横评四大AI模型:Gemini、GPT、Claude、Grok到底该用谁?
一、为什么需要多模型对比?
– 不同模型在不同任务上各有优势,像工具箱里的不同螺丝刀,面对同一需求,选择不同工具能显著提升效率与效果。
– 通过同一平台、同一环境对比,可以清晰观察到各自的强项与短板,协助个人或企业在具体场景中做出更精准的取舍。
二、评测设置说明
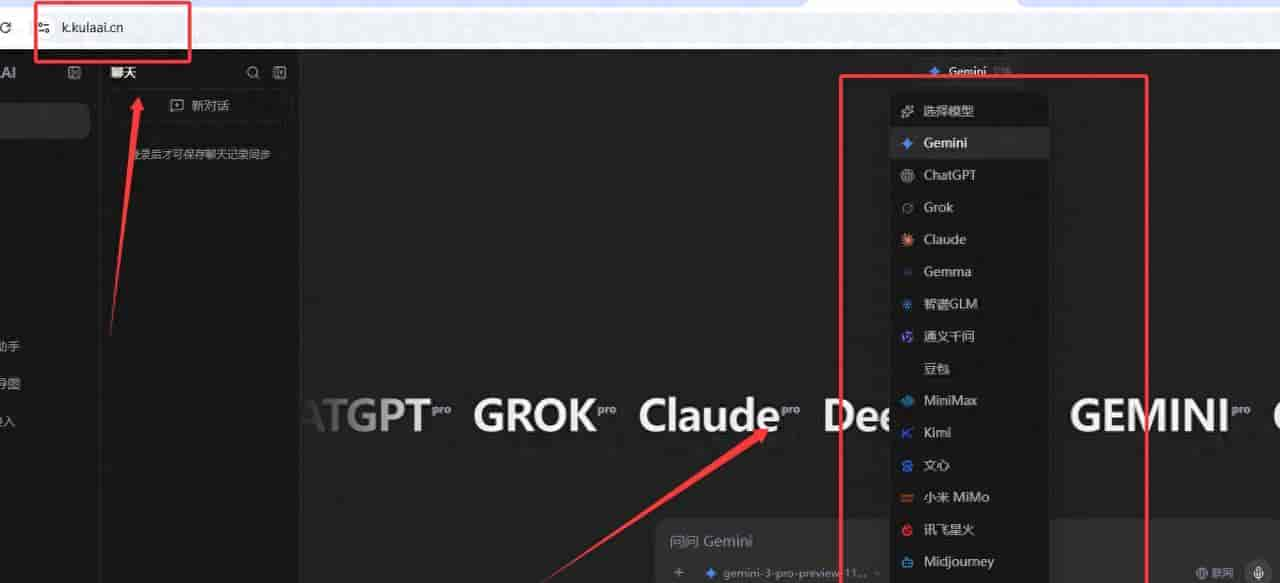
– 测试平台:KULAAI(k.kulaai.cn),确保网络环境与任务输入一致。
– 测试时间:2026年4月中旬。
– 评测维度:
1) 长文本处理能力(10,000字以上)
2) 多模态识别能力(文本/图表/手写等混合输入)
3) 代码Debug能力
4) 创意文案变现力
5) 逻辑推理与陷阱题处理
6) 实时信息查询能力
7) 多轮对话记忆与连贯性
8) 中文古诗词理解与分析
三、八大场景实测得分
在本次评测中,四款模型在不同场景的表现各具特色,下面给出每项场景的测评结果。
– 场景1:长文本处理能力
– 场景2:多模态识别能力
– 场景3:代码Debug能力
– 场景4:创意文案变现力
– 场景5:逻辑陷阱题
– 场景6:实时信息查询
– 场景7:多轮对话记忆
– 场景8:中文古诗词理解
分场景记录:
场景一:长文本处理能力
– 测试题:上传一篇约1.2万字的行业研究报告,要求用300字总结核心观点,并列出5个关键数据。
– Gemini 3 Pro:9.4,摘要全面、关键数据提取准确,能把细节要点完整覆盖。
– GPT-4o:9.1,概括到位,但对某些边缘趋势描述略显简略。
– Claude 3.5:9.3,结构清晰、分析细腻,但速度略慢。
– Grok-2:8.6,摘要简洁但对部分数据点覆盖不全。
长文本摘要这项里,Gemini 3 Pro最全面,Claude 3.5最严谨,GPT-4o最均衡,Grok-2最快但不够完整。
场景二:多模态识别能力
– 测试题:上传含手写笔记的会议记录照片与一张复杂数据图表。
– Gemini 3 Pro:9.6,手写识别较准,图表趋势对比判断清晰。
– GPT-4o:8.4,手写识别仍有提升空间,图表理解基本正确。
– Claude 3.5:7.9,手写识别较弱,但图表分析较稳健。
– Grok-2:7.2,手写识别能力有限,图表标签识读较多受限。
多模态识别方面,Gemini 3 Pro综合最强,GPT-4o基本够用,Claude 3.5偏重图表分析而手写较弱,Grok-2在手写和复杂图表上都相对吃力。
场景三:代码Debug能力
– 测试题:给定一段存在内存泄漏风险的代码,要求定位并给出修复方案。
– Gemini 3 Pro:9.2,定位准确,给出智能指针替代方案并附解释。
– GPT-4o:9.0,定位准确、修复思路偏常规(如手动释放)。
– Claude 3.5:9.5,不仅定位,还分析了潜在的并发风险,给出优化代码。
– Grok-2:8.1,能指出问题,但修复代码存在语法问题。
代码 Debug 场景里,Claude 3.5综合最强,Gemini 3 Pro和GPT-4o都很稳,Grok-2能定位问题但修复质量还有差距。
场景四:创意文案变现力
– 测试题:为轻食品牌撰写抖音口播文案,限时15秒内抓人、促转化。
– Gemini 3 Pro:9.0,给出多版本方案,覆盖不同人群痛点与行动号召。
– GPT-4o:9.4,专业性强,数据支撑有力,但情感共鸣略显不足。
– Claude 3.5:8.6,偏知识科普取向,情感表达不够强烈。
– Grok-2:9.3,风格具冲击力、口语化强,传播潜力突出。
内容创作方面,GPT-4o最专业扎实,Grok-2最有传播感,Gemini 3 Pro最均衡,Claude 3.5则更偏知识型表达。
场景五:逻辑陷阱题
– 测试题:“所有的鸟都会飞,鸵鸟是鸟,所以鸵鸟会飞。这个推理对吗?为什么?”
