
第 1 章 离子通道:地球生命的 “亿年电信号工匠”
从 35 亿年前原始海洋里的单细胞生物,到如今能感知喜怒哀乐、规避危险的人类,离子通道始终是生命体内 “隐形的电信号工程师”。它们趴在细胞膜上,用纳米级的 “分子孔道” 调控钾、钠、钙等离子的流动,为生命搭建起从 “维持生存” 到 “主动感知” 的电信号网络。这个家族不是一夜建成的 “精密工厂”,而是在亿年进化中从 “基础款工具” 一步步迭代成 “多功能军团”—— 每一次结构变异都对应着生命对环境的适应,每一项功能特化都藏着生存的智慧,甚至为神经痛的发生埋下了 “进化伏笔”。
1.1 进化起源:从原核生物的 “基础孔道” 到真核生物的 “功能军团”
生命诞生之初,单细胞生物面临的最大挑战是 “在多变的原始海洋中活下来”—— 盐浓度波动、温度骤变都可能打破细胞内外的离子平衡。正是这种生存压力,催生出了离子通道家族的 “初代工匠”;而随着生命从单细胞向多细胞、从简单向复杂进化,离子通道也随之 “扩招分支”,最终形成覆盖 “信号传递、环境感知、代谢调控” 的功能军团。
1.1.1 35 亿年前的 “初代工匠”:原核生物 KcsA 钾通道的保守结构与维稳功能
在南非巴伯顿绿岩带的古老岩层中,科学家找到了 35 亿年前原核生物(如古菌、蓝细菌)的化石痕迹。通过分子进化分析推测,此时地球上已出现离子通道家族的 “始祖”—— 以大肠杆菌 KcsA 钾通道为代表的 “基础孔道”。它没有复杂的调控结构,却凭一个 “核心技能” 成为原始细胞的 “生存守护者”。
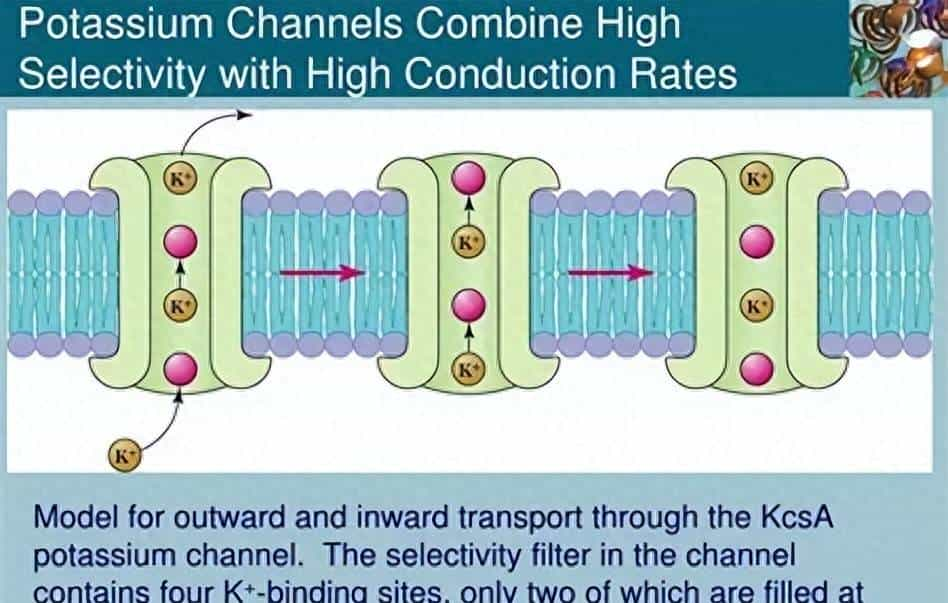
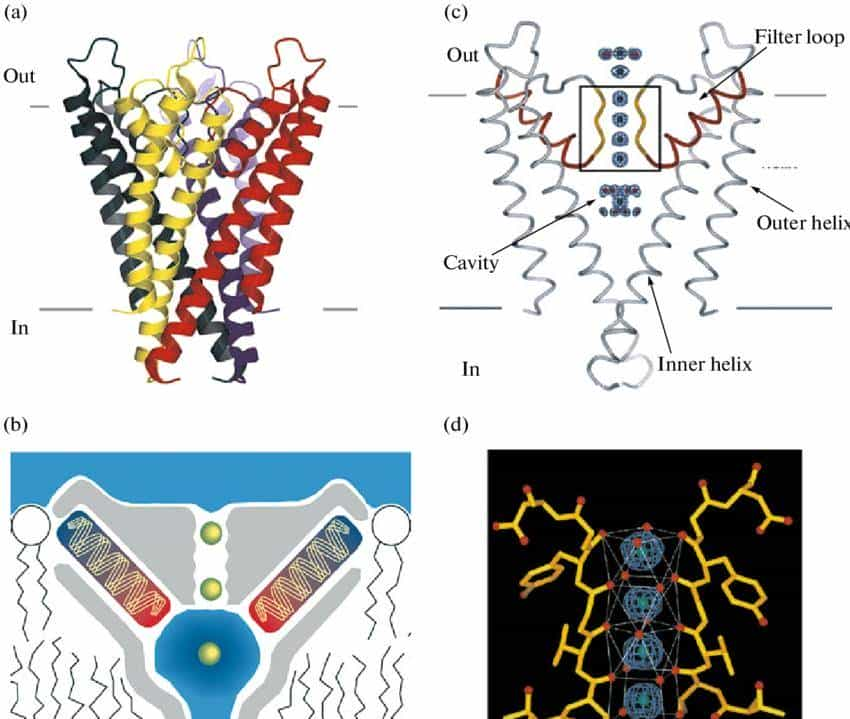
- 保守结构:30 亿年未变的 “分子模具”
- KcsA 钾通道的核心是 “四聚体孔道”——4 个一样的蛋白质亚基像 “四根柱子” 围成一个漏斗状通道,每个亚基包含 2 个跨膜螺旋(M1、M2)和 1 个 “孔道环”(pore loop)。最关键的是,孔道环中藏着一段 “亿年不变” 的氨基酸序列 ——GYG(甘氨酸 – 酪氨酸 – 甘氨酸),它就像 “定制的分子滤网”:
- 钾离子(直径约 0.266nm)进入孔道时,GYG 序列的氧原子会与钾离子形成 “水化层替代键”,帮钾离子脱离水分子的包裹,顺利通过;而钠离子(直径约 0.194nm)因尺寸太小,无法与 GYG 序列形成稳定结合,只能被挡在门外。这种 “只认钾、不认钠” 的选择性,从 35 亿年前的原核生物到如今的人类,在所有钾通道中几乎完全保留 —— 它是离子通道家族 “保守结构守护核心功能” 的第一个铁证。
- 维稳功能:原始细胞的 “渗透压安全阀”
