在这里给大家介绍一种低成本的将Modbus RTU协议的串口设备接入到OPC UA的服务器呢?
OPC全称是OLE(Object Linking and Embedding) for Process Control。为了便于自动化行业不同厂家的设备和应用程序能相互交换数据,定义了一个统一的接口函数,就是OPC协议规范。OPC是基于WINDOWS COM/DOM的技术,可以使用统一的方式去访问不同设备厂商的产品数据。

钡铼BL10XUA版本是专门针对工业现场而研发生产的,BL10XUA版本对下可以采集Modbus RTU、Modbus TCP、DLT645、三菱PLC、西门子PLC、台达PLC等工业现场常用的,将数据转换为OPC UA协议,将设备的数据对接OPC UA服务器了。

在这里许多朋友会问了,一些PLC本身就支持OPC UA功能,为什么还要选择你这个网关呢?成本,成本,主要还是出于成本的考量,就以西门子为例,西门子支持OPC UA的功能的只有S7-1200以上的高端CPU,这些高端PLC售价也是相当的高,尤其是目前工控产品普遍缺货价格更是水涨船高。如果一个S7-Smart就能解决的问题就不需要再上S7-1200、S7-1500了,一台Smart再加上一台BL10XUA网关成本低超级超级多!
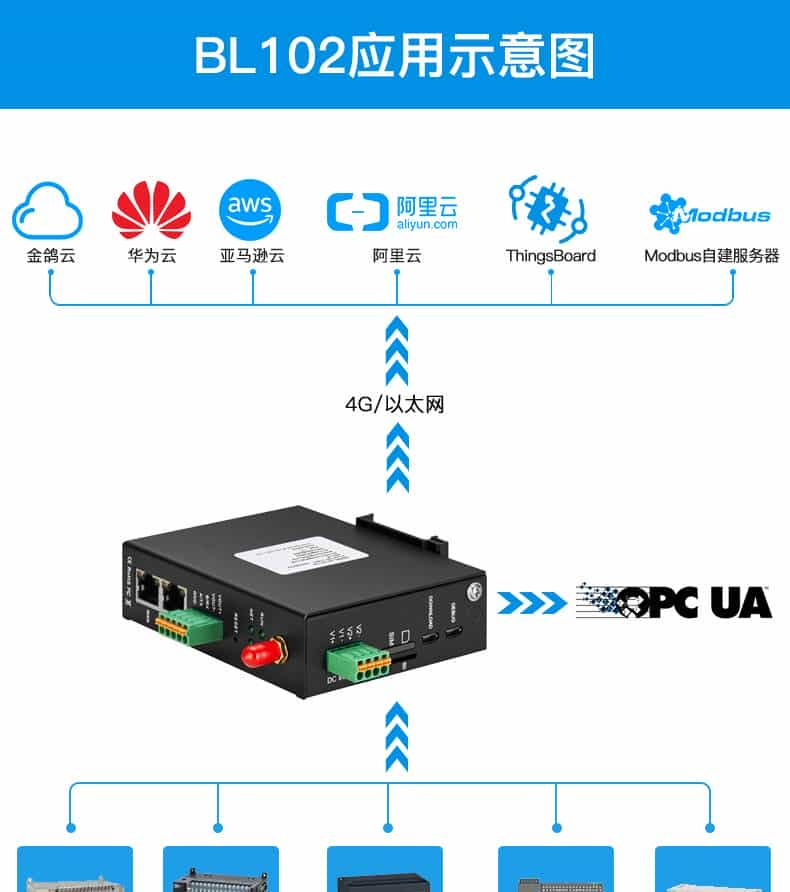
BL10X不仅支持采集PLC转OPC UA同时也可以转MQTT对接云平台,网关还内置了阿里云、华为云、thingsboard等公有云的云引擎,不需要做二次开发,一键对接上述平台。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











