
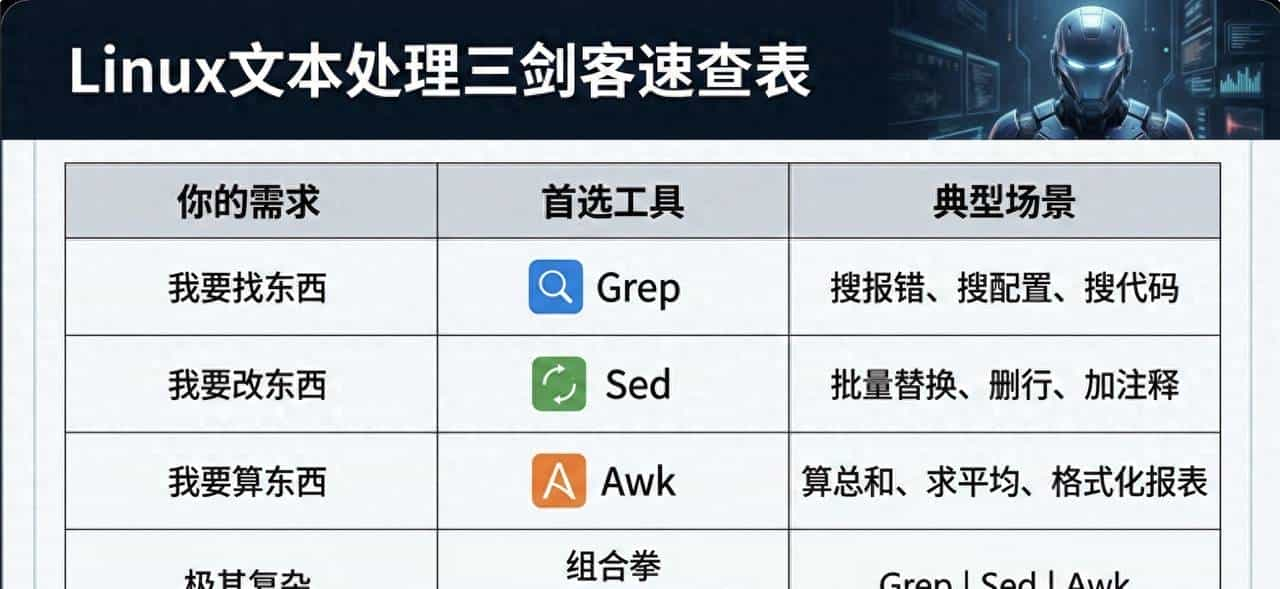
如果你只把 Linux 的 Grep、Sed、Awk 当作三个独立的命令来用,那你可能只发挥了它们 10% 的功力。
在 Linux 的哲学里,真正的威力来自于 “组合”。
这三位“剑客”虽然单兵作战能力极强,但当它们通过 管道符 (|) 连成一条流水线时,原本需要写几十行 Python 脚本才能搞定的复杂数据清洗任务,目前只需要一行命令就能秒杀。
今天,我们不谈枯燥的语法,直接上 3 个真实的生产级实战场景,带你看看它们合体后的“核武级”战力!