- 对大肠杆菌这样的原核生物来说,KcsA 钾通道的任务很简单:防止细胞因渗透压波动 “脱水死亡”。列如当原始海洋盐浓度突然升高时,细胞外的钠离子会大量涌入,导致细胞内水分流失、皱缩 —— 此时 KcsA 通道会迅速开放,让细胞内多余的钾离子外流,用 “钾离子外排” 抵消钠离子内流的影响,就像 “安全阀” 一样维持细胞内外的离子平衡。实验证明:若人为敲除大肠杆菌的 KcsA 基因,细菌在高盐环境中的存活率会暴跌 90% 以上。对原始生命而言,离子通道不是 “奢侈品”,而是 “保命工具”。
1.1.2 真核生物的 “军团扩张”:离子通道家族的分化(钾、钠、钙、TRP 等)
大约 15 亿年前,真核生物出现 —— 细胞核的形成、内膜系统的分化,让细胞有了更复杂的功能需求,也为离子通道的 “家族扩张” 按下了 “加速键”。如果说原核生物的离子通道是 “单打独斗的小作坊”,真核生物的离子通道就是 “分工明确的大工厂”:从钾通道这个 “老大哥” 出发,通过 “基因复制 – 突变 – 自然选择”,逐渐分化出钠、钙、TRP 等多个分支,每个分支都练就了 “专属技能”。
- 钾通道:从 “基础维稳” 到 “精细调控” 的 “老大哥”
- 钾通道作为家族 “元老”,率先开启 “功能升级”:除了保留原核 KcsA 的 GYG 孔道结构,还新增了 “调控域”—— 列如电压门控钾通道(Kv)多了 “电压感应域”(由 4 个带正电的精氨酸残基组成),能像 “天线” 一样感知细胞膜电位变化:当神经细胞兴奋(膜电位变正)时,电压感应域会随电位变化 “向上翻转”,触发 Kv 通道开放,钾离子外流,让细胞快速恢复平静。
- 还有 “双孔钾通道(K2P)”,新增了 “配体结合域”,能响应炎症介质(如前列腺素 PGE2):当身体出现炎症时,PGE2 会结合 K2P 通道,抑制其开放,减少钾离子外流 —— 这会让细胞更容易兴奋,从而传递 “炎症疼痛” 信号。钾通道的进化,从 “单纯维稳” 变成了 “参与信号调控”。
- 钠通道:脊椎动物特化的 “信号快递员”
- 钠通道的出现是离子通道家族的 “里程碑事件”—— 它并非凭空诞生,而是从钾通道的基因复制后 “改造而来”:保留了钾通道的 “四聚体孔道骨架”,但将每个亚基的跨膜螺旋从 2 个增加到 6 个,其中第 4 个螺旋(S4)带更多正电,形成更灵敏的 “电压感应域”;同时,孔道的选择性序列从 GYG 变成了 “DEKA(天冬氨酸 – 谷氨酸 – 赖氨酸 – 丙氨酸)”,专门筛选钠离子。
- 钠通道的进化,让脊椎动物(约 5 亿年前出现)拥有了 “快速电信号传递” 的能力:人类的感觉神经纤维依靠钠通道 “快速激活、快速失活” 的特性,能将痛觉信号以 100m/s 的速度从指尖传递到大脑 —— 这是低等生物(如水母)无法实现的。如果说钾通道是 “维稳官”,钠通道就是 “快递员”,它的出现直接推动了神经系统向 “高速响应” 进化。
- 钙通道:连接 “电信号” 与 “化学信号” 的 “转换器”
