
随着DeepSearch的问世, 我们熟悉的搜索模式,正在发生从传统的网络搜索,转变为智能体搜索(Search Agent)。
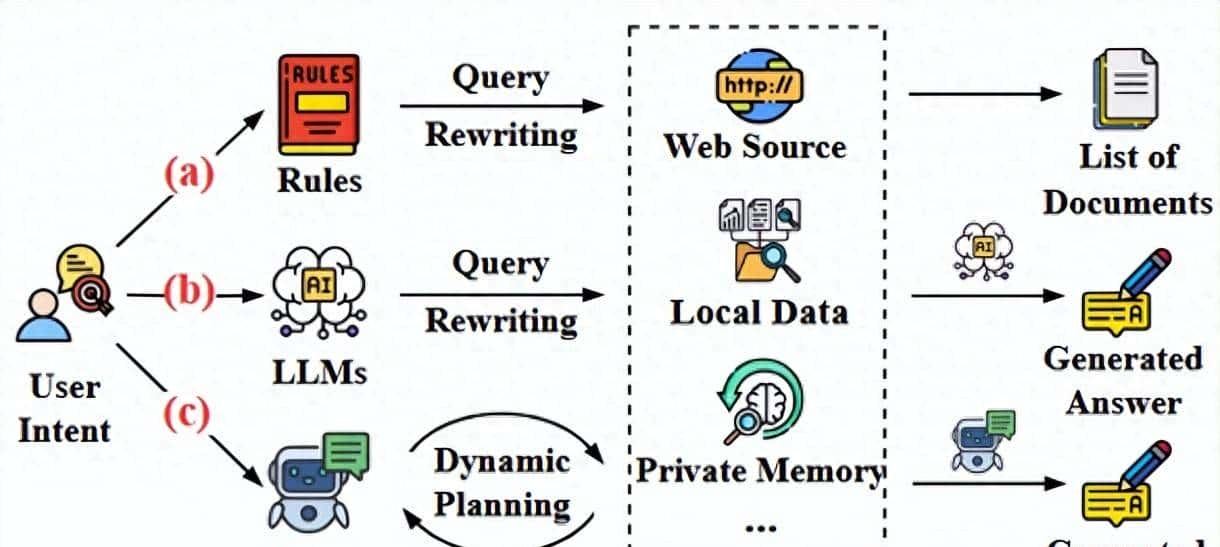
- 传统网络搜索( Traditional Web Search )是我们最熟悉的模式。
- 用户输入查询词,搜索引擎返回一个长长的文档链接列表。
- 用户需要手动点击、阅读、筛选和整合信息。
- 这个过程完全依赖人的判断力和劳动,效率低下且难以处理复杂问题。
- LLM增强搜索(LLM-enhanced Search)以集成了搜索功能的 GPT 为代表,这个阶段引入了大语言模型。
- LLM 可以协助用户改写查询词以提高搜索准确性,或者将搜索到的结果进行总结,生成一个简明的答案。
- 这种模式,也就是我们熟知的“检索增强生成”( RAG ),极大地提升了信息获取的效率。
- 不过,它的交互一般是静态的、单轮的,LLM主要扮演“优化者”或“总结者”的角色,难以应对需要多步骤、动态调整的复杂调研任务。
- 搜索智能体( Search Agent )。
- 搜索智能体标志着:搜索本身变成了一种由AI主导的主动行为。
- 这些智能体被赋予了“自主性”,能够理解用户意图和环境上下文,自主规划搜索策略,从包括:网页、本地数据、私有知识库在内的多样化来源执行多轮动态检索,并整合信息以提供全面洞察的智能体。
一、拆解Search Agent的核心模块
主要围绕何制定任务、如何搜索、优化、应用和评估四个模块来分析。
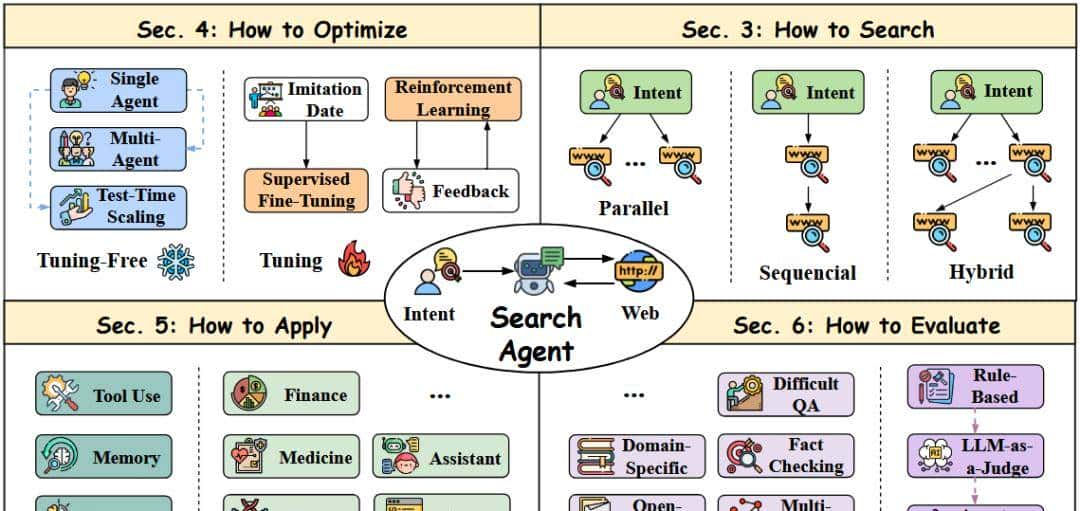
1.1 制定任务
给定用户的意图 和上下文 ,搜索代理会迭代地规划和行动,以收集信息并满足用户的意图。
- 在接收到意图 后,Agent会启动一个规划,构建一个信息查询轨迹
- 每一步,Agent都会反思其当前观察结果 和之前的轨迹 ,更新计划,然后执行一个动作(例如:搜索或浏览某些内容的动作),产生一个新的观察结果
- 此过程持续进行,直到获得足够的信息,形成一系列的观察结果。
- Agent提取并对最相关的数据进行排序,形成一个证据集 ,并生成一个响应 以满足用户的意图。
1.2 搜索
搜索代理的核心在于其能够根据用户意图和环境上下文自主确定其行动,决定何时以及搜索什么。
这种多轮过程代表着向“扩大测试时搜索规模”的重大转变。
因此,传统的单查询已经演变成动态和上下文相关的查询,其中搜索查询由复杂的搜索结构(并行、顺序和混合)和搜索反馈决定。
- 并行搜索(Parallel Structure)
- 基于分解的并行搜索:当用户意图复杂或模糊时,将原始意图分解为更小的子查询,然后并行执行并合成以获得完整的答案。
