
在计算机系统中,I/O 操作的性能一直是影响系统整体性能的关键因素。无论是文件读写、网络通信还是数据库访问,高效的 I/O 处理都至关重大。对于 Linux 系统而言,I/O 模型的发展经历了多个阶段,从早期的阻塞式 I/O 到如今强劲的 io_uring,每一次变革都为开发者带来了更高效、更灵活的 I/O 处理方式。
它作为 Linux 内核异步 I/O 领域的革新者,旨在打破传统异步 I/O 模型的性能束缚,为开发者提供更高效、更强劲的 I/O 处理能力。那么,io_uring 究竟有何独特之处?它是如何实现高性能异步 I/O 的?接下来,让我们一起深入探究 io_uring 的奥秘。
一、传统 I/O 模型的痛点
在深入了解 io_uring 之前,让我们先回顾一下传统 I/O 模型,剖析它们在应对高并发、高性能需求时所面临的挑战。
1.1阻塞式 I/O
阻塞式 I/O 是最基础、最直观的 I/O 模型。在这种模型下,当应用程序执行 I/O 操作(如 read 或 write)时,进程会被阻塞,直到 I/O 操作完成。例如,当从文件中读取数据时,如果数据尚未准备好,进程就会一直等待,期间无法执行其他任务。就好比你去餐厅点餐,然后一直在餐桌旁等待食物上桌,在等待的过程中什么也做不了。
以一个简单的文件读取操作为例,假设我们有如下代码:
#include
#include
#include
#define BUFFER_SIZE 1024
int main {
int fd = open("example.txt", O_RDONLY);
if (fd == -1) {
perror("open");
return 1;
}
char buffer[BUFFER_SIZE];
ssize_t bytes_read = read(fd, buffer, BUFFER_SIZE);
if (bytes_read == -1) {
perror("read");
close(fd);
return 1;
}
printf("Read %zd bytes: %.*s
", bytes_read, (int)bytes_read, buffer);
close(fd);
return 0;
}在这段代码中,read函数会阻塞进程,直到数据从文件中读取到缓冲区。如果文件很大或者读取过程中出现延迟,进程将长时间处于阻塞状态,无法处理其他任务。
在高并发的 Web 服务器场景中,如果使用阻塞式 I/O,每一个客户端连接都需要一个独立的线程来处理。当并发连接数增多时,线程资源将被大量消耗,系统性能会急剧下降。由于每个线程在等待 I/O 操作完成时,都会占用必定的系统资源(如栈空间、寄存器等),而线程的创建和销毁也会带来额外的开销。
1.2非阻塞式 I/O
为了解决阻塞式 I/O 的问题,非阻塞式 I/O 应运而生。在非阻塞式 I/O 模型中,当应用程序执行 I/O 操作时,如果数据尚未准备好,系统不会阻塞进程,而是立即返回一个错误(如 EWOULDBLOCK 或 EAGAIN)。应用程序可以继续执行其他任务,然后通过轮询的方式再次尝试 I/O 操作,直到数据准备好。这就像你在餐厅点餐时,服务员告知你需要等待一段时间,你可以先去做其他事情,然后时不时回来询问食物是否准备好了。
在 Linux 中,可以通过fcntl函数将文件描述符设置为非阻塞模式,示例代码如下:
#include
#include
#include
#include
#define BUFFER_SIZE 1024
int main {
int fd = open("example.txt", O_RDONLY | O_NONBLOCK);
if (fd == -1) {
perror("open");
return 1;
}
char buffer[BUFFER_SIZE];
while (1) {
ssize_t bytes_read = read(fd, buffer, BUFFER_SIZE);
if (bytes_read == -1) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// 数据未准备好,继续执行其他任务或再次轮询
usleep(1000); // 稍微等待一下再轮询
continue;
} else {
perror("read");
close(fd);
return 1;
}
}
break;
}
printf("Read %zd bytes: %.*s
", bytes_read, (int)bytes_read, buffer);
close(fd);
return 0;
}非阻塞式I/O提高了系统的并发处理能力,进程在等待 I/O操作的过程中可以执行其他任务。但是,频繁的轮询会消耗大量的 CPU 资源,增加了系统的开销。而且非阻塞式 I/O 的编程复杂度较高,需要处理更多的错误和状态判断。例如,在上述代码中,需要不断地检查read函数的返回值和errno来判断 I/O操作的状态 。
1.3I/O 多路复用
I/O 多路复用是在非阻塞式 I/O 的基础上进一步发展而来的,它允许一个进程同时监视多个 I/O 描述符(如文件描述符、套接字等),当其中任何一个描述符就绪(即有数据可读或可写)时,进程就可以对其进行处理。常见的 I/O 多路复用技术有 select、poll 和 epoll。
以 select 为例,应用程序通过调用 select 函数,将需要监视的 I/O 描述符集合传递给内核,内核会监视这些描述符的状态,当有描述符就绪时,select 函数返回,应用程序再对就绪的描述符进行 I/O 操作。这就好比你在餐厅同时点了多道菜,你只需要等待服务员一次性通知你哪些菜已经准备好了,然后去取相应的菜,而不需要每道菜都单独询问。
#include
#include
#include
#include
#include
#include
#define BUFFER_SIZE 1024
#define FD_SETSIZE 1024
int main {
int fd1 = open("file1.txt", O_RDONLY | O_NONBLOCK);
int fd2 = open("file2.txt", O_RDONLY | O_NONBLOCK);
if (fd1 == -1 || fd2 == -1) {
perror("open");
return 1;
}
fd_set read_fds;
FD_ZERO(&read_fds);
FD_SET(fd1, &read_fds);
FD_SET(fd2, &read_fds);
int max_fd = (fd1 > fd2)? fd1 : fd2;
int ret = select(max_fd + 1, &read_fds, , , );
if (ret == -1) {
perror("select");
close(fd1);
close(fd2);
return 1;
} else if (ret > 0) {
char buffer[BUFFER_SIZE];
if (FD_ISSET(fd1, &read_fds)) {
ssize_t bytes_read = read(fd1, buffer, BUFFER_SIZE);
if (bytes_read == -1) {
perror("read fd1");
} else {
printf("Read from fd1: %.*s
", (int)bytes_read, buffer);
}
}
if (FD_ISSET(fd2, &read_fds)) {
ssize_t bytes_read = read(fd2, buffer, BUFFER_SIZE);
if (bytes_read == -1) {
perror("read fd2");
} else {
printf("Read from fd2: %.*s
", (int)bytes_read, buffer);
}
}
}
close(fd1);
close(fd2);
return 0;
}在上述代码中,通过select函数同时监视fd1和fd2两个文件描述符,当其中任何一个有数据可读时,select函数返回,然后分别检查FD_ISSET来判断是哪个描述符就绪并进行读取操作。
而 epoll 是 Linux 2.6 内核引入的高性能 I/O 多路复用机制,它通过三个系统调用来实现:epoll_create创建一个 epoll 实例,epoll_ctl添加 / 删除文件描述符到 epoll 实例中,epoll_wait等待 I/O 事件。epoll 使用事件驱动机制,仅返回已就绪的文件描述符,避免了 select 和 poll 的线性遍历开销。例如在 Nginx 中,就大量使用了 epoll 来处理高并发的网络连接,使得 Nginx 能够高效地应对成千上万的并发请求 。
尽管如此,在高并发场景下,大量的事件处理也可能成为 epoll 的性能瓶颈。当需要处理的事件数量超级大时,epoll_wait的返回和事件处理过程可能会产生必定的延迟,影响系统的整体性能 。
二、io_uring 闪亮登场
2.1 io_uring 是什么?
