极简导航
本机IP
记事本
AI导航
AI对话
排行榜
极简导航
blog
收录投稿
在线工具
本机IP
高清壁纸
记事本
2FA验证器
计算器
文本对比
键盘测试
随机数生成
条形码生成
数字大小写
科学计算器
阿里云优惠券
更多小工具
未登录
登录后即可体验更多功能
登录
注册
找回密码
AI导航
AI对话
排行榜
极简导航
blog
收录投稿
在线工具
本机IP
高清壁纸
记事本
2FA验证器
计算器
文本对比
键盘测试
随机数生成
条形码生成
数字大小写
科学计算器
阿里云优惠券
更多小工具
未登录
登录后即可体验更多功能
登录
注册
找回密码
首页
•
内容分享
•
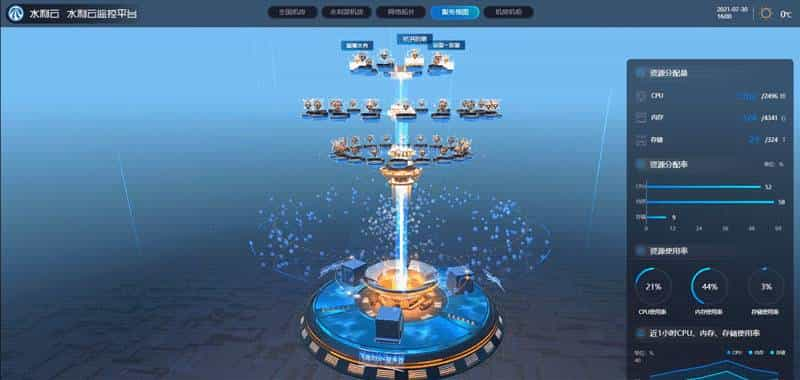
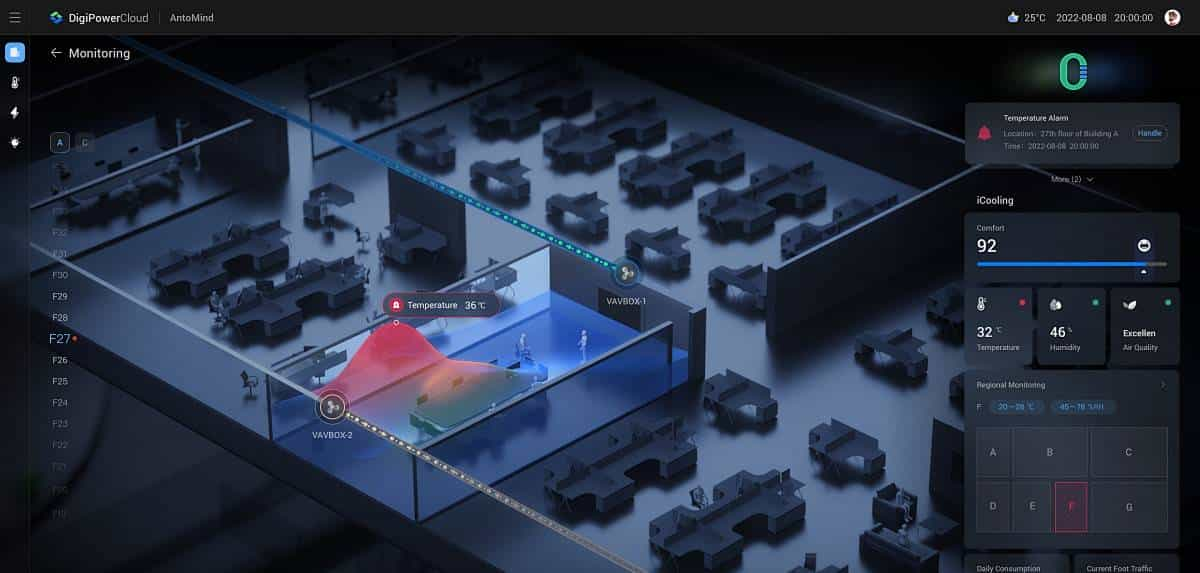
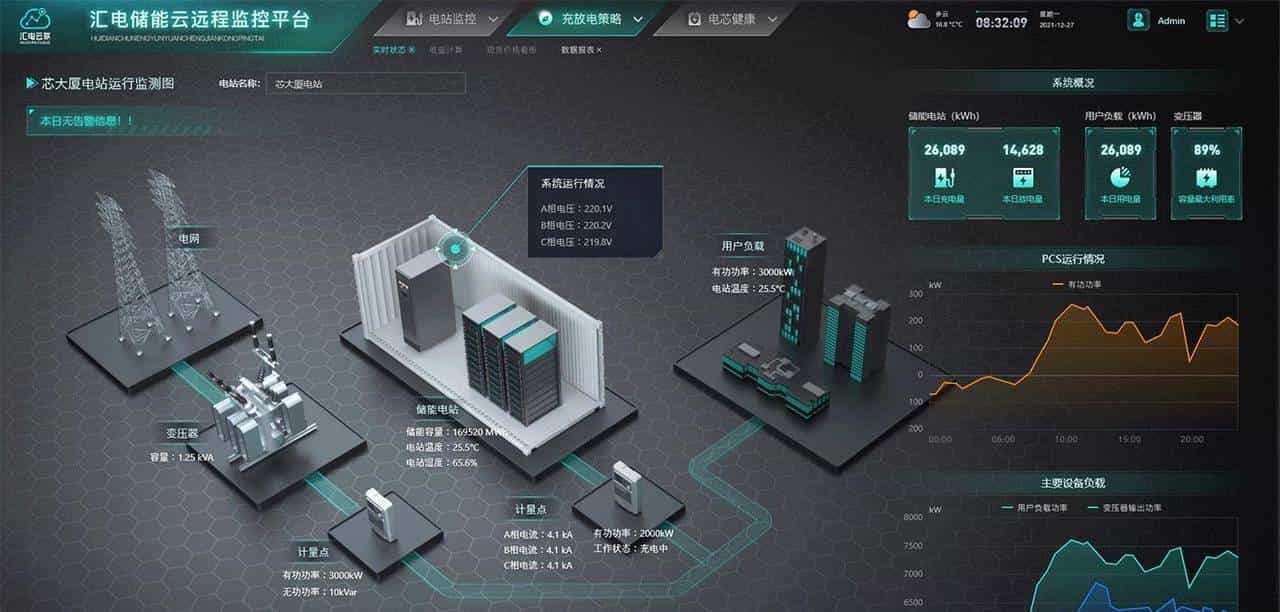
Three.js、Unity和WebGL:解锁3D数字孪生大屏的更多前端技术
Three.js、Unity和WebGL:解锁3D数字孪生大屏的更多前端技术
内容分享
4个月前发布
2
0
0
内容分享
©
版权声明
文章版权归作者所有,未经允许请勿转载。
上一篇
旧机顶盒别当废品扔!3个实用改造法,免月租也能看全台
下一篇
德国企业利用数字孪生技术加速工业AI训练
相关文章
Cursor 创始人复盘:AI 编程工具本质是提升人类指令表达能力,持续构建优秀产品才是壁垒
内容分享
3个月前
0
2
0
C#上位机的跨平台方案
内容分享
4个月前
4
7
0
直播脚本改一改!中职生掌握2个技巧,弹幕多到回不完
内容分享
4个月前
0
4
0
全网最全的ChatGPT提示词Prompts,可检索
内容分享
3个月前
0
4
0
暂无评论
暂无评论...
读者
1
0
0
4
Three.js、Unity和WebGL:解锁3D数字孪生大屏的更多前端技术