- 基于多样化的并行搜索:将原始查询重写为一组不同的查询,以便并行搜索。 这种策略确保检索到的内容捕获更广泛的观点和解释。
- 顺序搜索(Sequential Structure)
- 并行结构预先确定所有搜索查询,这使得它不太适应搜索过程中可能出现的意外问题。 相比之下,顺序结构更具动态性和灵活性,允许 agent 根据先前步骤的结果和反思来决定是否以及下一步搜索什么。
- 反思驱动的顺序搜索:采用基于循环的机制,其中智能体执行搜索,根据搜索结果生成答案,然后反思其质量和正确性,迭代直到获得满意的响应。
- 主动性驱动的顺序搜索:智能体根据上下文决定何时触发搜索以及搜索什么,例如,用户意图、搜索结果和之前的推理。 这种动态的顺序决策制定可以通过编码人类设计的启发式方法的提示来指导,从而使智能体能够逐步响应中间结果,进行推理、行动和反思。
- 混合搜索(Hybrid Structure)
- 混合结构结合了并行和顺序范式,能够同时沿多条路径进行探索,从而增加了覆盖正确答案的可能性。
- 基于树的搜索:每个节点代表一个检索步骤,并且在每次迭代中,可以从给定节点并行扩展多个后继节点。 然后通过聚合来自各种路径的结果来选择或合成最终答案,以确定最理想的结果。例如:通过使用扩展函数生成节点并应用蒙特卡罗树搜索(MCTS)算法来采用更动态的策略,最终答案通过投票或奖励模型等机制来选择。
- 基于图的搜索:基于图的结构允许节点之间任意连接,从而使搜索过程能够回溯并修改先前的决策。 一些方法将问题分解为有向无环图 (DAG),识别查询之间的依赖关系并动态地遍历该图
1.3 优化
让Agent表现得更出色,主要有两大优化方向:
- 预设的工作流(workflow)来引导Agent
- 训练Agent使其通过模仿和探索,根据当前上下文自动学习其下一个动作。
1.3.1 预设工作流
- 单Agent架构(Single-Agent):
- 包括:规划、查询生成和最终答案合成。
- 但是,由于单个提示驱动的 agent 难以动态地控制复杂过程的每个方面,因此这些系统一般采用预定义的结构化流程。
- 例如,一些工作涉及一个 迭代细化循环,即,agent 第一搜索,然后生成答案,评估其质量,最后决定是否进一步搜索。
- 多Agent架构(Multi-Agent):
- 多智能体架构将复杂的搜索任务分解并分配给专业的代理。
- 常见角色包括:规划者代理,控制流程并终止;搜索代理,从外部来源收集证据;以及生成代理,综合最终答案及收集的证据;
- 一些工作还涉及浏览器代理;评估者代理以及记忆代理
- 在流程控制方面,大多数解决方案采用固定的执行顺序,其中一个代理在完成时将其输出传递给下一个代理