- 钙通道的分化比钠通道稍晚,它同样起源于钾通道,但在 “功能定位” 上更偏向 “信号衔接”:孔道的选择性序列是 “EEEE(谷氨酸)”,专门允许钙离子通过;调控域除了电压感应域外,还多了 “钙调蛋白结合域”,能被细胞内的钙离子 “自我调控”。
- 钙通道的核心作用是 “电信号转化学信号”:列如在神经末梢,钙通道开放导致钙离子内流,会触发突触囊泡释放神经递质(如谷氨酸、P 物质),将 “电信号” 转化为 “化学信号”,实现神经细胞间的通讯;在肌肉细胞,钙离子内流会触发肌肉收缩。对多细胞生物而言,钙通道就像 “桥梁”,让不同组织能通过 “电 – 化学信号” 协同工作 —— 列如心脏的钙通道调控心跳,胰腺的钙通道调控胰岛素分泌。
- TRP 通道:感知环境的 “远古侦探”
- TRP(瞬时受体电位)通道是离子通道家族中 “最古老的环境感知者”,起源可追溯到 10 亿年前的低等真核生物(如果蝇、线虫)。与钾、钠、钙通道不同,TRP 通道的 “特长” 是 “感知多样环境信号”—— 它的孔道结构相对保守,但配体结合域和机械感应域高度可变,能 “解锁” 温度、化学物质、机械力等多种刺激:
- 果蝇的 TRP 通道能感知 “40℃以上的高温”,帮果蝇躲避酷热;
- 线虫的 TRPV 通道能识别 “辣椒素样有毒物质”,帮线虫避开危险植物;
- 人类的 TRPV1 通道除了感知高温(>43℃),还能结合炎症介质(如质子、PGE2),TRPA1 通道能感知低温(<17℃)和甲醛等刺激性物质。
- TRP 通道的进化,让生命从 “被动承受环境” 转向 “主动感知环境”—— 它就像 “远古侦探”,为生物提供 “危险预警”:高温、毒素、机械损伤,这些信号都能通过 TRP 通道转化为离子流动,触发逃避反应。
1.1.3 进化的 “核心法则”:保守结构域守护核心功能,可变结构域拓展适应范围
纵观离子通道亿年的进化历程,能总结出一条 “生存智慧”:保守结构域是 “功能基石”,保证家族的核心技能不丢失;可变结构域是 “进化触角”,协助家族适应新环境、新需求。这条法则不仅解释了离子通道为何能 “代代相传”,也揭示了它们成为 “生命必需品” 的缘由。
- 保守结构域:亿年不变的 “功能保险”
- 所有离子通道的 “孔道结构域” 都高度保守 —— 钾通道的 GYG、钠通道的 DEKA、钙通道的 EEEE、TRP 通道的 “六跨膜骨架”,这些结构在数十亿年里几乎没发生根本性改变。缘由很简单:孔道结构直接决定 “离子选择性”,一旦突变,可能导致通道 “认错离子”(如钾通道变成 “非选择性通道”)或完全失效,这种突变对生物是致命的,会被自然选择淘汰。
- 列如人类的 Kv7.2 钾通道若发生 GYG 序列突变,会导致通道无法开放,引发 “良性家族性新生儿惊厥”—— 患病婴儿出生后会频繁抽搐,这从反面证明:保守结构域是离子通道的 “功能保险”,守护着生命最基础的离子平衡。