核心心法:管道流 (The Pipeline)
在开始实战前,请记住这套**“黄金组合拳”**的逻辑:
Grep (过滤粗选) –> Sed (清洗规范) –> Awk (分析计算)
- 第一步:先用 Grep 甩掉 90% 的垃圾数据,只留相关的。
- 第二步:用 Sed 把剩下的数据“洗干净”,去掉括号、单位等干扰项。
- 第三步:最后交给 Awk 做精细的数值比较或格式化输出。
场景一:Web 日志分析的“黄金搭档”
(Grep + Awk)
痛点:
Nginx 突然大量报警,你需要立即找出今天产生 502 错误 最多的 前 10 个 IP。
日志样本 (error.log):
2025/12/25 16:44:12 [error] 17841#17841: *357623700 connect() failed (113: No route to host) while connecting to upstream, client: 61.129.70.252, server: sywx.redco.cn, request: "GET / HTTP/1.1", upstream: "http://192.168.12.106:80/", host: "sywx.xxxx.cn"
2025/12/25 16:45:11 [error] 17843#17843: *357626385 connect() failed (113: No route to host) while connecting to upstream, client: 61.129.70.252, server: mpos.redco.cn, request: "GET / HTTP/1.1", upstream: "http://192.168.12.105:7385/", host: "mpos.xxxx.cn"
2025/12/25 16:45:15 [error] 17846#17846: *357626707 connect() failed (113: No route to host) while connecting to upstream, client: 61.129.70.252, server: syerp.redco.cn, request: "GET / HTTP/1.1", upstream: "http://192.168.12.99:8280/", host: "syerp.xxxx.cn"✅ 一行命令解决:
# 假设今天是 12月25日
grep "25/Dec/2025" error.log | grep " 502 " | awk '{print $1}' | sort | uniq -c | sort -rn | head -n 10
解析:
- 为什么要用两次 Grep? 虽然 Awk 也能过滤,但 Grep 处理海量文本的速度远快于 Awk。先用 Grep 快速缩小数据范围,是性能优化的关键。
- 流程:选日期 -> 选错误码 -> 提IP -> 排序统计 -> 取前十。
场景二:地毯式重构
(Grep + Sed + Xargs)
痛点:
公司数据库迁移,你需要在一个包含 上千个文件 的项目目录中,找到所有写死旧域名 db.old.com 的配置,批量替换为 db.new.com。
错误做法:
手动打开文件一个个改?那得改到明年。
组合操作:
# 1. 递归查找含旧域名的文件名
# 2. 传给 sed 进行原地替换
grep -r -l "db.old.com" ./project/ | xargs -I {} sed -i.bak 's/db.old.com/db.new.com/g' {}
解析:
- grep -r -l:r 是递归搜索子目录,l 表明只输出文件名(这是关键!)。
- xargs:它是连接“搜索”和“操作”的桥梁,把 Grep 找到的文件名,喂给后面的命令。
- sed -i.bak:强烈提议加 .bak!这会在修改的同时自动备份原文件,万一改错了还有后悔药吃。
场景三:数据清洗 (处理脏数据)
(Grep + Sed + Awk 三位一体)
痛点:
应用日志格式极度混乱,你想找出执行时间超过 2000ms 的慢 SQL。但日志里充满了干扰字符。
脏日志样本:
[INFO] [DB] [DURATION: 1500ms] SQL: SELECT * FROM users WHERE id = 123
[INFO] [API] [DURATION: 5ms] Request: GET /api/users
[WARN] [DB] [DURATION: 2500ms] SQL: SELECT * FROM orders WHERE status = 'pending'
[INFO] [CACHE] [DURATION: 2ms] Cache hit for key: user_123
[ERROR] [DB] [DURATION: 3200ms] SQL: SELECT * FROM products JOIN inventory ON products.id = inventory.product_id
[INFO] [API] [DURATION: 15ms] Request: POST /api/orders
[INFO] [DB] [DURATION: 800ms] SQL: UPDATE users SET last_login = NOW() WHERE id = 456
[WARN] [DB] [DURATION: 2100ms] SQL: SELECT * FROM logs WHERE created_at > '2024-01-01'
[INFO] [API] [DURATION: 8ms] Request: DELETE /api/cache/all
[ERROR] [DB] [DURATION: 4500ms] SQL: SELECT COUNT(*) FROM transactions WHERE amount > 1000
[INFO] [DB] [DURATION: 1200ms] SQL: INSERT INTO audit_logs VALUES (...)
