
41.5K Star! CrewAI:我把500行LangChain代码全删了
「小墨是前端」专注前端技术分享,推荐优质开源项目,展示 Github、Gitee 创意作品,深入前端底层原理,一起探索技术边界。
目前 AI Agent 爆发,但是大多数框架还是太”程序员思维”了。你需要定义 Chain、定义 Memory、定义 Tool,像是在拼乐高。
而 CrewAI 是”产品经理思维”。你不需要关心底层怎么连接,你只需要定义”角色”(Role)、”目标”(Goal)和”任务”(Task)。
这就好比,以前你是写代码控制机器人,目前你是开公司招人。
它完全独立,不依赖 LangChain(虽然也能配合用),主打一个轻量、快速、生产级。短短几个月冲到 41.5K Star,这速度简直离谱。
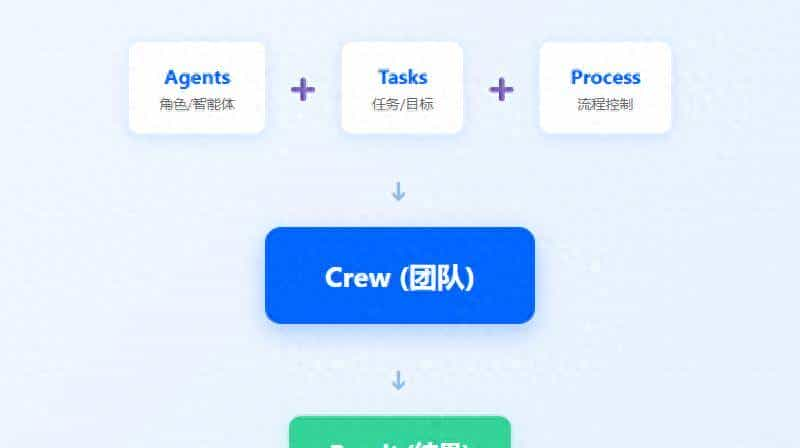
核心功能:真的像在管团队
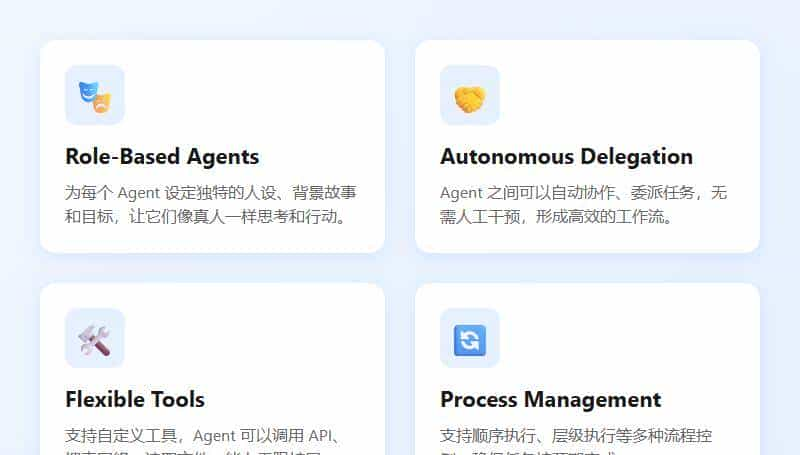
1. 基于角色的设计 (Role-Based)
在 CrewAI 里,每个 Agent 都有自己的人设。
列如你想写个爬虫,你定义的不是”爬虫脚本”,而是一个”高级数据研究员”。 你可以给它设定背景故事:”你是一个对数据极其敏感的专家,擅长从复杂的网页中提取关键信息。”
有了人设,LLM 的表现力会直接提升一个档次。它知道自己是谁,该干什么,不该干什么。
2. 自动协作与委派 (Delegation)
这是最骚的功能。Agent 之间可以相互”甩锅”。
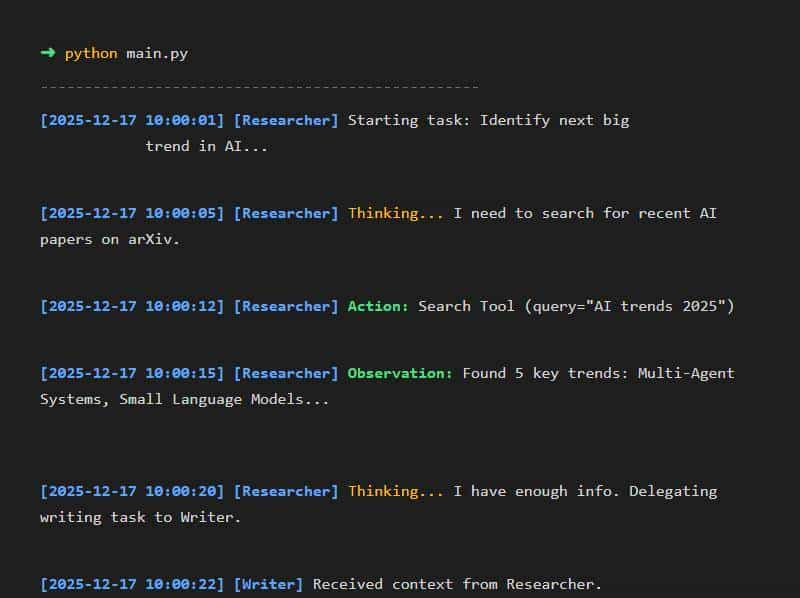
列如”研究员”发现数据太复杂,它自己处理不了,可以自动把任务委派给”分析师”。整个过程不需要你写一行代码去调度,它们自己会在内部”开会”解决。
我看着后台日志里它们相互通过话,真有种在看员工群聊的错觉。
3. Crews 与 Flows 的完美结合
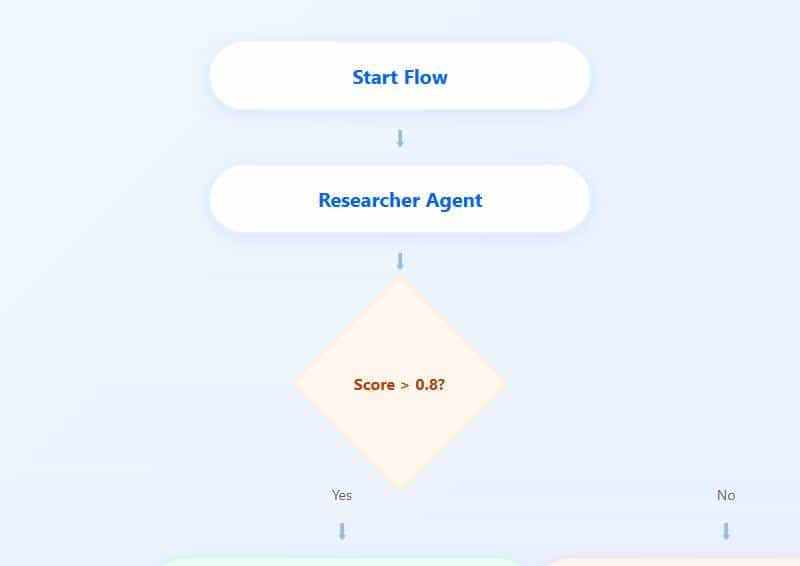
CrewAI 最近推出了 Flows。如果说 Crews 是”团队”,那 Flows 就是”SOP”(标准作业程序)。
你可以定义一个流程:先让”研究员”搜集信息,如果信心分数大于 0.8,直接发给”写手”写文章;如果小于 0.5,打回去重做。
这种事件驱动的流程控制,让它不仅能做 Demo,真能上生产环境。