- 可变结构域:适应环境的 “进化弹性”
- 与保守的孔道结构不同,离子通道的 “调控域”(电压感应域、配体结合域等)高度可变,这些 “可变部分” 是离子通道 “拓展生存技能” 的关键:
- 为了应对 “快速神经信号”,钠通道的电压感应域进化出 “更多正电残基”,能在 1 毫秒内响应膜电位变化;
- 为了感知 “不同危险信号”,TRP 通道的配体结合域进化出 “多样化结构”——TRPV1 结合辣椒素,TRPA1 结合甲醛,让不同类型的危险都能被捕捉;
- 为了适应 “组织需求”,钙通道进化出 “不同调控亚基”—— 神经末梢的 N 型钙通道带 α2δ 亚基,能更好地与突触囊泡结合;心肌细胞的 L 型钙通道带 β 亚基,能适应心跳的节律性。
- 这些变异不是 “随机试错”,而是自然选择的结果。列如生活在北极的北极狐,其 TRPM8 通道(感知低温)的配体结合域发生突变,对低温的敏感性比温带狐狸低 20%—— 这让北极狐在 – 50℃的环境中不会因过度感知寒冷而痛苦,更利于生存。
1.2 离子通道的 “工作原理”:电信号传递的 “分子开关”
如果把细胞比作 “一座工厂”,细胞膜就是 “围墙”,离子通道就是围墙上的 “智能门”—— 它们能根据外界信号(电压、化学物质、机械力)决定 “开门” 或 “关门”,调控离子流动,进而改变细胞膜内外的电势差(膜电位),产生 “电信号”。这种 “离子流动→电信号→细胞功能” 的过程,是神经感知、肌肉收缩、激素分泌等生命活动的核心,而离子通道的 “工作原理”,本质就是通过 “结构变化” 控制 “离子流动”,驱动电信号的产生与传递。
1.2.1 孔道结构:离子选择性的 “分子滤网”(如钾通道的 GYG 序列)
离子通道的核心能力是 “精准筛选离子”—— 只允许特定离子通过,就像工厂围墙上的 “滤网门”,只放特定尺寸的货物进出。这种 “选择性” 完全由孔道结构决定,不同通道有不同的 “筛选密码”。
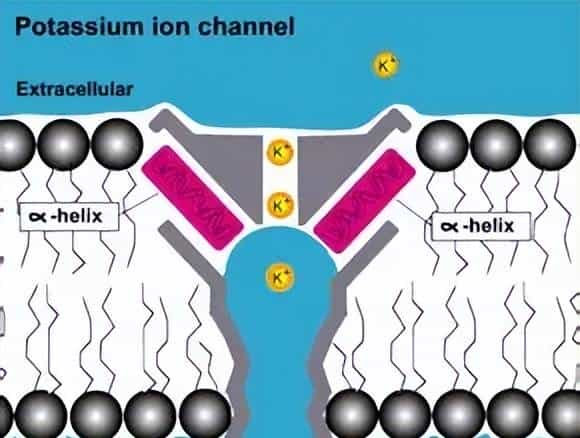
- 钾通道的 “GYG 密码”:只认钾离子的 “专属模具”
- 钾离子(K⁺)和钠离子(Na⁺)都是带正电的离子,但钾通道能精准区分它们:GYG 序列形成的孔道 “狭窄处” 直径约 0.3nm,刚好能容纳 “脱水后的钾离子”(钾离子在溶液中会包裹一层水分子,脱水后尺寸缩小);而钠离子因直径太小(0.194nm),无法与 GYG 序列的氧原子形成稳定结合,只能被挡在门外。这种 “尺寸匹配 + 化学结合” 的双重筛选,让钾通道的离子选择性达到 1000:1(钾离子通透率是钠离子的 1000 倍)。
- 不同通道有各自的 “专属密码”:
- 钠通道的 DEKA 序列:孔道狭窄处由天冬氨酸(D)、谷氨酸(E)、赖氨酸(K)、丙氨酸(A)组成,这些氨基酸的负电基团会 “吸引” 带正电的钠离子,同时排斥钾离子(钾离子的水合层更厚,无法通过);