[INFO] [API] [DURATION: 3ms] Request: GET /health
[WARN] [DB] [DURATION: 2800ms] SQL: SELECT * FROM users JOIN orders ON users.id = orders.user_id难点:2500ms 混在括号和单位里,Awk 没法直接拿来做大于 2000 的数字比较。
✅ 清洗流水线:
#!/bin/bash
# 通用日志分析脚本
# 用法: ./analyze_logs.sh <日志文件> [阈值ms]
LOG_FILE=${1:-"app.log"}
THRESHOLD=${2:-2000}
if [ ! -f "$LOG_FILE" ]; then
echo "❌ 错误: 文件 $LOG_FILE 不存在"
exit 1
fi
echo "========================================="
echo " 数据库慢查询分析工具"
echo "========================================="
echo " 分析文件: $LOG_FILE"
echo "⏱️ 阈值设置: ${THRESHOLD}ms"
echo " 文件大小: $(du -h "$LOG_FILE" | cut -f1)"
echo ""
# 提取并分析
grep '[DB]' "$LOG_FILE" |
sed 's/[INFO]//g; s/[WARN]//g; s/[ERROR]//g; s/[DB]//g; s/DURATION://g; s/ms//g; s/SQL://g' |
awk -v threshold="$THRESHOLD" '
BEGIN {
total = 0
slow_count = 0
slow_sum = 0
max_duration = 0
min_duration = 999999
}
{
duration = $1
total++
# 更新最大最小值
if (duration > max_duration) max_duration = duration
if (duration < min_duration) min_duration = duration
# 统计慢查询
if (duration > threshold) {
slow_count++
slow_sum += duration
# 保存前10条最慢的查询
if (slow_count <= 10) {
slow_queries[slow_count] = duration " ms | " substr($0, index($0, "SELECT"))
}
}
# 按时长分类
if (duration < 100) fast++
else if (duration < 500) normal++
else if (duration < 1000) slow++
else if (duration < threshold) warning++
else critical++
}
END {
print "========================================="
print " 统计汇总"
print "========================================="
print "✓ 总查询数: " total
print "✓ 最快查询: " min_duration "ms"
print "✓ 最慢查询: " max_duration "ms"
print ""
print "========================================="
print " 性能分布"
print "========================================="
print " 极快 (<100ms): " fast " (" (fast/total*100) "%)"
print " 正常 (100-500ms): " normal " (" (normal/total*100) "%)"
print " 偏慢 (500-1000ms): " slow " (" (slow/total*100) "%)"
print " 警告 (1000-" threshold "ms): " warning " (" (warning/total*100) "%)"
print " 严重 (>" threshold "ms): " critical " (" (critical/total*100) "%)"
print ""
if (slow_count > 0) {
print "========================================="
print " 慢查询详情 (TOP 10)"
print "========================================="
for (i = 1; i <= slow_count && i <= 10; i++) {
print i ". " slow_queries[i]
}
print ""
print "慢查询平均时长: " (slow_sum/slow_count) "ms"
if (slow_count > 10) {
print "(还有 " (slow_count - 10) " 条慢查询未显示)"
}
} else {
print " 未发现超过 " threshold "ms 的慢查询!"
}
print "========================================="
}'针结日志执行结果
=========================================
数据库慢查询分析工具
=========================================
分析文件: app.log
⏱️ 阈值设置: 2000ms
文件大小: 4.0K
=========================================
统计汇总
=========================================
✓ 总查询数: 8
✓ 最快查询: [ms
✓ 最慢查询: 0ms
=========================================
性能分布
=========================================
极快 (<100ms): 8 (100%)
正常 (100-500ms): (0%)
偏慢 (500-1000ms): (0%)
警告 (1000-2000ms): (0%)
严重 (>2000ms): (0%)
未发现超过 2000ms 的慢查询!
=========================================解析:
这就是组合的魅力!
- Grep 负责聚焦业务领域。
- Sed 负责像剥洋葱一样,把不需要的符号统统删掉,把数据清洗成 Awk 喜爱的空格分隔格式。