实战对比:它凭什么吊打 LangChain?
我拉了个表格,把 CrewAI 和其他主流方案做了个对比:
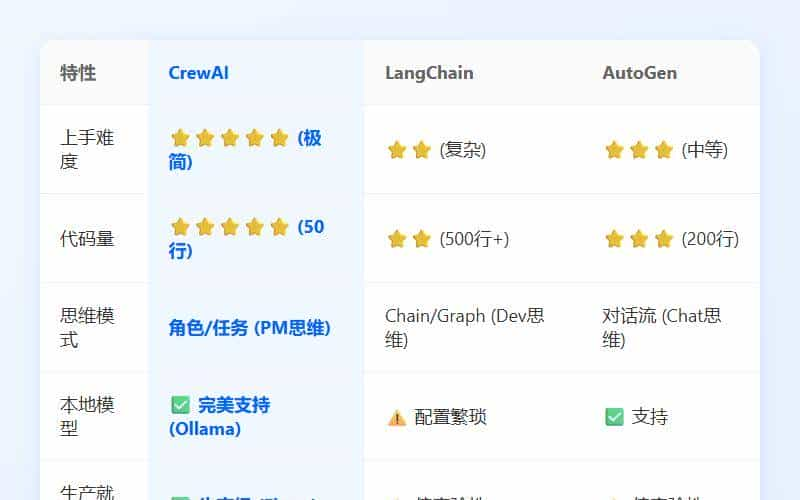
- LangChain:功能最强,但太底层,写起来像在解数学题。
- AutoGen:微软出品,很强,但配置复杂,对话流控制不容易。
- CrewAI:上手最快,逻辑最清晰,最适合快速落地。
实战:10分钟搭一个”竞品分析团队”
别光说不练,看看代码有多简单。假设我们要分析一个 AI 话题:
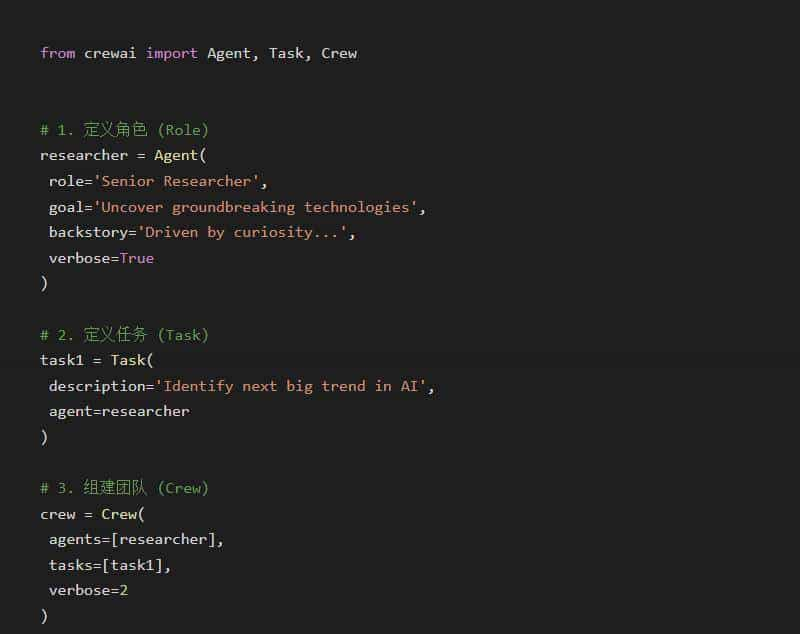
from crewai import Agent, Task, Crew, Process
# 1. 招聘员工(定义 Agent)
# 这里记得把 verbose 打开,能看到它们"吵架"的过程,特有意思
researcher = Agent(
role='高级研究员',
goal='发现 AI 领域的最新突破',
backstory='你是一个对技术趋势有敏锐嗅觉的专家,擅长挖掘被忽视的细节...',
verbose=True,
# memory=True, # 加上这个,它能记住之前的对话,不过有点吃显存
)
writer = Agent(
role='技术博主',
goal='把复杂的技术写成通俗易懂的文章',
backstory='你擅长把枯燥的论文变成 10w+ 的爆款文,文风要幽默...',
verbose=True
)
# 2. 分配任务(定义 Task)
task1 = Task(
description='研究 2025 年 AI Agent 的最新趋势,重点关注 CrewAI',
agent=researcher
)
task2 = Task(
description='根据研究结果,写一篇 1500 字的深度文章,要带 Markdown 格式',
agent=writer
)
# 3. 组建团队开干(定义 Crew)
crew = Crew(
agents=[researcher, writer],
tasks=[task1, task2],
process=Process.sequential # 顺序执行,也能并行(Process.hierarchical)
)
# 4. 启动!
# inputs 可以传参,列如 topic='AI Agents'
result = crew.kickoff()
