

摘要
Spring AI Alibaba DataAgent是一个基于Spring AI框架构建的智能数据查询系统,通过自然语言处理技术将用户的自然语言查询转换为SQL语句,并执行查询生成分析报告。系统采用状态图(StateGraph)架构,实现了意图识别、证据召回、查询增强、模式召回、SQL生成与执行、Python数据分析、报告生成等完整的数据分析流程。本文深入分析系统的架构设计、核心组件实现、数据流转机制,为开发者提供全面的技术参考。
1. 项目应用场景
Spring AI Alibaba DataAgent主要应用于以下场景:
1.1 业务数据分析
场景描述:业务人员无需掌握SQL语法,通过自然语言直接查询业务数据库
典型用例:”查询最近一个月销售额最高的前10个产品”
价值:降低数据分析门槛,提升业务决策效率
1.2 数据探索与洞察
场景描述:数据分析师通过自然语言快速探索数据,发现数据规律
典型用例:”分析用户购买行为,找出购买频次与客单价的关系”
价值:加速数据探索过程,支持复杂多步骤分析
1.3 智能报表生成
场景描述:自动将查询结果转换为结构化的分析报告
典型用例:生成包含数据可视化、趋势分析、建议措施的HTML报告
价值:自动化报告生成,提升工作效率
1.4 多数据源统一查询
场景描述:支持MySQL、PostgreSQL、H2、达梦等多种数据库
典型用例:跨数据库的数据关联查询和分析
价值:统一查询接口,简化多数据源管理
2. 学习目标
基于对项目核心代码的分析,设定以下学习目标:
2.1 核心架构理解
目标:深入理解基于状态图(StateGraph)的工作流编排机制
关键代码:
spring-ai-alibaba-data-agent-chat/src/main/java/com/alibaba/cloud/ai/dataagent/config/DataAgentConfiguration.java
学习要点:
状态图的节点定义与边连接
条件路由(ConditionalEdges)的实现机制
状态管理策略(KeyStrategy)的设计
2.2 流式处理机制
目标:掌握基于Reactor的流式数据处理和SSE(Server-Sent Events)推送
关键代码:
spring-ai-alibaba-data-agent-chat/src/main/java/com/alibaba/cloud/ai/dataagent/service/graph/GraphServiceImpl.java
学习要点:
Flux流的创建与转换
流式输出的封装与推送
错误处理与完成回调
2.3 NL2SQL转换技术
目标:理解自然语言到SQL的转换流程,包括查询增强、模式召回、SQL生成与优化
关键代码:
spring-ai-alibaba-data-agent-chat/src/main/java/com/alibaba/cloud/ai/dataagent/node/QueryEnhanceNode.java
spring-ai-alibaba-data-agent-chat/src/main/java/com/alibaba/cloud/ai/dataagent/node/SqlGenerateNode.java
学习要点:
查询改写与关键词提取
向量检索在模式召回中的应用
SQL质量评估与多轮优化
2.4 向量检索与知识库
目标:掌握基于向量数据库的语义检索和知识召回机制
关键代码:
spring-ai-alibaba-data-agent-chat/src/main/java/com/alibaba/cloud/ai/dataagent/node/EvidenceRecallNode.java
学习要点:
文档向量化与存储
相似度检索与混合搜索
业务知识库的构建与应用
2.5 计划生成与执行
目标:理解多步骤执行计划的生成、验证与执行机制
关键代码:
spring-ai-alibaba-data-agent-chat/src/main/java/com/alibaba/cloud/ai/dataagent/node/PlannerNode.java
spring-ai-alibaba-data-agent-chat/src/main/java/com/alibaba/cloud/ai/dataagent/node/PlanExecutorNode.java
学习要点:
计划的结构化表示(Plan、ExecutionStep)
计划验证与修复机制
人工反馈集成
3. 目录结构分析
项目采用多模块Maven结构,清晰的职责划分:
spring-ai-alibaba-data-agent/
├── spring-ai-alibaba-data-agent-chat/ # 核心功能模块(不可独立启动)
│ ├── src/main/java/com/alibaba/cloud/ai/dataagent/
│ │ ├── config/ # 配置类
│ │ │ ├── DataAgentConfiguration.java # 状态图配置与Bean定义
│ │ │ └── DataAgentProperties.java # 配置属性
│ │ ├── node/ # 状态图节点实现
│ │ │ ├── IntentRecognitionNode.java # 意图识别节点
│ │ │ ├── EvidenceRecallNode.java # 证据召回节点
│ │ │ ├── QueryEnhanceNode.java # 查询增强节点
│ │ │ ├── SchemaRecallNode.java # 模式召回节点
│ │ │ ├── TableRelationNode.java # 表关系分析节点
│ │ │ ├── FeasibilityAssessmentNode.java # 可行性评估节点
│ │ │ ├── PlannerNode.java # 计划生成节点
│ │ │ ├── PlanExecutorNode.java # 计划执行节点
│ │ │ ├── SqlGenerateNode.java # SQL生成节点
│ │ │ ├── SqlExecuteNode.java # SQL执行节点
│ │ │ ├── SemanticConsistencyNode.java # 语义一致性校验节点
│ │ │ ├── PythonGenerateNode.java # Python代码生成节点
│ │ │ ├── PythonExecuteNode.java # Python代码执行节点
│ │ │ ├── PythonAnalyzeNode.java # Python分析节点
│ │ │ ├── ReportGeneratorNode.java # 报告生成节点
│ │ │ └── HumanFeedbackNode.java # 人工反馈节点
│ │ ├── dispatcher/ # 路由分发器
│ │ │ ├── IntentRecognitionDispatcher.java # 意图识别路由
│ │ │ ├── QueryEnhanceDispatcher.java # 查询增强路由
│ │ │ ├── TableRelationDispatcher.java # 表关系路由
│ │ │ ├── FeasibilityAssessmentDispatcher.java # 可行性评估路由
│ │ │ ├── PlanExecutorDispatcher.java # 计划执行路由
│ │ │ ├── SQLExecutorDispatcher.java # SQL执行路由
│ │ │ ├── SqlGenerateDispatcher.java # SQL生成路由
│ │ │ ├── SemanticConsistenceDispatcher.java # 语义一致性路由
│ │ │ ├── PythonExecutorDispatcher.java # Python执行路由
│ │ │ └── HumanFeedbackDispatcher.java # 人工反馈路由
│ │ ├── service/ # 业务服务层
│ │ │ ├── graph/ # 图服务
│ │ │ │ ├── GraphService.java # 图服务接口
│ │ │ │ └── GraphServiceImpl.java # 图服务实现
│ │ │ ├── llm/ # LLM服务
│ │ │ ├── nl2sql/ # NL2SQL服务
│ │ │ ├── vectorstore/ # 向量存储服务
│ │ │ ├── schema/ # 模式服务
│ │ │ ├── semantic/ # 语义模型服务
│ │ │ ├── business/ # 业务知识服务
│ │ │ └── hybrid/ # 混合检索服务
│ │ ├── dto/ # 数据传输对象
│ │ ├── entity/ # 实体类
│ │ ├── mapper/ # MyBatis映射器
│ │ ├── pojo/ # 普通Java对象
│ │ │ ├── Plan.java # 执行计划
│ │ │ └── ExecutionStep.java # 执行步骤
│ │ ├── prompt/ # 提示词管理
│ │ │ ├── PromptLoader.java # 提示词加载器
│ │ │ └── PromptHelper.java # 提示词辅助类
│ │ ├── util/ # 工具类
│ │ └── constant/ # 常量定义
│ └── src/main/resources/prompts/ # 提示词模板文件
│
├── spring-ai-alibaba-data-agent-management/ # 管理端模块(可独立启动)
│ ├── src/main/java/com/alibaba/cloud/ai/dataagent/
│ │ ├── DataAgentApplication.java # 主启动类
│ │ ├── controller/ # REST控制器
│ │ │ ├── ChatController.java # 聊天控制器
│ │ │ ├── AgentController.java # 智能体控制器
│ │ │ ├── DatasourceController.java # 数据源控制器
│ │ │ ├── GraphController.java # 图控制器
│ │ │ └── ...
│ │ ├── service/ # 业务服务
│ │ │ ├── AgentService.java # 智能体服务
│ │ │ ├── ChatSessionService.java # 会话服务
│ │ │ └── ...
