

分享兴趣,传播快乐,增长见闻,留下美好!
亲爱的您,这里是LearningYard学苑。
今天小编为大家带来“悦见新知(2):Python流程控制与函数封装(竞赛篇)”。
欢迎您的访问!
Share interest, spread happiness, increase knowledge, and leave beautiful.
Dear, this is the LearingYard Academy!
Today, the editor brings the “悦见新知(2):Python流程控制与函数封装(竞赛篇)””.
Welcome to visit!
一. 思维导图
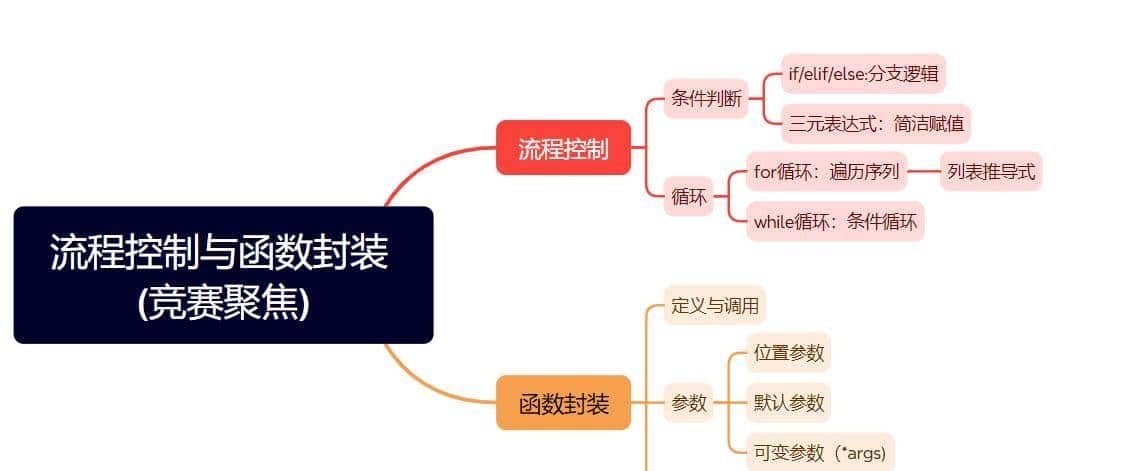
二. 核心知识点(聚焦竞赛应用)
II. Core Knowledge Points (Focusing on Competition Applications)
1. 条件判断:竞赛中的决策逻辑
竞赛应用:算法比赛中根据输入数据选择不同策略;建模比赛中根据模型表现决定后续步骤;爬虫比赛中判断页面元素是否存在。
1.Conditional Judgment: Decision-Making Logic in Competitions
Competition Applications: Selecting different strategies based on input data in algorithm competitions; deciding subsequent steps according to model performance in modeling competitions; determining whether page elements exist in web crawling competitions.
实战示例(算法比赛):成绩等级判定
score = 85
# if/elif/else 结构进行多分支判断
if score >= 90:
grade = “A”
bonus = 5
elif score >= 80:
grade = “B”
bonus = 3
elif score >= 70:
grade = “C”
bonus = 1
else:
grade = “D”
bonus = 0
print(f”得分:{score}, 等级:{grade}, 奖励积分:{bonus}”)
# 输出:得分:85, 等级:B, 奖励积分:
Practical Example (Algorithm Competition): Grade Evaluation Based on Scores
score = 85
# Using if/elif/else structure for multi-branch judgment
if score >= 90:
grade = “A”
bonus = 5
elif score >= 80:
grade = “B”
bonus = 3
elif score >= 70:
grade = “C”
bonus = 1
else:
grade = “D”
bonus = 0
print(f”Score: {score}, Grade: {grade}, Bonus Points: {bonus}”)
# Output: Score: 85, Grade: B, Bonus Points: 3
高频操作:三元表达式(简洁赋值)
# 竞赛中常用于快速初始化或简单条件赋值
# 语法:value_if_true if condition else value_if_false
High-Frequency Operation: Ternary Expressions (Concise Assignment)
#Commonly used in competitions for quick initialization or simple conditional assignments.
#Syntax: value_if_true if condition else value_if_false
# 示例:判断样本是否为有效样本(得分>60为有效)
is_valid = True if score > 60 else False
# 或者更简洁地:is_valid = score > 60
#Example: Determining if a Sample is Valid (a score > 60 is considered valid)
is_valid = True if score > 60 else False
# Or more concisely: is_valid = score > 60
status = “晋级” if score >= 80 else “待定”
print(f”状态:{status}”) # 输出:状态:晋级
status = “Promoted” if score >= 80 else “Pending”
print(f”Status: {status}”) # Output: Status: Promoted
2. 循环:自动化处理竞赛数据
(1)for循环:遍历数据集合
竞赛应用:遍历数据聚焦的所有样本进行处理;循环调用多次模型进行集成学习;遍历网页链接进行批量爬取。
2.Loops: Automating Data Processing in Competitions
(1) For Loop: Iterating Over Data Collections
Competition Applications: Processing all samples in a dataset; repeatedly calling models for ensemble learning; batch crawling web links.
