
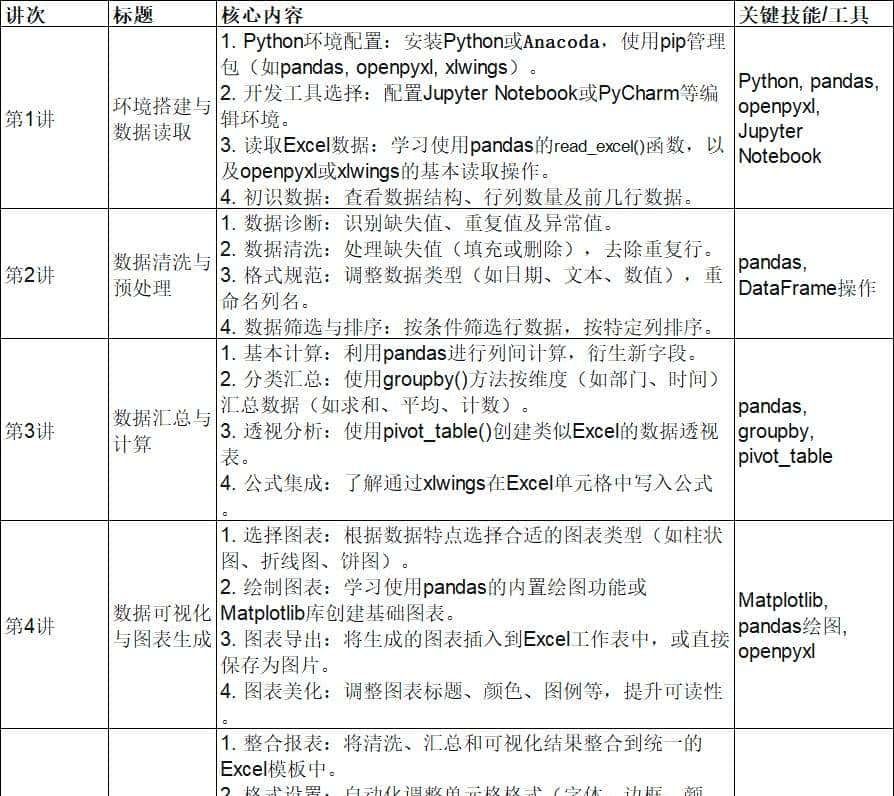
第1讲-环境搭建与读取数据
第2讲-自动数据清洗与预处理
第3讲-数据汇总与计算
第4讲-数据可视化与图表生成
第5讲-自动化报表整合与输出
目标描述:学习python编程语言,把现实工作中需要的功能,用代码去实现,从而学以致用。逐步积累经验,成为一种专业和专长
核心技能课程大纲:
第1讲 环境搭建与数据读取
第一步:环境准备
先安装Python,如果您是新手,强烈建议安装Anaconda,此软件的傻瓜式安装过程比较友好,按安装提示点下一步完成即可,而且可以包含Python环境。
1.下载Anaconda:从Anaconda官网下载适合您操作系统的版本(Windows/macOS/Linux)。https://www.anaconda.com/
2. 安装Anaconda:运行安装程序,按照提示完成安装(建议勾选“Add Anaconda to PATH”选项)。
3. 创建Python环境: 打开Anaconda Prompt(Windows)或终端(macOS/Linux)。 输入 conda create –name myenv python=3.8(可替换myenv为自定义环境名,3.8为Python版本)。 激活环境:conda activate myenv。
操作过程截图如下:
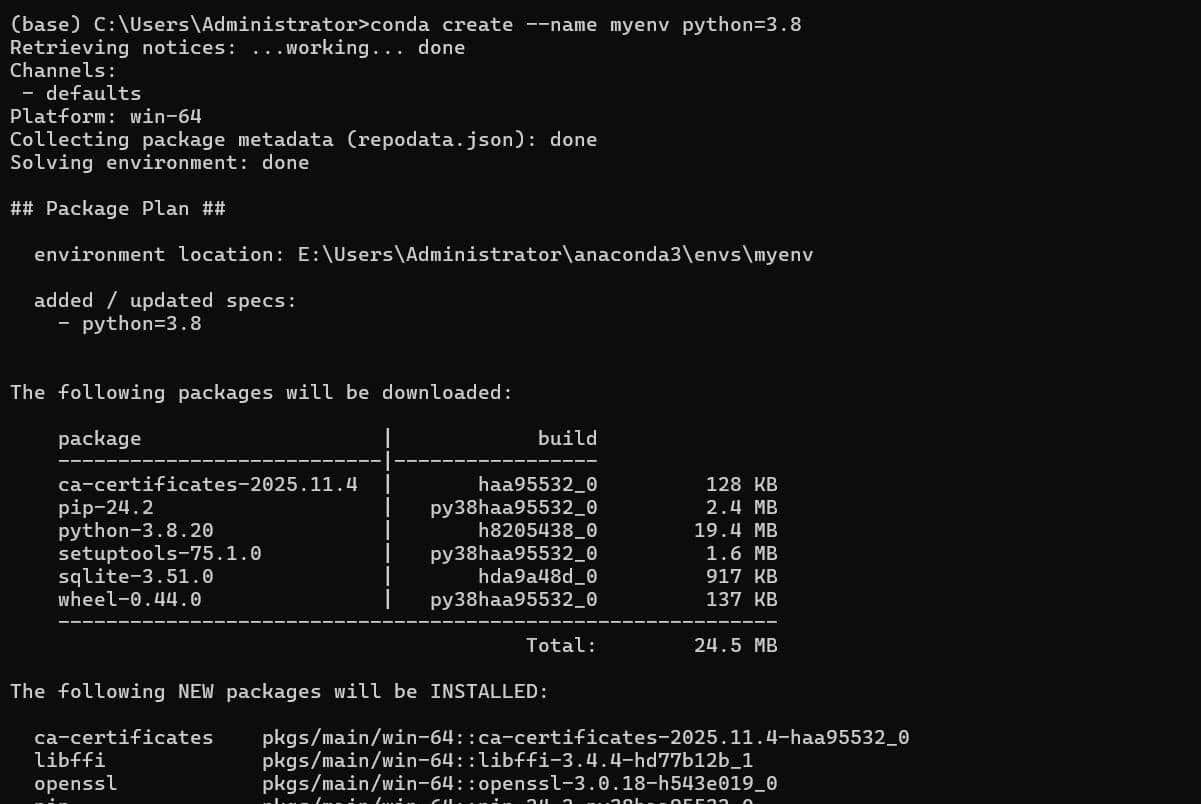
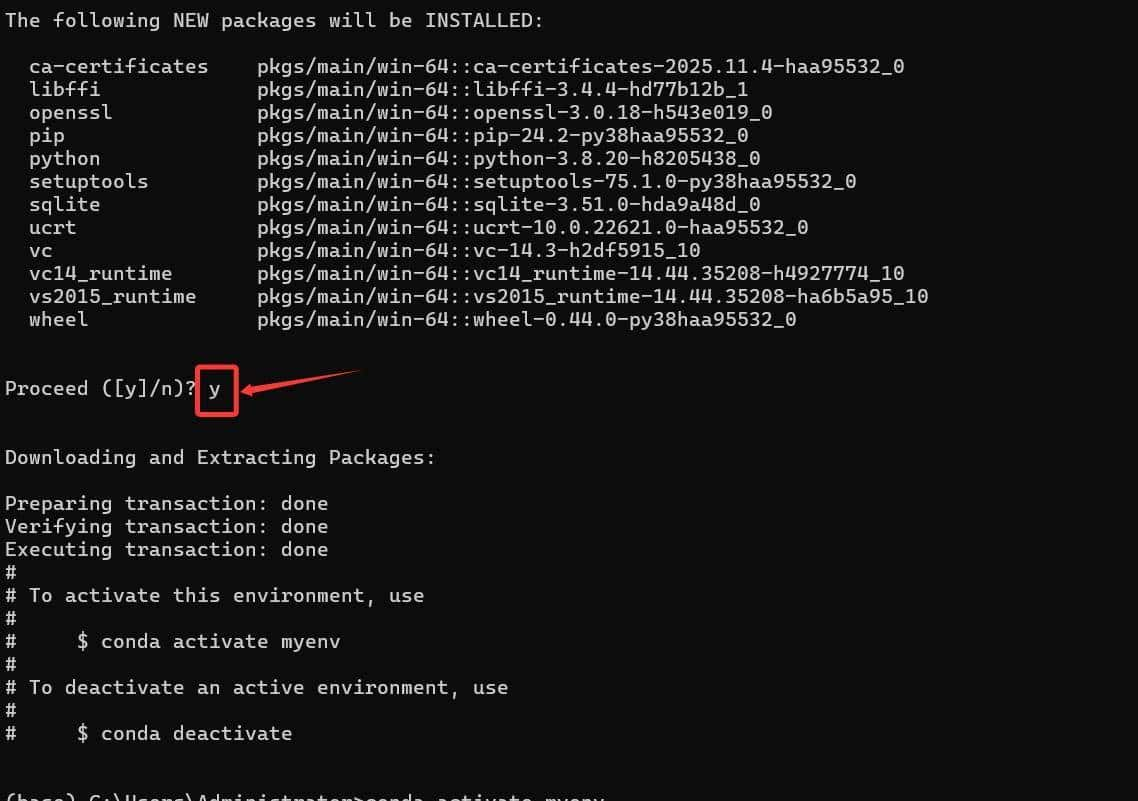
注意:标红的地方需要输入y。
安装完之后在命令行窗口输入python –version 可以检查是否安装成功以及版本信息。
4.安装额外包:使用conda install或pip install安装所需库(如numpy、pandas)。
在开始之前,请确保您已安装以下Python库,它包含了数据科学所需的大部分库,执行以下命令。