│ │ └── entity/ # 实体类
│ │ ├── Agent.java # 智能体实体
│ │ ├── ChatSession.java # 会话实体
│ │ └── ChatMessage.java # 消息实体
│ └── src/main/resources/
│ ├── application.yml # 应用配置
│ └── sql/ # SQL初始化脚本
│
├── spring-ai-alibaba-data-agent-common/ # 公共模块
│ └── src/main/java/com/alibaba/cloud/ai/dataagent/common/
│ ├── connector/ # 数据库连接器
│ │ ├── accessor/ # 数据访问器
│ │ │ ├── Accessor.java # 访问器接口
│ │ │ └── impls/ # 各数据库实现
│ │ │ ├── mysql/MySQLDBAccessor.java
│ │ │ ├── postgre/PostgreDBAccessor.java
│ │ │ └── ...
│ │ ├── pool/ # 连接池
│ │ └── ddl/ # DDL操作
│ ├── enums/ # 枚举类
│ ├── request/ # 请求对象
│ └── util/ # 工具类
│
├── spring-ai-alibaba-data-agent-frontend/ # 前端模块
│ ├── src/
│ │ ├── views/ # 视图组件
│ │ │ ├── AgentList.vue # 智能体列表
│ │ │ ├── AgentCreate.vue # 智能体创建
│ │ │ ├── AgentDetail.vue # 智能体详情
│ │ │ └── AgentRun.vue # 智能体运行
│ │ ├── components/ # 组件
│ │ ├── services/ # API服务
│ │ └── router/ # 路由配置
│ └── package.json
│
├── docker-file/ # Docker部署文件
│ ├── docker-compose.yml # Docker Compose配置
│ ├── Dockerfile-backend # 后端镜像
│ └── Dockerfile-frontend # 前端镜像
│
├── tools/ # 工具脚本
│ ├── linter/ # 代码检查工具
│ └── scripts/ # 脚本文件
│
├── pom.xml # 根POM文件
└── README.md # 项目说明文档3.1 模块职责说明
spring-ai-alibaba-data-agent-chat:核心业务逻辑模块,包含所有状态图节点、服务层实现,不可独立运行,供其他模块依赖
spring-ai-alibaba-data-agent-management:Web应用管理端,提供REST API和Web界面,可独立启动
spring-ai-alibaba-data-agent-common:公共代码模块,包含数据库连接器、工具类等,被其他模块共享
spring-ai-alibaba-data-agent-frontend:Vue.js前端应用,提供用户交互界面
4. 关键文件清单
4.1 核心配置文件
|
文件路径 |
说明 |
|
|
应用主配置文件,包含数据库、AI模型、向量库等配置 |
|
|
状态图配置类,定义所有节点和边的关系 |
4.2 核心节点文件
|
文件路径 |
说明 |
|
|
意图识别节点,判断用户输入是闲聊还是数据分析请求 |
|
|
证据召回节点,从向量库检索相关业务知识 |
|
|
查询增强节点,进行查询改写和关键词提取 |
|
|
模式召回节点,召回相关的数据库表和列信息 |
|
|
计划生成节点,生成多步骤执行计划 |
|
|
SQL生成节点,生成SQL语句并进行多轮优化 |
|
|
SQL执行节点,执行SQL查询并返回结果 |
|
|
报告生成节点,生成HTML格式的分析报告 |
4.3 核心服务文件
|
文件路径 |
说明 |
|
|
图服务实现,处理流式请求和状态管理 |
|
|
NL2SQL服务实现,负责SQL生成逻辑 |
4.4 数据模型文件
|
文件路径 |
说明 |
|
|
执行计划数据模型 |
|
|
执行步骤数据模型 |
5. 技术栈分析
5.1 后端技术栈
|
技术 |
版本 |
用途 |
|
Java |
17 |
开发语言 |
|
Spring Boot |
3.4.8 |
Web框架 |
|
Spring AI |
1.0.1 |
AI框架,提供状态图、LLM集成等能力 |
|
Spring AI Alibaba |
1.0.0.4 |
阿里云AI集成,提供DashScope模型支持 |
|
MyBatis |
3.0.4 |
ORM框架 |
|
MySQL |
– |
关系型数据库(管理数据) |
|
Reactor |
– |
响应式编程框架,用于流式处理 |
|
Druid |
1.2.22 |
数据库连接池 |
|
Elasticsearch |
8.18.0 |
向量检索(可选,支持混合搜索) |
5.2 前端技术栈
|
技术 |
版本 |
用途 |
|
Vue.js |
3.x |
前端框架 |
|
Element Plus |
– |
UI组件库 |
|
Axios |
– |
HTTP客户端 |
|
Vite |
– |
构建工具 |
5.3 AI与向量技术
|
技术 |
说明 |
|
DashScope |
阿里云AI服务,提供通义千问模型和文本嵌入模型 |
|
Spring AI VectorStore |
向量存储抽象,默认使用内存向量,支持扩展为Milvus、Elasticsearch等 |
|
混合检索 |
结合向量检索和关键词检索,提升召回准确率 |
5.4 数据库支持
系统支持多种数据库方言:
MySQL
PostgreSQL
H2(测试用)
达梦数据库
6. 系统架构设计
6.1 系统整体架构图
6.2 数据流图
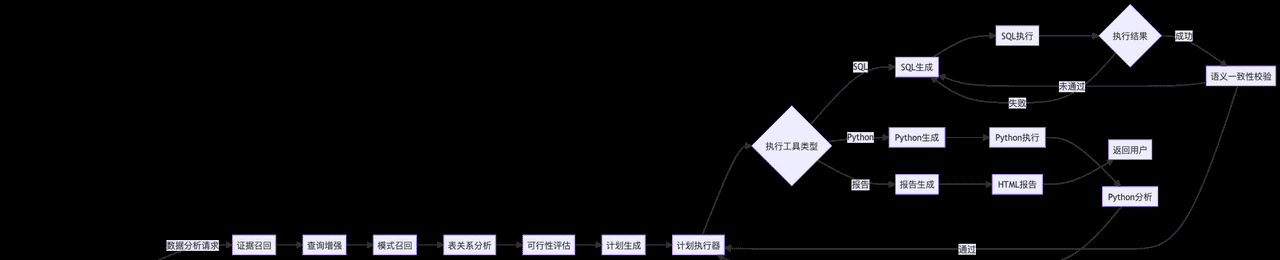
6.3 状态图(核心工作流)
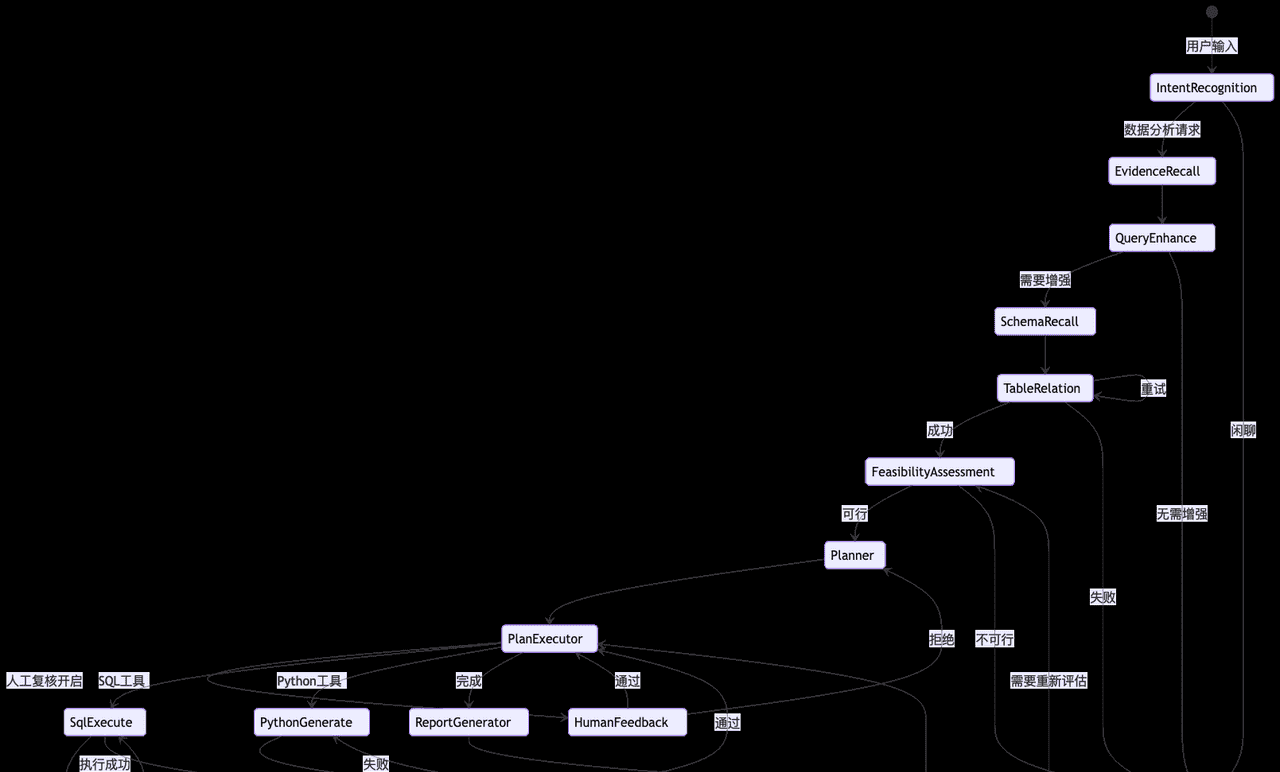
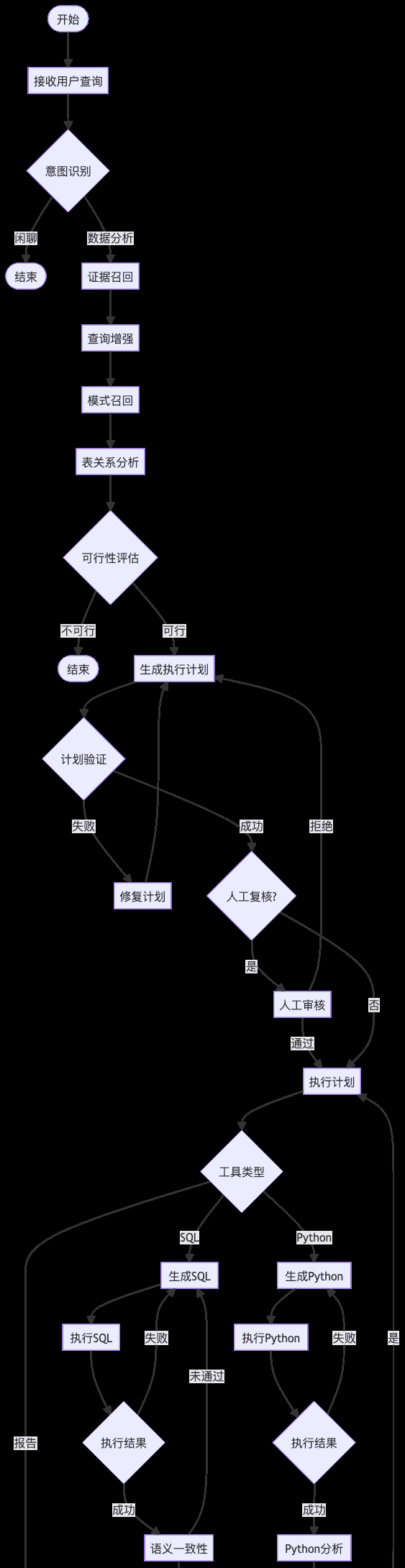
6.4 活动图(完整执行流程)
7. 核心组件实现
7.1 状态图配置(DataAgentConfiguration)
状态图是整个系统的核心编排引擎,定义在
spring-ai-alibaba-data-agent-chat/src/main/java/com/alibaba/cloud/ai/dataagent/config/DataAgentConfiguration.java
@Bean
public StateGraph nl2sqlGraph(NodeBeanUtil nodeBeanUtil) throws GraphStateException {
KeyStrategyFactory keyStrategyFactory = () -> {
HashMap<String, KeyStrategy> keyStrategyHashMap = new HashMap<>();
// User input
keyStrategyHashMap.put(INPUT_KEY, new ReplaceStrategy());
// Agent ID
keyStrategyHashMap.put(AGENT_ID, new ReplaceStrategy());
// Intent recognition
keyStrategyHashMap.put(INTENT_RECOGNITION_NODE_OUTPUT, new ReplaceStrategy());
// QUERY_ENHANCE_NODE节点输出
keyStrategyHashMap.put(QUERY_ENHANCE_NODE_OUTPUT, new ReplaceStrategy());
// Semantic model
keyStrategyHashMap.put(GENEGRATED_SEMANTIC_MODEL_PROMPT, new ReplaceStrategy());
// EVIDENCE节点输出
keyStrategyHashMap.put(EVIDENCE, new ReplaceStrategy());
// schema recall节点输出
keyStrategyHashMap.put(TABLE_DOCUMENTS_FOR_SCHEMA_OUTPUT, new ReplaceStrategy());
keyStrategyHashMap.put(COLUMN_DOCUMENTS__FOR_SCHEMA_OUTPUT, new ReplaceStrategy());
// table relation节点输出
keyStrategyHashMap.put(TABLE_RELATION_OUTPUT, new ReplaceStrategy());
keyStrategyHashMap.put(TABLE_RELATION_EXCEPTION_OUTPUT, new ReplaceStrategy());
keyStrategyHashMap.put(TABLE_RELATION_RETRY_COUNT, new ReplaceStrategy());
// Feasibility Assessment 节点输出
keyStrategyHashMap.put(FEASIBILITY_ASSESSMENT_NODE_OUTPUT, new ReplaceStrategy());
// sql generate节点输出
keyStrategyHashMap.put(SQL_GENERATE_SCHEMA_MISSING_ADVICE, new ReplaceStrategy());
keyStrategyHashMap.put(SQL_GENERATE_OUTPUT, new ReplaceStrategy());
keyStrategyHashMap.put(SQL_GENERATE_COUNT, new ReplaceStrategy());
// Semantic consistence节点输出
keyStrategyHashMap.put(SEMANTIC_CONSISTENCY_NODE_OUTPUT, new ReplaceStrategy());
keyStrategyHashMap.put(SEMANTIC_CONSISTENCY_NODE_RECOMMEND_OUTPUT, new ReplaceStrategy());
// Planner 节点输出
keyStrategyHashMap.put(PLANNER_NODE_OUTPUT, new ReplaceStrategy());
// PlanExecutorNode
keyStrategyHashMap.put(PLAN_CURRENT_STEP, new ReplaceStrategy());
