
Pod:Kubernetes的最小调度单元与设计精髓
在Kubernetes的世界里,Pod远非简单的“容器组”,而是一个精心设计的协作单元,代表了云原生架构中的一种全新抽象。理解Pod的真正本质,是掌握Kubernetes设计哲学的关键一步。
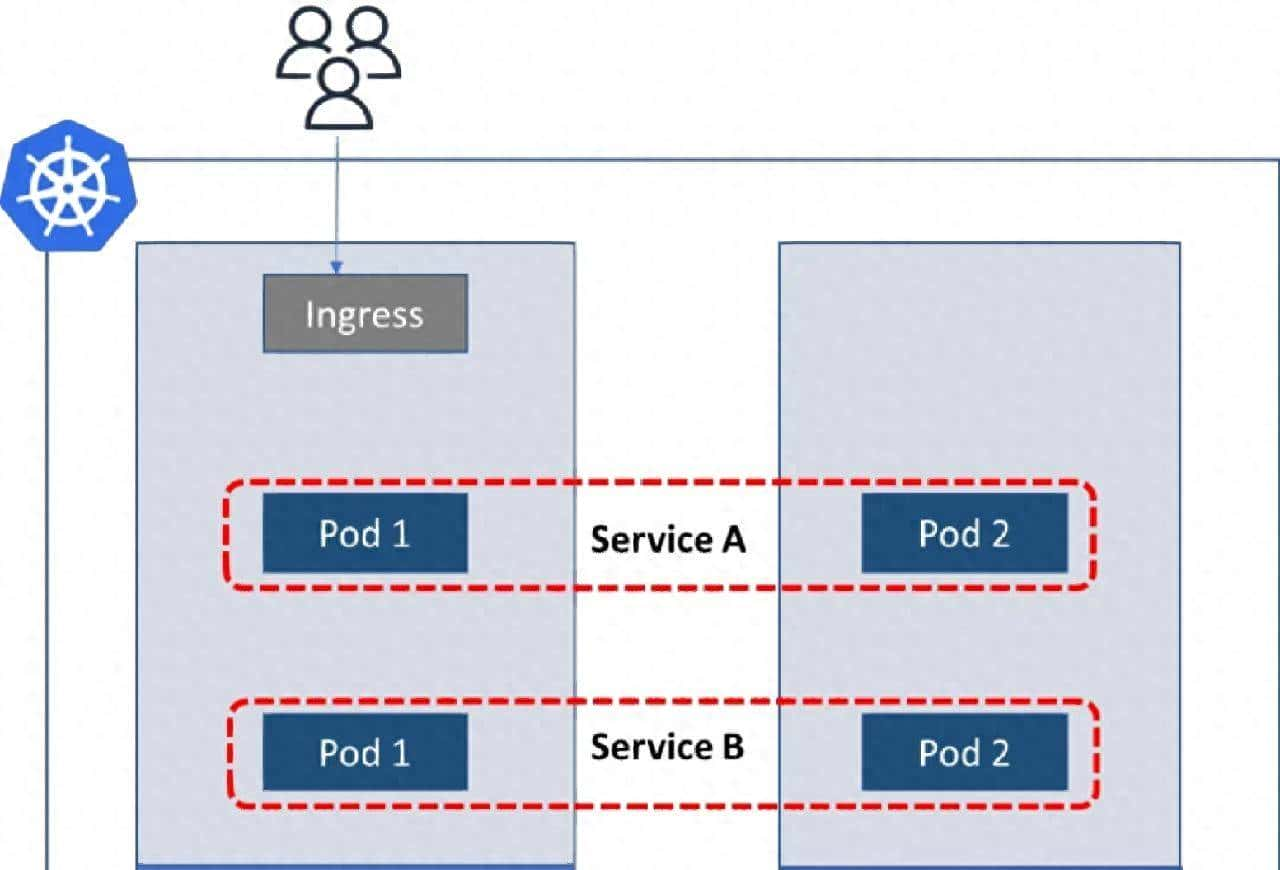
一、Pod的本质:为什么不是直接调度容器?
在深入Pod之前,我们需要回答一个根本问题:为什么Kubernetes不直接调度容器,而要引入Pod这个额外的抽象层?
