量能潮指标TT(Turnover Tide)是一个以量能为观察对象的技术指标。我们已经知道成交额是量能的表象,也已经知道量能是态势的外在体现形式,所以,量能潮指标TT就是专用于反映主态势发展演变趋向和态势嬗变动态的技术指标,由这本书首倡。
量能潮指标TT是基于能量潮指标OBV经过超级简单的修改调整而形成的。OBV指标是一个广为周知并且得到了广泛运用的技术指标,咱们介绍TT就从介绍OVB入手。
能量潮OBV(On Balance Volume)也称为平衡成交量、累积能量线,是一种基于成交量并且思考了股价变化方向的技术指标,由美国投资分析师葛兰维尔(Joe·Granville)于1981年提出。中国股市最初通行的看盘软件是钱龙软件,那时候它用的就是平衡交易量这个名称。后来OBV指标受到中国许多业内人士的重点关注和广泛应用,为它起了一个好听、好记又很好理解的中国名:能量潮。有关成交量的技术指标还有一些,OBV是其中最简单却又较为重大的一个。
OBV依据成交量和股价变动方向两种因素,采用简单累加方式获得。它把前一期的收盘价当作基准,把股价上涨看作是人气汇聚的正能量,把股价下跌看作是人气涣散的负能量,用成交量作为计算值,形成了一个超级简单的计算公式:
当期的OBV = 上期的OBV ± 当期的成交量
“期”的概念我们以前多次遇到过,也就是周期。较短的周期可以是多少秒,多少分钟;适中的也是最常用到的周期是交易日;较长的周期是周、月等等。在什么周期做观察、研究,所面对的就是什么期。
公式里的“±”符号表明或者是加,或者是减。成交量当然只能是正值,如果涨了就是正能量,就是加,跌了就是负能量,就是减,当期的收盘价比起上期没有涨也没有跌,走平了,就是0,上期的OBV就直接挪过来作为当期的OBV。
在实际应用中一般要在绘制OBV曲线的同时附加一条平均线,平均线参数的默认值是30,就是取最近30个周期OBV的平均值。平均线能抚平OBV的剧烈波动,清晰呈现出OBV的中期平均水平和中期趋向。
OBV指标的计算公式简单到很难更简单了,所蕴含的道理却十分丰富、深刻。实践证明它真的很好用,所以好用的不必定复杂,复杂的也不必定就好用,这或许就是大道至简的一个例证,就像在中国餐具的进化过程中筷子取代了餐叉一样。
由于实际交易中涨跌参差成交量缩放很频繁,所以OBV曲线常常会充满许多∧形或者是∨形的尖锐波动,呈现为折线形态。为了说起来方便咱们约定,后来分别把这样的急剧逆转称作是尖顶或者是尖底,把这种充满了尖顶尖底的曲线称为折线。
TT脱胎于OBV,所以TT与OBV存在类似之处。但OBV思考的是成交量,TT瞄准的是主态势,这使得它们之间不但有类似,更存在明显的根本差异。
一、 从OBV到TT
TT对OBV做了两处简单改动。
1、 用成交额比值替代了成交量
TT以成交额为基础,成交额中包含有股价因素,也包含有成交量因素,所以,TT直接体现量能,反映态势。
不论从数额还是幅度角度看,股价变化对成交额的影响在一般情况下总是远远低于成交量变化,如果直接把成交额数据放进计算公式,股价变化因素就会在相当程度上被成交量变化因素所遮盖,所以,TT计算公式采用了当期成交额与最近125期平均成交额的比值。取比值能在必定程度上减轻成交量对股价的遮盖影响,以较长周期平均成交额作为基数计算比值,能使得出的结果更敏感地反映成交额的变化特征。同时,态势分析真正关心的并不是成交额的绝对数值,只是成交额的变化方向和变化幅度,这样的替换不会对计算结果造成负面影响,能够满足实用需求。
于是,只要把OBV计算公式中的成交量换为成交额比值,就完成了基本计算公式的转换,也就完成了对指标概念和指标指向的根本扭转。