keyStrategyHashMap.put(PLAN_NEXT_NODE, new ReplaceStrategy());
keyStrategyHashMap.put(PLAN_VALIDATION_STATUS, new ReplaceStrategy());
keyStrategyHashMap.put(PLAN_VALIDATION_ERROR, new ReplaceStrategy());
keyStrategyHashMap.put(PLAN_REPAIR_COUNT, new ReplaceStrategy());
// SQL Execute 节点输出
keyStrategyHashMap.put(SQL_EXECUTE_NODE_OUTPUT, new ReplaceStrategy());
keyStrategyHashMap.put(SQL_EXECUTE_NODE_EXCEPTION_OUTPUT, new ReplaceStrategy());
// Python代码运行相关
keyStrategyHashMap.put(SQL_RESULT_LIST_MEMORY, new ReplaceStrategy());
keyStrategyHashMap.put(PYTHON_IS_SUCCESS, new ReplaceStrategy());
keyStrategyHashMap.put(PYTHON_TRIES_COUNT, new ReplaceStrategy());
keyStrategyHashMap.put(PYTHON_EXECUTE_NODE_OUTPUT, new ReplaceStrategy());
keyStrategyHashMap.put(PYTHON_GENERATE_NODE_OUTPUT, new ReplaceStrategy());
keyStrategyHashMap.put(PYTHON_ANALYSIS_NODE_OUTPUT, new ReplaceStrategy());
// NL2SQL相关
keyStrategyHashMap.put(IS_ONLY_NL2SQL, new ReplaceStrategy());
keyStrategyHashMap.put(ONLY_NL2SQL_OUTPUT, new ReplaceStrategy());
// Human Review keys
keyStrategyHashMap.put(HUMAN_REVIEW_ENABLED, new ReplaceStrategy());
// Final result
keyStrategyHashMap.put(RESULT, new ReplaceStrategy());
return keyStrategyHashMap;
};
StateGraph stateGraph = new StateGraph(NL2SQL_GRAPH_NAME, keyStrategyFactory)
.addNode(INTENT_RECOGNITION_NODE, nodeBeanUtil.getNodeBeanAsync(IntentRecognitionNode.class))
.addNode(EVIDENCE_RECALL_NODE, nodeBeanUtil.getNodeBeanAsync(EvidenceRecallNode.class))
.addNode(QUERY_ENHANCE_NODE, nodeBeanUtil.getNodeBeanAsync(QueryEnhanceNode.class))
.addNode(SCHEMA_RECALL_NODE, nodeBeanUtil.getNodeBeanAsync(SchemaRecallNode.class))
.addNode(TABLE_RELATION_NODE, nodeBeanUtil.getNodeBeanAsync(TableRelationNode.class))
.addNode(FEASIBILITY_ASSESSMENT_NODE, nodeBeanUtil.getNodeBeanAsync(FeasibilityAssessmentNode.class))
.addNode(SQL_GENERATE_NODE, nodeBeanUtil.getNodeBeanAsync(SqlGenerateNode.class))
.addNode(PLANNER_NODE, nodeBeanUtil.getNodeBeanAsync(PlannerNode.class))
.addNode(PLAN_EXECUTOR_NODE, nodeBeanUtil.getNodeBeanAsync(PlanExecutorNode.class))
.addNode(SQL_EXECUTE_NODE, nodeBeanUtil.getNodeBeanAsync(SqlExecuteNode.class))
.addNode(PYTHON_GENERATE_NODE, nodeBeanUtil.getNodeBeanAsync(PythonGenerateNode.class))
.addNode(PYTHON_EXECUTE_NODE, nodeBeanUtil.getNodeBeanAsync(PythonExecuteNode.class))
.addNode(PYTHON_ANALYZE_NODE, nodeBeanUtil.getNodeBeanAsync(PythonAnalyzeNode.class))
.addNode(REPORT_GENERATOR_NODE, nodeBeanUtil.getNodeBeanAsync(ReportGeneratorNode.class))
.addNode(SEMANTIC_CONSISTENCY_NODE, nodeBeanUtil.getNodeBeanAsync(SemanticConsistencyNode.class))
.addNode(HUMAN_FEEDBACK_NODE, nodeBeanUtil.getNodeBeanAsync(HumanFeedbackNode.class));
stateGraph.addEdge(START, INTENT_RECOGNITION_NODE)
.addConditionalEdges(INTENT_RECOGNITION_NODE, edge_async(new IntentRecognitionDispatcher()),
Map.of(EVIDENCE_RECALL_NODE, EVIDENCE_RECALL_NODE, END, END))
.addEdge(EVIDENCE_RECALL_NODE, QUERY_ENHANCE_NODE)
.addConditionalEdges(QUERY_ENHANCE_NODE, edge_async(new QueryEnhanceDispatcher()),
Map.of(SCHEMA_RECALL_NODE, SCHEMA_RECALL_NODE, END, END))
.addEdge(SCHEMA_RECALL_NODE, TABLE_RELATION_NODE)
.addConditionalEdges(TABLE_RELATION_NODE, edge_async(new TableRelationDispatcher()),
Map.of(FEASIBILITY_ASSESSMENT_NODE, FEASIBILITY_ASSESSMENT_NODE, END, END, TABLE_RELATION_NODE,
TABLE_RELATION_NODE)) // retry
.addConditionalEdges(FEASIBILITY_ASSESSMENT_NODE, edge_async(new FeasibilityAssessmentDispatcher()),
Map.of(PLANNER_NODE, PLANNER_NODE, END, END))
// The edge from PlannerNode now goes to PlanExecutorNode for validation and
// execution
.addEdge(PLANNER_NODE, PLAN_EXECUTOR_NODE)
// python nodes
.addEdge(PYTHON_GENERATE_NODE, PYTHON_EXECUTE_NODE)
.addConditionalEdges(PYTHON_EXECUTE_NODE, edge_async(new PythonExecutorDispatcher()),
Map.of(PYTHON_ANALYZE_NODE, PYTHON_ANALYZE_NODE, END, END, PYTHON_GENERATE_NODE,
PYTHON_GENERATE_NODE))
.addEdge(PYTHON_ANALYZE_NODE, PLAN_EXECUTOR_NODE)
// The dispatcher at PlanExecutorNode will decide the next step
.addConditionalEdges(PLAN_EXECUTOR_NODE, edge_async(new PlanExecutorDispatcher()), Map.of(
// If validation fails, go back to PlannerNode to repair
PLANNER_NODE, PLANNER_NODE,
// If validation passes, proceed to the correct execution node
SQL_EXECUTE_NODE, SQL_EXECUTE_NODE, PYTHON_GENERATE_NODE, PYTHON_GENERATE_NODE,
REPORT_GENERATOR_NODE, REPORT_GENERATOR_NODE,
// If human review is enabled, go to human_feedback node
HUMAN_FEEDBACK_NODE, HUMAN_FEEDBACK_NODE,
// If max repair attempts are reached, end the process
END, END))
// Human feedback node routing
.addConditionalEdges(HUMAN_FEEDBACK_NODE, edge_async(new HumanFeedbackDispatcher()), Map.of(
// If plan is rejected, go back to PlannerNode
PLANNER_NODE, PLANNER_NODE,
// If plan is approved, continue with execution
PLAN_EXECUTOR_NODE, PLAN_EXECUTOR_NODE,
// If max repair attempts are reached, end the process