- 钙通道的 EEEE 序列:4 个谷氨酸提供大量负电荷,能强烈吸引带 2 价正电的钙离子(Ca²⁺)—— 钙离子的电荷密度更高,与负电基团的结合力比钠离子强,因此能优先通过;
- TRP 通道的 “宽松筛选”:多数 TRP 通道是 “非选择性阳离子通道”,允许钠离子、钙离子通过,但有偏好 —— 列如 TRPV1 主要通透钙离子,TRPA1 主要通透钠离子,这与其孔道中的 “选择性过滤器” 氨基酸组成有关。
- 这些 “密码” 是亿年进化的结果,确保细胞能精准调控离子流动 —— 如果钠通道失去选择性,允许钾离子通过,神经细胞就无法产生电信号,信号传递会完全中断。
1.2.2 调控机制:电压门控、配体门控、机械门控的 “进化特化”
离子通道不会 “一直开” 或 “一直关”,它们需要根据外界信号 “按需调控”。这种调控机制主要分三类,每一类都是为了适应特定功能需求而 “进化特化” 的结果。、
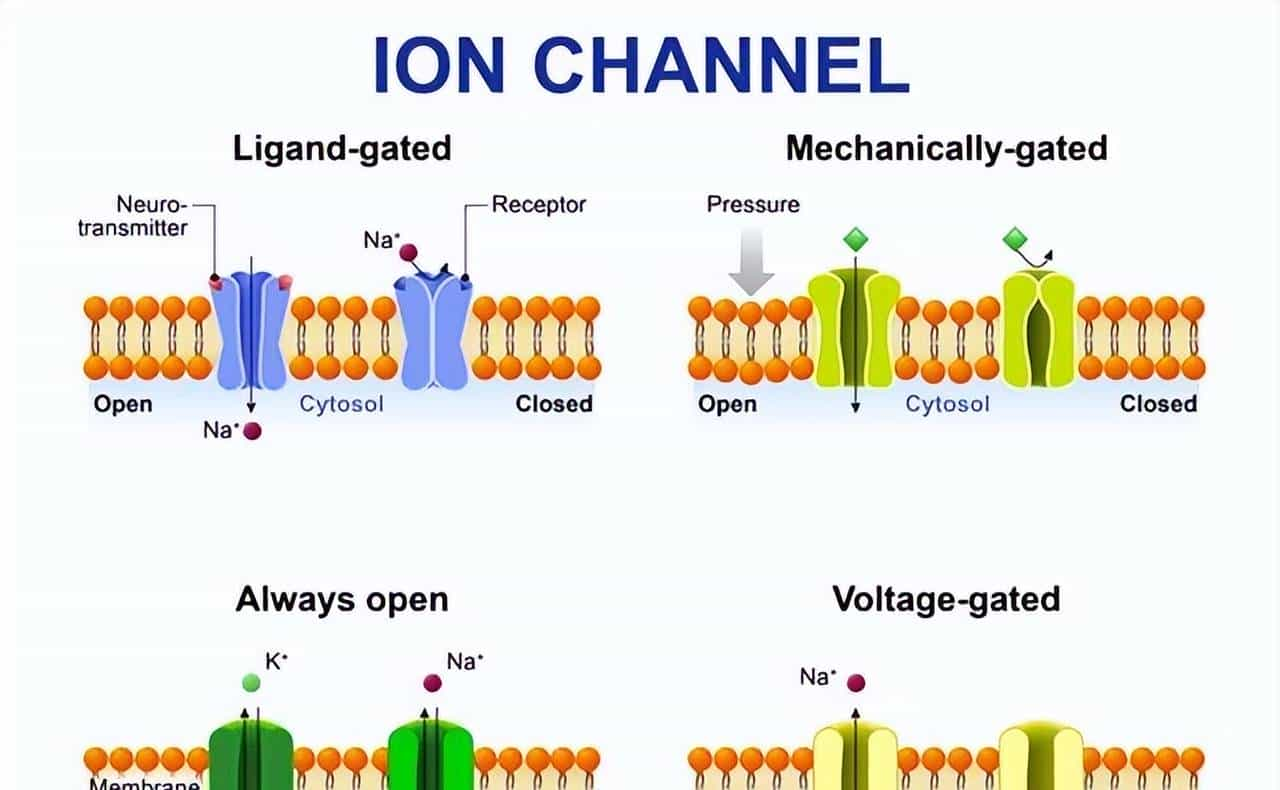
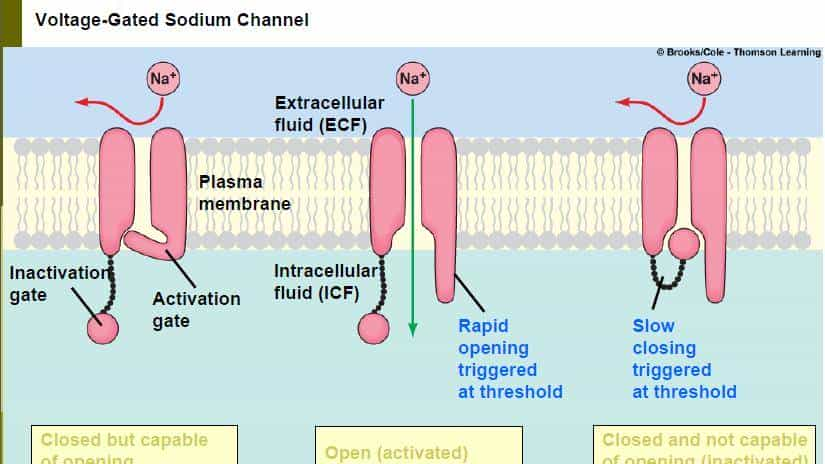
- 电压门控:感知膜电位的 “智能开关”
- 电压门控离子通道(钾、钠、钙通道)的关键是 “电压感应域”—— 由 4 个带正电的精氨酸残基组成,像 “天线” 一样感知细胞膜电位的变化。当膜电位改变时(如从静息电位 – 70mV 变到 – 55mV),电压感应域会因电场变化 “翻转”,带动孔道打开或关闭:
- 钠通道:膜电位达到 – 55mV(阈电位)时,电压感应域向上移动,孔道打开,钠离子快速内流,引发动作电位;1 毫秒后,通道的 “失活域”(一个氨基酸环)会堵住孔道,防止钠离子过度内流;
- 延迟整流钾通道(Kv):膜电位达到 – 40mV 时开始开放,但速度比钠通道慢 2 毫秒 —— 刚好在动作电位峰值时开放,钾离子外流,协助膜电位恢复平静。
- 这种 “快速响应、精准控制” 的机制,让神经细胞能 1 秒内传递 100 次动作电位,确保肌肉快速收缩、痛觉快速传递。低等生物(如线虫)的电压门控通道则简单得多,信号传递速度仅为人类的 1/10。
- 配体门控:响应化学信号的 “分子锁”
- 配体门控离子通道(如 P2X3 受体、GABA 受体)的调控依赖 “特定化学物质(配体)结合”—— 通道上有 “配体结合域”,就像 “锁孔”,只有对应的配体(“钥匙”)插入,通道才会打开。这种机制主要用于 “化学信号→电信号” 的转换:
- P2X3 受体:配体是 ATP(细胞损伤时会释放),ATP 结合后,通道打开,钠离子和钙离子内流,引发感觉神经末梢兴奋,传递 “疼痛信号”;
- GABA 受体:配体是 GABA(中枢抑制性神经递质),结合后通道打开,氯离子内流,让神经细胞超极化,抑制兴奋,起到 “镇痛、镇静” 作用;