io_uring 是 Linux 内核提供的高性能异步 I/O 框架,于 2019 年在 Linux 5.1 版本中首次引入,由 Jens Axboe 开发。它旨在解决传统异步 I/O 模型(如 epoll 或 POSIX AIO)在大规模 I/O 操作中的效率问题,是 Linux 异步 I/O 领域的一次重大革新。
在 io_uring 出现之前,传统 I/O 模型在高并发场景下存在诸多性能瓶颈,如系统调用开销大、数据拷贝次数多、异步处理能力有限等。而 io_uring 通过创新的设计,实现了低时延、低开销、异步、高吞吐的 I/O 操作,为开发者提供了更强劲的 I/O 处理能力。
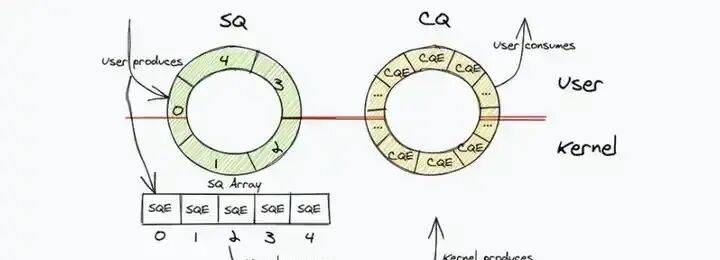
io_uring 的核心概念主要包括提交队列(SQ)、完成队列(CQ)、提交队列项(SQE)和完成队列项(CQE):
-
提交队列(SQ,Submission Queue):用于存放用户空间提交的 I/O 请求。用户将 I/O 请求填充到 SQ 中,并通知内核有新的请求需要处理。它是一个环形队列,用户通过操作队列的 tail 指针来写入新的请求 。
-
完成队列(CQ,Completion Queue):用于存放已经完成的 I/O 请求结果。内核在处理完 I/O 请求后,会将结果填充到 CQ 中,并通知用户空间有请求已完成。同样是环形队列,用户通过操作队列的 head 指针来读取完成的结果 。
-
提交队列项(SQE,Submission Queue Entry):表明一个具体的 I/O 请求,包含了操作类型(如 READ、WRITE、ACCEPT 等)、文件描述符、缓冲区地址、偏移量、数据长度等信息。用户通过填充 SQE 来描述 I/O 请求,并将其放入 SQ 队列 。例如:
struct io_uring_sqe {
__u8 opcode; // 操作类型,如 READ, WRITE, ACCEPT…
__u8 flags;
__u16 ioprio;
__s32 fd;
__u64 offset;
__u64 addr; // 用户缓冲区地址
__u32 len;
__u64 user_data; // 用户自定义数据(回调、标识等)
};完成队列项(CQE,Completion Queue Entry) :表明一个 I/O 请求的完成结果,包含返回值(成功时为字节数,失败时为 -errno)、用户自定义数据等信息。用户从 CQ 队列中读取 CQE 来获取 I/O 请求的执行结果 。其数据结构如下:
struct io_uring_cqe {
__u64 user_data; // 与 SQE 中设置的一致
__s32 res; // 返回值:成功时为字节数,失败时为 -errno
__u32 flags;
};SQ 和 CQ 通过内存映射(mmap)的方式映射到用户空间,使得用户态和内核态可以直接访问,避免了频繁的系统调用和数据拷贝。用户是 SQ 的生产者,内核是消费者;内核是 CQ 的生产者,用户是消费者 。
2.2设计目标与特点
统一网络和磁盘异步 I/O:在 io_uring 之前,Linux 的网络 I/O 和磁盘 I/O 使用不同的机制,这给开发者带来了很大的不便。io_uring 的设计目标之一就是统一网络和磁盘异步 I/O,使得开发者可以使用统一的接口来处理不同类型的 I/O 操作。这就像一个万能的工具,无论你是处理网络数据的传输,还是磁盘文件的读写,都可以使用 io_uring 这个工具,而不需要在不同的工具之间切换。
提供统一完善的异步 API:它提供了一套统一且完善的异步 API,简化了异步 I/O 编程。在传统的 I/O 模型中,开发者可能需要使用多个不同的函数和系统调用来实现异步 I/O,而且这些接口可能并不统一,容易出错。io_uring 将这些复杂的操作封装成了简单易用的 API,开发者只需要调用这些 API,就可以轻松地实现异步 I/O 操作,降低了编程的难度和出错的概率。
支持异步、轮询、无锁、零拷贝:io_uring 支持异步操作,应用程序在发起 I/O 请求后不必等待操作完成,可以继续执行其他任务,提高了系统的并发处理能力;它还支持轮询模式,不依赖硬件的中断,通过调用 IORING_ENTER_GETEVENTS 不断轮询收割完成事件,减少了中断开销;同时,io_uring 采用了无锁设计,避免了锁竞争带来的性能损耗;在数据传输过程中,io_uring 支持零拷贝技术,减少了数据在用户空间和内核空间之间的拷贝次数,提高了数据传输的效率。例如,在一个文件传输的场景中,使用 io_uring 可以大大减少数据拷贝的时间,提高文件传输的速度。
2.3io_uring设计思路
(1)解决“系统调用开销大”的问题?
针对这个问题,思考是否每次都需要系统调用。如果能将多次系统调用中的逻辑放到有限次数中来,就能将消耗降为常数时间复杂度。
(2)解决“拷贝开销大”的问题?
之所以在提交和完成事件中存在大量的内存拷贝,是由于应用程序和内核之间的通信需要拷贝数据,所以为了避免这个问题,需要重新考量应用与内核间的通信方式。我们发现,两者通信,不是必须要拷贝,通过现有技术,可以让应用与内核共享内存。
要实现核外与内核的零拷贝,最佳方式就是实现一块内存映射区域,两者共享一段内存,核外往这段内存写数据,然后通知内核使用这段内存数据,或者内核填写这段数据,核外使用这部分数据。因此,需要一对共享的ring buffer用于应用程序和内核之间的通信。
-
一块用于核外传递数据给内核,一块是内核传递数据给核外,一方只读,一方只写。
-
提交队列SQ(submission queue)中,应用是IO提交的生产者,内核是消费者。
-
完成队列CQ(completion queue)中,内核是IO完成的生产者,应用是消费者。
-
内核控制SQ ring的head和CQ ring的tail,应用程序控制SQ ring的tail和CQ ring的head
(3)解决“API不友善”的问题?