1.1 容器协作的局限性
容器技术本质上提供的是隔离的执行环境,每个容器都有自己的文件系统、进程空间和网络栈。这种强隔离性超级适合封装单个应用进程,但在微服务架构中,我们常常遇到需要紧密协作的多个进程:
- 日志收集器需要访问应用容器的日志文件
- 服务网格代理需要拦截和转发应用的网络流量
- 配置文件监视器需要动态更新应用配置
- 数据同步助手需要与主应用共享数据卷
如果每个进程都运行在完全隔离的容器中,这种紧密协作将变得异常复杂。这正是Pod设计要解决的核心问题。
1.2 Pod:共享执行环境的容器组
Pod是Kubernetes中最小的可部署和可调度单元,它代表了一个共享执行环境的容器集合。这种设计使得Pod内的容器能够:
- 共享网络命名空间:所有容器共享同一个IP地址和端口空间
- 共享存储卷:容器可以挂载一样的持久化存储
- 共享IPC命名空间:容器可以通过System V IPC或POSIX消息队列通信
- 可选共享UTS命名空间:容器可以共享主机名和域名
- 通过localhost直接通信:容器间可以通过本地回环地址直接访问
这种设计哲学的核心是:将需要紧密协作、共享资源的进程放在同一个Pod中,将松散耦合的进程放在不同的Pod中。
二、Pod的生命周期:状态流转与控制器管理
2.1 Pod生命周期阶段
Pod在其生命周期中会经历一系列明确的阶段,这些阶段反映了Pod从创建到终止的完整过程:
stateDiagram-v2
[*] --> Pending: 创建Pod
Pending --> Running: 调度成功并启动容器
Running --> Succeeded: 所有容器成功退出
Running --> Failed: 至少一个容器异常退出
Pending --> Failed: 调度失败或启动错误
Succeeded --> [*]: Pod完成
Failed --> [*]: Pod失败
state Running {
[*] --> ContainerCreating
ContainerCreating --> Running: 所有容器运行
Running --> Terminating: 收到终止信号
Terminating --> [*]: 清理完成
}
各阶段详解:
|
阶段 |
描述 |
常见缘由 |
|
Pending |
Pod已被Kubernetes接受,但一个或多个容器尚未创建和运行 |
镜像下载中、资源不足、调度延迟 |
|
Running |
Pod已绑定到节点,所有容器已创建 |
至少有一个容器正在运行或正在启动/重启 |
|
Succeeded |
Pod中的所有容器已成功终止且不会重启 |
批处理作业完成 |
|
Failed |
Pod中的所有容器已终止,且至少一个容器失败退出 |
应用错误、配置错误、资源不足 |
|
Unknown |
无法获取Pod状态 |
节点通信故障 |
2.2 Pod的创建与调度流程
理解Pod如何从YAML定义变为运行中的实例至关重大:
# 1. 用户定义Pod(或通过Deployment等控制器)
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: main-app
image: nginx:1.21
ports:
- containerPort: 80
Pod创建流程:
- 提交定义:用户通过kubectl或API提交Pod定义
- API Server验证:API Server验证配置并存储在etcd中
- 调度决策:调度器选择适合的节点(基于资源、亲和性等)
- kubelet执行:目标节点的kubelet通过容器运行时创建容器
- 状态报告:kubelet向API Server报告Pod状态
2.3 Pod的终止流程
Pod的终止是一个优雅的过程,确保应用能够妥善处理终止信号:
// Pod终止序列的简化示意
1. API Server收到删除请求 → 标记Pod为"Terminating"
2. kubelet检测到终止状态 → 开始关闭序列
3. 发送SIGTERM到主进程 → 应用开始优雅关闭
4. 等待优雅关闭期(默认30秒)
5. 如果容器未停止 → 发送SIGKILL强制终止
6. 清理容器和资源 → 从API Server移除Pod记录
关键配置:
spec:
terminationGracePeriodSeconds: 60 # 优雅关闭期限(秒)
三、容器设计模式:Pod的高级协作模式
Pod的多容器特性催生了几种强劲的设计模式,这些模式是理解Pod”设计精髓”的关键。
3.1 Sidecar模式:增强主容器功能
Sidecar模式是最常见的设计模式,通过添加辅助容器来扩展或增强主容器的功能,而不修改主容器本身。
典型应用场景:
- 日志收集(Fluentd、Logstash)
- 监控代理(Prometheus Node Exporter)
- 配置热更新
- 安全代理
Sidecar示例:日志收集器
apiVersion: v1
kind: Pod
metadata:
name: webapp-with-logging
spec:
containers:
# 主容器:Web应用
- name: webapp
image: my-webapp:latest
volumeMounts:
- name: log-volume
mountPath: /var/log/app
# Sidecar容器:日志收集器
- name: log-collector
image: fluentd:latest
volumeMounts:
- name: log-volume
mountPath: /var/log/app
- name: config-volume
mountPath: /etc/fluentd
# 共享的存储卷
volumes:
- name: log-volume
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
在这个示例中,Web应用将日志写入共享卷,Fluentd Sidecar容器读取这些日志并发送到中央日志系统。两个容器独立运行但共享资源。
3.2 Ambassador模式:代理外部服务访问
Ambassador模式通过代理容器为应用容器提供统一的外部服务访问接口,常用于服务发现、负载均衡和协议转换。
典型应用场景:
- 数据库访问代理
- API网关集成
- 服务发现抽象
Ambassador示例:数据库代理
apiVersion: v1
kind: Pod
metadata:
name: app-with-db-proxy
spec:
containers:
# 主容器:应用
- name: app
image: my-app:latest
env:
- name: DATABASE_HOST
