
张量成了 AI 的底层骨架。模型里那些“参数”“权重”“注意力矩阵”,无论工程实现还是学术论文,最终都绕回到一个词:张量。像 TensorFlow、PyTorch 这种框架把 tensor 放在最核心位置也不奇怪——它们把数据和计算都看成张量在流动和变形。

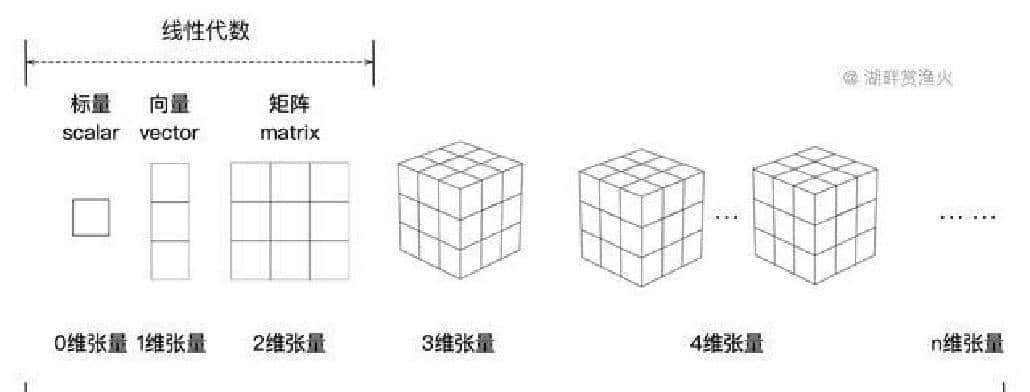
讲清楚前,先把最直观的对比摆出来。数字世界有层次感:一个数就是一个点;一串数是一条线;把线排成表格就是二维;再往上加维度,就成了张量。打个更接地气的比方,Excel 表格很好理解:一张表格是矩阵,把好几张表格摞起来就是三维张量;继续往上摞,就像把一排排书架叠成书库,每多一层就多了一个区分信息的方向。
这不是抽象概念,拍张照片就能看出来。灰度图可以用高度×宽度的矩阵表明;彩色图多了三个通道,变成高度×宽度×颜色,正儿八经的三维张量。视频把时间也算进去,帧数就是一维,常见的就是四维。工程里还会有 batch 这维,channel 那维,形状很快就变成 4D、5D,乃至更多维。每一维都承载不同的含义,越多维就能表明越复杂的关系。
把张量放到模型里看一眼。卷积层的权重不是二维表,一般是四维:输出通道数、输入通道数、核高、核宽。注意力里生成的权重矩阵,按批次和头数分布,常见形状像 batch×heads×seq_len×seq_len。词向量表表面是二维(词表大小×向量维度),但进到编码器后,会被升成三维、四维的数据流。把这些堆起来,模型规模一上去,张量数量和维度呈指数级增长,这也是为什么像 GPT 这种大模型会有千亿、万亿级参数:底层就是各种形状的张量在堆和算。
张量不仅仅是“高维矩阵”。矩阵擅长描述线性变换,向量表达一个方向,张量更强调“关系的关系”。打个工程例子:向量是单个样本的特征,矩阵可以做特征变换,张量则把多样本、多通道、多时间步之间的复杂联系一并装进去。越复杂的关系,越需要多维张量去承载和表达。
模型跑起来时,张量是会动的。输入先被编码成张量,经过每层网络它们会变形、数值会更新、信息被拆分又合并。形状会变,维度会被扩展或压扁,像水在管道里流动、分叉、汇合。TensorFlow 这个名字里就有“张量”和“流”,说的就是这种计算图里张量的流向。PyTorch 里底层也叫 tensor,框架设计把张量放在第一位,能看出大家都把它当作根基。
拿一句话来走一遍流程。把“我爱北京天安门”拆成 token,每个 token 对应一个向量,把向量一列列排开就是矩阵,再加上 batch 就变成三维张量。Transformer 的注意力要算 token 相互之间的关系,会产生多头注意力相关的张量,形状里会出现头数、序列长度之类的维度。多层堆叠后,最初的词向量被一层层投影、混合、还原,最后模型在这些张量变换里算出下一个词出现的概率分布。
卷积网络里也是同理。输入图片是三维张量,卷积核是四维张量,卷积操作把它们合成新的三维张量。池化、激活、归一化,每一步都在改形状、改数值,直到把特征压成分类或回归需要的形式。操作规则不同,但核心都是对张量做线性或非线性变换。
模型规模上来后,看起来复杂的缘由也来自张量。层数多、头数多、序列长、embedding 宽,这些都会让张量维度和数量暴增。工程上要把这些大张量切分到多卡、多机,通信开销、内存布局、数据并行或模型并行策略,都和张量的形状紧密相连。换句话说,真正影响训练效率的,往往不是参数的绝对数量,而是张量怎样排布、怎样移动、怎样被切分。
张量的概念也帮我们理解“信息”本身。矩阵把一组数据规整好,便于做线性运算;张量则把多重关系放到结构里,让模型能在一次运算中并行处理不同维度的互动。图像的颜色、位置、时间,文本的词序、句子层次、语义维度,这些都能用张量的不同维度并行表明和操作。
工程细节不少,值得提一提。大多数库里,张量带着元信息:形状、数据类型、在哪个设备上(CPU/GPU)存放等。常用操作包括切片、广播、重排(reshape、transpose)、合并、拆分。排查 bug 时,打印张量形状是最常用的策略之一;模型设计时,想清楚每一步输出的形状,决定了下一步能不能接受数据。还有内存相关的东西,列如连续性(contiguous)、stride,这些看起来细碎,但在大训练里会直接影响速度和显存占用。
举个小插曲,我第一次跑一个自制 Transformer,卡了一整天,后来才发现只是 batch 维度漏掉了一个 unsqueeze,导致后面几层形状不匹配。那次教训让我养成了随手打印 shape 的习惯,这比盲看参数数量要有效得多。
看论文和读代码时,把注意力从“参数有多少”转到“张量怎么流转、怎么排布、怎么压缩”上,会更有收获。参数是静态的数字,张量才是运行时的血肉。弄清楚张量的形状和流向,许多设计决策的背后逻辑自然就清楚了。列如多头注意力里的维度拆分、卷积核尺寸对空间信息的影响、以及 embedding 表在并行训练里该怎么分片,这些都能从张量角度一眼看懂。
在工程实现层面,还有些常见做法值得提一记。像对大张量做混合精度训练时,要思考浮点格式带来的内存和数值稳定性影响;做梯度裁剪或分布式同步时,通信量和同步模式会直接随张量大小走;做模型压缩或量化时,目标就是把这些张量的存储和计算成本降下来。每一种优化,都是在和张量的形状、类型、布局打交道。
把世界映成张量,并不是数学家的空想。现实数据本来就是多维的,单靠矩阵难以高效表达。张量给了工程师一套直接可操作的语言,让多维信息并行存在并被计算。未来模型怎么扩展、维度会怎么演进,许多线索实则都能从张量的形状和流动里看到。调试模型时,先看看张量的形状,往往能找到那条最靠谱的线索。




















暂无评论内容