问题在于需要多个系统调用才能完成,思考是否可以把多个系统调用合而为一。有时候,将多个类似的函数合并并通过参数区分不同的行为是更好的选择,而有时候可能需要将复杂的函数分解为更简单的部分来进行重构。
如果发现函数中的某一部分代码可以独立出来成为一个单独的函数,可以先进行这样的提炼,然后再思考是否需要进一步使用参数化方法重构。
三、io_uring的实现原理
io_uring实现异步I/O的方式实则是一个生产者-消费者模型:
-
用户进程生产I/O请求,放入提交队列(Submission Queue,简称SQ)。
-
内核消费SQ中的I/O请求,完成后将结果放入完成队列(Completion Queue,简称CQ)。
-
用户进程从CQ中收割I/O结果。
SQ和CQ是内核初始化io_uring实例的时候创建的。为了减少系统调用和减少用户进程与内核之间的数据拷贝,io_uring使用mmap的方式让用户进程和内核共享SQ和CQ的内存空间。
另外,由于先提交的I/O请求不必定先完成,SQ保存的实则是一个数组索引(数据类型 uint32),真正的SQE(Submission Queue Entry)保存在一个独立的数组(SQ Array)。所以要提交一个I/O请求,得先在SQ Array中找到一个空闲的SQE,设置好之后,将其数组索引放到SQ中。
用户进程、内核、SQ、CQ和SQ Array之间的基本关系如下:
3.1核心组件解析
提交队列(SQ)与提交队列项(SQE):提交队列(Submission Queue,简称 SQ)是 io_uring 中用于存储 I/O 请求的队列,它是一个环形缓冲区,位于用户态和内核态共享的内存区域。每个 I/O 请求在提交队列中都以提交队列项(Submission Queue Entry,简称 SQE)的形式存在。SQE 是一个结构体,它存储了 I/O 请求的详细信息,包括操作类型(如读、写、异步连接等)、目标文件描述符、缓冲区地址、操作长度、偏移量等关键信息。
例如,在进行文件读取操作时,SQE 会记录要读取的文件描述符、读取数据的缓冲区地址、读取的字节数以及文件中的偏移量等信息。应用程序通过填充 SQE 结构体,并将其添加到 SQ 中,来向内核提交 I/O 请求。由于 SQ 是环形缓冲区,当队列满时,新的请求会覆盖旧的请求,从而保证 I/O 请求的持续提交。
完成队列(CQ)与完成队列项(CQE):完成队列(Completion Queue,简称 CQ)同样是一个环形缓冲区,用于存储 I/O 请求的完成结果。当内核完成一个 I/O 操作后,会将操作的结果封装成一个完成队列项(Completion Queue Entry,简称 CQE),并将其放入 CQ 中。CQE 结构体包含了 I/O 操作的返回值、状态码、用户自定义数据等信息。
通过这些信息,应用程序可以判断 I/O 操作是否成功,并获取操作的相关结果。列如,在文件读取操作完成后,CQE 中的返回值会表明实际读取的字节数,状态码则用于指示操作是否成功,若操作失败,状态码会包含具体的错误信息。应用程序可以通过轮询 CQ 或者等待特定的事件通知,来获取完成的 I/O 请求结果,从而进行后续的处理。
SQ Ring 与 CQ Ring:SQ Ring 和 CQ Ring 分别是提交队列和完成队列的环形缓冲区结构。它们包含了队列本身(即 SQ 和 CQ)、头部索引(head)、尾部索引(tail)以及队列大小等关键信息。头部索引(head)指向队列中第一个待处理的元素,而尾部索引(tail)则指向队列中下一个空闲的位置。当应用程序向 SQ 提交 I/O 请求时,它会将请求信息填充到 tail 指向的 SQE 中,然后将 tail 指针递增,指向下一个空闲位置。
内核在处理 I/O 请求时,会从 head 指向的 SQE 中获取请求信息,处理完成后,将结果放入 CQ 中。同样,CQ Ring 通过 head 和 tail 指针来管理完成队列,内核将完成的 I/O 结果放入 tail 指向的 CQE 中,并递增 tail 指针,应用程序则从 head 指向的 CQE 中获取结果。这种环形缓冲区结构以及基于 head 和 tail 指针的操作方式,实现了用户态和内核态之间高效的数据交换,减少了锁的使用和上下文切换的开销,从而大大提高了 I/O 操作的效率。
3.2系统调用详解
io_uring的实现仅仅使用了三个syscall:io_uring_setup, io_uring_enter和io_uring_register。这几个系统调用接口都在io_uring.c文件中:
⑴io_uring_setup 是用于初始化 io_uring 环境的系统调用。在使用 io_uring 进行异步 I/O 操作之前,第一需要调用 io_uring_setup 来创建一个 io_uring 实例。它接受两个参数,第一个参数是期望的提交队列(SQ)的大小,即队列中可以容纳的 I/O 请求数量;第二个参数是一个指向 io_uring_params 结构体的指针,该结构体用于返回 io_uring 实例的相关参数,如实际分配的 SQ 和完成队列(CQ)的大小、队列的偏移量等信息。
在调用 io_uring_setup 时,内核会为 io_uring 实例分配所需的内存空间,包括 SQ、CQ 以及相关的控制结构。同时,内核还会创建一些内部数据结构,用于管理和调度 I/O 请求。如果初始化成功,io_uring_setup 会返回一个文件描述符,这个文件描述符用于标识创建的 io_uring 实例,后续的 io_uring 系统调用(如 io_uring_enter、io_uring_register)将通过这个文件描述符来操作该 io_uring 实例。若初始化失败,函数将返回一个负数,表明相应的错误代码。
io_uring_setup:
SYSCALL_DEFINE2(io_uring_setup, u32, entries,
struct io_uring_params __user *, params)
{
return io_uring_setup(entries, params);
}-
功能:用于初始化和配置 io_uring 。
-
应用用途:在使用 io_uring 之前,第一需要调用此接口初始化一个 io_uring 环,并设置其参数。
⑵io_uring_enter 是用于提交和等待 I/O 操作的系统调用。它的主要作用是将应用程序准备好的 I/O 请求提交给内核,并可以选择等待这些操作完成。io_uring_enter 接受多个参数,其中包括 io_uring_setup 返回的文件描述符,用于指定要操作的 io_uring 实例;to_submit 参数表明要提交的 I/O 请求的数量,即从提交队列(SQ)中取出并提交给内核的 SQE 的数量;min_complete 参数指定了内核在返回之前必须等待完成的 I/O 操作的最小数量;flags 参数则用于控制 io_uring_enter 的行为,例如可以设置是否等待 I/O 操作完成、是否获取完成的 I/O 事件等。当调用 io_uring_enter 时,如果 to_submit 参数大于 0,内核会从 SQ 中取出相应数量的 SQE,并将这些 I/O 请求提交到内核中进行处理。
同时,如果设置了等待 I/O 操作完成的标志,内核会阻塞等待,直到至少有 min_complete 个 I/O 操作完成,然后将这些完成的操作结果放入完成队列(CQ)中。应用程序可以通过检查 CQ 来获取这些完成的 I/O 请求的结果。通过 io_uring_enter,应用程序可以灵活地控制 I/O 请求的提交和等待策略,提高 I/O 操作的效率和灵活性。
io_uring_enter:
SYSCALL_DEFINE6(io_uring_enter, unsigned int, fd, u32, to_submit,
u32, min_complete, u32, flags, const void __user *, argp,
size_t, argsz)-
功能:用于提交和处理异步 I/O 操作。
-
应用用途:在向 io_uring 环中提交 I/O 操作后,通过调用此接口触发内核处理这些操作,并获取完成的操作结果。
⑶io_uring_register 用于注册文件描述符或事件文件描述符到 io_uring 实例中,以便在后续的 I/O 操作中使用。它接受四个参数,第一个参数是 io_uring_setup 返回的文件描述符,用于指定要注册到的 io_uring 实例;第二个参数 opcode 表明注册的类型,例如可以是 IORING_REGISTER_FILES(注册文件描述符集合)、IORING_REGISTER_BUFFERS(注册内存缓冲区)、IORING_REGISTER_EVENTFD(注册 eventfd 用于通知完成事件)等;
第三个参数 arg 是一个指针,根据 opcode 的类型不同,它指向不同的内容,如注册文件描述符时,arg 指向一个包含文件描述符的数组;注册缓冲区时,arg 指向一个描述缓冲区的结构体数组;第四个参数 nr_args 表明 arg 所指向的数组的长度。通过 io_uring_register 注册文件描述符或缓冲区等资源后,内核在处理 I/O 请求时,可以直接访问这些预先注册的资源,而无需每次都重新设置相关信息,从而提高了 I/O 操作的效率。例如,在进行大量文件读写操作时,预先注册文件描述符可以避免每次提交 I/O 请求时都进行文件描述符的查找和验证,减少了系统开销,提升了 I/O 性能。