value: "localhost" # 通过localhost访问代理
- name: DATABASE_PORT
value: "5432"
# Ambassador容器:数据库代理
- name: db-proxy
image: envoyproxy/envoy:latest
env:
- name: UPSTREAM_DB_HOST
value: "database-cluster.example.com"
- name: UPSTREAM_DB_PORT
value: "5432"
# Envoy配置通过ConfigMap挂载
应用容器只需连接到localhost:5432,由Envoy代理处理实际的数据库连接、负载均衡和故障转移。
3.3 Adapter模式:标准化输出格式
Adapter模式用于标准化或转换不同容器产生的数据,使其符合统一格式。
典型应用场景:
- 指标格式标准化
- 日志格式转换
- API响应适配
Adapter示例:指标标准化
apiVersion: v1
kind: Pod
metadata:
name: app-with-metrics-adapter
spec:
containers:
# 主容器:应用(暴露自定义指标)
- name: app
image: my-app:latest
ports:
- containerPort: 8080
# Adapter容器:指标转换器
- name: metrics-adapter
image: prometheus-community/prometheus:latest
command:
- /bin/sh
- -c
- |
# 从应用获取自定义指标
# 转换为Prometheus格式
# 暴露在/metrics端点
ports:
- containerPort: 9090
四、探针机制:应用健康管理
Kubernetes提供了强劲的探针机制来监控和管理容器健康状态,这是生产环境稳定性的关键保障。
4.1 探针类型与用途
|
探针类型 |
检查时机 |
失败后果 |
典型用途 |
|
启动探针 |
容器启动期间 |
重启容器 |
检查慢启动应用是否已就绪 |
|
存活探针 |
整个容器生命周期 |
重启容器 |
检测应用是否死锁或无响应 |
|
就绪探针 |
容器运行期间 |
从Service端点移除 |
检查应用是否可处理请求 |
4.2 探针配置实践
apiVersion: v1
kind: Pod
metadata:
name: probed-app
spec:
containers:
- name: webapp
image: my-app:latest
# 启动探针:给应用足够的启动时间
startupProbe:
httpGet:
path: /health/startup
port: 8080
failureThreshold: 30 # 最多检查30次
periodSeconds: 5 # 每5秒检查一次
# 存活探针:确保应用正常运行
livenessProbe:
httpGet:
path: /health/live
port: 8080
initialDelaySeconds: 10 # 容器启动后10秒开始检查
periodSeconds: 5 # 每5秒检查一次
timeoutSeconds: 1 # 1秒超时
failureThreshold: 3 # 连续失败3次则重启
# 就绪探针:确保应用可处理流量
readinessProbe:
httpGet:
path: /health/ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
successThreshold: 1
failureThreshold: 1
4.3 探针设计最佳实践
- 区分就绪与存活:就绪探针失败不应重启容器,只是暂时不接受流量
- 保守的初始延迟:给应用足够的启动时间,避免不必要的重启
- 适当的检查频率:根据应用特性调整检查间隔
- 定义明确的检查端点:健康检查端点应快速响应,不依赖外部服务
- 实现优雅降级:探针失败时应用应提供有意义的错误信息
五、资源管理与调度优化
5.1 资源请求与限制
Pod的资源管理通过请求(requests)和限制(limits)来实现:
spec:
containers:
- name: app
image: my-app:latest
resources:
# 请求:调度器保证的最低资源
requests:
memory: "128Mi"
cpu: "250m" # 250毫核,即0.25个CPU核心
# 限制:容器可使用的最大资源
limits:
memory: "256Mi"
cpu: "500m" # 500毫核,即0.5个CPU核心
资源单位说明:
- CPU:1000m = 1个CPU核心,500m = 0.5核心,100m = 0.1核心
- 内存:Mi表明MiB(220字节),`Gi`表明GiB(230字节)
5.2 服务质量等级(QoS Classes)
基于资源设置,Kubernetes为Pod分配不同的QoS等级:
|
QoS等级 |
条件 |
调度优先级 |
资源不足时 |
|
Guaranteed |
所有容器设置了requests=limits |
高 |
最后被终止 |
|
Burstable |
至少一个容器设置了requests<limits |
中 |
在BestEffort之后 |
|
BestEffort |
未设置requests和limits |
低 |
最先被终止 |
QoS配置示例:
# Guaranteed QoS
resources:
limits:
memory: "128Mi"
cpu: "250m"
requests: # 如果requests与limits一样,可只设置limits
memory: "128Mi"
cpu: "250m"
# Burstable QoS
resources:
requests:
memory: "64Mi"
cpu: "100m"
limits:
memory: "128Mi"
cpu: "250m"
# BestEffort QoS
# 不设置resources字段
5.3 节点选择与亲和性
通过节点选择器和亲和性规则,可以精细控制Pod的调度位置:
spec:
nodeSelector:
disktype: ssd # 必须调度到具有disktype=ssd标签的节点
affinity:
# 节点亲和性:优先调度到特定节点
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: zone
operator: In
values: ["east-1"]