- 乙酰胆碱受体:配体是乙酰胆碱(神经肌肉接头的递质),结合后通道打开,钠离子内流,引发肌肉收缩。
- 这种 “特异性结合” 确保只有 “目标信号” 能触发反应 —— 列如 P2X3 受体只认 ATP,不会被其他神经递质干扰,保证疼痛信号传递的精准性。
- 机械门控:感知物理刺激的 “压力传感器”
- 机械门控离子通道(如 TRPV4、Piezo 通道)的调控依赖 “细胞膜机械变形”—— 当细胞受到拉伸、压力、剪切力时,细胞膜变形会带动通道的 “机械感应域”(胞外结构域或跨膜螺旋)“拉开”,进而打开孔道。这种机制用于 “物理刺激→电信号” 的转换:
- TRPV4 通道:能感知 “中等压力”(如皮肤按压、内脏扩张),压力导致细胞膜拉伸时,TRPV4 的胞外结构域像 “弹簧” 一样被拉开,孔道打开,钙离子内流,传递 “机械疼痛” 信号(如腹痛);
- Piezo2 通道:分布在皮肤触觉小体和关节,能感知 “轻微刺激”(如羽毛触碰、关节活动),是触觉和本体感觉的关键 —— 它的机械感应域由 38 个跨膜螺旋组成,像 “桨叶” 一样感知膜变形。
- 机械门控通道的敏感性因物种而异:鱼类侧线器官(感知水流)的通道敏感性是人类皮肤 TRPV4 的 10 倍,这是鱼类适应水生环境的进化选择。
1.2.3 功能本质:维持细胞膜电位,驱动神经信号的 “产生与传递”
离子通道的所有结构和调控机制,最终都指向一个核心 ——维持细胞膜电位,驱动神经信号的产生与传递。细胞膜电位是细胞内外离子浓度差形成的电势差,像 “电池电压”,而离子通道就是 “调节电压的开关”。
- 静息电位:钾通道的 “维稳杰作”
- 神经细胞 “休憩” 时,膜电位稳定在 – 70mV(静息电位),这主要靠 “钾离子外流” 维持:
- 钠钾泵(主动运输蛋白)会把 3 个钠离子泵出细胞、2 个钾离子泵入细胞,让细胞内钾离子浓度(140mmol/L)远高于细胞外(5mmol/L)。此时,“内向整流钾通道(Kir)” 开放,钾离子顺着浓度差外流 —— 当钾离子外流到必定程度,细胞内的负电荷会 “拉住” 钾离子,阻止其继续外流,形成 “电化学平衡”,这就是静息电位。
- 静息电位是神经细胞的 “待机状态”—— 如果 Kir 通道关闭(如高血糖抑制),钾离子无法外流,静息电位会从 – 70mV 变到 – 40mV,神经细胞会 “过度兴奋”,容易产生异常电信号,这正是糖尿病神经痛中 “自发性疼痛” 的缘由之一。
- 动作电位:钠通道与钾通道的 “协同表演”
- 当神经细胞受到刺激(如针扎、神经递质),会产生 “动作电位”—— 神经信号的 “基本单位”,其过程像一场 “离子流动的接力赛”:
- 去极化:刺激让膜电位从 – 70mV 升到 – 55mV(阈电位),钠通道快速开放,钠离子大量内流,膜电位飙升至 + 30mV;
- 复极化:膜电位达 + 30mV 时,钠通道失活关闭,钾通道开放,钾离子外流,膜电位回落至 – 70mV;