io_uring_register:
SYSCALL_DEFINE4(io_uring_register, unsigned int, fd, unsigned int, opcode,
void __user *, arg, unsigned int, nr_args)-
功能:用于注册文件描述符、缓冲区、事件文件描述符等资源到 io_uring 环中。
-
应用用途:在进行 I/O 操作之前,需要将相关的资源注册到 io_uring 环中,以便进行后续的异步 I/O 操作。
3.3io_uring 的工作流程
io_uring 的工作流程涉及用户态和内核态的交互,具体如下:
(1)初始化 :用户空间程序通过io_uring_setup系统调用创建 io_uring 实例,并设置相关参数,如队列的大小等。这个过程会在内核中创建 io_uring 相关的数据结构,包括 SQ 和 CQ,并通过 mmap 将 SQ 和 CQ 映射到用户空间,使得用户态和内核态可以共享这两个队列 。例如:
#include
struct io_uring ring;
struct io_uring_params params;
int ret = io_uring_queue_init_params(ENTRIES, ˚, ¶ms);
if (ret
// 初始化失败处理
}(2)准备 I/O 请求 :用户空间程序准备 I/O 请求,通过io_uring_get_sqe获取一个 SQE,然后使用io_uring_prep_XXX系列函数(如io_uring_prep_read、io_uring_prep_write等)填充 SQE,指定操作类型、文件描述符、缓冲区、偏移地址等信息 。例如:
struct io_uring_sqe *sqe = io_uring_get_sqe(˚);
if (!sqe) {
// 获取SQE失败处理
}
io_uring_prep_read(sqe, fd, buffer, size, offset);(3)提交 I/O 请求 :将填充好的 SQE 写入 SQ 队列,并更新 SQ 队列的 tail 指针。用户可以通过io_uring_submit函数提交请求,该函数会触发io_uring_enter系统调用(若未启用 SQ 轮询),通知内核有新的 I/O 请求需要处理 。代码示例:
int ret = io_uring_submit(˚);
if (ret
// 提交请求失败处理
}(4)内核处理 :内核通过检查 SQ 队列,发现有新的请求后,从 SQ 队列中取出 SQE 并进行处理。处理过程中可能涉及磁盘操作、网络通信等实际的 I/O 操作 。
(5)完成通知 :当 I/O 请求完成后,内核将结果填充到 CQ 队列中,并更新 CQ 队列的 tail 指针,通知用户空间有请求已完成 。
(6)用户空间处理完成请求 :用户空间程序通过io_uring_wait_cqe或io_uring_peek_cqe等函数检查 CQ 队列,发现有请求完成后,从 CQ 队列中取出 CQE 并进行后续处理,获取返回值和用户自定义数据等。处理完成后,通过io_uring_cqe_seen函数标记 CQE 已处理,以便内核可以重用该位置 。例如:
struct io_uring_cqe *cqe;
ret = io_uring_wait_cqe(˚, &cqe);
if (ret
// 等待CQE失败处理
}
if (cqe->res >= 0) {
// 处理成功的结果
} else {
// 处理失败的结果
}
io_uring_cqe_seen(˚, cqe);(7)重复操作 :用户空间程序可以重复上述步骤,继续提交和处理更多的 I/O 请求 。
通过这样的工作流程,io_uring 实现了高效的异步 I/O 操作,减少了系统调用开销和上下文切换,提高了 I/O 性能 。
四、io_uring 与其他 I/O 模型的对比
4.1 io_uring与阻塞 I/O 对比
阻塞 I/O 在进行 I/O 操作时,线程会被阻塞,直到操作完成。例如在读取文件时,若数据未准备好,线程就会一直等待,期间无法执行其他任务,这就像你排队买奶茶,必须等买到奶茶才能去做别的事。而 io_uring 是异步 I/O 模型,提交 I/O 请求后,线程不会阻塞,可以立即返回去执行其他任务,内核会在 I/O 操作完成后通过完成队列通知应用程序,就好比你点了奶茶后可以先去附近逛逛,等奶茶做好了店员会通知你。
在系统资源利用率方面,阻塞 I/O 在高并发场景下,由于每个 I/O 操作都会阻塞线程,大量线程被阻塞,导致线程上下文切换频繁,系统资源被大量消耗。而 io_uring 采用异步方式,一个线程可以同时处理多个 I/O 请求,大大提高了系统资源的利用率,减少了线程上下文切换的开销。列如在一个高并发的文件服务器中,使用阻塞 I/O 时,每个文件读取请求都可能阻塞一个线程,当并发请求数增多时,线程资源会被迅速耗尽,而使用 io_uring,一个线程可以同时处理多个文件读取请求,系统可以轻松应对大量并发请求 。
4.2 io_uring与非阻塞 I/O 对比
非阻塞 I/O 在数据未准备好时,会立即返回一个错误(如 EWOULDBLOCK 或 EAGAIN),应用程序需要通过轮询的方式不断检查 I/O 操作是否完成。这就像你在等快递,每隔一段时间就去快递站看看快递到了没有。而 io_uring 通过提交队列和完成队列实现异步 I/O,应用程序提交 I/O 请求后,无需轮询,内核会自动处理并在完成后通知应用程序,就像快递到了会直接给你打电话通知。
从 CPU 资源利用角度来看,非阻塞 I/O 的频繁轮询会消耗大量的 CPU 资源,由于每次轮询都需要 CPU 进行计算和判断。而 io_uring 避免了这种无效的 CPU 消耗,内核在后台处理 I/O 操作,只有在 I/O 完成时才会通知应用程序,使得 CPU 可以更高效地处理其他任务。在编程复杂度上,非阻塞 I/O 需要处理复杂的轮询逻辑和错误处理,而 io_uring 提供了更简洁的 API,开发者只需要关注 I/O 请求的提交和结果的获取,降低了编程难度。例如在编写一个网络爬虫程序时,使用非阻塞 I/O 需要不断地检查网络连接是否可读可写,处理各种错误情况,而使用 io_uring 可以更简单地提交网络请求,等待结果返回 。
4.3 io_uring与 epoll 对比
从系统调用次数来看,epoll 虽然是一种高效的 I/O 多路复用机制,但每次 I/O 操作仍需要多次系统调用,如epoll_wait获取就绪事件后,还需要调用read/write等函数进行数据传输,这会带来必定的系统调用开销。而 io_uring 通过提交队列和完成队列,用户可以一次性提交多个 I/O 请求,内核处理完成后将结果放入完成队列,大大减少了系统调用次数。例如在处理大量网络连接时,epoll 需要频繁调用epoll_wait和read/write,而 io_uring 可以一次性提交多个网络请求,等待结果统一处理 。
在异步处理能力方面,epoll 本质上还是同步非阻塞的,当epoll_wait返回后,应用程序依旧需要主动调用read/write等函数来进行数据拷贝操作,这在高并发场景下会限制系统的性能提升。而 io_uring 实现了真正的异步 I/O,I/O 操作由内核异步处理,数据拷贝也由内核完成,应用程序只需在 I/O 完成后处理结果,提高了系统的异步处理能力和响应速度。
在功能支持上,io_uring 支持更多的异步系统调用,如accept、connect、fsync、open、sendmsg、recvmsg等,不仅适用于文件 I/O,还广泛应用于网络 I/O 等多种场景,相比之下,epoll 的功能相对单一,主要用于 I/O 多路复用 。
综上所述,io_uring 在高并发场景下,无论是与阻塞 I/O、非阻塞 I/O 还是 epoll 相比,都具有显著的性能优势和功能优势,为开发者提供了更高效、更强劲的 I/O 处理方式 。
五、io_uring 的应用场景
5.1高性能网络服务
在高性能网络服务领域,io_uring 展现出了强劲的性能优势,为应对海量并发请求提供了高效的解决方案。以 Nginx 的 io_uring 模块为例,在传统的 Nginx 架构中,使用 epoll 进行 I/O 多路复用处理网络请求。当面临大量并发网络请求时,epoll 虽然能够高效地处理事件通知,但在频繁的系统调用和数据拷贝过程中,依旧会产生必定的性能开销。
而引入 io_uring 模块后,Nginx 的性能得到了显著提升。io_uring 通过提交队列和完成队列,实现了用户态与内核态之间的高效通信,减少了系统调用次数。在处理大量并发连接时,用户可以一次性将多个网络请求提交到提交队列中,内核在后台异步处理这些请求,并将结果放入完成队列。Nginx 只需从完成队列中获取已完成的请求结果,无需像传统方式那样频繁地进行系统调用和轮询,大大提高了处理效率。