TT也像OBV那样通过简单叠加得出,这种叠加只是看上去很简单,它的道理实则很深邃。态势的发育和衰退,的确都是在日积月累之下才由量变逐渐发展为质变的,这其中体现的是态势嬗变的本质规律。
就像成交量必定是正值一样,成交额比值也必定是正值。成交量往往有巨大数值,而成交额比值是一个很小的数字,量能放大它会>1,量能萎缩它会<1,量能持平它会接近于1。
2、 增设了一条均线
OBV均线取30周期,把它用于中线操盘参考没有问题,用于短线操盘参考就会觉得它的敏感性太差,过于迟钝滞后。
TT指标保留30周期均线,命名为TT30均线,称为慢均线。增设一条5周期均线TT5,用来反映TT的近期平均水平和近期趋向,也就是用来观察近期的主态势及其变化情况,以适应短线操盘的需要,称为快均线。
这样一来,TT指标就由OBV的一条折线游走在一条曲线上下变成了一条折线运行在两条均线周围。一般情况下TT折线会与快均线靠得比较近,这是快均线敏感性的体现。慢均线变化较为缓慢,这是它稳定性的体现。
两条均线的取值都随时可以方便调整。
在通达信看盘软件K线图画面的任意一处空白区点击鼠标的右键,从弹出的菜单项里选择“指标窗口个数”,进一步选定“3个窗口”,就能在量柱指标下方看到一个副图指标窗口,选定其中的OBV指标,就能调出如图2.13-1所示的OBV指标曲线。

图2.13-1
如果在指标列表中没有找到OBV指标,可以点击指标列表后面箭头指向的“设置”,从弹出界面里的左侧指标列表中寻找并选定OBV指标,点击中部的“=>”键把它放进右侧指标列表,就可以从副图指标窗口下方的列表中看到它了。
点击图中左上角箭头指向的那个图标,在出现的下拉菜单中点击“修改当前指标公式”选项,就会弹出图2.13-2的指标公式编辑器,其中包含了OBV指标公式的源代码和指标公式编辑界面,这是变换指标时需要用到的指标蓝本。
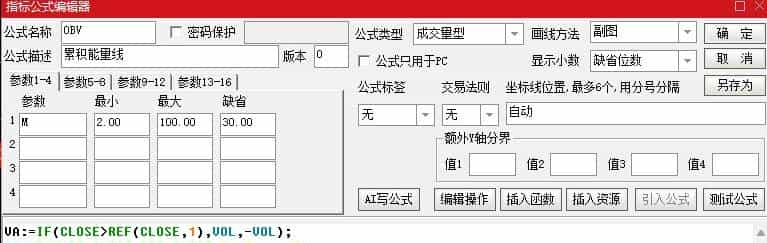
图2.13-2
TT指标的公式的源代码可以在这个界面中的OBV源代码基础上修改生成。
第一重新定义公式名称和公式描述两栏。
然后,在参数区定义两条均线的相应参数:快均线参数M1调整范围是2-20之间,默认值取5,这是一个适用于短线投资参考的调整范围;慢均线参数M2调整范围改变为20-60之间,默认值保留30不变,便于中长线投资者在稍长的周期内调整参数进行观察。
在源程序编辑区,在OBV源程序的第一行前面插入成交额比值计算公式;TT源程序的第二行是在OBV源程序第一行的计算公式中用成交额比值替换成交量修改而成;第三行继续进行后续的相应替换;最后两行分别定义了短、长两条均线。
以这样的改动创建一个新的指标不算很复杂,对吧?改动之后原来的OBV源程序就变成了图2.13-3所示的TT指标公式源代码。
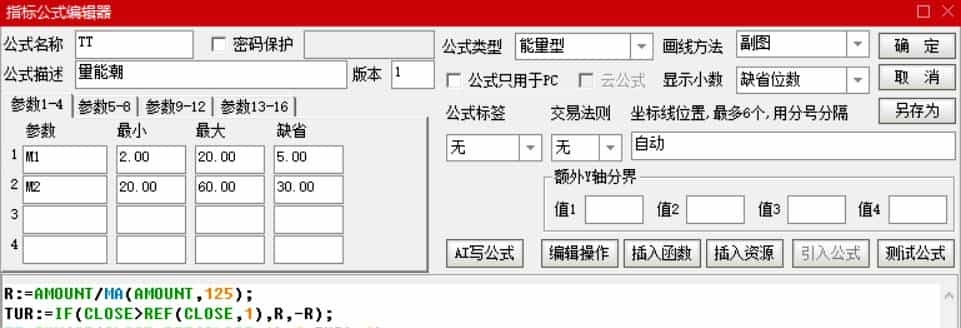
图2.13-3
逐项细心核对,确认所有的改动完整准确无误之后,点击编辑器右上方的“另存为”键,就完成了TT指标公式的录入。
然后,点击图2.13-1下侧中部箭头指向的那个“设置”选项,就会弹出系统设置功能的设置2界面,在左侧选项栏下方找到红色的TT指标,点选它之后点击界面中部的“=>”键,把它放进界面右侧的副图指标栏,TT指标就会立即出目前图2.13-1下方的那个副图指标区。在设置界面的右侧副图指标栏里点选某一个指标之后,点击界面中部的“前移”“后移”键,就能调整这个指标在副图指标区中的位置,让随时调用更加方便快捷。
做完这一切后来点击设置界面下方的“确定”键,就全部搞定可以使用了。
二、 TT指标的基本样态
TT指标由一条波动变化比较频繁,常常会出现尖顶尖底转折的折线和两条起伏波动急缓不同的均线共同构成。
折线也就是TT线,所反映的就是当前即时主态势的指向和变化情况。