END, END))
.addEdge(REPORT_GENERATOR_NODE, END)
.addConditionalEdges(SQL_EXECUTE_NODE, edge_async(new SQLExecutorDispatcher()),
Map.of(SQL_GENERATE_NODE, SQL_GENERATE_NODE, SEMANTIC_CONSISTENCY_NODE, SEMANTIC_CONSISTENCY_NODE))
.addConditionalEdges(SQL_GENERATE_NODE, edge_async(new SqlGenerateDispatcher()),
Map.of(FEASIBILITY_ASSESSMENT_NODE, FEASIBILITY_ASSESSMENT_NODE, END, END, SQL_EXECUTE_NODE,
SQL_EXECUTE_NODE))
.addConditionalEdges(SEMANTIC_CONSISTENCY_NODE, edge_async(new SemanticConsistenceDispatcher()),
Map.of(SQL_GENERATE_NODE, SQL_GENERATE_NODE, PLAN_EXECUTOR_NODE, PLAN_EXECUTOR_NODE));
GraphRepresentation graphRepresentation = stateGraph.getGraph(GraphRepresentation.Type.PLANTUML,
"workflow graph");
log.info("workflow in PlantUML format as follows
" + graphRepresentation.content() + "
");
return stateGraph;
}关键设计点:
KeyStrategy:定义状态键的更新策略,使用
ReplaceStrategy
节点注册:通过
addNode
边连接:使用
addEdge
addConditionalEdges
条件路由:通过Dispatcher实现条件判断,决定下一步执行哪个节点
7.2 图服务实现(GraphServiceImpl)
图服务负责处理流式请求,管理状态图的执行:
@Override
public void graphStreamProcess(Sinks.Many<ServerSentEvent<GraphNodeResponse>> sink, GraphRequest graphRequest) {
if (StringUtils.hasText(graphRequest.getHumanFeedbackContent())) {
handleHumanFeedback(sink, graphRequest);
}
else {
handleNewProcess(sink, graphRequest);
}
}
private void handleNewProcess(Sinks.Many<ServerSentEvent<GraphNodeResponse>> sink, GraphRequest graphRequest) {
if (!StringUtils.hasText(graphRequest.getThreadId())) {
graphRequest.setThreadId(UUID.randomUUID().toString());
}
String query = graphRequest.getQuery();
String agentId = graphRequest.getAgentId();
String threadId = graphRequest.getThreadId();
boolean nl2sqlOnly = graphRequest.isNl2sqlOnly();
boolean humanReviewEnabled = graphRequest.isHumanFeedback() & !(nl2sqlOnly);
if (!StringUtils.hasText(threadId) || !StringUtils.hasText(agentId) || !StringUtils.hasText(query)) {
throw new IllegalArgumentException("Invalid arguments");
}
Flux<NodeOutput> nodeOutputFlux = compiledGraph.fluxStream(Map.of(IS_ONLY_NL2SQL, nl2sqlOnly, INPUT_KEY, query,
AGENT_ID, agentId, HUMAN_REVIEW_ENABLED, humanReviewEnabled),
RunnableConfig.builder().threadId(threadId).build());
CompletableFuture
.runAsync(() -> nodeOutputFlux.subscribe(output -> handleNodeOutput(graphRequest, output, sink),
error -> handleStreamError(agentId, threadId, error, sink),
() -> handleStreamComplete(agentId, threadId, sink)), executor);
}
private void handleHumanFeedback(Sinks.Many<ServerSentEvent<GraphNodeResponse>> sink, GraphRequest graphRequest) {
String agentId = graphRequest.getAgentId();
String threadId = graphRequest.getThreadId();
String feedbackContent = graphRequest.getHumanFeedbackContent();
if (!StringUtils.hasText(threadId) || !StringUtils.hasText(agentId) || !StringUtils.hasText(feedbackContent)) {
throw new IllegalArgumentException("Invalid arguments");
}
Map<String, Object> feedbackData = Map.of("feedback", !graphRequest.isRejectedPlan(), "feedback_content",
feedbackContent);
OverAllState.HumanFeedback humanFeedback = new OverAllState.HumanFeedback(feedbackData, HUMAN_FEEDBACK_NODE);
StateSnapshot stateSnapshot = compiledGraph.getState(RunnableConfig.builder().threadId(threadId).build());
OverAllState resumeState = stateSnapshot.state();
resumeState.withResume();
resumeState.withHumanFeedback(humanFeedback);
Flux<NodeOutput> nodeOutputFlux = compiledGraph.fluxStreamFromInitialNode(resumeState,
RunnableConfig.builder().threadId(threadId).build());
CompletableFuture
.runAsync(() -> nodeOutputFlux.subscribe(output -> handleNodeOutput(graphRequest, output, sink),
error -> handleStreamError(agentId, threadId, error, sink),
() -> handleStreamComplete(agentId, threadId, sink)), executor);
}关键设计点:
流式处理:使用
Flux<NodeOutput>
线程隔离:每个请求使用独立的
threadId
状态恢复:人工反馈场景下,从历史状态恢复执行
SSE推送:通过
Sinks.Many<ServerSentEvent>
7.3 意图识别节点(IntentRecognitionNode)
意图识别是流程的第一个节点,判断用户输入是数据分析请求还是闲聊:
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 获取用户输入
String userInput = StateUtil.getStringValue(state, INPUT_KEY);
log.info("User input for intent recognition: {}", userInput);
// 构建意图识别提示,多轮对话暂时为空
String prompt = PromptHelper.buildIntentRecognitionPrompt(null, userInput);
log.debug("Built intent recognition prompt as follows
{}
", prompt);
// 调用LLM进行意图识别
Flux<ChatResponse> responseFlux = llmService.callUser(prompt);
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGenerator(this.getClass(), state,
responseFlux,
Flux.just(ChatResponseUtil.createResponse("正在进行意图识别..."),
ChatResponseUtil.createPureResponse(TextType.JSON.getStartSign())),
Flux.just(ChatResponseUtil.createPureResponse(TextType.JSON.getEndSign()),
ChatResponseUtil.createResponse("
意图识别完成!")),
result -> Map.of(INTENT_RECOGNITION_NODE_OUTPUT, result));
return Map.of(INTENT_RECOGNITION_NODE_OUTPUT, generator);
}关键设计点:
状态读取:从
OverAllState
流式输出:使用
FluxUtil.createStreamingGenerator
文本类型标记:使用
