
WebSockets 是一种先进的技术,允许在用户的浏览器和服务器之间开启交互式通信会话。用户可以通过 WebSocket 发送消息到服务器并接收事件驱动的响应,而无需轮询服务器以获取回复。

WebSocket 的用途超级广泛,它们主要用于需要快速、实时通信的应用程序。例如,在在线游戏、聊天应用、实时交易平台等场合中,WebSocket 能够提供低延迟的通信解决方案。此外,WebSocket 也被用于物联网(IoT)设备和服务器之间的通信,以及在浏览器中实现各种实时数据流的应用程序。
WebSocket 的工作原理可以分为以下几个步骤:
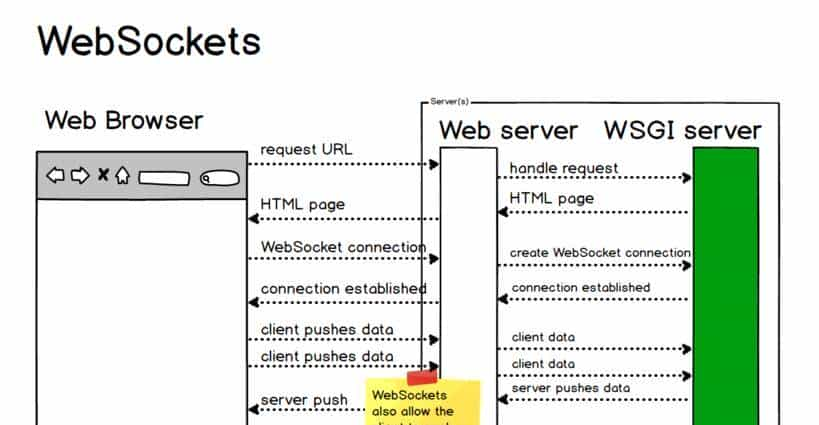
- 客户端请求:客户端通过发送一个 HTTP 请求到服务器来初始化一个 WebSocket 连接。这个请求被称为握手请求,它包含了特殊的头部信息,告知服务器客户端想要建立一个 WebSocket 连接。
- 服务器响应:如果服务器支持 WebSocket 协议,它会返回一个 HTTP 响应,状态码为 101 Switching Protocols,表明服务器同意切换到 WebSocket 协议。
- 连接建立:一旦握手成功,客户端和服务器之间的连接就会从 HTTP 协议升级到 WebSocket 协议。此时,连接保持打开状态,直到客户端或服务器决定关闭连接。
- 数据传输:在 WebSocket 连接建立之后,客户端和服务器可以通过发送帧来交换数据。帧可以包含文本或二进制数据,这使得 WebSocket 超级适合传输各种类型的数据。
- 保持连接:WebSocket 连接会保持活跃状态,直到其中一方发送一个关闭帧来终止连接。在连接关闭之前,客户端和服务器可以随时发送数据。
WebSocket 协议的主要优点包括:
- 全双工通信:WebSocket 允许服务器和客户端之间进行双向通信,这意味着服务器可以在任何时候发送数据到客户端,而不需要客户端先发送请求。
- 减少开销:与传统的 HTTP 轮询相比,WebSocket 在建立连接后,数据交换的开销更小,由于它不需要每次交换都发送 HTTP 头部信息。
- 实时性:WebSocket 提供了比 HTTP 更快的消息传递,这对于需要实时反馈的应用程序来说超级重大。
- 兼容性:WebSocket 使用标准的 HTTP 端口(80 和 443),因此它能够兼容大多数现有的网络基础设施,包括防火墙和代理服务器。
尽管 WebSocket 有许多优点,但它也有一些局限性和思考因素:
- 浏览器支持:虽然大多数现代浏览器都支持 WebSocket,但在一些旧的浏览器或者某些网络环境中可能不被支持。
- 安全性:WebSocket 可以使用加密连接(wss://),但开发者需要确保正的确 现安全措施,防止中间人攻击和其他安全威胁。
- 服务器负载:WebSocket 连接保持打开状态,这可能会增加服务器的负载,特别是在有大量并发连接时。
总的来说,WebSocket 提供了一种有效的方法来实现实时、双向、全双工的网络通信。随着网络应用对实时性要求的不断提高,WebSocket 正在成为越来越多应用程序的首选技术。无论是在金融行业的实时交易更新,还是在社交媒体的即时消息传递中,WebSocket 都扮演着重大的角色。随着技术的发展和标准的完善,我们可以预见 WebSocket 将在未来的网络通信中发挥更大的作用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