波动变化比较快的是快均线,指示较短周期主态势的指向和变化情况;形态比较舒缓平稳的是慢均线,指示较长周期主态势的指向和变化情况。
不论是折线还是均线,向侧上方延伸说明上行态势是相应级别目前正在当家的主态势;向侧下方延伸说明下行态势是相应级别目前正在当家的主态势;呈现大体水平状态,就意味着相应级别的主态势已经进入到休整阶段。
折线在波动中总体上渐渐走缓乃至走平,说明主态势有衰退迹象。如果这种情况发生在指标的高位,不论K线在如何表现,都说明上行态势正在接近于进入休整或者是即将发生逆转。如果这种情况发生在指标的低位,同样,不论K线在如何表现,都说明下行态势正在接近于进入休整或者是即将发生逆转。
如果在某一天,盘中股价以巨大成交额上蹿下跳发生了剧烈震荡,多空双方交锋激烈,但是最终收盘价却和前一天一样,那么,包含有丰富信息甚至可能是关键信息的这一天的盘面情况,就不会在TT中留下一丝一毫痕迹。从态势分析角度看过去,这一天经历了态势的剧烈嬗变,最终多空双方打了个平手,TT只有延伸,没有起伏,这正是当天态势嬗变结果的客观体现,这个结果无疑具有十分明确的意义。
均线也是同样的道理。延伸的倾角越陡,说明主态势的作用越强,获得的补充越多;倾角越缓,说明主态势的作用越弱,消散的速度越快。某一条均线走平,意味着相应级别的主态势已经进入了休整,或许日后还能延续,但是也超级有可能主态势逆转的过程已经开始了。
不要指望TT指标的三条折线曲线之间会出现什么支撑压制之类的现象,它们都完全不讲究那一套。不论主态势是由主力推动用来调动市场的情绪和氛围,还是由市场情绪和氛围所推动,都不会去照顾历史的面子,只会根据当时各方面的具体因素演进。
是否有过除权,是否做复权处理,对于TT的形态甚至对于各条均线的走向以及相互位置关系都会产生明显而重大的影响。除非做复权处理否则没有办法消除这种影响,只能让时间慢慢去抚平它。这不是TT指标的缺陷,任何技术指标面对除权复权都没有办法不受影响。至于是前复权、后复权还是定点复权,不同选择对各种技术指标形态的影响都比较小,在TT也同样。
从TT指标的计算公式我们能清楚知道,股价在涨跌时发生剧烈的突然放量会使成交额比值出现较大值,明显加大TT曲线升降的幅度,发生迅速缩量成交额比值就会远小于1,TT曲线升降的幅度就会显著缩小。另一方面我们知道,推动股价上涨往往会产生放量,消耗巨大的量能;推动股价下跌一般并不需要消耗很大的量能,股价会受到重力规律的作用而下跌。
TT指标在放量时反应敏感鲜明,在缩量时反应迟钝和缓,而放量特别是突然放量常常会发生在股价的上涨过程中,较少会发生在下跌过程中,伴随下跌过程的往往是缩量甚至是快速缩量,这就使得TT对上行态势的变化反映比较灵敏,对下行态势的变化则反映比较迟钝,这不是指标的缺陷,这是现实的客观规律,TT只是如实地反映了这个规律。
在这个客观规律支配下,TT折线、均线在下跌中往往会有粉饰太平的表现,欠缺警示性和震撼感。上涨之后当K线已经在明显下行的时候,由于缩量,TT折线和均线往往还在走平,这显然很容易产生误导。对TT的这些特点,在参考它时心里应该有数。
另外,TT采用累加方法计算,上述现象的日积月累使几乎所有个股的TT曲线都会处在总体上逐渐抬高的过程里,这显然并不意味着所有的个股都在长期走牛。在比较短的时段里,这种现象的影响并不明显,不至于妨碍日常看盘参考形成误导。由于有这样的客观规律存在,所以把30周期均线作为慢均线的取值,要考察更长周期的态势走向可以去周线级别看,以避免受到这个因素的明显影响。
——节录自张纪著《炒股》第二集,《量能潮TT》,发布在《360doc个人图书馆》、《原创力文档》、《道客88》、《百度文库》等网络文库
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...