TextType.JSON
7.4 证据召回节点(EvidenceRecallNode)
证据召回节点从向量库中检索相关的业务知识:
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 从state中提取question和agentId
String question = StateUtil.getStringValue(state, INPUT_KEY);
String agentId = StateUtil.getStringValue(state, AGENT_ID);
Assert.hasText(agentId, "Agent ID cannot be empty.");
log.info("Extracting keywords before getting evidence in question: {}", question);
log.debug("Agent ID: {}", agentId);
// 构建关键词提取提示词
String prompt = PromptConstant.getQuestionToKeywordsPromptTemplate().render(Map.of("question", question));
log.debug("Built evidence keyword extraction prompt as follows
{}
", prompt);
// 调用LLM提取关键词
Flux<ChatResponse> responseFlux = llmService.callUser(prompt);
Sinks.Many<String> evidenceDisplaySink = Sinks.many().multicast().onBackpressureBuffer();
final Map<String, Object> resultMap = new HashMap<>();
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGenerator(this.getClass(), state,
responseFlux,
Flux.just(ChatResponseUtil.createResponse("正在获取关键词..."),
ChatResponseUtil.createPureResponse(TextType.JSON.getStartSign())),
Flux.just(ChatResponseUtil.createPureResponse(TextType.JSON.getEndSign()),
ChatResponseUtil.createResponse("
关键词获取完成!")),
result -> {
resultMap.putAll(getEvidences(result, agentId, evidenceDisplaySink));
return resultMap;
});
Flux<GraphResponse<StreamingOutput>> evidenceFlux = FluxConverter.builder()
.startingNode(this.getClass().getSimpleName())
.startingState(state)
.mapResult(r -> resultMap)
.build(evidenceDisplaySink.asFlux().map(ChatResponseUtil::createPureResponse));
return Map.of(EVIDENCE, generator.concatWith(evidenceFlux));
}关键设计点:
关键词提取:先通过LLM提取查询关键词
向量检索:使用关键词在向量库中检索相关业务知识
流式推送:使用
Sinks.Many
7.5 SQL生成节点(SqlGenerateNode)
SQL生成节点负责生成SQL语句,并在执行失败时进行多轮优化:
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// Get necessary input parameters
Plan plan = PlanProcessUtil.getPlan(state);
ExecutionStep executionStep = PlanProcessUtil.getCurrentExecutionStep(state);
ExecutionStep.ToolParameters toolParameters = executionStep.getToolParameters();
// Execute business logic first - determine what needs to be regenerated
Map<String, Object> result = new HashMap<>(Map.of(SQL_GENERATE_OUTPUT, SQL_EXECUTE_NODE));
String displayMessage;
Consumer<String> finalSqlConsumer = finalSql -> {
toolParameters.setSqlQuery(finalSql);
log.info("[{}] Regenerated SQL: {}", this.getClass().getSimpleName(), finalSql);
result.put(PLANNER_NODE_OUTPUT, plan.toJsonStr());
};
Flux<String> sqlFlux;
if (StateUtil.hasValue(state, SQL_EXECUTE_NODE_EXCEPTION_OUTPUT)) {
displayMessage = "检测到SQL执行异常,开始重新生成SQL...";
sqlFlux = handleSqlExecutionException(state, toolParameters, finalSqlConsumer);
}
else if (isSemanticConsistencyFailed(state)) {
displayMessage = "语义一致性校验未通过,开始重新生成SQL...";
sqlFlux = handleSemanticConsistencyFailure(state, toolParameters, finalSqlConsumer);
}
else {
throw new IllegalStateException("SQL generation node was called unexpectedly");
}
// Create display flux for user experience only
Flux<ChatResponse> preFlux = Flux.just(ChatResponseUtil.createResponse(displayMessage));
Flux<ChatResponse> displayFlux = preFlux.concatWith(sqlFlux.map(ChatResponseUtil::createResponse))
.concatWith(Flux.just(ChatResponseUtil.createResponse("SQL重新生成完成,准备执行")));
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGeneratorWithMessages(this.getClass(),
state, v -> {
log.debug("resultMap: {}", result);
return result;
}, displayFlux);
return Map.of(SQL_GENERATE_OUTPUT, generator);
}关键设计点:
多轮优化:通过
expand
质量评估:对生成的SQL进行语法、安全性、性能三个维度的评分
异常处理:区分SQL执行异常和语义一致性失败两种场景
7.6 SQL执行节点(SqlExecuteNode)
SQL执行节点负责执行SQL查询并返回结果:
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
ExecutionStep executionStep = PlanProcessUtil.getCurrentExecutionStep(state);
Integer currentStep = PlanProcessUtil.getCurrentStepNumber(state);
ExecutionStep.ToolParameters toolParameters = executionStep.getToolParameters();
String sqlQuery = toolParameters.getSqlQuery();
log.info("Executing SQL query: {}", sqlQuery);
log.info("Step description: {}", toolParameters.getDescription());
// Get the agent ID from the state
String agentIdStr = StateUtil.getStringValue(state, Constant.AGENT_ID);
if (agentIdStr == null || agentIdStr.trim().isEmpty()) {
throw new IllegalStateException("Agent ID cannot be empty.");
}
Integer agentId = Integer.valueOf(agentIdStr);
// Dynamically get the data source configuration for an agent
DbConfig dbConfig = databaseUtil.getAgentDbConfig(agentId);
return executeSqlQuery(state, currentStep, sqlQuery, dbConfig, agentId);
}关键设计点:
动态数据源:根据Agent ID动态获取对应的数据库配置
结果累积:将每个步骤的执行结果累积到
SQL_EXECUTE_NODE_OUTPUT
异常捕获:捕获SQL执行异常,触发SQL重新生成流程
7.7 计划生成节点(PlannerNode)
计划生成节点根据用户查询和Schema信息生成多步骤执行计划:
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 获取查询增强节点的输出
String canonicalQuery = StateUtil.getCanonicalQuery(state);
log.info("Using processed query for planning: {}", canonicalQuery);