以一个实际的 Web 服务器场景来说,假设一个热门的电商网站在促销活动期间,瞬间涌入了数十万的并发访问请求。在使用 io_uring 之前,Nginx 服务器可能会由于频繁的系统调用和上下文切换,导致响应延迟增加,部分用户甚至会遇到页面加载缓慢或超时的问题。而启用 io_uring 模块后,Nginx 能够更快速地处理这些并发请求,大大降低了响应延迟,用户能够更流畅地浏览商品、下单支付,有效提升了用户体验和业务转化率 。
io_uring 处理网络请求的简化代码示例:
#include
#include
#include
#include
#include
#include
#include
#define PORT 8080
#define BUFFER_SIZE 1024
#define QUEUE_DEPTH 1024
// 存储请求上下文
struct request {
int fd;
struct sockaddr_in client_addr;
socklen_t client_len;
char buffer[BUFFER_SIZE];
};
int main {
int server_fd;
struct sockaddr_in address;
int opt = 1;
int addrlen = sizeof(address);
// 创建服务器套接字
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == 0) {
perror("socket failed");
exit(EXIT_FAILURE);
}
// 设置套接字选项
if (setsockopt(server_fd, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt))) {
perror("setsockopt");
exit(EXIT_FAILURE);
}
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
// 绑定套接字到端口
if (bind(server_fd, (struct sockaddr *)&address, sizeof(address))
perror("bind failed");
exit(EXIT_FAILURE);
}
// 开始监听
if (listen(server_fd, 3)
perror("listen");
exit(EXIT_FAILURE);
}
// 初始化io_uring
struct io_uring ring;
if (io_uring_queue_init(QUEUE_DEPTH, ˚, 0)
perror("io_uring_queue_init");
exit(EXIT_FAILURE);
}
// 分配请求上下文
struct request *reqs = malloc(sizeof(struct request) * QUEUE_DEPTH);
if (!reqs) {
perror("malloc failed");
exit(EXIT_FAILURE);
}
// 准备接受连接的请求
struct request *accept_req = &reqs[0];
accept_req->fd = server_fd;
accept_req->client_len = sizeof(accept_req->client_addr);
struct io_uring_sqe *sqe = io_uring_get_sqe(˚);
io_uring_prep_accept(sqe, server_fd,
(struct sockaddr *)&accept_req->client_addr,
&accept_req->client_len, 0);
io_uring_sqe_set_data(sqe, accept_req);
io_uring_submit(˚);
printf("Server listening on port %d...
", PORT);
while (1) {
struct io_uring_cqe *cqe;
// 等待完成事件
int ret = io_uring_wait_cqe(˚, &cqe);
if (ret
perror("io_uring_wait_cqe");
break;
}
struct request *req = io_uring_cqe_get_data(cqe);
int res = cqe->res;
// 处理完成事件
if (req->fd == server_fd) {
// 新连接建立
if (res
fprintf(stderr, "Accept error: %d
", res);
} else {
int client_fd = res;
printf("New connection: %d
", client_fd);
// 准备读取请求
struct request *read_req = &reqs[client_fd % QUEUE_DEPTH];
read_req->fd = client_fd;
struct io_uring_sqe *read_sqe = io_uring_get_sqe(˚);
io_uring_prep_recv(read_sqe, client_fd, read_req->buffer,
BUFFER_SIZE, 0);
io_uring_sqe_set_data(read_sqe, read_req);
// 再次提交接受请求
struct request *new_accept_req = &reqs[(client_fd + 1) % QUEUE_DEPTH];
new_accept_req->fd = server_fd;
new_accept_req->client_len = sizeof(new_accept_req->client_addr);
struct io_uring_sqe *accept_sqe = io_uring_get_sqe(˚);
io_uring_prep_accept(accept_sqe, server_fd,
(struct sockaddr *)&new_accept_req->client_addr,
&new_accept_req->client_len, 0);
io_uring_sqe_set_data(accept_sqe, new_accept_req);
io_uring_submit(˚);
}
} else if (res > 0) {
// 读取到数据,准备响应
printf("Received %d bytes from %d: %s
", res, req->fd, req->buffer);
// 准备响应内容
const char *response = "HTTP/1.1 200 OK
Content-Length: 12
Hello World!";
struct io_uring_sqe *write_sqe = io_uring_get_sqe(˚);
io_uring_prep_send(write_sqe, req->fd, response, strlen(response), 0);
io_uring_sqe_set_data(write_sqe, req);
io_uring_submit(˚);
} else {
// 关闭连接
printf("Closing connection: %d
", req->fd);
close(req->fd);
}
io_uring_cqe_seen(˚, cqe);
}
// 清理资源
free(reqs);
io_uring_queue_exit(˚);
close(server_fd);
return 0;
}
-
第一创建一个服务器套接字并进行初始化配置
-
初始化 io_uring 环境,设置队列深度
-
提交一个接受连接的请求到提交队列 (SQ)
-
进入主循环,等待完成队列 (CQ) 中的事件
-
当有新连接到来时,处理连接并提交读取请求
-
当读取到数据后,准备响应并提交写入请求
-
完成所有操作后关闭连接
这种模式特别适合处理类似电商促销期间的高并发场景,能够更高效地利用系统资源,降低响应延迟;要编译运行此代码,需要系统支持 io_uring 并安装相应的库(一般是 liburing)。
5.2数据库系统
在数据库系统中,I/O 性能是影响数据库整体性能的关键因素。无论是数据的读取、写入还是日志操作,都涉及大量的 I/O 操作。传统的 I/O 模型在处理这些操作时,由于系统调用开销大、数据拷贝次数多等问题,难以满足数据库对高性能 I/O 的需求。
io_uring 的出现为数据库系统带来了新的转机。以 Ceph 分布式存储系统为例,Ceph 在使用 io_uring 进行优化后,性能得到了显著提升。在读写操作中,io_uring 允许 Ceph 一次性提交多个 I/O 请求,内核异步处理这些请求并将结果返回,减少了 I/O 操作的等待时间,提高了系统的吞吐量。在实际测试中,开启 io_uring 优化后,Ceph 的吞吐(iops)提升了 20% – 30%,同时延迟降低了 20 – 30% 。