# 在您的终端或命令提示符中运行以下命令进行安装
pip install pandas numpy matplotlib seaborn plotly5.在电脑屏幕左下角的开始菜单中找到anacoda3,点击二级菜单Anacoda Navigator,这是一个集成应用软件管理器,可以一键下载和安装各种工具,相当于手机的应用市场,通过打开这个工具,在主页home中安装Jupyter Notebook(编写python代码的工具),写代码都在这里进行。
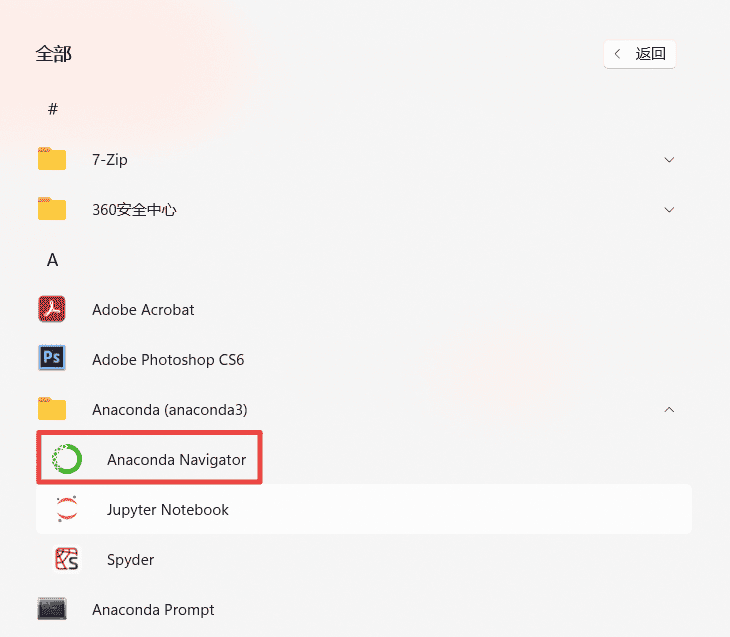
下一步点击install,开始安装,安装完成后,在电脑左下角的开始菜单中找到Jupyter Notebook启动。
 打开后,点击New ,选择Notebook。
打开后,点击New ,选择Notebook。
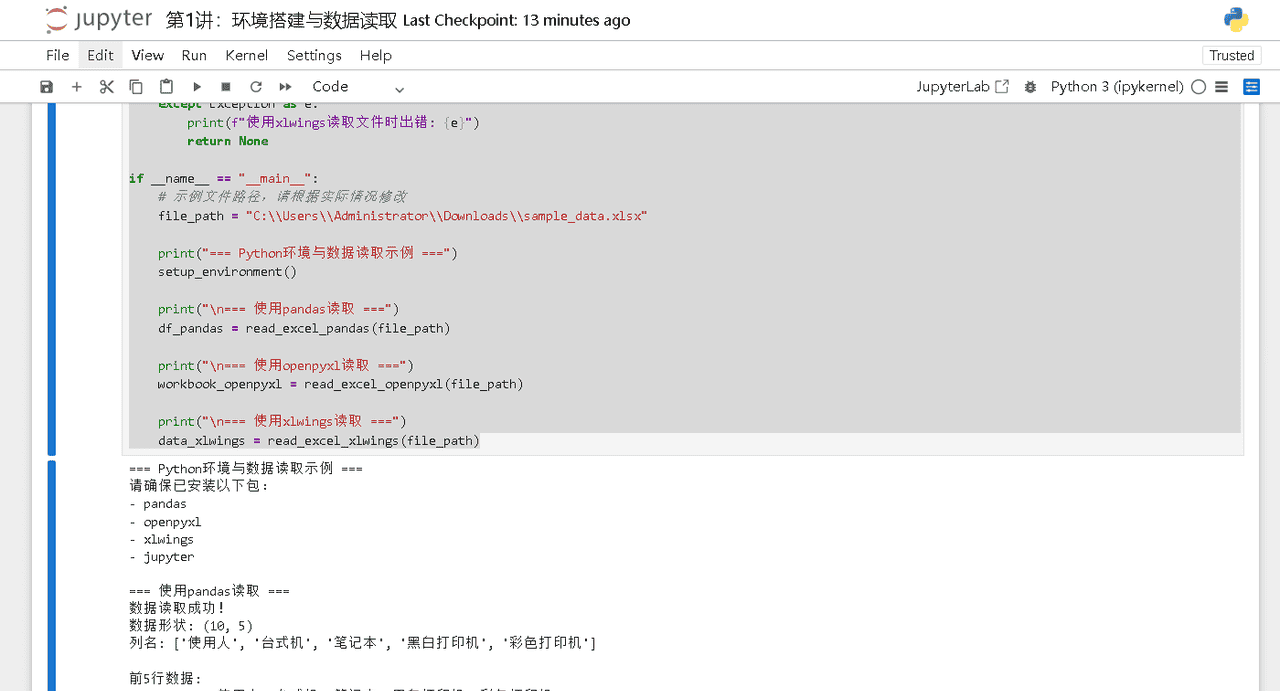
第二步:数据读取
代码如下:
# lecture1_data_reading.py
import pandas as pd
import openpyxl
import xlwings as xw
def setup_environment():
"""检查并安装必要的包"""
required_packages = ['pandas', 'openpyxl', 'xlwings', 'jupyter']
print("请确保已安装以下包:")
for package in required_packages:
print(f"- {package}")
def read_excel_pandas(file_path):
"""使用pandas读取Excel文件"""
try:
df = pd.read_excel(file_path)
print("数据读取成功!")
print(f"数据形状: {df.shape}")
print(f"列名: {list(df.columns)}")
print("
前5行数据:")
print(df.head())
return df
except Exception as e:
print(f"读取文件时出错: {e}")
return None
def read_excel_openpyxl(file_path):
"""使用openpyxl读取Excel文件"""
try:
workbook = openpyxl.load_workbook(file_path)
sheet = workbook.active
print(f"工作表名称: {sheet.title}")
print(f"数据范围: A1:{sheet.max_column}{sheet.max_row}")
# 读取前5行数据
for row in sheet.iter_rows(max_row=5, values_only=True):
print(row)
return workbook
except Exception as e:
print(f"使用openpyxl读取文件时出错: {e}")
return None
def read_excel_xlwings(file_path):
"""使用xlwings读取Excel文件"""
try:
app = xw.App(visible=False)
workbook = app.books.open(file_path)
sheet = workbook.sheets[0]
# 读取整个数据范围
data_range = sheet.used_range
data = data_range.value
print(f"数据范围: {data_range.address}")
print("前5行数据:")
for i in range(min(5, len(data))):
print(data[i])
workbook.close()
app.quit()
return data
except Exception as e:
print(f"使用xlwings读取文件时出错: {e}")
return None
if __name__ == "__main__":
# 示例文件路径,请根据实际情况修改
file_path = "C:UsersAdministratorDownloadssample_data.xlsx"
print("=== Python环境与数据读取示例 ===")
setup_environment()
print("
=== 使用pandas读取 ===")
df_pandas = read_excel_pandas(file_path)
print("
=== 使用openpyxl读取 ===")
workbook_openpyxl = read_excel_openpyxl(file_path)
print("
=== 使用xlwings读取 ===")
data_xlwings = read_excel_xlwings(file_path)第2讲:数据清洗与预处理
# lecture2_data_cleaning.py
import pandas as pd
import numpy as np
def data_diagnosis(df):
"""数据诊断:识别缺失值、重复值及异常值"""
print("=== 数据诊断报告 ===")
print(f"数据形状: {df.shape}")
print(f"
数据类型:")
print(df.dtypes)
print(f"
缺失值统计:")
missing_data = df.isnull().sum()
for col, count in missing_data.items():
if count > 0:
print(f"{col}: {count}个缺失值 ({count/len(df)*100:.2f}%)")
print(f"
重复行数量: {df.duplicated().sum()}")
print(f"
数据描述性统计:")
print(df.describe())
def clean_data(df):
"""数据清洗:处理缺失值、重复值"""
df_clean = df.copy()
# 处理缺失值
print("处理缺失值...")