// 是否为NL2SQL模式
Boolean onlyNl2sql = state.value(IS_ONLY_NL2SQL, false);
// 检查是否为修复模式
String validationError = StateUtil.getStringValue(state, PLAN_VALIDATION_ERROR, null);
if (validationError != null) {
log.info("Regenerating plan with user feedback: {}", validationError);
}
else {
log.info("Generating initial plan");
}
// 构建提示参数
String semanticModel = (String) state.value(GENEGRATED_SEMANTIC_MODEL_PROMPT).orElse("");
SchemaDTO schemaDTO = StateUtil.getObjectValue(state, TABLE_RELATION_OUTPUT, SchemaDTO.class);
String schemaStr = PromptHelper.buildMixMacSqlDbPrompt(schemaDTO, true);
// 构建用户提示
String userPrompt = buildUserPrompt(canonicalQuery, validationError, state);
String evidence = StateUtil.getStringValue(state, EVIDENCE);
// 构建模板参数
Map<String, Object> params = Map.of("user_question", userPrompt, "schema", schemaStr, "evidence", evidence,
"semantic_model", semanticModel, "plan_validation_error", formatValidationError(validationError));
// 生成计划
String plannerPrompt = (onlyNl2sql ? PromptConstant.getPlannerNl2sqlOnlyTemplate()
: PromptConstant.getPlannerPromptTemplate())
.render(params);
log.debug("Planner prompt: as follows
{}
", plannerPrompt);
Flux<ChatResponse> chatResponseFlux = Flux.concat(
Flux.just(ChatResponseUtil.createPureResponse(TextType.JSON.getStartSign())),
llmService.callUser(plannerPrompt),
Flux.just(ChatResponseUtil.createPureResponse(TextType.JSON.getEndSign())));
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGeneratorWithMessages(this.getClass(),
state, v -> Map.of(PLANNER_NODE_OUTPUT, v.substring(TextType.JSON.getStartSign().length(),
v.length() - TextType.JSON.getEndSign().length())),
chatResponseFlux);
return Map.of(PLANNER_NODE_OUTPUT, generator);
}关键设计点:
计划修复:支持根据验证错误重新生成计划
模式区分:NL2SQL模式和完整模式使用不同的提示词模板
上下文整合:整合Schema、证据、语义模型等多方面信息
7.8 报告生成节点(ReportGeneratorNode)
报告生成节点将执行结果转换为HTML格式的分析报告:
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// Get necessary input parameters
String plannerNodeOutput = StateUtil.getStringValue(state, PLANNER_NODE_OUTPUT);
String userInput = StateUtil.getCanonicalQuery(state);
Integer currentStep = StateUtil.getObjectValue(state, PLAN_CURRENT_STEP, Integer.class, 1);
@SuppressWarnings("unchecked")
HashMap<String, String> executionResults = StateUtil.getObjectValue(state, SQL_EXECUTE_NODE_OUTPUT,
HashMap.class, new HashMap<>());
log.info("Planner node output: {}", plannerNodeOutput);
// Parse plan and get current step
Plan plan = converter.convert(plannerNodeOutput);
ExecutionStep executionStep = getCurrentExecutionStep(plan, currentStep);
String summaryAndRecommendations = executionStep.getToolParameters().getSummaryAndRecommendations();
// Generate report streaming flux
Flux<ChatResponse> reportGenerationFlux = generateReport(userInput, plan, executionResults,
summaryAndRecommendations);
// Use utility class to create streaming generator with content collection
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGeneratorWithMessages(this.getClass(),
state, "开始生成报告...", "报告生成完成!", reportContent -> {
log.info("Generated report content: {}", reportContent);
Map<String, Object> result = new HashMap<>();
result.put(RESULT, reportContent);
result.put(SQL_EXECUTE_NODE_OUTPUT, null);
result.put(PLAN_CURRENT_STEP, null);
result.put(PLANNER_NODE_OUTPUT, null);
return result;
},
Flux.concat(Flux.just(ChatResponseUtil.createPureResponse(TextType.HTML.getStartSign())),
reportGenerationFlux,
Flux.just(ChatResponseUtil.createPureResponse(TextType.HTML.getEndSign()))));
return Map.of(RESULT, generator);
}关键设计点:
结果整合:整合所有执行步骤的结果
HTML输出:使用
TextType.HTML
状态清理:报告生成后清理中间状态
8. 核心流程与逻辑解析
8.1 完整查询流程示例
以查询”最近一个月销售额最高的前10个产品”为例,展示完整的执行流程:
步骤1:意图识别
用户输入:”最近一个月销售额最高的前10个产品”
// 获取用户输入
String userInput = StateUtil.getStringValue(state, INPUT_KEY);
log.info("User input for intent recognition: {}", userInput);
// 构建意图识别提示,多轮对话暂时为空意图识别节点调用LLM判断这是数据分析请求,输出:
{"intent": "data_analysis"}
步骤2:证据召回
private Map<String, Object> getEvidences(String llmOutput, String agentId, Sinks.Many<String> sink) {
try {
List<String> keywords = extractKeywords(llmOutput);
if (null == keywords || keywords.isEmpty()) {
log.debug("No keywords extracted from LLM output");
sink.tryEmitNext("未找到关键词!
");
return Map.of(EVIDENCE, "无");
}
// 将关键词列表用空格拼接成字符串
sink.tryEmitNext("关键词:
");
keywords.forEach(keyword -> sink.tryEmitNext(keyword + " "));
sink.tryEmitNext("
");
String keywordsString = String.join(" ", keywords);
log.debug("Joined keywords string: {}", keywordsString);
sink.tryEmitNext("正在获取证据...");
// 获取业务知识和智能体的知识
List<Document> businessTermDocuments = vectorStoreService
.getDocumentsForAgent(agentId, keywordsString, DocumentMetadataConstant.BUSINESS_TERM)
.stream()
.toList();
// 检查是否有证据文档
if (businessTermDocuments.isEmpty()) {
log.debug("No evidence documents found for agent: {} with keywords: {}", agentId, keywordsString);
sink.tryEmitNext("未找到证据!