对于数据库系统中的事务处理,io_uring 也发挥着重大作用。在事务的提交和回滚过程中,需要进行大量的日志写入和数据更新操作。io_uring 的高效异步 I/O 能力,使得这些操作能够快速完成,减少了事务的执行时间,提高了数据库的并发处理能力。列如在一个银行核心交易系统中,每秒可能会处理成千上万的交易事务,使用 io_uring 能够确保这些事务快速、稳定地执行,保障了金融业务的高效运转 。 io_uring 优化数据库 I/O 操作的代码示例:
#include
#include
#include
#include
#include
#include
#include
#define QUEUE_DEPTH 256
#define BLOCK_SIZE 4096
#define LOG_ENTRY_SIZE 512
#define MAX_TRANSACTIONS 100
// 数据库操作类型
typedef enum {
OP_READ,
OP_WRITE,
OP_LOG
} OpType;
// 数据库操作请求
struct db_request {
OpType type; // 操作类型
int fd; // 文件描述符
off_t offset; // 操作偏移量
size_t size; // 数据大小
char *buffer; // 数据缓冲区
char *log_entry; // 日志条目
int transaction_id; // 事务ID
};
// 初始化io_uring
int init_io_uring(struct io_uring *ring) {
int ret = io_uring_queue_init(QUEUE_DEPTH, ring, 0);
if (ret
fprintf(stderr, "io_uring初始化失败: %s
", strerror(-ret));
return -1;
}
return 0;
}
// 提交数据库读请求
void submit_read_request(struct io_uring *ring, struct db_request *req) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
if (!sqe) {
fprintf(stderr, "无法获取SQE
");
return;
}
io_uring_prep_read(sqe, req->fd, req->buffer, req->size, req->offset);
io_uring_sqe_set_data(sqe, req);
}
// 提交数据库写请求
void submit_write_request(struct io_uring *ring, struct db_request *req) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
if (!sqe) {
fprintf(stderr, "无法获取SQE
");
return;
}
io_uring_prep_write(sqe, req->fd, req->buffer, req->size, req->offset);
io_uring_sqe_set_data(sqe, req);
}
// 提交日志写入请求
void submit_log_request(struct io_uring *ring, struct db_request *req) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
if (!sqe) {
fprintf(stderr, "无法获取SQE
");
return;
}
// 日志一般追加到文件末尾
io_uring_prep_write(sqe, req->fd, req->log_entry, LOG_ENTRY_SIZE, -1);
io_uring_sqe_set_data(sqe, req);
}
// 处理完成的I/O请求
void handle_completion(struct io_uring *ring, struct io_uring_cqe *cqe) {
struct db_request *req = io_uring_cqe_get_data(cqe);
int res = cqe->res;
if (res
fprintf(stderr, "操作失败 (类型: %d, 事务: %d): %s
",
req->type, req->transaction_id, strerror(-res));
} else {
switch (req->type) {
case OP_READ:
printf("读取完成 - 事务: %d, 大小: %d bytes
",
req->transaction_id, res);
break;
case OP_WRITE:
printf("写入完成 - 事务: %d, 大小: %d bytes
",
req->transaction_id, res);
break;
case OP_LOG:
printf("日志完成 - 事务: %d, 大小: %d bytes
",
req->transaction_id, res);
break;
}
}
// 释放缓冲区
if (req->buffer) free(req->buffer);
if (req->log_entry) free(req->log_entry);
free(req);
}
// 处理事务 - 包含数据读写和日志记录
void process_transaction(struct io_uring *ring, int db_fd, int log_fd, int tx_id) {
// 分配事务所需的请求结构
struct db_request *read_req = malloc(sizeof(struct db_request));
struct db_request *write_req = malloc(sizeof(struct db_request));
struct db_request *log_req = malloc(sizeof(struct db_request));
// 初始化读请求
read_req->type = OP_READ;
read_req->fd = db_fd;
read_req->offset = (tx_id % 100) * BLOCK_SIZE; // 模拟不同数据块
read_req->size = BLOCK_SIZE;
read_req->buffer = malloc(BLOCK_SIZE);
read_req->log_entry = ;
read_req->transaction_id = tx_id;
// 初始化写请求
write_req->type = OP_WRITE;
write_req->fd = db_fd;
write_req->offset = (tx_id % 100) * BLOCK_SIZE;
write_req->size = BLOCK_SIZE;
write_req->buffer = malloc(BLOCK_SIZE);
snprintf(write_req->buffer, BLOCK_SIZE, "事务 %d 的数据", tx_id);
write_req->log_entry = ;
write_req->transaction_id = tx_id;
// 初始化日志请求
log_req->type = OP_LOG;
log_req->fd = log_fd;
log_req->offset = 0; // 会被忽略,使用追加模式
log_req->size = LOG_ENTRY_SIZE;
log_req->buffer = ;
log_req->log_entry = malloc(LOG_ENTRY_SIZE);
snprintf(log_req->log_entry, LOG_ENTRY_SIZE,
"事务 %d 已提交 - 操作日志", tx_id);
log_req->transaction_id = tx_id;
// 提交请求到io_uring
submit_read_request(ring, read_req);
submit_write_request(ring, write_req);
submit_log_request(ring, log_req);
}
int main {
struct io_uring ring;
int db_fd, log_fd;
int i;
// 初始化io_uring
if (init_io_uring(˚)
return 1;
}
// 打开数据库文件和日志文件
db_fd = open("database.dat", O_RDWR | O_CREAT, 0644);
log_fd = open("transaction.log", O_WRONLY | O_CREAT | O_APPEND, 0644);
if (db_fd
perror("文件打开失败");
return 1;
}
printf("开始处理 %d 个事务...
