一、产品简介:
同三维T500UHK USB3.2 单路4K60超高清HDMI采集盒具有性能优越、兼容性强、携带方便、安装简单等特点,可采集1路HDMI™视频信号和1路HDMI环出,带1路3.5音频输入+1路MIC输入和1路3.5音频输出。该产品支持8K@60Hz, 4K2K@144Hz输入和环出,以及高达4K@60, 2560×1440@144Hz的视频采集。支持麦克风和线性音频输入以及环路输出,兼容HDMI™数字音频混音采集。USB 3.2 Gen 1信号的传输速率高达5Gpbs。产品符合UVC和UAC标准,即插即用,无需驱动下载和安装设置。

二、产品特点:
1、将HDMI™音视频信号转换为USB 3.2 Gen 1信号进行数据传输
2、支持HDMI™信号输入和环出,分辨率高达8K@60Hz, 4K2K@144Hz,支持HDR
3、可采集无压缩视频4K60fps, 2560×1440@144fps
4、可精准混合HDMI™麦克风音频和线性音频,通过3.5mm模拟音频端口输出或
USB采集端口输出
5、支持多个操作平台:Windows 7/10/11, Mac OS和Linux OS
6、兼容USB 3.2 Gen 1,传输速率达5Gpbs
7、兼容OBS, Streamlabs, Vmix, Zoom, Microsoft Teams等多种软件
8、支持YUY2, NV12, I420, MJPEG视频采集格式
9、即插即用,无需驱动下载和安装设置

三、规格参数:
|
HDCP兼容 |
HDMI™ 2.1 |
|
|
HDCP兼容 |
HDCP 2.3 |
|
|
视频带宽 |
48Gbps |
|
|
USB带宽 |
5Gbps |
|
|
输入&输出 分辨率 |
高达8K@60Hz, 4K2K@144Hz * 全部可支持分辨率见表格下方 |
|
|
色彩空间 |
RGB, YCbCr_4:4:4, YCbCr_4:2:2, YCbCr_4:2:0 |
|
|
色彩深度 |
8/10/12-bit |
|
|
HDMI™ 音频格式 |
最大通道:8通道 采样率 (kHz): 32, 44.1, 48, 88.2, 96, 176.4, 192 数码流:标准&高清 |
|
|
HDR |
HDR, HDR10, HDR10+, Dolby Vision, HLG |
|
|
静电保护 |
IEC 61000-4-2: ±8kV (空气放电) , ±4kV (接触放电) |
|
|
输入端口 |
1× IN [HDMI™ Type A, 19-pin母口] 1× MIC IN [3.5mm音频接口] 1× LINE IN [3.5mm音频接口] |
|
|
输出端口 |
1× OUT [HDMI™ Type A, 19-pin母口] 1× USB-C [USB-C, 12-pin母口] 1× LINE OUT [3.5mm音频接口] |
|
|
HDMI™ 分辨率 |
640x480p60Hz, 800x600p60Hz, 1024x768p60Hz, 1280x1024p60Hz, 1360x768p60Hz, 1440x900p60Hz, 1440x1050p60Hz, 1600x1200p60Hz, 720x480i59.94Hz(480i59), 720x480p59.94Hz(480p59), 720x576i50Hz(576i50), 720x576p50Hz(576p50), 1280x720p50Hz(720p50), 1280x720p59.94Hz(720p59), 1280x720p60Hz(720p60), 1920x1080i50Hz(1080i50), 1920x1080i59.94Hz(1080i59), 1920x1080i60Hz(1080i60), 1920x1080p23.98Hz(1080p23), 1920x1080p24Hz(1080p24), 1920x1080p25Hz(1080p25), 1920x1080p29.97Hz(1080p29), 1920x1080p30Hz(1080p30), 1920x1080p50Hz(1080p50), 1920x1080p59.94Hz(1080p59), 1920x1080p60Hz(1080p60), 3840x2160p23.98Hz(2160p23), 3840x2160p24Hz(2160p24), 3840x2160p25Hz(2160p25), 3840x2160p29.97Hz(2160p29), 3840x2160p30Hz(2160p30), 3840x2160p50Hz(2160p50), 3840x2160p59.94Hz(2160p59), 3840x2160p60Hz(2160p60), 3840x2160p100Hz(2160p100), 3840x2160p120Hz(2160p120), 4096x2160p23.98Hz, 4096x2160p24Hz, 4096x2160p25Hz, 4096x2160p29.97Hz, 4096x2160p30Hz, 4096x2160p50Hz, 4096x2160p59.94Hz, 4096x2160p60Hz, 4096x2160p100Hz, 4096x2160p120Hz 5120x2160p50Hz, 5120x2160p60Hz, 7680x4320p23.98Hz, 7680x4320p24Hz, 7680x4320p25Hz, 7680x4320p29.97Hz, 7680x4320p30Hz, 7680x4320p50Hz, 7680x4320p60Hz |
|
|
UVC分辨率 |
YUY2 |
2560×1440@60及更低的FPS, 1920×1080@60及更低的FPS, 1280×720@120及更低的FPS, 720×576@50及更低的FPS, 720×480@60及更低的FPS, 640×480@60及更低的FPS |
|
NV12/I420 |
2560×1440@60及更低的FPS, 1920×1080@60及更低的FPS, 1280×720@120及更低的FPS, 720×576@50及更低的FPS, 720×480@60及更低的FPS, 640×480@60及更低的FPS |
|
|
MJPG |
3840×2160@60及更低的FPS, 2560×1440@120及更低的FPS, 1920×1080@120及更低的FPS, 1280×720@120及更低的FPS, 720×576@50及更低的FPS, 720×480@60及更低的FPS, 640×480@60及更低的FPS |
|
|
外壳 |
银色铝壳 |
|
|
尺寸 |
114mm [长] × 82mm [宽] × 22mm [高] |
|
|
重量 |
180g |
|
|
供电电源 |
USB供电 |
|
|
电源功耗 |
5.8W(最大值) |
|
|
工作温度 |
0°C ~ 40°C / 32°F ~ 104°F |
|
|
储存温度 |
-20°C ~ 60°C / -4°F ~ 140°F |
|
|
工作湿度 |
20%~80% 相对湿度,无凝结 |
|
|
储存湿度 |
10%~90% 相对湿度,无凝结 |
|
四、电脑配置要求:

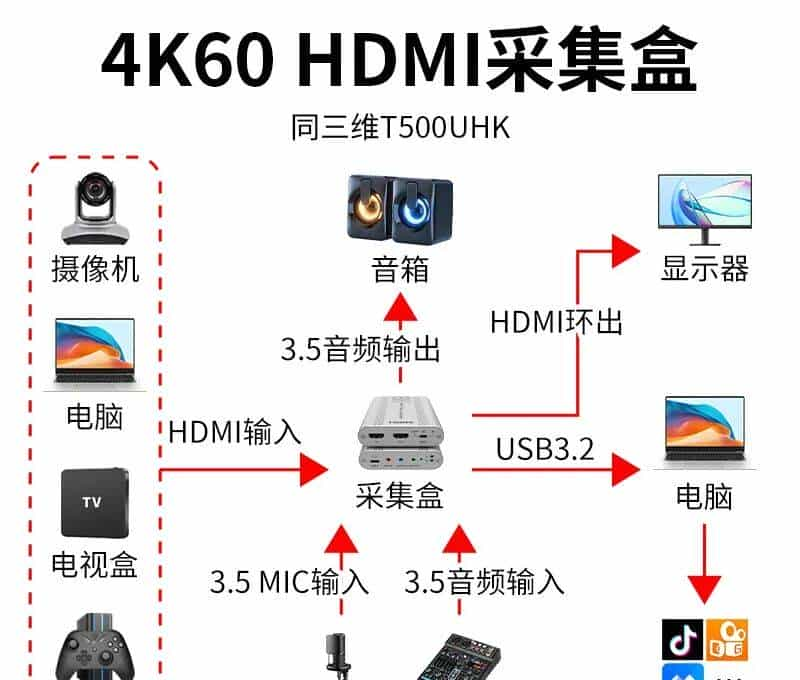
五、产品连接示意图:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...