");
return Map.of(EVIDENCE, "无");
}
// 构建业务知识提示
String businessKnowledgePrompt = PromptHelper.buildBusinessKnowledgePrompt(
businessTermDocuments.stream().map(Document::getText).collect(Collectors.joining(";
")));
// TODO 根据知识库模板渲染智能体的知识,然后拼接成EVIDENCE。 businessKnowledgePrompt + "
" +
// agentKnowledgePrompt;
String evidence = businessKnowledgePrompt + "
";
// 输出证据内容
sink.tryEmitNext("证据内容:
");
businessTermDocuments.forEach(e -> sink.tryEmitNext(e.getText() + "
"));
// TODO agentKnowledge.forEach
// 返回结果
return Map.of(EVIDENCE, evidence);提取关键词:[“销售额”, “产品”, “最近一个月”],从向量库检索相关业务知识,如”销售额=订单金额总和”等。
步骤3:查询增强
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 获取用户输入
String userInput = StateUtil.getStringValue(state, INPUT_KEY);
log.info("User input for query enhance: {}", userInput);
String evidence = StateUtil.getStringValue(state, EVIDENCE);
// 构建查询处理提示,多轮对话暂时为空
String prompt = PromptHelper.buildQueryEnhancePrompt(null, userInput, evidence);
log.debug("Built query enhance prompt as follows
{}
", prompt);
// 调用LLM进行查询处理
Flux<ChatResponse> responseFlux = llmService.callUser(prompt);
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGenerator(this.getClass(), state,
responseFlux,
Flux.just(ChatResponseUtil.createResponse("正在进行问题增强..."),
ChatResponseUtil.createPureResponse(TextType.JSON.getStartSign())),
Flux.just(ChatResponseUtil.createPureResponse(TextType.JSON.getEndSign()),
ChatResponseUtil.createResponse("
问题增强完成!")),
this::handleQueryEnhance);
return Map.of(QUERY_ENHANCE_NODE_OUTPUT, generator);
}输出规范化查询:”查询最近30天内,按销售额降序排列的前10个产品”。
步骤4:模式召回
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// get input information
QueryEnhanceOutputDTO queryEnhanceOutputDTO = StateUtil.getObjectValue(state, QUERY_ENHANCE_NODE_OUTPUT,
QueryEnhanceOutputDTO.class);
String input = queryEnhanceOutputDTO.getCanonicalQuery();
List<String> keywords = queryEnhanceOutputDTO.getConsolidatedKeywords();
String agentId = StateUtil.getStringValue(state, AGENT_ID);
// Execute business logic first - recall schema information immediately
List<Document> tableDocuments = new ArrayList<>(schemaService.getTableDocumentsForAgent(agentId, input));
List<Document> columnDocumentsByKeywords = schemaService.getColumnDocumentsByKeywordsForAgent(agentId, keywords,
tableDocuments);
// extract table names
List<String> recallTableNames = extractTableName(tableDocuments);
// extract column names
List<String> recallColumnNames = extractColumnName(columnDocumentsByKeywords);
Flux<ChatResponse> displayFlux = Flux.create(emitter -> {
emitter.next(ChatResponseUtil.createResponse("开始初步召回Schema信息..."));
emitter.next(ChatResponseUtil.createResponse(
"初步表信息召回完成,数量: " + tableDocuments.size() + ",表名: " + String.join(", ", recallTableNames)));
emitter.next(ChatResponseUtil.createResponse("初步列信息召回完成,数量: " + columnDocumentsByKeywords.size() + ",列名: "
+ String.join(", ", recallColumnNames)));
emitter.next(ChatResponseUtil.createResponse("初步Schema信息召回完成."));
emitter.complete();
});
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGeneratorWithMessages(this.getClass(),
state, currentState -> {
return Map.of(TABLE_DOCUMENTS_FOR_SCHEMA_OUTPUT, tableDocuments,
COLUMN_DOCUMENTS__FOR_SCHEMA_OUTPUT, columnDocumentsByKeywords);
}, displayFlux);
// Return the processing result
return Map.of(SCHEMA_RECALL_NODE_OUTPUT, generator);
}召回相关表:
orders
products
orders.amount
orders.product_id
orders.order_date
步骤5:计划生成
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 获取查询增强节点的输出
String canonicalQuery = StateUtil.getCanonicalQuery(state);
log.info("Using processed query for planning: {}", canonicalQuery);
// 是否为NL2SQL模式
Boolean onlyNl2sql = state.value(IS_ONLY_NL2SQL, false);
// 检查是否为修复模式
String validationError = StateUtil.getStringValue(state, PLAN_VALIDATION_ERROR, null);
if (validationError != null) {
log.info("Regenerating plan with user feedback: {}", validationError);
}
else {
log.info("Generating initial plan");
}
// 构建提示参数
String semanticModel = (String) state.value(GENEGRATED_SEMANTIC_MODEL_PROMPT).orElse("");
SchemaDTO schemaDTO = StateUtil.getObjectValue(state, TABLE_RELATION_OUTPUT, SchemaDTO.class);
String schemaStr = PromptHelper.buildMixMacSqlDbPrompt(schemaDTO, true);
// 构建用户提示
String userPrompt = buildUserPrompt(canonicalQuery, validationError, state);
String evidence = StateUtil.getStringValue(state, EVIDENCE);
// 构建模板参数
Map<String, Object> params = Map.of("user_question", userPrompt, "schema", schemaStr, "evidence", evidence,
"semantic_model", semanticModel, "plan_validation_error", formatValidationError(validationError));
// 生成计划
String plannerPrompt = (onlyNl2sql ? PromptConstant.getPlannerNl2sqlOnlyTemplate()
: PromptConstant.getPlannerPromptTemplate())
.render(params);
log.debug("Planner prompt: as follows
{}
", plannerPrompt);
Flux<ChatResponse> chatResponseFlux = Flux.concat(
Flux.just(ChatResponseUtil.createPureResponse(TextType.JSON.getStartSign())),
llmService.callUser(plannerPrompt),
Flux.just(ChatResponseUtil.createPureResponse(TextType.JSON.getEndSign())));
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGeneratorWithMessages(this.getClass(),
state, v -> Map.of(PLANNER_NODE_OUTPUT, v.substring(TextType.JSON.getStartSign().length(),
v.length() - TextType.JSON.getEndSign().length())),
chatResponseFlux);
return Map.of(PLANNER_NODE_OUTPUT, generator);
}生成执行计划:
{
"thoughtProcess": "需要查询最近一个月的销售额,按产品分组汇总,然后排序取前10",
"executionPlan": [
{
"step": 1,
"toolToUse": "sql_execute",
"toolParameters": {
"description": "查询最近30天的订单,按产品ID分组计算销售额",
"sqlQuery": "SELECT product_id, SUM(amount) as sales FROM orders WHERE order_date >= DATE_SUB(NOW(), INTERVAL 30 DAY) GROUP BY product_id ORDER BY sales DESC LIMIT 10"
}
}
]
}步骤6:SQL执行
private Map<String, Object> executeSqlQuery(OverAllState state, Integer currentStep, String sqlQuery,
DbConfig dbConfig, Integer agentId) {
// Execute business logic first - actual SQL execution
DbQueryParameter dbQueryParameter = new DbQueryParameter();
dbQueryParameter.setSql(sqlQuery);
dbQueryParameter.setSchema(dbConfig.getSchema());
Accessor dbAccessor = databaseUtil.getAgentAccessor(agentId);
try {
// Execute SQL query and get results immediately
ResultSetBO resultSetBO = dbAccessor.executeSqlAndReturnObject(dbConfig, dbQueryParameter);
String jsonStr = resultSetBO.toJsonStr();
// Update step results with the query output
Map<String, String> existingResults = StateUtil.getObjectValue(state, SQL_EXECUTE_NODE_OUTPUT, Map.class,
new HashMap<>());
Map<String, String> updatedResults = PlanProcessUtil.addStepResult(existingResults, currentStep, jsonStr);
log.info("SQL execution successful, result count: {}",
resultSetBO.getData() != null ? resultSetBO.getData().size() : 0);
// Prepare the final result object
// Store List of SQL query results for use by code execution node
Map<String, Object> result = Map.of(SQL_EXECUTE_NODE_OUTPUT, updatedResults,
SQL_EXECUTE_NODE_EXCEPTION_OUTPUT, "", Constant.SQL_RESULT_LIST_MEMORY, resultSetBO.getData());
// Create display flux for user experience only
Flux<ChatResponse> displayFlux = Flux.create(emitter -> {
// todo: 先返回Flux流,再去执行SQL查询
emitter.next(ChatResponseUtil.createResponse("开始执行SQL..."));
emitter.next(ChatResponseUtil.createResponse("执行SQL查询"));
emitter.next(ChatResponseUtil.createPureResponse(TextType.SQL.getStartSign()));
emitter.next(ChatResponseUtil.createResponse(sqlQuery));
emitter.next(ChatResponseUtil.createPureResponse(TextType.SQL.getEndSign()));
emitter.next(ChatResponseUtil.createResponse("执行SQL完成"));
emitter.next(ChatResponseUtil.createResponse("SQL查询结果:"));
emitter.next(ChatResponseUtil.createPureResponse(TextType.RESULT_SET.getStartSign()));
emitter.next(ChatResponseUtil.createPureResponse(jsonStr));
emitter.next(ChatResponseUtil.createPureResponse(TextType.RESULT_SET.getEndSign()));
emitter.complete();
});
// Create generator using utility class, returning pre-computed business logic
// result
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil
.createStreamingGeneratorWithMessages(this.getClass(), state, v -> result, displayFlux);
return Map.of(SQL_EXECUTE_NODE_OUTPUT, generator);
}执行SQL,返回结果:
[
{"product_id": 101, "sales": 50000},
{"product_id": 102, "sales": 45000},
...
