
「小墨是前端」专注前端技术分享,推荐优质开源项目,展示 Github、Gitee 创意作品,深入前端底层原理,一起探索技术边界。
都 2025 年了,做一个 RAG(检索增强生成)应用,还得维护三套数据库?存用户信息用 MySQL,存向量用 Chroma,做全文检索用 ES。代码写得我想吐,一出 Bug 更是查到头秃。
我在 GitHub 上刷到了 OceanBase seekdb。号称 “AI-Native Search Database”。我一开始以为又是哪个大厂出的 KPI 项目,结果仔细一看,好家伙,这不就是 “All in One” 方案吗?
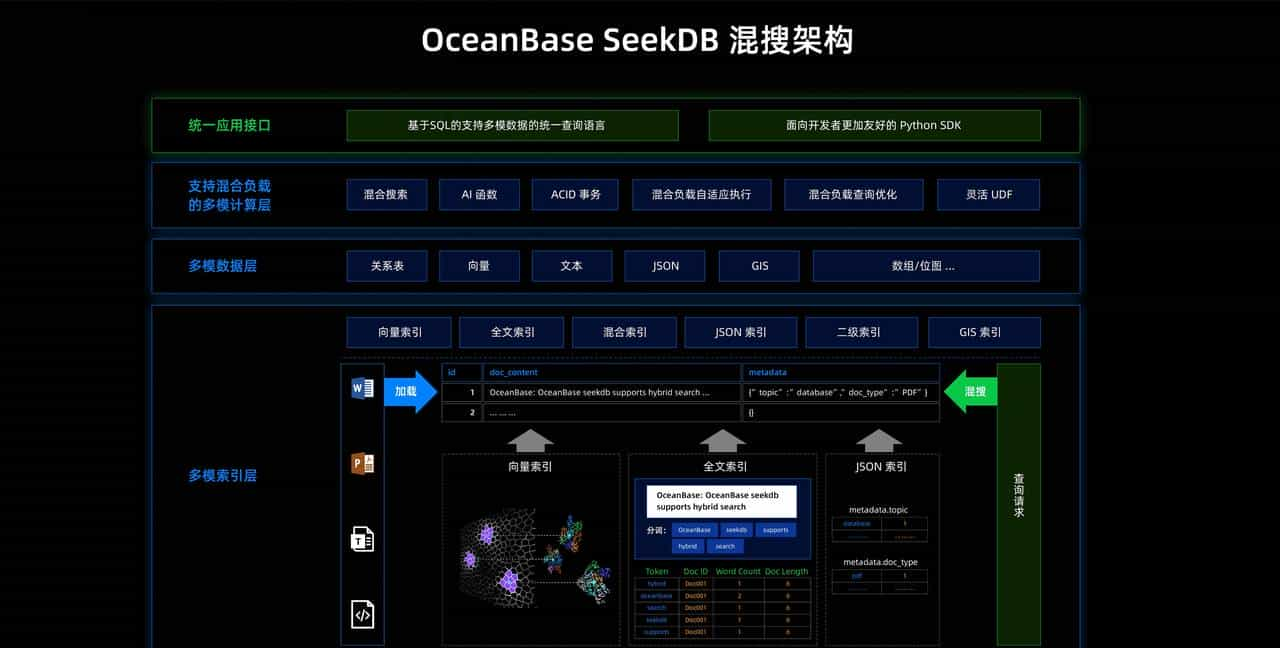
为什么我们需要 “AI-Native” 数据库?
