把应用拆成“有状态”和“无状态”,结果很直接:能不能在流量暴涨时活下来,能不能在节点挂掉时快速恢复,基本都靠这个判断。许多团队最后的经验都是——先把能外置的状态搬出去,剩下必须保留状态的,用有序、稳定的方式去管理。说白了,设计得对,系统能撑;设计得不对,出事儿就很麻烦。

最近几次线上演练都印证了这点。一次电商促销,搜索服务改成无状态之后,扩容速度从几分钟降到几秒,峰值时自动触发扩到上百个实例,延迟还稳定;另一家金融机构把数据库集群按StatefulSet部署,靠着稳定的网络名和持久化卷,即便节点故障也能在短时间内恢复一致性,交易没丢。这两种案例的对比很直接,能说明为什么在云原生里区分状态重大。这不是学术话题,是能看见效果的工程实践。说实话,做到位的人少,光说不练的多。
往前推一步看整个背景。过去单体时代,状态往往被程序嵌在里头,随机器一起跑。分布式普及后,状态问题变成设计要点:谁来保存数据,怎么保证一致性,故障时谁负责恢复。云原生把这些问题带到平台层,Kubernetes也不得不提供一套管理办法。从最早的Pod直接跑,到Deployment管理无状态副本,再到StatefulSet、Headless Service,以及后来越来越多用Operator做自定义生命周期管理,生态是一步步完善起来的。演进的方向很明确:把通用的、可复用的能力上升为平台构件,降低开发运维的重复工作。
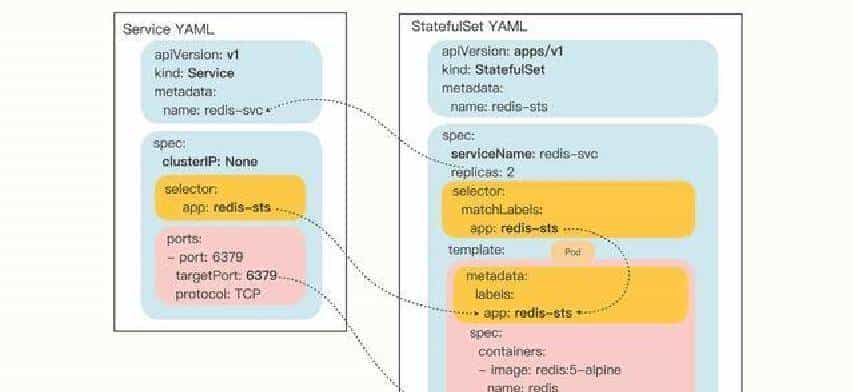
说到定义。无状态应用的核心就是单次请求里能带齐处理所需信息,不依赖本地会话。常见做法是把数据放到外部数据库、缓存、对象存储里,实例之间互不绑死。它的好处显而易见:扩容简单,负载均衡器把流量随意丢给哪个副本就行。部署时一般用Deployment,结合水平自动扩缩(像HPA),并配合共享或临时存储即可。注意,这里“无状态”并不等于完全不用存储,只是不把会话状态绑到本地。许多团队对这一点理解不到位,导致所谓的无状态实则还在某些节点上有隐性状态,扩容时就出问题。改造过程里要把会话和持久化都剥离出去,做一次彻底清理,听起来简单,做起来要花不少工夫。
有状态应用的定义更清楚:请求处理依赖之前的交互或本地持久化,必需保证某些实例有稳定身份、稳定存储和启动顺序。这类应用在Kubernetes里常用StatefulSet来管理。StatefulSet会给每个Pod分配稳定的名字,列如app-0、app-1,和对应的持久卷绑定,保证重启后还能找到自己的数据。配合Headless Service可以实现基于DNS的服务发现,其他组件能按名直接访问到特定副本。由于牵扯到数据一致性、主备选举、同步复制等,扩容和恢复都要按序进行,不能随意扩删。这就带来管理复杂度,需要在设计时就把数据迁移、备份、恢复流程说清楚。
把这两类放在一起对比,差异就在几个维度:数据是否必须本地持久、会话是否需要粘连到同一实例、Pod是否有稳定标识、更新能否并行、扩缩是否可以瞬时等。列如无状态可以线性扩展,实例立刻接手;有状态扩容一般要按序创建,删的时候要逆序,保证数据不会丢。更新策略也不同:无状态常用并行滚动更新;有状态需要顺序升级,保证集群总是有一致的数据副本。这里的细节别小看,升级顺序错了,可能就把整个集群搞崩。
再说具体实现细节。无状态服务的存储模式多是外置化:关系型数据库、分布式缓存、对象存储,这些都放在平台外面或作为共享服务提供。访问层使用普通ClusterIP Service,通过负载均衡分发请求。普遍做法还会配合服务网格,把流量管理、熔断、观测等能力下沉到网格里,给无状态服务更多精细控制。服务网格带来的效果包括细粒度路由、灰度发布、可观测性和安全通信(像mTLS),对微服务治理很有协助。
有状态的存储模式强调持久卷和稳定绑定。每个Pod会通过PVC绑定到PV,保证数据不随Pod的任意重建丢失。网络方面靠Headless Service和Pod的DNS记录来实现稳定访问。复杂的数据库集群往往还需要更多控制逻辑,列如选主、同步延迟检测、快照备份等,这些内容超出了StatefulSet本身的能力。这时Operator就派上用场。Operator是把应用的运维知识写成控制器,定义自定义资源,把复杂的生命周期操作(部署拓扑、升降级、故障切换、备份恢复)自动化。对于需要特定顺序和策略的有状态系统,Operator比原生控制器更灵活也更可控。
实践里两种模式常常混合出现。以电商订单处理为例:前端查询和搜索是无状态的,靠Deployment和缓存做弹性扩缩;订单状态和支付记录放到数据库里,用StatefulSet管理集群,保证持久性和一致性;消息队列用专门的持久化组件做缓冲,作为两者之间的桥梁。这种分层把职责划清,既能利用无状态的弹性,也能满足关键业务的数据一致性需求。具体到某家电商的改造路线,他们先把搜索服务的会话和索引读写分离,使用外部搜索集群和缓存层,搜索节点变成可丢弃的副本,促销当天流量暴增时通过Deployment和HPA在几秒内扩到100多个实例。这一手,工程上要做的事情不少:会话迁移、缓存穿透处理、索引一致性校验、自动化扩容策略调优,任何一项掉链都会影响体验。
在选择策略时,实务上可以把几个问题当成判断依据:数据是否必须长期保存在本地?用户会话是否要求粘连到同一实例?业务在高峰时是否需要秒级扩容?团队能否接受更高的运维复杂度?这些问题回答清楚,后续的设计方向就明确了。迁移时常见做法是分阶段推进:先把易分离的功能改为无状态,验证扩缩和可靠性;再处理数据库集群的现代化,思考引入Operator去自动化管理;最后在全流程里加入监控、告警和恢复演练,确保理论能落地。
值得一提的是,Kubernetes生态并不停止在StatefulSet和Operator上。服务网格、Serverless、以及更多社区贡献的存储插件,都在不断降低把有状态应用放上云原生平台的门槛。现实里没必要把所有东西都改成无状态;目标是把能外置的状态外置,把必须保留的状态用平台原语尽可能稳妥地管理。做工程的,别图省事,把边界和风险都写清楚就行。最后举个细节:在做StatefulSet的滚动升级时,千万不要忽略pod顺序和PV回收策略,一个小配置错误可能会让你恢复丢数据,那可就麻烦了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...