", MAX_TRANSACTIONS);
// 提交一批事务处理请求
for (i = 0; i
process_transaction(˚, db_fd, log_fd, i);
// 每提交QUEUE_DEPTH个请求就提交一次
if ((i + 1) % QUEUE_DEPTH == 0 || i == MAX_TRANSACTIONS - 1) {
io_uring_submit(˚);
}
}
// 处理所有完成的请求
for (i = 0; i
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(˚, &cqe);
if (ret
fprintf(stderr, "等待完成事件失败: %s
", strerror(-ret));
break;
}
handle_completion(˚, cqe);
io_uring_cqe_seen(˚, cqe);
}
printf("所有事务处理完成
");
// 清理资源
close(db_fd);
close(log_fd);
io_uring_queue_exit(˚);
return 0;
}
编译此程序需要系统支持 io_uring 并安装 liburing 库,编译命令一般为:gcc db_io_uring.c -o db_io_uring -luring。
5.3大规模文件处理
在处理大规模文件读写时,io_uring 相较于传统 I/O 模型具有明显的优势。以文件传输场景为例,假设我们需要将一个大型数据中心的海量数据文件传输到另一个存储节点,传统的 I/O 模型在传输过程中,由于频繁的系统调用和数据拷贝,会导致传输速度缓慢,耗费大量的时间和系统资源。
而 io_uring 通过零拷贝技术和高效的异步 I/O 机制,大大提高了文件传输速度。它允许用户预先将内存缓冲区注册到内核,在文件传输过程中,数据可以直接从用户缓冲区发送到目标存储节点,避免了内核与用户空间之间的数据拷贝,减少了数据传输的时间开销。同时,io_uring 支持批量提交 I/O 请求,能够同时处理多个文件的读写操作,进一步提高了文件处理的效率。
在一个大型媒体公司的文件存储和分发系统中,每天都需要处理大量的视频、音频文件。使用io_uring后,文件的上传、下载和转码等操作速度大幅提升,能够更快地满足用户对媒体内容的访问需求,提升了公司的业务竞争力 。io_uring 实现高效文件传输的代码示例:
#include
#include
#include
#include
#include
#include
#include
#include
#define QUEUE_DEPTH 128
#define BLOCK_SIZE 1024*1024 // 1MB块大小,适合大文件传输
#define MAX_FILES 10 // 同时处理的最大文件数量
// 传输请求结构
struct transfer_request {
int src_fd; // 源文件描述符
int dest_fd; // 目标文件描述符
off_t offset; // 当前传输偏移量
size_t remaining; // 剩余传输大小
char *buffer; // 数据缓冲区
struct iovec iov; // 用于零拷贝的iovec结构
char filename[256]; // 文件名,用于日志
};
// 初始化io_uring
int init_uring(struct io_uring *ring) {
int ret = io_uring_queue_init(QUEUE_DEPTH, ring, IORING_SETUP_IOPOLL);
if (ret
fprintf(stderr, "io_uring初始化失败: %s
", strerror(-ret));
return -1;
}
return 0;
}
// 获取文件大小
off_t get_file_size(int fd) {
struct stat st;
if (fstat(fd, &st)
perror("获取文件大小失败");
return -1;
}
return st.st_size;
}
// 提交读请求
void submit_read_request(struct io_uring *ring, struct transfer_request *req) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
if (!sqe) {
fprintf(stderr, "无法获取SQE
");
return;
}
size_t read_size = req->remaining remaining : BLOCK_SIZE;
// 准备读取请求
io_uring_prep_readv(sqe, req->src_fd, &req->iov, 1, req->offset);
req->iov.iov_len = read_size;
io_uring_sqe_set_data(sqe, req);
}
// 提交写请求
void submit_write_request(struct io_uring *ring, struct transfer_request *req) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
if (!sqe) {
fprintf(stderr, "无法获取SQE
");
return;
}
// 准备写入请求,使用从读取操作得到的数据
io_uring_prep_writev(sqe, req->dest_fd, &req->iov, 1, req->offset);
io_uring_sqe_set_data(sqe, req);
}
// 处理完成的请求
void handle_completion(struct io_uring *ring, struct io_uring_cqe *cqe) {
struct transfer_request *req = io_uring_cqe_get_data(cqe);
int res = cqe->res;
if (res
fprintf(stderr, "文件 %s 操作失败: %s
", req->filename, strerror(-res));
return;
} else if (res == 0) {
// 读取完成(EOF)
printf("文件 %s 传输完成
", req->filename);
close(req->src_fd);
close(req->dest_fd);
free(req->buffer);
free(req);
return;
}
// 根据当前偏移量判断是读完成还是写完成
if (req->offset == 0 || req->remaining + res == req->iov.iov_len) {
// 读操作完成,提交写操作
submit_write_request(ring, req);
} else {
// 写操作完成,更新偏移量并继续读取
req->offset += res;
req->remaining -= res;
if (req->remaining > 0) {
submit_read_request(ring, req);
} else {
printf("文件 %s 传输完成
", req->filename);
close(req->src_fd);
close(req->dest_fd);
free(req->buffer);
free(req);
}
}
}
// 初始化文件传输请求
int init_transfer_request(const char *src_path, const char *dest_path,
struct io_uring *ring) {
// 打开源文件和目标文件
int src_fd = open(src_path, O_RDONLY);
int dest_fd = open(dest_path, O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (src_fd
perror("文件打开失败");
if (src_fd >= 0) close(src_fd);
if (dest_fd >= 0) close(dest_fd);
return -1;
}
// 获取文件大小
off_t file_size = get_file_size(src_fd);
if (file_size
close(src_fd);
close(dest_fd);
return -1;
}
// 分配请求结构和缓冲区
struct transfer_request *req = malloc(sizeof(struct transfer_request));
if (!req) {
perror("内存分配失败");
close(src_fd);
close(dest_fd);
return -1;
}
req->buffer = malloc(BLOCK_SIZE);
if (!req->buffer) {
perror("缓冲区分配失败");
free(req);
close(src_fd);
close(dest_fd);
return -1;
}
// 初始化请求结构
strncpy(req->filename, src_path, sizeof(req->filename)-1);
req->src_fd = src_fd;
req->dest_fd = dest_fd;
req->offset = 0;
req->remaining = file_size;
req->iov.iov_base = req->buffer;
req->iov.iov_len = BLOCK_SIZE;
// 提交初始读请求
submit_read_request(ring, req);
printf("开始传输文件: %s (大小: %ld bytes)
", src_path, file_size);
return 0;
}
int main(int argc, char *argv[]) {
if (argc
fprintf(stderr, "用法: %s [ ...]