做过 AI 应用的兄弟都知道,目前的技术栈有多割裂。
你想做一个带权限的知识库搜索:
- 先去 MySQL 查用户权限,拿到一堆文档 ID。
- 再去 Chroma 用向量搜类似文档。
- 如果还要支持关键词匹配,还得去 ES 查一遍。
- 最后在内存里把这三堆数据聚合、排序、过滤。
这流程,光是网络 IO 就得跑好几趟,更别提数据一致性了。万一 MySQL 删了文档,Chroma 没删,搜出来的就是死链。
seekdb 就是为了解决这个问题。它把关系型数据、向量数据、文本数据和 JSON 全部塞进了一个引擎里。
核心特性:把复杂留给数据库
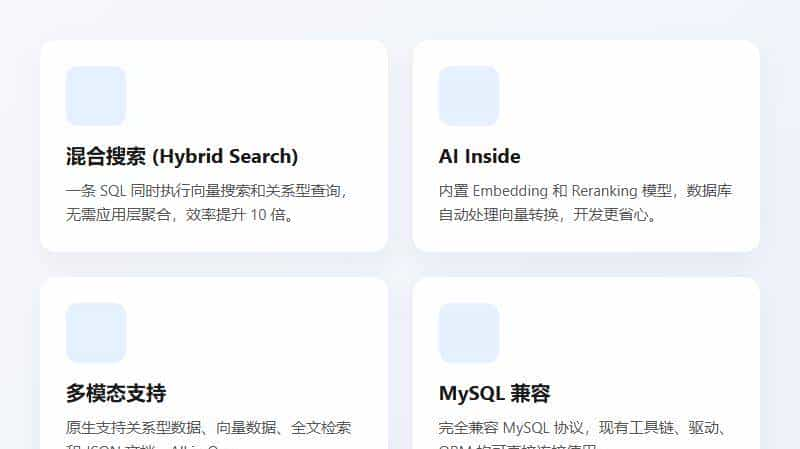
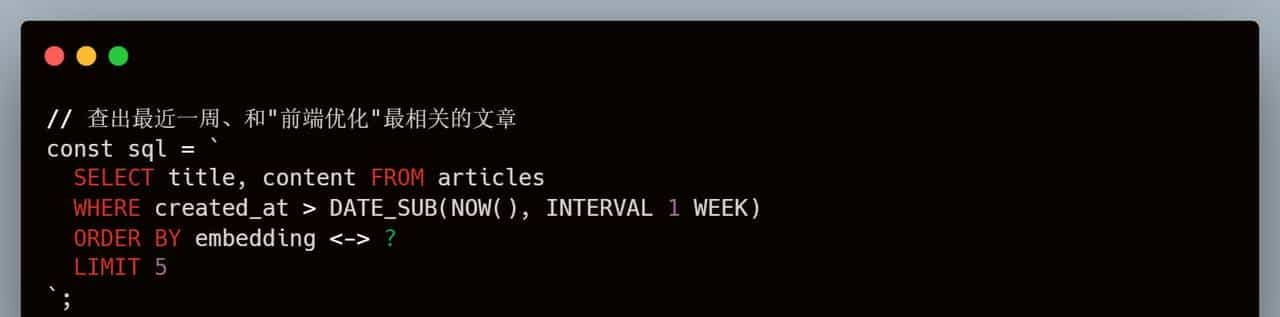
1. 混合搜索:一条 SQL 搞定所有
这是我最爽的功能。以前得写几十行代码逻辑,目前直接一条 SQL:
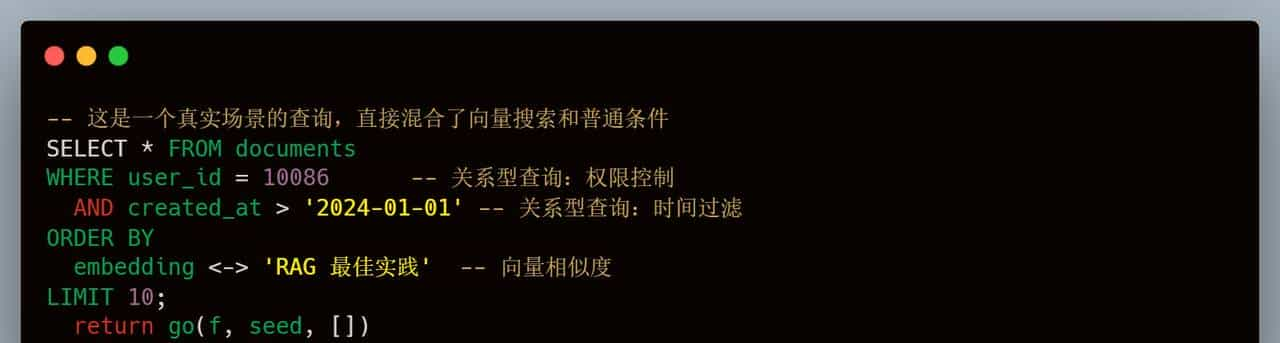
看到没?这就叫降维打击。数据库层面直接过滤+排序,性能比应用层聚合快了不止一个数量级。
2. AI Inside:数据库自己会”思考”
以前存向量,得先在应用层调 OpenAI 的 API 拿到 Embedding,再存进去。
seekdb 直接把 Embedding 和 Reranking 做进去了。你定义表的时候,告知它用什么模型,剩下的就不用管了。
