
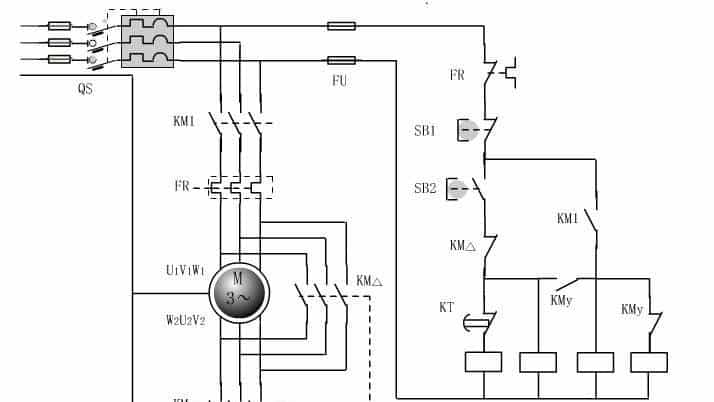
1、下图是小编给大家绘制的一个星三角降压启动电路图,是最简洁、最安全的电路图哦!觉得有用,赶快收藏咯!
2、该图的优点是:
(1)、 启动时,是KM1接通启动电流的,KMY先闭合不接通电机启动电流,所以KMY是一个小接触器;
(2)、运行时,只有KM1、KM△工作,KMY、KT都不工作;

如果觉得不错帮转载一下!谢谢!!
如有侵犯到其他媒体或个人版权的,请和小编联系!
更多资料分享:
联系QQ:277620680
微信公众号:工控PLC零基础或PLCadu
© 版权声明
文章版权归作者所有,未经允许请勿转载。












电路中欠个一时间继电器的常开触头