– Gemini 3 Pro:8.9,指出前提错误,逻辑形式正确但结论不成立。
– GPT-4o:9.4,解释可证伪性,推理过程清晰。
– Claude 3.5:9.8,区分演绎推理与实际错误,逻辑分析最严谨。
– Grok-2:8.7,给出正确结论,但带有轻度调侃语气。
逻辑推理方面,Claude 3.5最严谨,GPT-4o解释最清晰,Gemini 3 Pro能抓到前提问题,Grok-2则更偏轻松调侃但结论基本正确。
场景六:实时信息查询
– 测试题:请描述2026年3月15日的3条热点新闻。
– Gemini 3 Pro:9.3,联网后给出3条真实新闻并附来源。
– GPT-4o:9.2,给出2条新闻,时效性较好但有一条稍旧。
– Claude 3.5:8.9,更多聚焦国际政治,娱乐热点不足。
– Grok-2:9.7,联网后提供多条热点,更新速度快。
新闻检索方面,Grok-2更新最快、覆盖最广,Gemini 3 Pro和GPT-4o也很强且较可靠,Claude 3.5更偏国际政治类信息。
场景七:多轮对话记忆
– 测试题:初始聊旅行计划(想去云南),后续聊了5个不相关话题,问回“你之前说想去哪里?”
– Gemini 3 Pro:9.4,记忆准确,能够回忆并补充相关细节。
– GPT-4o:9.1,记忆正确但反应稍迟缓。
– Claude 3.5:9.6,记忆准确且能回忆出具体景点。
– Grok-2:8.9,记忆有时会被中间话题干扰。
记忆回溯方面,Claude 3.5和Gemini 3 Pro最准确,GPT-4o也可靠但反应稍慢,Grok-2则更容易受中间话题干扰。
场景八:中文古诗词理解
– 测试题:“落霞与孤鹜齐飞,秋水共长天一色”的意境与修辞分析。
– Gemini 3 Pro:9.5,动静结合、意境层次、对仗分析到位,结合背景。
– GPT-4o:9.2,分析扎实但略显模板化。
– Claude 3.5:8.9,学术性强,情感表达不足。
– Grok-2:9.1,画面感强,深度略逊于前三者。
诗词分析方面,Gemini 3 Pro最有层次感,GPT-4o最扎实,Claude 3.5偏学术,Grok-2则更擅长营造画面感。
四、常见问题(FAQ)
1) 在KULAAI上切换模型,历史对话会保留吗?
– 不自动保留对话上下文。提议在切换前记录要点,或在新模型中重新阐述背景信息。
2) 哪个模型最适合新手入门?
– 综合来看,Gemini 3 Pro的均衡性最好,长文本与多模态能力优势明显,初学者友善度较高。
3) 四款模型都免费,KULAAI平台如何盈利?
– 目前以免费体验吸引用户,未来可能增加增值服务(如更高额度、定制化模型),基础免费版一般会持续存在。
4) 模型会随时间变“变笨”吗?
– 模型本身此处一般不会“变笨”,但免费额度使用升级、策略调整,可能影响响应速率与可用能力。
5) 哪个模型在安全与合规方面更严格?
– 一般 Claude 3.5 在合规性上更谨慎,其次是 GPT-4o 与 Gemini,Grok-2 可能在边界场景上更需要人工监督。
五、总结
这次在KULAAI平台下对Gemini、GPT、Claude、Grok进行了多场景对比,呈现出各自的“性格”。Gemini 3 Pro在多模态与长文本处理方面具备显著优势,适合需要综合输入输出的应用场景;GPT-4o则以均衡性著称,适合需要稳定、综合能力的任务;Claude 3.5在安全性、严谨性方面表现突出,适合对合规性要求较高的场景;Grok-2以实时性与口语化风格著称,适合需要快速互动与传播的应用。通过KULAAI这一聚合平台,用户可以在同一界面内自由切换,针对不同任务选择最合适的模型。
如果你在寻找一个快速的起点来对比并筛选模型,提议先从Gemini 3 Pro开始,结合GPT-4o的均衡、Claude 3.5的安全性以及Grok-2的快速互动,形成一个“任务—模型”的对照表,以提升日常工作与创作的效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...