
多行多列转换,TOCOL很擅长,REDUCE+VSTACK套路也好用!
应用场景一:
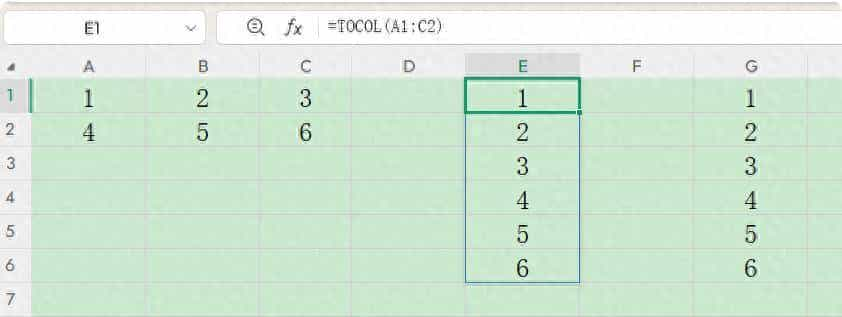
将多行多列转换为一列表格。
公式一:
=TOCOL(A1:C2)
公式二:
=REDUCE(,A1:C2,VSTACK)
解析:
TOCOL作用就是将二维数组转化为一列,用法是TOCOL(数组,忽略特殊值,通过行或列扫描)。
公式二、三参数均采用默认值,表明将A1:C2通过行扫描的方式,转换为一列。
REDUCE作用是通过将LAMBDA函数应用到每个值并返回累加器中的总值,将数组减小为累计值,用法是REDUCE(初始值,数组,函数)。
REDUCE(,A1:C2,VSTACK)完整写法为:
=REDUCE(,A1:C2,LAMBDA(X,Y,VSTACK(X,Y)))
公式中第一参数省略,此时第二参数A1:C2中的第一个值,直接不参与计算作为初始值。
VSTACK(X,Y)作为计算表达式,表明将初始值X与传递的Y值合并,每计算一次的结果作为下一步的初始值,这样通过堆积木的形式,将每次计算的结果垂直堆砌起来。

类似于REDUCE(,A1:C2,VSTACK)的写法:
=REDUCE(,A1:C2,SUM)返回21;
=REDUCE(,A1:C2,MAX)返回6。
应用场景二:
判断并将符合条件的值转换为一列。
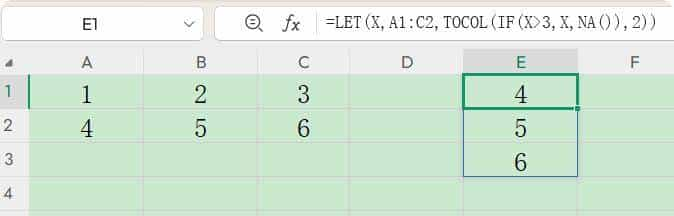
公式一:
=LET(X,A1:C2,TOCOL(IF(X>3,X,NA()),2))
解析:
LET定义A1:C2为X,IF函数判断符合大于3的值返回数值本身,否则返回NA();
这样,再通过TOCOL第二参数2忽略掉错误值,最后将剩下的符合条件的数值转为一列。
同样地,REDUCE+VSTACK也能轻松完成任务。
公式二:
=DROP(
REDUCE(
0,
A1:C2,
LAMBDA(X, Y, IF(Y > 3, VSTACK(X, Y), X))
),
1
)

解析:
REDUCE初始值为0,遍历的数组A1:C2,如果传递计算的Y值符合条件,则VSTACK将初始值与Y垂直堆砌起来,否则返回X即上一次的结果不变。
最后DROP的作用是删除REDUCE的初始值所在的行。
应用案例:
提取每个单元格内的最大值,并将所有最大值转换为一列。
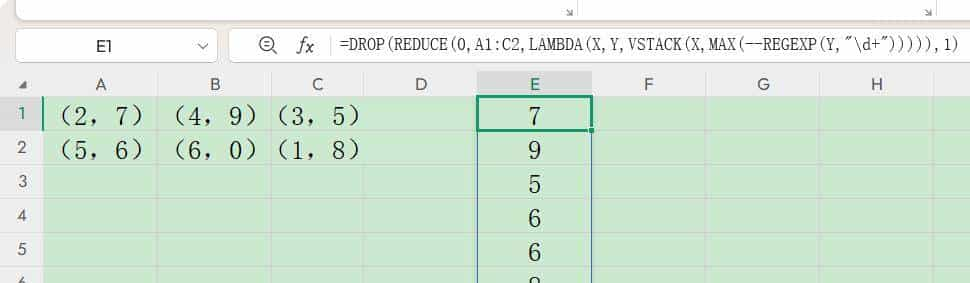
公式:
=DROP(
REDUCE(
0,
A1:C2,
LAMBDA(X, Y, VSTACK(X, MAX( –REGEXP(Y, “d+”))))
),
1
)
解析:
原理同上,区别在于计算表达式部分, MAX( –REGEXP(Y, “d+”))表明将传递计算的Y中提取出全部数字并计算出最大值, VSTACK(X, MAX( –REGEXP(Y, “d+”)))表明将初始值与每次计算的结果合并,最终将所有最大值垂直堆砌起来。
同样,DROP删除掉初始值所在行。
当然,也可直接添加一个表头作为初始值,效果也是很好的。
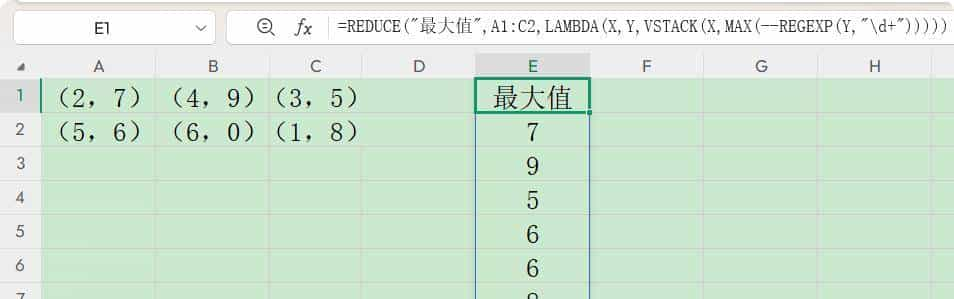
公式为:
=REDUCE(
“最大值”,
A1:C2,
LAMBDA(X, Y, VSTACK(X, MAX( –REGEXP(Y, “d+”))))
)
小结:
由于REDUCE仅返回最终的总值,而不体现计算的过程,因此REDUCE常常与VSTACK(或HSTACK)组合使用,将每次计算的结果与上一步的结果合并起来呈现整个计算过程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