- 超极化:钾通道关闭较慢,钾离子过度外流,膜电位短暂降至 – 80mV,随后恢复静息电位。
- 动作电位具有 “全或无” 特性 —— 只要刺激达阈电位,就会产生幅度一样的动作电位,不会因刺激变强而增大;同时,它会沿着神经纤维 “不衰减传递”,就像 “多米诺骨牌”:前一段神经纤维产生动作电位后,会刺激相邻的钠通道激活,推动电信号向前传递。列如手指被针扎时,指尖感觉神经末梢产生动作电位,沿着手臂神经纤维传递到脊髓,再到大脑 —— 整个过程仅需 0.1 秒,让你瞬间感受到疼痛并缩回手指。
1.3 进化视角下的离子通道意义:生命从 “被动适应” 到 “主动感知” 的关键
离子通道的进化,不仅是 “结构的升级”,更是 “生命生存策略的进化”—— 从原核生物的 “被动维稳”,到多细胞生物的 “主动通讯”,再到脊椎动物的 “精准伤害感知”,离子通道每一次功能特化,都让生命更适应环境,也为复杂的神经系统和疼痛感知埋下了 “进化伏笔”。
1.3.1 原核生物:离子通道是 “生存维稳工具”
对 35 亿年前的原核生物而言,离子通道的唯一任务是 “活下去”—— 它们是细胞的 “渗透压调节器”“代谢控制器”:
- 除了 KcsA 钾通道抗渗透压,原核生物的氯离子通道能调节细胞内 pH 值,协助细菌在酸性环境中存活;
- 钙离子通道能调控细菌的鞭毛运动,协助细菌向营养丰富的区域移动。
- 此时的离子通道,还只是 “简单的生存工具”,没有参与复杂信号传递 —— 由于原核生物不需要感知 “疼痛”,只需应对最基础的环境压力。
1.3.2 多细胞生物:离子通道成为 “细胞间通讯枢纽”
大约 10 亿年前,多细胞生物出现 —— 细胞开始分工合作,需要 “通讯工具” 协调功能,离子通道应运而生:
- 海绵动物的钙通道能传递 “收缩信号”,让身体在水流中收缩或舒张;
- 腔肠动物(如水母)的钠通道和钙通道协同工作,传递 “捕食信号”—— 当触手碰到猎物时,离子通道产生电信号,触发刺细胞释放毒液。
- 对多细胞生物而言,离子通道从 “单一维稳工具” 变成 “细胞间通讯枢纽”—— 它们连接起不同细胞的功能,让组织、器官能协同工作,为更复杂的神经系统进化奠定了基础。
1.3.3 脊椎动物:离子通道分化出 “伤害性信号专属传递者”(为神经痛埋下进化伏笔)
5 亿年前,脊椎动物出现,神经系统进一步复杂化 —— 需要 “精准感知伤害” 以规避危险,离子通道随之分化出 “伤害性信号专属分支”,这些分支的特化,既是生存优势,也为神经痛的发生埋下了 “隐患”。
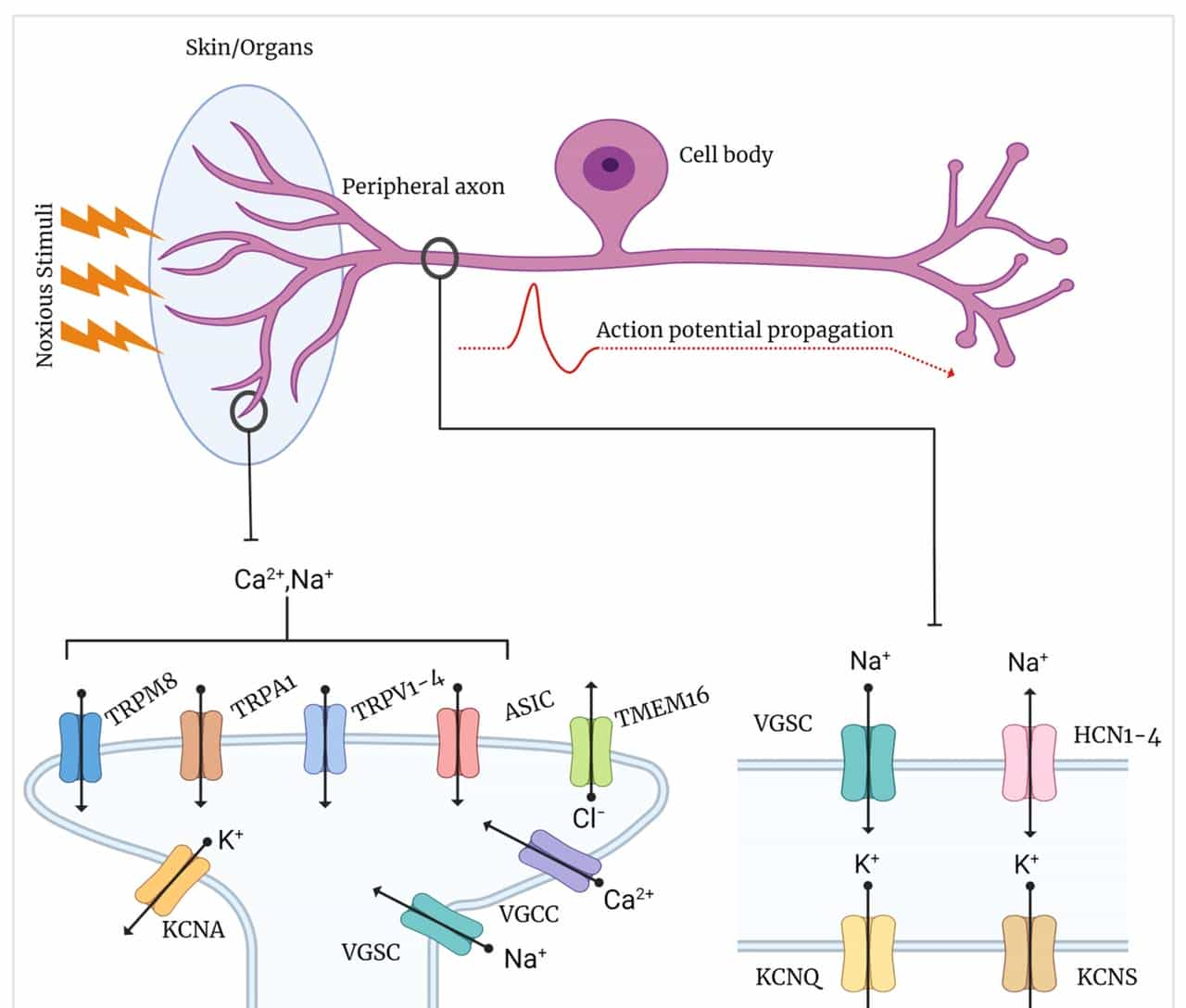
- TRPV1:“高温 + 炎症” 双传感器