]步骤7:报告生成
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// Get necessary input parameters
String plannerNodeOutput = StateUtil.getStringValue(state, PLANNER_NODE_OUTPUT);
String userInput = StateUtil.getCanonicalQuery(state);
Integer currentStep = StateUtil.getObjectValue(state, PLAN_CURRENT_STEP, Integer.class, 1);
@SuppressWarnings("unchecked")
HashMap<String, String> executionResults = StateUtil.getObjectValue(state, SQL_EXECUTE_NODE_OUTPUT,
HashMap.class, new HashMap<>());
log.info("Planner node output: {}", plannerNodeOutput);
// Parse plan and get current step
Plan plan = converter.convert(plannerNodeOutput);
ExecutionStep executionStep = getCurrentExecutionStep(plan, currentStep);
String summaryAndRecommendations = executionStep.getToolParameters().getSummaryAndRecommendations();
// Generate report streaming flux
Flux<ChatResponse> reportGenerationFlux = generateReport(userInput, plan, executionResults,
summaryAndRecommendations);
// Use utility class to create streaming generator with content collection
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGeneratorWithMessages(this.getClass(),
state, "开始生成报告...", "报告生成完成!", reportContent -> {
log.info("Generated report content: {}", reportContent);
Map<String, Object> result = new HashMap<>();
result.put(RESULT, reportContent);
result.put(SQL_EXECUTE_NODE_OUTPUT, null);
result.put(PLAN_CURRENT_STEP, null);
result.put(PLANNER_NODE_OUTPUT, null);
return result;
},
Flux.concat(Flux.just(ChatResponseUtil.createPureResponse(TextType.HTML.getStartSign())),
reportGenerationFlux,
Flux.just(ChatResponseUtil.createPureResponse(TextType.HTML.getEndSign()))));
return Map.of(RESULT, generator);
}生成HTML格式的分析报告,包含数据摘要、趋势分析、建议措施等。
8.2 错误处理与重试机制
系统实现了完善的错误处理和重试机制:
SQL执行异常:SQL执行失败时,触发SQL重新生成流程
语义一致性校验:SQL执行成功但结果不符合预期时,触发SQL重新生成
计划验证失败:计划验证失败时,触发计划修复流程
多轮优化:SQL生成支持最多3轮优化,每次优化都会进行质量评分
9. 具体实现示例和最佳实践
9.1 自定义节点开发
开发自定义节点需要实现
NodeAction
@Component
public class CustomNode implements NodeAction {
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 1. 从state读取输入
String input = StateUtil.getStringValue(state, INPUT_KEY);
// 2. 执行业务逻辑
String output = processInput(input);
// 3. 返回结果(支持流式输出)
return Map.of("CUSTOM_NODE_OUTPUT", output);
}
}9.2 流式输出最佳实践
使用
FluxUtil.createStreamingGenerator
Flux<GraphResponse<StreamingOutput>> generator = FluxUtil.createStreamingGenerator(
this.getClass(),
state,
responseFlux,
Flux.just(ChatResponseUtil.createResponse("开始处理...")), // 前置消息
Flux.just(ChatResponseUtil.createResponse("处理完成!")), // 后置消息
result -> Map.of("OUTPUT_KEY", result) // 结果转换
);9.3 向量检索优化
批处理策略:配置
embedding-batch
混合搜索:启用混合搜索提升召回准确率
相似度阈值:调整
similarity-threshold
9.4 提示词优化
提示词模板存储在
src/main/resources/prompts/
变量替换:使用
{{variable}}
多模板支持:根据场景选择不同模板
用户自定义:通过
UserPromptConfig
10. 部署方式
10.1 本地开发部署
参考项目根目录下的
README.md
数据库初始化步骤
配置文件说明
启动方式
10.2 Docker部署
项目提供了Docker Compose配置,位于
docker-file/
docker-compose.yml
docker-compose-datasource.yml
Dockerfile-backend
Dockerfile-frontend
详细部署说明请参考
docker-file/
10.3 生产环境部署建议
数据库配置:使用连接池,配置合理的超时时间
向量库选择:生产环境建议使用Milvus或Elasticsearch替代内存向量
API Key管理:使用环境变量或密钥管理服务
监控告警:集成监控系统,监控LLM调用、SQL执行等关键指标
11. 社区与文档资源
11.1 官方资源
GitHub仓库:https://github.com/spring-ai-alibaba/DataAgent
项目主页:https://github.com/alibaba/spring-ai-alibaba
钉钉群:DataAgent用户1群(群号:154405001431)
11.2 相关文档
Spring AI文档:https://springdoc.cn/spring-ai/
Spring AI Alibaba文档:参考GitHub仓库的README和Wiki
11.3 技术栈文档
Spring Boot 3.4.8:https://spring.io/projects/spring-boot
Reactor:https://projectreactor.io/docs/core/release/reference/
DashScope:https://help.aliyun.com/product/61175.html
12. 学习总结
12.1 核心设计思想
12.1.1 状态图编排模式
系统采用状态图(StateGraph)作为工作流编排引擎,这是一种声明式的流程定义方式:
优势:
可维护性:流程逻辑清晰,节点职责单一
可扩展性:新增节点只需注册和连接,无需修改现有代码
可测试性:每个节点可独立测试
设计要点:
使用
KeyStrategy
通过
Dispatcher
支持节点重试和错误恢复
12.1.2 流式处理架构
系统全面采用Reactor响应式编程模型,实现流式数据处理:
优势:
用户体验:实时推送处理进度,提升交互体验
资源效率:非阻塞IO,提高系统吞吐量
错误处理:流式错误处理,不影响整体流程
设计要点:
使用
Flux
通过
Sinks.Many
使用
TextType
12.1.3 多轮优化机制
SQL生成节点实现了多轮优化机制,体现了”快速失败、持续改进”的设计思想:
设计要点:
质量评估:从语法、安全性、性能三个维度评估SQL质量
提前终止:质量分数达到阈值时提前结束优化
异常反馈:将执行异常作为优化输入,实现闭环优化
12.2 技术亮点
12.2.1 向量检索与知识库
系统将业务知识、Schema信息向量化存储,通过语义检索实现智能召回:
技术要点:
使用Spring AI的VectorStore抽象,支持多种向量库实现
实现混合检索,结合向量检索和关键词检索
支持批处理优化,提升向量化效率
12.2.2 多数据库支持
通过抽象层实现多数据库支持,体现了良好的架构设计:
设计要点:
Accessor
Ddl
各数据库实现类封装方言差异
12.2.3 计划生成与执行分离
将计划生成和执行分离,支持复杂的多步骤分析:
设计要点:
Plan
ExecutionStep
PlanExecutorNode
支持计划验证和修复机制
12.3 可借鉴的设计模式
12.3.1 策略模式
KeyStrategy:状态更新策略
BatchingStrategy:批处理策略
FusionStrategy:检索结果融合策略
12.3.2 工厂模式
AccessorFactory:数据访问器工厂
DBConnectionPoolFactory:连接池工厂
LlmServiceFactory:LLM服务工厂
12.3.3 模板方法模式
AbstractAccessor:定义数据访问的模板方法
AbstractDBConnectionPool:定义连接池的模板方法
12.4 改进思考
性能优化:
考虑缓存常用的Schema信息和业务知识
优化向量检索的批处理策略
使用连接池复用数据库连接
可观测性:
增加详细的日志和指标收集
集成分布式追踪系统
监控LLM调用成本和延迟
安全性:
加强SQL注入防护
实现细粒度的权限控制
审计敏感操作
扩展性:
支持更多数据库类型
支持更多LLM提供商
支持自定义分析工具(除SQL和Python外)
12.5 总结
Spring AI Alibaba DataAgent是一个设计精良的智能数据查询系统,展现了以下核心价值:
架构设计:采用状态图编排、流式处理、多轮优化等先进设计模式
技术选型:基于Spring AI框架,充分利用响应式编程和AI能力
工程实践:模块化设计、多数据库支持、完善的错误处理机制
该系统为构建智能数据分析平台提供了优秀的参考实现,值得深入学习和借鉴。



















暂无评论内容