
引言:
学过数据数据结构都知道二叉树的概念,而又有多种比较常见的二叉树类型,列如完全二叉树、满二叉树、二叉搜索树、均衡二叉树、完美二叉树等;今天我们要说的红黑树就是就是一颗非严格均衡的二叉树,均衡二叉树又是在二叉搜索树的基础上增加了自动维持平衡的性质,插入、搜索、删除的效率都比较高。红黑树也是实现TreeMap存储结构的基石。

一. 二叉搜索树
二叉搜索树又叫二叉查找树、二叉排序树,我们先看一下典型的二叉搜索树,这样的二叉树有何规则特点呢?
1.节点的左子树小于节点本身;
2.节点的右子树大于节点本身;
3.左右子树同样为二叉搜索树;
下图就是一颗典型的二叉搜索树
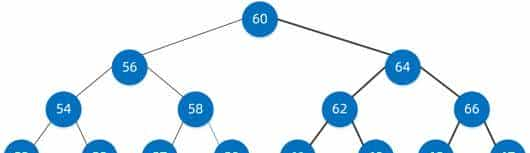
二叉搜索树是均衡二叉树的基础,我们看一下它的搜索步骤如何
我们要从二叉树中找到值为 58 的节点
第一步:第一查找到根节点,值为60的节点
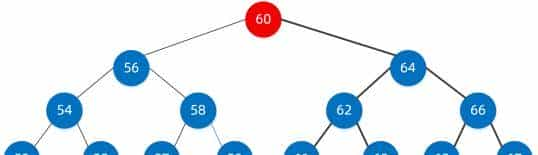
第二步:比较我们要找的值58与该节点的大小
如果等于,那么祝贺,已经找到;
如果小于,继续找左子树;
如果大于,那么找右子树;
很明显58 < 60,因此我们找到左子树的节点 56,此时我们已经定位到了节点56
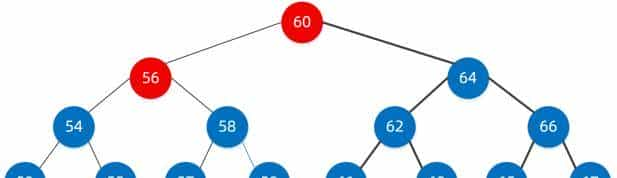
第三步:按照第二步的规则继续找
58 > 56 我们需要继续找右子树,定位到了右子树节点58,祝贺,此时我们已经找到了。
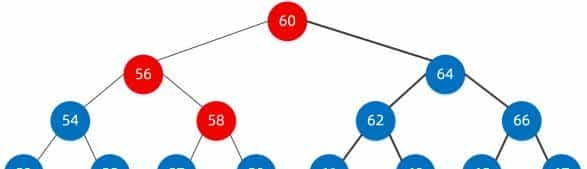
我们经过三步就已经找到了,实则就是我们平时所说的二分查找,这种二叉搜索树好像查找效率很高,但同样它也有缺陷,如下面这样的二叉搜索树。
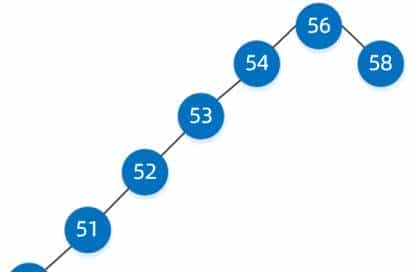
看到这样的二叉搜索树是否很别扭,典型的大长腿瘸子,但它也是二叉搜索树,如果我们要找值为50的节点,基本上和单链表查询没多大区别了,性能将大打折扣。这个时候我们的均衡二叉树就粉墨登场了,均衡二叉树就是在二叉搜索树的基础上添加了自动维持平衡的性质。
上面的大长腿瘸子二叉搜索树经过自动平衡后,可能就成为了下面这样的二叉树。
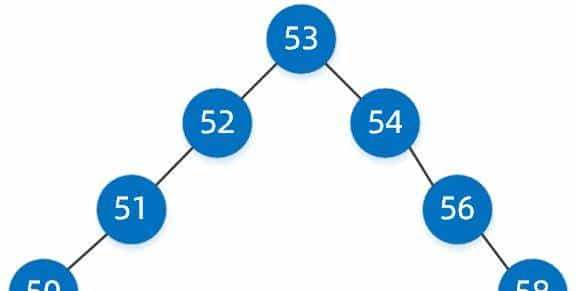
经过了自动平衡,再去找值为50的节点,查找性能将提升许多。红黑树就是非严格均衡的二叉搜索树。
二. 红黑树规则特点
红黑树具体有哪些规则特点呢?
1.节点分为红色或者黑色;
2.根节点必为黑色;
3.叶子节点都为黑色,且为null;
4.连接红色节点的两个子节点都为黑色(红黑树不会出现相邻的红色节点);
5.从任意节点出发,到其每个叶子节点的路径中包含一样数量的黑色节点;
6.新加入到红黑树的节点为红色节点;
规则看着好像挺多,没错,由于红黑树也是均衡二叉树,需要具备自动维持平衡的性质,上面的6条就是红黑树给出的自动维持平衡所需要具备的规则
我们看一看一个典型的红黑树到底是什么样儿?
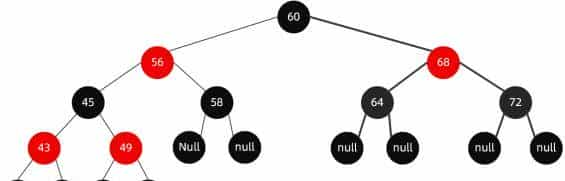
第一解读一下规则,除了字面上看到的意思,还隐藏了哪些意思呢?
第一. 从根节点到叶子节点的最长路径不大于最短路径的2倍
怎么样的路径算最短路径?
从规则5中,我们知道从根节点到每个叶子节点的黑色节点数量是一样的,那么纯由黑色节点组成的路径就是最短路径;
什么样的路径算是最长路径?
根据规则4和规则3,若有红色节点,则必然有一个连接的黑色节点,当红色节点和黑色节点数量一样时,就是最长路径,也就是黑色节点(或红色节点)* 2
第二. 为什么说新加入到红黑树中的节点为红色节点
从规则4中知道,当前红黑树中从根节点到每个叶子节点的黑色节点数量是一样的,此时如果新的黑色节点的话,必然破坏规则,但加入红色节点却不必定,除非其父节点就是红色节点,因此加入红色节点,破坏规则的可能性小一些,下面我们也会举例来说明。
什么情况下,红黑树的结构会被破坏呢?破坏后又怎么维持平衡,维持平衡主要通过两种方式【变色】和【旋转】,【旋转】又分【左旋】和【右旋】,两种方式可相互结合。
下面我们从插入和删除两种场景来举例说明
由于文章过长不能一一上传编写,所以整理成了PDF文档,想要获取的小伙伴的朋友,可以私信我关键字【资料】进行获取。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