热门网站
日榜
周榜
月榜
百度手机助手
百度手机助手是权威安卓应用资源下载商店,拥有海量安卓应用、游戏下载资源,为您提供安全、高速的安卓app下载服务。
Pakutaso
Pakutaso 是一个免费的图片库和 AI 图像网站,无需注册即可立即下载。网站不收取任何销售费用,下载图片数量也没有限制。该网站提供美丽的日本风景照片(包括人物和纹理),以及 AI 生成的背景图片。截至 2025 年 9 月 5 日,共有 57,962 张照片可供下载。
ISO Republic
ISO Republic 提供超过 7,000 张优质高清图片和视频,全部免费供个人和商业使用。立即下载您喜爱的图片和视频吧!
亚马逊跨境电商培训
亚马逊全球开店旨在借助亚马逊全球资源,帮助中国卖家抓住跨境电商新机遇,发展出口业务。目前,已向中国卖家开放20个海外站点,能将商品配送至全球200多个国家和地区,为您链接数亿活跃用户及600万+的企业机构买家。更多开店注册信息请关注亚马逊全球开店官网。
PaperYY
PaperYY专业提供AIGC免费论文检测与智能降重服务,精准识别ChatGPT等AI生成内容,出具权威检测报告。支持论文查重、AI降重、AIGC检测、AI论文等一站式服务,保障学术合规性,已服务超千万师生用户。
拍拍回收
上京东搜回收
查看完整榜单
热门文章
日榜
周榜
月榜
Linux驱动-设备树2
4个月前
4
中高考英语必备核心语法考点地点状语从句详解及双语例句
4个月前
36
coze, dify,n8n,那个更有前途
4个月前
21
EPlan二次开发入门文档
4个月前
6
透明底抠图怎么制作?从AI工具到手把手教程一次搞懂
3个月前
33
拆解第一代AI应用Jasper.ai 的兴衰:AI 营销工具的护城河,不在模型而在工作流
3个月前
13
查看完整榜单
标签云
网址
网址
文章
软件
书籍