- Awk 最后只需要做简单的逻辑判断($3 > 2000)。
如果只用 Awk 硬写正则去匹配那个 2500,代码复杂度会翻倍,可读性也会极差。
该脚本展示了三剑客如何分工协作:Grep 负责过滤异常,Sed 负责数据脱敏,Awk 负责统计计算。
#!/bin/bash
# log_analyzer.sh - Linux 三剑客综合实战脚本(优化版)
# ============================================
# 配置区域
# ============================================
LOG_FILE="${1:-server.log}"
REPORT_FILE="daily_report_$(date +%Y%m%d).txt"
OUTPUT_DIR="./reports"
# 颜色定义
GREEN='33[0;32m'
RED='33[0;31m'
YELLOW='33[1;33m'
BLUE='33[0;34m'
NC='33[0m'
# ============================================
# 前置检查
# ============================================
check_prerequisites() {
# 检查日志文件是否存在
if [ ! -f "$LOG_FILE" ]; then
echo -e "${RED}❌ 错误: 日志文件 $LOG_FILE 不存在${NC}"
echo "用法: $0 [日志文件路径]"
exit 1
fi
# 检查文件是否为空
if [ ! -s "$LOG_FILE" ]; then
echo -e "${YELLOW}⚠️ 警告: 日志文件为空${NC}"
exit 0
fi
# 创建输出目录
mkdir -p "$OUTPUT_DIR"
echo -e "${BLUE} 分析文件: $LOG_FILE ($(du -h "$LOG_FILE" | cut -f1))${NC}"
}
# ============================================
# 主流程
# ============================================
echo -e "${GREEN}╔════════════════════════════════════════╗${NC}"
echo -e "${GREEN}║ 开始执行日志分析流水线 ║${NC}"
echo -e "${GREEN}╔════════════════════════════════════════╗${NC}"
echo ""
check_prerequisites
# 开始记录报告
{
echo "日志分析报告"
echo "生成时间: $(date '+%Y-%m-%d %H:%M:%S')"
echo "分析文件: $LOG_FILE"
echo "========================================="
echo ""
} > "$OUTPUT_DIR/$REPORT_FILE"
# ---------------------------------------------------------
# 1. GREP 环节: 快速定位并过滤异常
# ---------------------------------------------------------
echo -e "${BLUE}[1/4] 正在使用 GREP 提取异常日志...${NC}"
# 创建临时文件(使用 mktemp 更安全)
ERRORS_TMP=$(mktemp)
CLEAN_ACCESS_TMP=$(mktemp)
# 提取多种错误码
grep -E " (500|502|503|504) " "$LOG_FILE" > "$ERRORS_TMP" 2>/dev/null
ERROR_COUNT=$(wc -l < "$ERRORS_TMP")
if [ "$ERROR_COUNT" -gt 0 ]; then
echo -e "${RED}⚠️ 发现 $ERROR_COUNT 个服务器错误!${NC}"
# 统计各类错误数量
echo ""
echo "错误分布:"
grep -oE " (500|502|503|504) " "$ERRORS_TMP" | sort | uniq -c |
awk '{printf " %s 错误: %d 次
", $2, $1}'
# 写入报告
{
echo "【错误统计】"
echo "总错误数: $ERROR_COUNT"
grep -oE " (500|502|503|504) " "$ERRORS_TMP" | sort | uniq -c |
awk '{printf " %s 错误: %d 次
", $2, $1}'
echo ""
} >> "$OUTPUT_DIR/$REPORT_FILE"
else
echo -e "${GREEN}✅ 没有发现服务器错误${NC}"
echo "【错误统计】无错误" >> "$OUTPUT_DIR/$REPORT_FILE"
fi
# ---------------------------------------------------------
# 2. SED 环节: 数据清洗与脱敏
# ---------------------------------------------------------
echo -e "
${BLUE}[2/4] 正在使用 SED 进行敏感数据脱敏...${NC}"
# 创建备份(添加时间戳避免覆盖)
BACKUP_FILE="${LOG_FILE}.bak.$(date +%Y%m%d_%H%M%S)"
# 场景1: 脱敏 token (不修改原文件,输出到临时文件)
# 场景2: IP 匿名化
# 场景3: 去掉多余的标签和单位
# 多重 sed 处理(使用管道更清晰)
sed 's/token=[^ ]*/token=*****/g' "$LOG_FILE" |
sed -E 's/([0-9]+.[0-9]+.[0-9]+).[0-9]+/1.xxx/g' |
sed 's/[INFO]//g; s/[WARN]//g; s/[ERROR]//g' |
grep "GET /api" > "$CLEAN_ACCESS_TMP" 2>/dev/null
CLEAN_COUNT=$(wc -l < "$CLEAN_ACCESS_TMP")
if [ "$CLEAN_COUNT" -gt 0 ]; then
echo -e "${GREEN}✅ 数据脱敏完成: token已隐藏, IP已匿名化${NC}"
echo " 处理了 $CLEAN_COUNT 条 API 访问记录"
else
echo -e "${YELLOW}⚠️ 未找到 API 访问记录${NC}"
fi