- 测试时缩放(Test-time Scaling)
- 测试时缩放通过在推理期间分配更多计算来提高代理性能,以提升任务性能。
- 搜索代理与外部环境交互,通过增加与外部环境的交互次数,以更好地探索外部知识。例如:用自洽性(SC)、最佳N(BoN)和蒙特卡洛树搜索(MCTS)来实现最终结果。
1.3.2 基于微调的方式
- SFT微调
- 蒸馏,其中通过对强劲的教师模型进行精心提示生成的数据被转移到较小的学生模型
- 自我提升,涉及在通过拒绝采样过滤的自我生成的高质量轨迹上进行迭代再训练
- RL 训练准备,其中 SFT 充当一个关键的热身,以用必要的运行先验初始化模型
- 包含高质量推理和搜索轨迹或动作的数据集上直接训练 LLM,从而将这些能力内化到模型中。
- 例如,查询重写和反思,或者完全的端到端推理-搜索流程。
- SFT 主要服务于几个关键角色:
- RL强化学习
- 使用 RL 优化搜索代理的一个关键方面是构建多目标奖励函数。
- 虽然格式遵从性和答案正确性是几乎无处不在的奖励组成部分,但常常集成的其他目标包括:效率、多样性、证据质量和检索增益,此外,一般会加入对冗余和长度的惩罚,以完善行为。
- 这些奖励很大程度上依赖于基于规则的验证、基于结果的奖励模型 (ORM) 和基于过程的奖励模型 (PRM)。
- 基于规则的奖励适用于可验证的结果,例如,具有标准答案的问题。
- ORM 一般使用 LLM 来判断没有标准答案的结果。
- PRM 评估搜索轨迹中每个单独步骤的效用
- 混合方法
- 使用 SFT 作为 RL 阶段的热身阶段,协助模型适应任务并纠正格式,为 RL 训练提供良好的初始化。
- 进一步优化可以在 SFT 和 RL 之间实现了一个迭代训练循环,其中 SFT 使用来自先前 RL 迭代的高质量 rollouts 进行优化,为下一个 RL 训练周期提供增强的初始化。
1.4 应用
- 工具的使用:智能体搜索通过多轮推理和搜索提供了一个解决方案,从而实现更动态和准确的工具选择
- 记忆:随着用户交互的积累,智能体的记忆可能会变得庞大而难以处理。 有效地导航这些信息以查明内容是智能体搜索擅长的另一个领域。 智能体搜索可以从复杂和模棱两可的用户意图中提取查询,然后在智能体的记忆中进行深度搜索,以检索高度相关的信息
- 推理:智能体搜索可以从这个内部储存库中动态地检索相关经验,将它们与外部获取的知识相结合,以促进更强劲和更有见地的推理。
https://export.arxiv.org/pdf/2508.05668v1
© 版权声明
文章版权归作者所有,未经允许请勿转载。如内容涉嫌侵权,请在本页底部进入<联系我们>进行举报投诉!
THE END




















暂无评论内容