V4预览版刚上线一天多,代码能力成了最炸的卖点。内部测评说体验超过Sonnet 4.5,交付质量接近Opus 4.6非思考模式。
世界知识测评也大幅领先其他开源模型。但第三方用户普遍反馈体感更偏工程向,复杂的逻辑推理还是得等思考模式出来才稳。那些指望V4一出就把Claude和GPT摁在地上摩擦的,目前来看还不太现实。
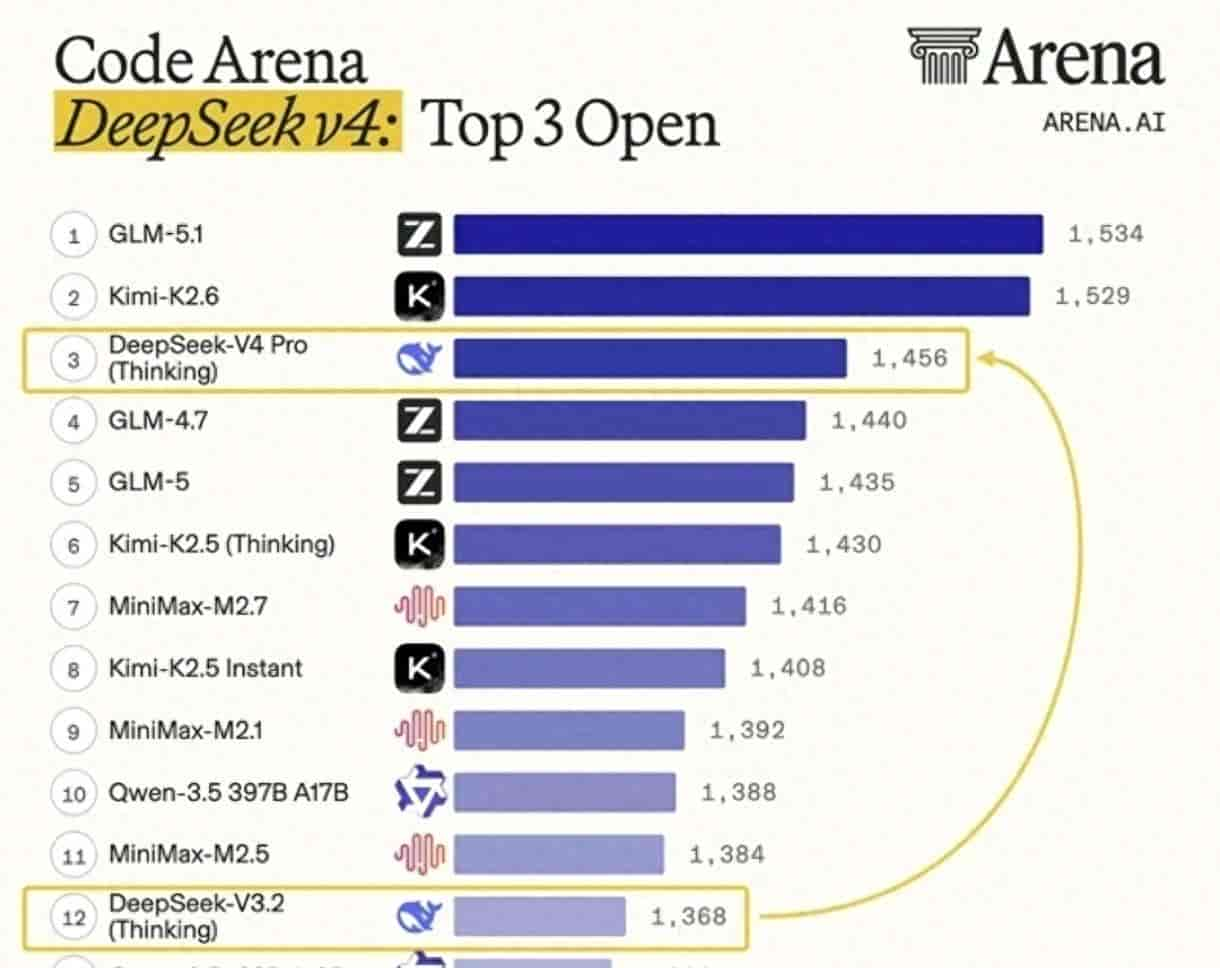
从公布出来的数据看,V4-Pro-Max在竞赛数学基准HMMT拿到95.2分,跟Opus-4.6 Max的96.2分只差了1分,紧追顶级闭源模型梯队。