
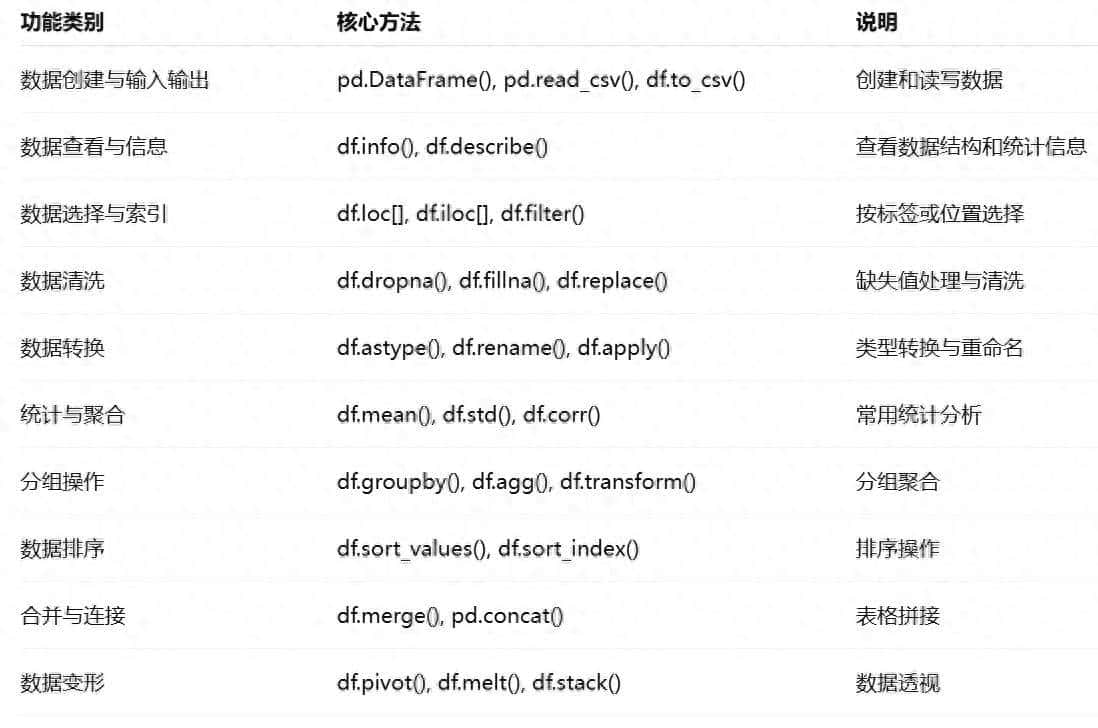
谈到用Python做数据分析,那就少不了对Pandas库引用!针对繁多的函数;我在这里整理了 Pandas 核心功能,覆盖数据读取、清洗等常用方法。希望可以协助到有需要的小伙伴,快速上手项目。
一、数据创建与输入输出
用来“造数据、读文件、存文件”,是任何项目的第一步。
pd.DataFrame(), pd.Series()
pd.read_csv(), pd.read_excel()
df.to_csv(), df.to_excel()技巧:
- pd. 一般用于“读入文件”
- df. 一般用于“输出文件”
- CSV 是最通用格式,Excel 适合展示汇报
二、数据查看与信息统计
数据读进来,第一步要知道它“长啥样”。
df.head(), df.tail(), df.info(), df.describe()
df.columns, df.index, df.dtypes技巧:
- df.head() 看前 5 行
- df.info() 看列名、类型、缺失值
- df.describe() 自动统计平均值、标准差、分布范围
三、数据选择与索引
想取某几行某几列?这几招最常用!
df.loc[], df.iloc[], df.at[], df.iat[], df.filter()技巧:
- loc 是按名字取
- iloc 是按位置取
- filter 可以模糊匹配列名
四、数据清洗与缺失处理
数据不干净?这里是 Pandas 的杀手级功能!
df.dropna(), df.fillna(), df.replace(), df.drop()
pd.isnull()技巧:
- dropna() 删除缺失行
- fillna() 用均值/中位数填补空值
- replace() 替换错误值(如 “—” → NaN)
五、数据转换与重命名
想要统一格式?批量处理列?直接用这些。
df.astype(), df.apply(), df.rename()技巧:
- apply() = 批量应用函数
- astype() = 改类型
- rename() = 改列名(配合字典)
六、统计与聚合分析
一行就能算平均值、相关性、标准差。
df.sum(), df.mean(), df.std(), df.corr()技巧:
- corr() = 变量间相关性
- mean() = 常用于 KPI 平均分析
七、分组与聚合操作
数据分析的灵魂操作,最像 Excel 透视表。
df.groupby(), df.agg(), df.transform()技巧:
- groupby('列') → 按列分组
- agg() → 批量统计,如求和、均值、计数
八、数据排序与合并
数据太乱?轻松排序、拼接表格!
df.sort_values(), df.sort_index()
df.merge(), df.join(), pd.concat()技巧:
- merge() 类似 SQL join
- concat() 纵向拼表
九、数据透视与变形
想做“长表转宽表”?就像 Excel 透视表。
df.pivot(), df.melt(), df.stack(), df.unstack()技巧:
- pivot():行列互转
- melt():压平结构(长表)
十、时间序列与索引管理
Pandas 原生支持时间序列,超级强劲。
pd.to_datetime(), df.resample(), df.shift(), df.rolling()
df.set_index(), df.reset_index(), df.reindex()技巧:
- to_datetime() 转时间格式
- resample() 做时间分组(如按月统计)
- rolling() 做移动平均
十一、总结:一张表看全 Pandas 核心逻辑
#Python##Pandas##数据分析#
© 版权声明
文章版权归作者所有,未经允许请勿转载。如内容涉嫌侵权,请在本页底部进入<联系我们>进行举报投诉!
THE END



















- 最新
- 最热
只看作者