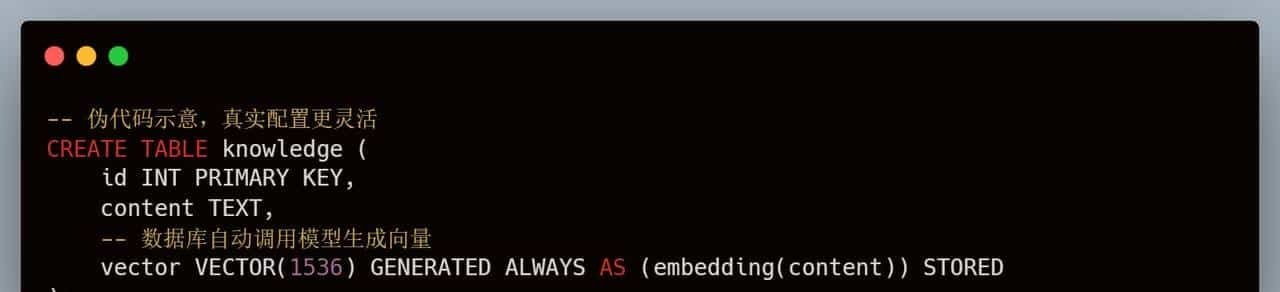
你只管往里塞文本,它自己转向量。这对于我们这种想快速验证想法的开发者来说,简直是神技。
3. 多模态支持:啥都能存
除了向量,它还支持标准的 SQL 关系型数据,支持全文检索(类似 ES),支持 JSON 文档。这意味着,你真的只需要部署这一个数据库,就能覆盖 90% 的业务场景。
实战体验:5分钟搭个私有知识库
光说不练假把式。我手痒试了一下,用 seekdb 搭个语义搜索真的快。
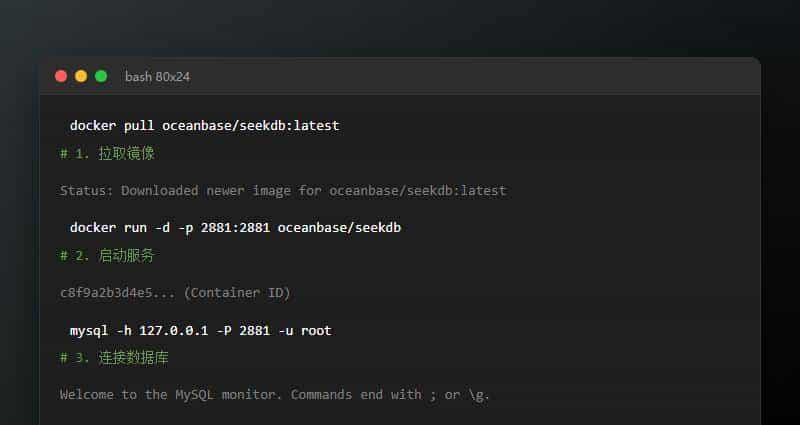
第一步:启动服务
它是 C++ 写的,可以直接用 Docker 跑,不用装一堆 Python 依赖。

第二步:创建向量表
连上数据库(支持 MySQL 协议,Navicat 都能连),建个表:
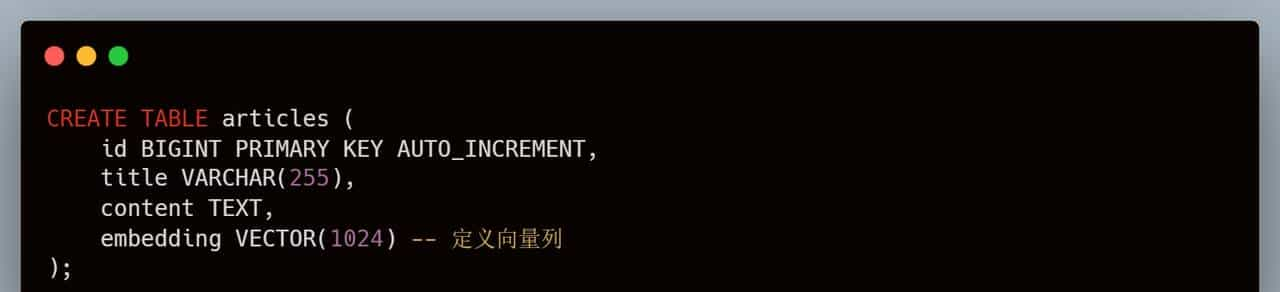
第三步:写入数据
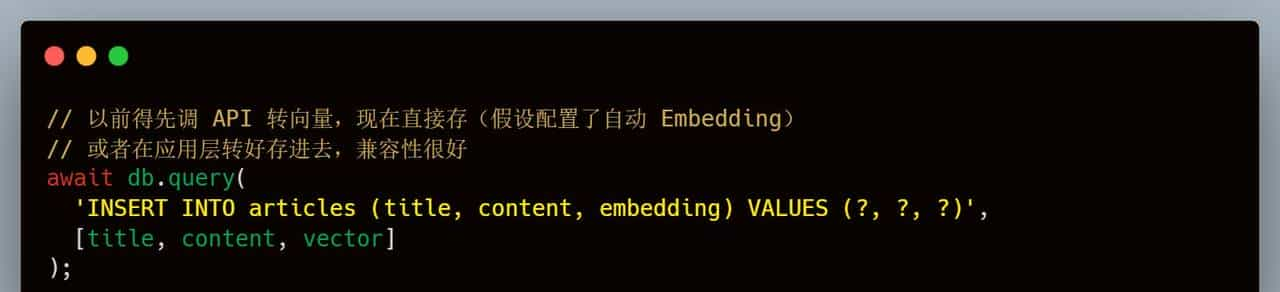
第四步:混合查询
整个过程流畅得不像是在做 AI 开发,更像是在写传统的 CRUD。我原来那个项目,光是处理数据同步的代码就写了两天,用 seekdb 半天就重构完了。
实战对比:谁才是 RAG 的终极答案?
为了让大家看得更清楚,我做了一个简单的对比。别看 seekdb Star 数目前只有 1.1K,但在架构理念上,它真的赢麻了。