但不管是内部数据还是民间测评,都承认它跟Opus 4.6的思考模式依然有差距。
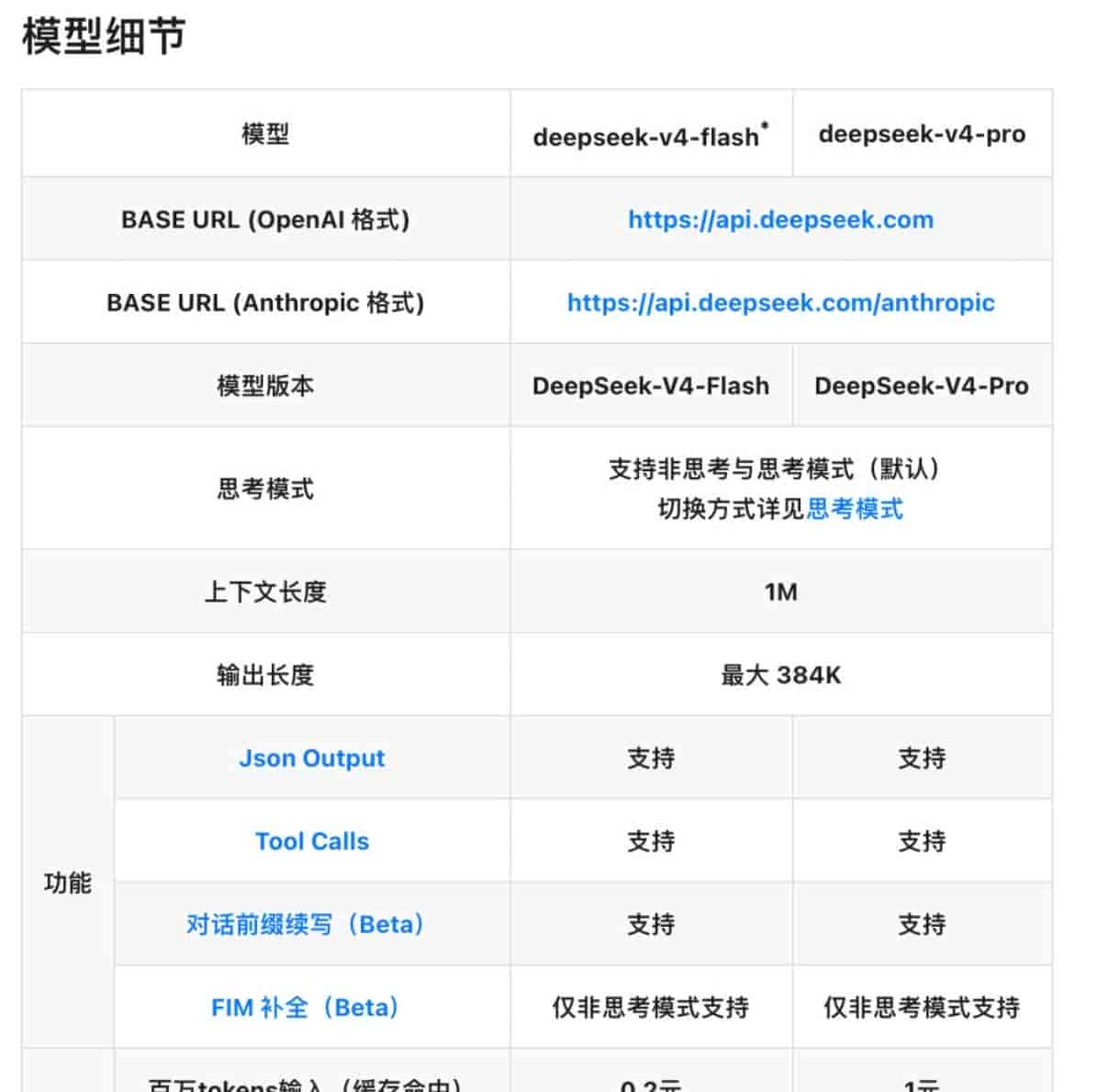
百万上下文早就成了标配,各家都一样。V4这次定价的确 有杀伤力,成本压到极致。但想成为“Claude杀手”,光靠便宜还不够,推理能力里那种“机灵感”,是最难抄作业的部分。希望下次迭代能把思考模式的短板彻底补齐。

#头条创作训练营##DeepSeek##GPT#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...