- 人类的 TRPV1 通道既能感知 43℃以上的高温(避免烫伤),又能结合炎症介质(如质子、PGE2)—— 当身体出现炎症时,局部组织会释放这些介质,激活 TRPV1,让我们感受到 “烧灼痛”,提醒及时处理损伤。但在神经痛中,TRPV1 会 “过度敏感”:列如糖尿病神经病变患者的 TRPV1 表达量是正常人的 3 倍,对 37℃体温(正常体温)就会产生反应,导致 “自发性烧灼痛”。
- Nav1.7/1.8:痛觉信号的 “专属快递员”
- 脊椎动物特化出 Nav1.7、Nav1.8 等 “感觉神经专属钠通道”—— 它们主要分布在 DRG(背根神经节)感觉神经元,负责传递痛觉信号:
- Nav1.7 能 “快速激活、快速失活”,让痛觉信号快速启动;
- Nav1.8 对局部麻醉药不敏感,能在炎症环境中持续传递信号。
- 这种特化让我们能快速、持续地感知伤害,但在神经损伤后,Nav1.7/1.8 会 “过度表达”:列如带状疱疹后神经痛(PHN)患者的皮肤感觉神经中,Nav1.7 表达量翻倍,即使是衣服摩擦(非伤害性刺激)也会触发动作电位,导致 “触诱发痛”。
- T 型钙通道:“低阈值伤害” 的 “探测器”
- 脊椎动物的 T 型钙通道(如 CaV3.2)主要分布在 DRG 神经元,能被 “低阈值刺激”(如轻微压力、低温)激活 —— 它的进化意义是 “感知轻微伤害,提前规避”。但在神经痛中,T 型钙通道会 “过度激活”:列如化疗诱导神经痛(CIPN)患者的 DRG 神经元中,CaV3.2 表达增加 40%,轻微触碰就会引发钙离子内流,导致 “痛觉过敏”。
- 这些 “伤害性信号专属通道” 的进化,让脊椎动物能更好地保护自己,但当神经损伤打破了它们的 “进化平衡”—— 列如通道过度表达、敏感性增强时,原本的 “保护信号” 就会变成 “病理疼痛”,这正是神经痛的 “进化根源”:离子通道的 “伤害感知功能” 被异常激活,从 “生存优势” 变成了 “痛苦负担”。
本章小结
离子通道是地球生命亿年进化的 “活化石”—— 从原核生物的 KcsA 钾通道到人类的 TRPV1、Nav1.7,它们带着 “保守结构域守护核心功能,可变结构域拓展适应范围” 的进化法则,从 “生存维稳工具” 迭代成 “电信号传递军团”。它们的工作原理围绕 “离子选择性” 和 “精准调控”,最终实现膜电位维持与神经信号传递;而它们的进化意义,更是见证了生命从 “被动适应” 到 “主动感知” 的飞跃。
但正是这种 “主动感知伤害” 的进化特化,为神经痛埋下了伏笔 —— 当离子通道的 “伤害信号传递功能” 因神经损伤而异常激活时,原本的 “保护机制” 会变成 “病理疼痛”。理解离子通道的亿年进化史,不仅能揭开神经痛的机理面纱,更能为药物治疗提供 “顺应进化规律” 的精准策略 —— 列如靶向保守结构域减少副作用,纠正异常通道功能恢复进化平衡。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