真的有那么神吗?
当然,没有完美的技术。seekdb 也有它的短板,我得实话实说:
- 社区还不够大:毕竟刚开源不久,Star 数 1.1K,跟那些老牌向量库比,生态还不够丰富。遇到问题可能得自己去 GitHub 提 Issue,或者直接看源码。
- 文档还在完善:有些高级功能的文档写得比较简略,列如某些特定 AI 模型的配置,我当时折腾了好一会儿才跑通。
- 工具链支持:虽然兼容 MySQL 协议,但有些针对 MySQL 优化的特定工具可能不完全兼容。
但是,对于我们这种想快速落地 AI 应用,又不想维护复杂技术栈的开发者来说,它绝对是一个值得尝试的选择。
结论
如果你正在从头搭建一个 RAG 应用,或者受够了在 MySQL、Redis、VectorDB 之间来回横跳,不妨试试 seekdb。
它可能不是最成熟的,但绝对是最省心的。把复杂留给数据库,把简单留给自己,这才是程序员该有的生活。
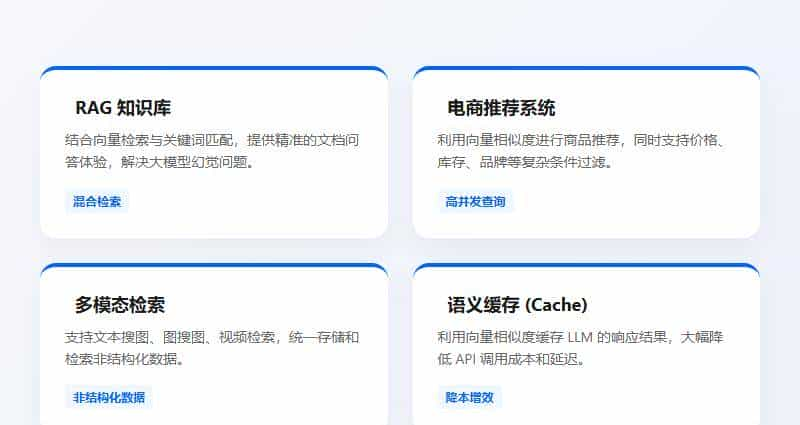
项目地址:https://github.com/oceanbase/seekdb
如果这篇文章对你有协助,欢迎点赞、收藏、转发!持续分享前端干货和开源好物,关注我,不迷路~
#Github##开源##数据库##RAG技术##向量数据库#
© 版权声明
文章版权归作者所有,未经允许请勿转载。





收藏了,感谢分享