实战示例(建模比赛):批量数据预处理
# 原始数据列表(例如,从文件读取的多个样本值)
raw_data_list = [89, 105, -5, 78, 320] # 假设包含异常值(如-5, 320)
cleaned_data_list = []
# 使用for循环遍历并清洗每个数据点
for data in raw_data_list:
# 清洗规则:只保留0到100之间的合理值
if 0 <= data <= 100:
cleaned_data_list.append(data)
print(f”清洗后的数据:{cleaned_data_list}”) # 输出:清洗后的数据:[89, 78]
Practical Example (Modeling Competition): Batch Data Preprocessing
# Original data list (e.g., sample values read from a file)
raw_data_list = [89, 105, -5, 78, 320] # Assume it contains outliers (e.g., -5, 320)
cleaned_data_list = []
# Using a for loop to iterate and clean each data point
for data in raw_data_list:
# Cleaning rule: Only retain reasonable values between 0 and 100
if 0 <= data <= 100:
cleaned_data_list.append(data)
print(f”Cleaned Data: {cleaned_data_list}”) # Output: Cleaned Data: [89, 78]
高频操作:列表推导式(竞赛代码优化利器)
# 上述循环用列表推导式一行完成,更高效、更Pythonic
cleaned_data_list = [data for data in raw_data_list if 0 <= data <= 100]
print(f”(列表推导式)清洗后的数据:{cleaned_data_list}”)
High-Frequency Operation: List Comprehensions (A Powerful Tool for Optimizing Competition Code)
#Complete the above loop in one line using a list comprehension, which is more efficient and Pythonic.
cleaned_data_list = [data for data in raw_data_list if 0 <= data <= 100]
print(f”(List Comprehension) Cleaned Data: {cleaned_data_list}”)
# 另一个例子:快速生成平方数序列(用于测试数据)
squares = [x**2 for x in range(1, 6)] # [1, 4, 9, 16, 25]
print(f”平方数序列:{squares}”)
# Another example: Quickly generate a sequence of square numbers (for test data)
squares = [x**2 for x in range(1, 6)] # [1, 4, 9, 16, 25]
print(f”Sequence of Square Numbers: {squares}”)
(2)while循环:满足条件时持续运行
竞赛应用:爬虫比赛中的持续翻页直到没有下一页;算法比赛中的迭代优化直到收敛;模拟比赛中的多轮次对决。
(2) While Loop: Continuing to Run While Conditions Are Met
Competition Applications: Continuously turning pages in web crawling competitions until there are no more pages; iterative optimization in algorithm competitions until convergence; multi-round duels in simulation competitions.
实战示例(爬虫比赛):自动翻页直到末尾
current_page = 1
max_pages = 5 # 假设已知最大页数,实践中可能通过检测”下一页”按钮是否存在来判断
Practical Example (Web Crawling Competition): Automatically Turning Pages Until the End
current_page = 1
max_pages = 5 # Assume the maximum number of pages is known; in practice, it may be determined by detecting the presence of a “Next Page” button
# 模拟爬取过程
while current_page <= max_pages:
print(f”正在爬取第 {current_page} 页…”)
# 这里应放置实际的爬取代码,如 requests.get(…)
# … (爬取逻辑)
print(f”第 {current_page} 页数据爬取完毕!”)
current_page += 1 # 更新页码,至关重大,避免无限循环!
print(“所有页面爬取完成!”)
#Simulate the crawling process
while current_page <= max_pages:
print(f”Crawling page {current_page}…”)
# Place the actual crawling code here, such as requests.get(…)
# … (crawling logic)
print(f”Data from page {current_page} has been crawled successfully!”)
current_page += 1 # Update the page number; crucial to avoid infinite loops!
print(“All pages have been crawled successfully!”)
3. 函数封装:构建可复用的竞赛代码块
竞赛应用:将常用的数据预处理、特征工程、模型评估步骤封装成函数,避免代码重复,提高可读性和协作效率。
3.Function Encapsulation: Building Reusable Code Blocks for Competitions
Competition Applications: Encapsulating commonly used data preprocessing, feature engineering, and model evaluation steps into functions to avoid code duplication, improve readability, and enhance collaboration efficiency.