# Pod亲和性:与特定Pod部署在一起
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["cache"]
topologyKey: "kubernetes.io/hostname"
# Pod反亲和性:避免与特定Pod部署在一起
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["web"]
topologyKey: "kubernetes.io/hostname"
六、Pod安全与隔离
6.1 安全上下文配置
Pod安全上下文(Security Context)定义了特权、访问控制和权限设置:
spec:
securityContext: # Pod级别安全上下文
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: app
image: my-app:latest
securityContext: # 容器级别安全上下文
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
readOnlyRootFilesystem: true
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
6.2 Pod安全策略(PSP)与Pod安全标准
随着PodSecurityPolicy(PSP)的弃用,Kubernetes引入了Pod安全标准:
apiVersion: v1
kind: Pod
metadata:
name: secured-pod
spec:
securityContext:
runAsNonRoot: true
containers:
- name: app
image: my-app:latest
命名空间级别安全标准:
apiVersion: v1
kind: Namespace
metadata:
name: my-app
labels:
pod-security.kubernetes.io/enforce: baseline
pod-security.kubernetes.io/enforce-version: v1.24
pod-security.kubernetes.io/audit: restricted
pod-security.kubernetes.io/warn: restricted
七、实战应用场景分析
7.1 微服务应用Pod设计
apiVersion: v1
kind: Pod
metadata:
name: user-service
labels:
app: user-service
version: v1.2.0
spec:
# 服务账户和RBAC
serviceAccountName: user-service-account
containers:
# 主应用容器
- name: app
image: user-service:v1.2.0
ports:
- containerPort: 8080
env:
- name: DB_HOST
value: "postgres-service"
- name: DB_PORT
value: "5432"
# 健康检查
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
# 资源管理
resources:
requests:
memory: "256Mi"
cpu: "200m"
limits:
memory: "512Mi"
cpu: "500m"
# Sidecar:服务网格代理
- name: istio-proxy
image: istio/proxyv2:1.15
# 代理配置...
# Init容器:预配置检查
initContainers:
- name: init-db-check
image: postgres:14-alpine
command: ['sh', '-c', 'until pg_isready -h postgres-service; do echo waiting for database; sleep 2; done']
7.2 批处理作业Pod设计
apiVersion: v1
kind: Pod
metadata:
name: data-processor
spec:
restartPolicy: Never # 批处理作业一般不重启
containers:
- name: processor
image: data-processor:latest
command: ["python", "/app/process.py"]
args: ["--input", "/data/input.csv", "--output", "/data/output.csv"]
# 资源限制避免影响其他Pod
resources:
requests:
memory: "1Gi"
cpu: "1"
limits:
memory: "2Gi"
cpu: "2"
# 挂载持久化存储
volumeMounts:
- name: data-volume
mountPath: /data
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: data-pvc
八、Pod设计的最佳实践总结
- 单一职责原则:每个Pod应专注于一个主要功能,通过Sidecar扩展能力
- 合理设置资源:准确估计资源需求,设置适当的requests和limits
- 实现健壮的健康检查:配置完整的探针机制确保应用可用性
- 思考亲和性与反亲和性:优化Pod调度以提升性能和可用性
- 实施安全最佳实践:使用非root用户、只读文件系统等安全配置
- 优雅处理终止:配置适当的terminationGracePeriodSeconds
- 合理使用Init容器:用于预检查、预配置和数据准备
- 标签与注解策略:使用有意义的标签和注解便于管理和监控
总结
Pod作为Kubernetes的最小调度单元,其设计远不止是”容器组”那么简单。它体现了Kubernetes对协作性、可组合性和声明式管理的深刻理解。通过共享命名空间和存储卷,Pod为紧密协作的进程提供了理想的运行环境;通过Sidecar、Ambassador等设计模式,Pod实现了功能的灵活扩展;通过探针机制和资源管理,Pod确保了应用的稳定运行。
掌握Pod的设计精髓,意味着我们不仅知道如何使用Pod,更理解为什么Kubernetes要这样设计Pod。这种理解将协助我们在实际工作中做出更合理的设计决策,构建更稳定、可维护的云原生应用。随着Kubernetes生态的不断发展,Pod作为基础构建块,将继续在云原生架构中扮演核心角色。


















- 最新
- 最热
只看作者