
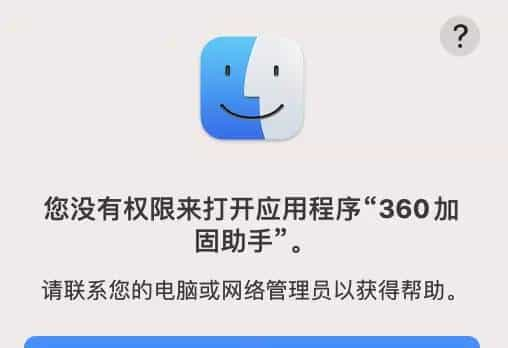
Mac 系统升级到最新后(11.6),原生还能凑合打开的360加固保彻底的打不开了,百度了许多方法,没有尝试成功,下载官网上最新的mac版本的安装包,打开提示“您没有权限来打开应用程序“360加固助手””,如下图:
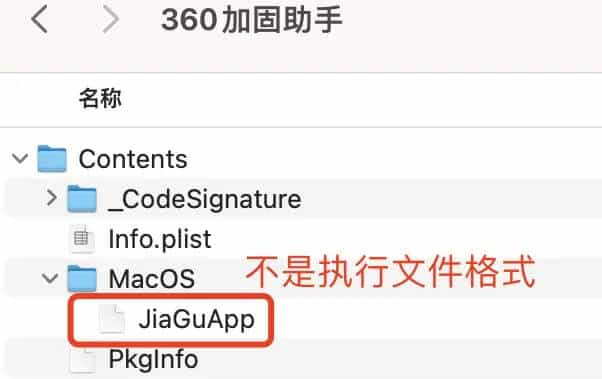
尝试了使用upx 解决,没有成功,在打算放弃时,比对了一下未升级系统前的安装包,发现了一些不一样的地方,360加固助手->显示包内容,MacOS内的jiaGuApp不是执行文件
chmod +x /Users/hn_copote/Downloads/360jiagubao_mac 2/360加固助手.app/Contents/MacOS/JiaGuApp
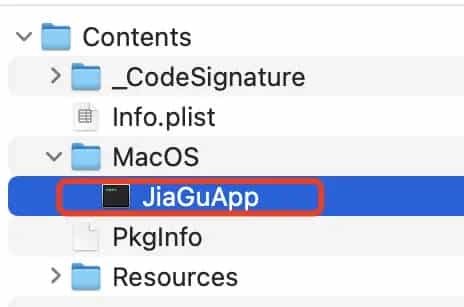
此时点击JiaGuApp,应用可以打开了
还找不开就执行以下
sudo spctl –master-disable
© 版权声明
文章版权归作者所有,未经允许请勿转载。













不行,打不开