(1)基础函数:定义、参数与返回值
(1) Basic Functions: Definition, Parameters, and Return Values
实战示例(通用竞赛工具函数)
# 定义一个计算模型评估指标的函数
def calculate_metrics(true_values, predicted_values):
“””
计算模型的准确率与平均绝对误差。
参数:
true_values (list): 真实值列表
predicted_values (list): 预测值列表
返回:
dict: 包含准确率和平均绝对误差的字典
“””
if len(true_values) != len(predicted_values):
return {“error”: “输入列表长度必须一致。”}
# 计算准确率 (以回归问题中在必定误差范围内视为正确为例)
correct_predictions = 0
total_predictions = len(true_values)
absolute_errors = []
for true, pred in zip(true_values, predicted_values):
error = abs(true – pred)
absolute_errors.append(error)
if error <= 2.0: # 假设误差小于等于2.0算作预测正确
correct_predictions += 1
accuracy = correct_predictions / total_predictions
mae = sum(absolute_errors) / len(absolute_errors)
# 返回一个字典,包含多个指标
return {“accuracy”: accuracy, “mean_absolute_error”: mae}
# — 调用函数 —
# 模拟一组真实值和预测值
y_true = [10, 20, 30, 40]
y_pred = [12, 18, 33, 38] # 注意第二个样本误差为2,刚好在阈值内
results = calculate_metrics(y_true, y_pred)
print(f”模型评估结果:{results}”)
# 输出:模型评估结果:{'accuracy': 1.0, 'mean_absolute_error': 2.25}
# 准确率100%,由于所有样本预测误差都在2.0以内
Practical Example (General-Purpose Competition Utility Function)
# Define a function to calculate model evaluation metrics
def calculate_metrics(true_values, predicted_values):
“””
Calculate the accuracy and mean absolute error of a model.
Parameters:
true_values (list): List of true values
predicted_values (list): List of predicted values
Returns:
dict: Dictionary containing accuracy and mean absolute error
“””
if len(true_values) != len(predicted_values):
return {“error”: “Input lists must have the same length.”}
# Calculate accuracy (assuming predictions within a certain error margin are considered correct for regression problems)
correct_predictions = 0
total_predictions = len(true_values)
absolute_errors = []
for true, pred in zip(true_values, predicted_values):
error = abs(true – pred)
absolute_errors.append(error)
if error <= 2.0: # Assume predictions with an error <= 2.0 are considered correct
correct_predictions += 1
accuracy = correct_predictions / total_predictions
mae = sum(absolute_errors) / len(absolute_errors)
# Return a dictionary containing multiple metrics
return {“accuracy”: accuracy, “mean_absolute_error”: mae}
# — Function Call —
# Simulate a set of true and predicted values
y_true = [10, 20, 30, 40]
y_pred = [12, 18, 33, 38] # Note: The error for the second sample is 2, which is within the threshold
results = calculate_metrics(y_true, y_pred)
print(f”Model evaluation results: {results}”)
# Output: Model evaluation results: {'accuracy': 1.0, 'mean_absolute_error': 2.25}
# Accuracy is 100% because all sample prediction errors are within 2.0
(2)高级参数技巧(提升函数灵活性)
(2) Advanced Parameter Techniques (Enhancing Function Flexibility
# 默认参数:为参数提供默认值,调用时可省略
def load_data(file_path, encoding='utf-8', header=True):
“””模拟加载数据,带有默认参数”””
print(f”从 {file_path} 加载数据,编码:{encoding}, 包含表头:{header}”)
# … 实际的数据加载逻辑
return f”Data from {file_path}”
# 调用时可以选择性提供参数
data1 = load_data(“data.csv”) # 使用默认的utf-8编码和True表头
data2 = load_data(“data_gbk.csv”, encoding='gbk') # 指定编码
data3 = load_data(“data_no_header.csv”, header=False) # 指定无表头
# 可变参数 *args:接受任意数量的位置参数
def calculate_sum(*numbers):
“””计算任意个数字的和”””
total = 0
for num in numbers:
total += num
return total
# 在竞赛中可用于计算不定长指标集合的总和或平均值
team_scores = calculate_sum(85, 92, 78, 96)
print(f”团队总得分:{team_scores}”) # 输出:团队总得分:351
# Default parameters: Provide default values for parameters, which can be omitted during calls
def load_data(file_path, encoding='utf-8', header=True):
“””Simulate loading data with default parameters”””
print(f”Loading data from {file_path}, encoding: {encoding}, includes header: {header}”)
# … Actual data loading logic
return f”Data from {file_path}”
# Parameters can be selectively provided during calls
data1 = load_data(“data.csv”) # Use default utf-8 encoding and True for header
data2 = load_data(“data_gbk.csv”, encoding='gbk') # Specify encoding
data3 = load_data(“data_no_header.csv”, header=False) # Specify no header
今天的分享就到这里了,如果您对文章有独特的想法,欢迎给我们留言。
让我们相约明天,祝您今天过得开心快乐!
That's all for today's sharing.
If you have a unique idea about the article, please leave us a message, and let us meet tomorrow.
I wish you a nice day!
参考资料:
· Python 官方文档
· 各类编程竞赛真题与最佳实践
翻译:文心一言
本文由LearningYard学苑整理并发出,如有侵权请后台留言沟通。
文案 | yue
排版 | yue
审核 |qiu



















暂无评论内容