一步发生了什么都一清二楚。目前 Claude Code 的 team mode,本质上也在做类似的事情。
没有 plan mode?那就写一个 plan.md 文件。它是一个持久化的 artifact,比那些塞不进 terminal viewport 的“蹩脚 UI”实用多了,而且还能跨 session 复用。没有 background bash?tmux 已经帮你解决了。没有内置 to-dos?写一个 todo.md 就行。
当然,你也可以选择把这些全部按自己的方式重新实现,这正是 pi 的价值所在:极致的可扩展性。你可以扩展工具,给 LLM 提供你自己定义的能力。目前几乎没有其他 Coding Agent harness 支持这一点,除非你去 fork OpenCode。但在 pi 里,你只需要写一个简单的 TypeScript 文件,它就会自动加载。
你还可以写自定义 UI、skills、prompt templates、themes,然后打包发布到 npm 或 git,通过一条命令安装。更关键的是,所有东西都支持 hot reload。我平时会在项目内部开发一些 task-specific 的 extension,当 agent 修改这些 extension 后,我只需要 reload,一切就即时生效,整个运行中的系统会立刻更新,体验超级顺滑。
这在实践中意味着许多事情都可以自己动手做。列如 custom compaction,这是我觉得大家应该多尝试的方向,目前所有的 compaction 实现都不太理想。permission gates?50 行代码就能写一个,覆盖市面上大多数 agent harness 的能力。custom providers?无论是注册 proxy 还是接 self-hosted models,都不用等我来做,你自己甚至可以让 clanker 帮你写。
你甚至可以重写内置工具,改变 read、edit、bash 的行为。我自己就有一套版本,是通过 SSH 在远程机器上执行的,5 分钟就实现了,而且很好用。再加上完整的 TUI 访问能力,你可以在 Coding Agent 里直接构建完全自定义的界面。
社区里已经有不少有趣的 extension。列如有人用 5 分钟就在 pi 里复刻了 Claude Code ships,而且功能更多。
pi-messenger,是多个 pi agent 的聊天室,它们可以相互通信,还有自定义 UI,可以实时观察它们的行为,而且的确 能跑。
甚至还有一些更“离谱”的玩法,列如 pi-nes,你可以在 agent 运行的时候顺手打个游戏。
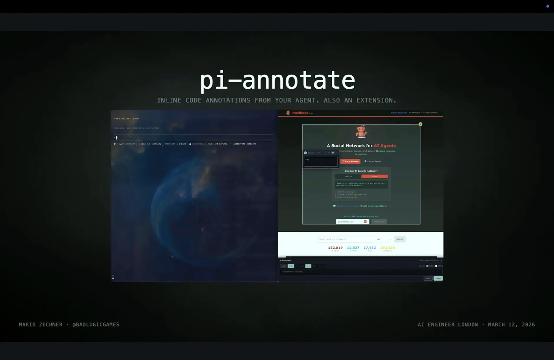
pi-annotate,可以直接打开你正在开发的网站,在前端界面上做标注,把反馈原地喂回给 agent,再让它修改代码。
还有我自己常用的 pi-files-widget,不用切到 IDE,就能快速查看刚刚被修改的文件。
关键在于,这些都不是内置功能,全都是 extension。而大多数人只需要几分钟到一个下午,就能把这些东西按自己的习惯搭出来。

pi 的 session 是树结构,而不是线性的聊天记录。你可以在一个分支里让 agent 读取目录、总结内容,然后回到主对话,把总结带回来继续工作,本质上就是一种更可控的 sub-agent。系统不会在你背后偷偷注入任何东西,agent、skills、调用成本,全都是透明可追踪的。这一点许多 harness 都没做好。此外还支持 HTML 导出、JSON 格式、headless JSON streaming 等等。
Pi 真的有用吗?terminal bench 的结果显示:pi 紧跟在 Terminus 2 后面,使用的是 Claude Opus 4.5。而那还是在去年 10 月,当时 pi 甚至还没有 compaction。
最后说一点现实问题。如果你参与这个项目,很可能会有大量来自 OpenClaw 的用户涌进你的仓库,用 clanker 批量提交 issue 和 PR,直接把你淹没。
所以我不得不搞了一些“防御机制”。列如我发明了一个叫 OSS Vacation 的策略:直接把 issue 和 PR 关掉几周,自己专心开发。真正重大的问题,总会有人在之后重新提出来,或者在 Discord 里说。
另外我还做了一个简单的访问控制:仓库里有一个 markdown 文件,如果有人提交 PR,但用户名不在这个文件里,PR 会被自动关闭。规则也很简单,先用“人类的声音”写一个 issue,自我介绍一下,而且不要超过一屏,由于太长的大致率是 clanker 写的。通过之后,你的名字会被加入列表,就可以正常提 PR 了。本质上,我只是在做一件事:验证你是人类。
后来 Ghostty 的 Mitchell 也基于这个思路做了一个项目,叫 vouch,可以更方便地应用在你自己的开源仓库里。
以上就是 pi,去试试吧。
演讲原链接:
https://www.youtube.com/watch?v=Dli5slNaJu0
声明:本文为 InfoQ 翻译整理,不代表平台观点,未经许可禁止转载。
今日好文推荐
会议推荐
世界模型的下一个突破在哪?Agent 从 Demo 到工程化还差什么?安全与可信这道坎怎么过?研发体系不重构,还能撑多久?
AICon 上海站 2026,4 大核心专题等你来:世界模型与多模态智能突破、Agent 架构与工程化实践、Agent 安全与可信治理、企业级研发体系重构。14 个专题全面开放征稿。
诚挚邀请你登台分享实战经验。AICon 2026,期待与你同行。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...