print(result)看到没?没有复杂的 Chain,没有晦涩的 Graph,就是简单的招人、分活、开干。
本地模型支持:省钱神器
除了接 OpenAI,CrewAI 对本地模型的支持也是一绝。
配合 Ollama,你可以在本地跑 Llama 3 或者 Mistral。

# 只需要一行配置
os.environ["OPENAI_API_BASE"] = 'http://localhost:11434/v1'
os.environ["OPENAI_MODEL_NAME"] = 'openhermes' # Adjust based on available model
os.environ["OPENAI_API_KEY"] = 'sk-111111111111111111111111111111111111111111111111'我在本地跑了个 Llama 3,配合 CrewAI,处理一些隐私数据,速度虽然比不上 GPT-4,但胜在免费且安全。
说实话,也有门槛
吹了半天,也得泼点冷水。这东西毕竟还在快速迭代,我也踩了几个坑:
- 文档有点散:功能更新太快,有时候文档跟不上代码。列如 Flows 的文档,我翻了好久才在 Examples 里找到用法。
- 本地模型吃配置:虽然支持 Ollama,但如果你的显卡显存小于 12G,跑 Llama 3 可能会有点慢,Agent 思考时间会变长。
- Token 消耗:如果不小心开启了 Memory 和详细日志,Token 消耗会比较快,提议测试时用便宜的模型。
最后的提议
如果你受够了 LangChain 的臃肿,或者想快速验证一个 Multi-Agent 的想法,CrewAI 绝对是目前最好的选择。
它把 AI 开发的门槛,从”写代码”降低到了”写剧本”。只要你会通过 Prompt 定义角色,你就能指挥一支 AI 军团。
项目地址:https://github.com/crewAIInc/crewAI
如果这篇文章对你有协助,欢迎点赞、收藏、转发!持续分享前端干货和开源好物,关注我,不迷路~
#AI# #GitHub# #开源# #CrewAI# #Python#
© 版权声明
文章版权归作者所有,未经允许请勿转载。











看过1.0版本的langchain吗?别误导别人
lanhchain成实验性的了?
做玩具当然
收藏了,感谢分享