# ---------------------------------------------------------
# 3. AWK 环节: 数据统计与报表生成
# ---------------------------------------------------------
echo -e "
${BLUE}[3/4] 正在使用 AWK 生成流量分布报表...${NC}"
if [ "$CLEAN_COUNT" -gt 0 ]; then
echo ""
echo "╔════════════════════════════════════════╗"
echo "║ IP访问统计 (TOP 10) ║"
echo "╠════════════════════════════════════════╣"
printf "║ %-20s │ %8s │ %5s ║
" "IP地址(匿名)" "请求次数" "占比"
echo "╠════════════════════════════════════════╣"
# 增强版 AWK: 计算总数和百分比
awk -v total="$CLEAN_COUNT" '
{
count[$1]++
}
END {
for (ip in count) {
percentage = (count[ip] / total) * 100
printf "║ %-20s │ %8d │ %4.1f%% ║
", ip, count[ip], percentage
}
}' "$CLEAN_ACCESS_TMP" | sort -t'│' -k2 -rn | head -n 10
echo "╚════════════════════════════════════════╝"
# 写入报告
{
echo ""
echo "【流量分布 TOP 10】"
awk '{count[$1]++} END {for (ip in count) printf "%-20s : %6d 次
", ip, count[ip]}' "$CLEAN_ACCESS_TMP" |
sort -k3 -rn | head -n 10
echo ""
} >> "$OUTPUT_DIR/$REPORT_FILE"
fi
# ---------------------------------------------------------
# 4. 终极合体: Grep + Sed + Awk 管道流
# ---------------------------------------------------------
echo -e "
${BLUE}[4/4] ⚡️ 三剑客合体:分析慢 SQL 查询...${NC}"
# 增强版: 统计慢查询并分类
SLOW_QUERY_RESULT=$(grep "[DB]" "$LOG_FILE" 2>/dev/null |
sed 's/DURATION: //g; s/ms//g; s/[//g; s/]//g' |
awk '
BEGIN {
count_2000 = 0 # 2-3秒
count_3000 = 0 # 3-5秒
count_5000 = 0 # >5秒
max_duration = 0
total = 0
}
$3 ~ /^[0-9]+$/ {
total++
duration = $3
if (duration > max_duration) {
max_duration = duration
max_query = $0
}
if (duration > 5000) {
count_5000++
print " 严重慢查询: 耗时 " duration "ms - " substr($0, index($0, "SQL"))
} else if (duration > 3000) {
count_3000++
print " 慢查询: 耗时 " duration "ms - " substr($0, index($0, "SQL"))
} else if (duration > 2000) {
count_2000++
print " 轻度慢查询: 耗时 " duration "ms"
}
}
END {
if (total == 0) {
print "✅ 未发现数据库查询记录"
} else {
print "
【慢查询统计】"
print "总查询数: " total
print "2-3秒: " count_2000 " 条"
print "3-5秒: " count_3000 " 条"
print ">5秒: " count_5000 " 条"
if (max_duration > 0) {
print "最慢查询: " max_duration "ms"
}
}
}
')
echo "$SLOW_QUERY_RESULT"
# 写入报告
{
echo ""
echo "【慢查询分析】"
echo "$SLOW_QUERY_RESULT"
} >> "$OUTPUT_DIR/$REPORT_FILE"
# ---------------------------------------------------------
# 5. 生成汇总报告
# ---------------------------------------------------------
echo ""
echo -e "${GREEN}╔════════════════════════════════════════╗${NC}"
echo -e "${GREEN}║ 分析完成! ║${NC}"
echo -e "${GREEN}╚════════════════════════════════════════╝${NC}"
echo ""
echo -e "${BLUE} 详细报告已保存至: $OUTPUT_DIR/$REPORT_FILE${NC}"
echo -e "${BLUE} 原文件已备份至: $BACKUP_FILE${NC}"
# 显示报告摘要
echo ""
echo "报告摘要:"
cat "$OUTPUT_DIR/$REPORT_FILE" | head -n 20
# 清理临时文件
cleanup() {
rm -f "$ERRORS_TMP" "$CLEAN_ACCESS_TMP" 2>/dev/null
}
trap cleanup EXIT
# 清理临时文件
rm *.tmp errors.tmp 2>/dev/null最后,赠予诸位一言:切勿急于着手编写长达数十行的脚本。当您遭遇复杂的文本处理任务时,不妨暂且停下匆忙的脚步,静心思索一番:是否能够凭借一条管道命令便将问题妥善解决?
倘若本文对您有所助益,烦请点赞并收藏,您的支持是我持续创作的动力。
#三剑客##Linux学习##Linux高级技巧##awk、sed、grep#
© 版权声明
文章版权归作者所有,未经允许请勿转载。













分享精彩,点赞👍🏻
关键是这玩意,学了忘忘了学,反反复复折腾人
是的 不经常用就这样,也很正常
收藏了,感谢分享