for col in df_clean.columns:
if df_clean[col].isnull().sum() > 0:
# 数值列用中位数填充,文本列用众数填充
if df_clean[col].dtype in ['int64', 'float64']:
df_clean[col].fillna(df_clean[col].median(), inplace=True)
else:
mode_value = df_clean[col].mode()
if len(mode_value) > 0:
df_clean[col].fillna(mode_value[0], inplace=True)
# 去除重复行
initial_rows = len(df_clean)
df_clean.drop_duplicates(inplace=True)
removed_duplicates = initial_rows - len(df_clean)
print(f"移除了 {removed_duplicates} 个重复行")
return df_clean
def format_data(df):
"""格式规范:调整数据类型,重命名列名"""
df_formatted = df.copy()
# 重命名列名(去掉空格,统一格式)
df_formatted.columns = [col.strip().replace(' ', '_').lower() for col in df_formatted.columns]
print("列名已标准化")
# 调整数据类型
for col in df_formatted.columns:
# 尝试转换为数值类型
if df_formatted[col].dtype == 'object':
try:
df_formatted[col] = pd.to_numeric(df_formatted[col], errors='ignore')
except:
pass
# 尝试转换为日期类型
if 'date' in col.lower() or '时间' in col:
try:
df_formatted[col] = pd.to_datetime(df_formatted[col], errors='ignore')
except:
pass
return df_formatted
def filter_and_sort_data(df, filter_condition=None, sort_columns=None, ascending=True):
"""数据筛选与排序"""
df_processed = df.copy()
# 数据筛选
if filter_condition is not None:
df_processed = df_processed.query(filter_condition)
print(f"筛选后数据形状: {df_processed.shape}")
# 数据排序
if sort_columns is not None:
if isinstance(sort_columns, str):
sort_columns = [sort_columns]
df_processed = df_processed.sort_values(by=sort_columns, ascending=ascending)
print(f"按 {sort_columns} 排序完成")
return df_processed
# 示例使用
if __name__ == "__main__":
# 创建示例数据
sample_data = {
'姓名': ['张三', '李四', '王五', '赵六', np.nan, '张三'],
'年龄': [25, 30, np.nan, 35, 28, 25],
'工资': [5000, 6000, 7000, np.nan, 5500, 5000],
'部门': ['销售', '技术', '销售', '人事', '技术', '销售'],
'入职日期': ['2020-01-15', '2019-03-20', '2021-07-10', '2018-11-05', '2022-02-28', '2020-01-15']
}
df = pd.DataFrame(sample_data)
print("原始数据:")
print(df)
# 数据诊断
data_diagnosis(df)
# 数据清洗
df_clean = clean_data(df)
print("
清洗后数据:")
print(df_clean)
# 格式规范
df_formatted = format_data(df_clean)
print("
格式化后数据:")
print(df_formatted)
# 数据筛选与排序
df_filtered = filter_and_sort_data(
df_formatted,
filter_condition="年龄 > 26",
sort_columns="工资",
ascending=False
)
print("
筛选排序后数据:")
print(df_filtered)


















暂无评论内容