", argv[0]);
return 1;
}
int num_files = (argc - 1) / 2;
if (num_files > MAX_FILES) {
fprintf(stderr, "最大支持同时传输 %d 个文件
", MAX_FILES);
return 1;
}
struct io_uring ring;
if (init_uring(˚)
return 1;
}
// 初始化所有文件传输请求
for (int i = 0; i
const char *src = argv[1 + i*2];
const char *dest = argv[2 + i*2];
if (init_transfer_request(src, dest, ˚)
fprintf(stderr, "初始化文件传输失败: %s -> %s
", src, dest);
}
}
// 提交所有请求
io_uring_submit(˚);
// 处理所有完成的I/O操作
int completed = 0;
while (completed
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(˚, &cqe);
if (ret
fprintf(stderr, "等待完成事件失败: %s
", strerror(-ret));
break;
}
handle_completion(˚, cqe);
io_uring_cqe_seen(˚, cqe);
completed++;
}
printf("所有文件传输操作已处理
");
// 清理资源
io_uring_queue_exit(˚);
return 0;
}
与传统文件传输方式相比,这种实现特别适合媒体公司的大文件处理场景,能够显著提升视频、音频等大型文件的传输效率,减少系统资源占用。编译时需要链接 liburing 库:
gcc file_transfer_uring.c -o file_transfer_uring -luring 运行方式:
./file_transfer_uring 源文件1 目标文件1 源文件2 目标文件2 ... 六、io_uring 的代码实践
6.1环境准备
使用 io_uring 需要 Linux 内核版本 5.1 及以上。你可以通过以下命令检查当前系统的内核版本:
uname -r如果内核版本低于 5.1,你需要升级内核。升级内核的方法因 Linux 发行版而异,以 Ubuntu 为例,可以通过官方源进行内核升级:
sudo apt update
sudo apt install linux-image-generic对于 CentOS,可以参考官方文档或相关社区教程进行内核升级 。
安装 liburing 库,它提供了用户空间与 io_uring 交互的接口。可以从官方仓库获取源码进行编译安装,步骤如下:
(1)安装依赖库
在 Debian/Ubuntu 系统中:
sudo apt install build-essential libssl-dev在 RHEL/CentOS 系统中:
sudo yum groupinstall "Development Tools"
sudo yum install openssl-devel(2)下载 liburing 源码
git clone https://git.kernel.dk/liburing
cd liburing(3)配置与编译
./configure --cc=gcc --cxx=g++
make -j$(nproc)(4)安装到系统路径
sudo make install安装完成后,动态库默认位于/usr/local/lib,头文件位于
/usr/local/include/liburing 。
6.2简单示例代码解析
下面是一个使用 io_uring 进行文件读取的简单 C 语言示例代码:
#include
#include
#include
#include
#include
#include
#define QUEUE_DEPTH 1
#define BUFFER_SIZE 4096
int main {
struct io_uring ring;
struct io_uring_cqe *cqe;
struct io_uring_sqe *sqe;
int ret, fd;
char buffer[BUFFER_SIZE];
// 打开文件
fd = open("testfile.txt", O_RDONLY);
if (fd
perror("open");
return 1;
}
// 初始化io_uring实例
ret = io_uring_queue_init(QUEUE_DEPTH, ˚, 0);
if (ret
perror("io_uring_queue_init");
return 1;
}
// 获取一个提交队列条目
sqe = io_uring_get_sqe(˚);
if (!sqe) {
fprintf(stderr, "io_uring_get_sqe failed
");
return 1;
}
// 准备读取请求
io_uring_prep_read(sqe, fd, buffer, BUFFER_SIZE, 0);
// 提交请求
ret = io_uring_submit(˚);
if (ret
perror("io_uring_submit");
return 1;
}
// 等待请求完成
ret = io_uring_wait_cqe(˚, &cqe);
if (ret
perror("io_uring_wait_cqe");
return 1;
}
// 检查请求结果
if (cqe->res
fprintf(stderr, "I/O error: %s
", strerror(-cqe->res));
return 1;
}
// 输出读取的数据
write(STDOUT_FILENO, buffer, cqe->res);
// 释放完成队列条目
io_uring_cqe_seen(˚, cqe);
// 清理
io_uring_queue_exit(˚);
close(fd);
return 0;
}①打开文件 :
fd = open("testfile.txt", O_RDONLY);使用open函数打开名为testfile.txt的文件,以只读模式打开。如果打开失败,perror函数会输出错误信息并返回 1。
②初始化 io_uring 实例 :
ret = io_uring_queue_init(QUEUE_DEPTH, ˚, 0);调用io_uring_queue_init函数初始化 io_uring 实例,QUEUE_DEPTH指定了队列的深度,这里设置为 1,表明最多可以同时处理 1 个 I/O 请求。如果初始化失败,perror函数会输出错误信息并返回 1 。
③获取提交队列条目 :
sqe = io_uring_get_sqe(˚);使用io_uring_get_sqe函数从提交队列中获取一个空的提交队列条目(SQE),用于描述 I/O 请求。如果获取失败,输出错误信息并返回 1 。
④准备读取请求 :
io_uring_prep_read(sqe, fd, buffer, BUFFER_SIZE, 0);通过io_uring_prep_read函数填充 SQE,准备一个读取请求。参数依次为 SQE 指针、文件描述符fd、缓冲区buffer、读取长度BUFFER_SIZE和偏移量 0 。
⑤提交请求 :
ret = io_uring_submit(˚);调用io_uring_submit函数将提交队列中的请求提交给内核处理。如果提交失败,perror函数会输出错误信息并返回 1 。
⑥等待请求完成 :
ret = io_uring_wait_cqe(˚, &cqe);使用io_uring_wait_cqe函数阻塞等待,直到有 I/O 请求完成,完成的结果会存储在cqe中。如果等待失败,perror函数会输出错误信息并返回 1 。
⑦检查请求结果 :
if (cqe->res
fprintf(stderr, "I/O error: %s
", strerror(-cqe->res));
return 1;
}检查完成队列条目(CQE)的结果cqe->res,如果小于 0 表明 I/O 操作失败,通过strerror函数获取错误信息并输出,然后返回 1 。
⑧输出读取的数据 :
write(STDOUT_FILENO, buffer, cqe->res);如果 I/O 操作成功,使用write函数将读取到的数据输出到标准输出。
⑨释放完成队列条目 :
io_uring_cqe_seen(˚, cqe);调用io_uring_cqe_seen函数标记 CQE 已处理,以便内核可以重用该位置。
⑩清理 :
io_uring_queue_exit(˚);
close(fd);最后,调用io_uring_queue_exit函数清理 io_uring 实例,关闭文件描述符 。
6.2常见问题与解决方法
在使用 io_uring 进行实践时,初学者可能会遇到以下一些问题:
- 初始化失败:在调用io_uring_queue_init时可能会失败,常见缘由包括内核版本不支持、系统资源不足等。解决方法是第一确保内核版本符合要求,然后检查系统资源(如内存、文件描述符限制等)。可以通过ulimit -n查看当前用户的文件描述符限制,若不够可以通过修改/etc/security/limits.conf文件来增加限制 。
- I/O 请求提交错误:调用io_uring_submit时返回错误,可能是由于提交队列已满、SQE 填充不正确等。可以检查提交队列的深度设置是否合理,以及 SQE 的各个字段是否正确填充,列如文件描述符是否有效、缓冲区地址是否正确等 。
- 获取完成队列条目失败:使用io_uring_wait_cqe或io_uring_peek_cqe获取 CQE 时失败,可能是由于内核处理 I/O 请求出错、信号干扰等。可以检查内核日志(如/var/log/syslog)查看是否有相关错误信息,同时注意在多线程环境中处理信号时,要确保信号处理函数不会干扰 io_uring 的正常工作 。
- 内存锁定限制问题:在使用 io_uring 时,可能会遇到java.lang.RuntimeException: failed to create io_uring ring fd Cannot allocate memory的异常,这一般是由于内存锁定限制(memlock)不足导致的。解决方法是检查当前 memlock 限制(使用ulimit -l命令),并通过修改系统配置文件(如/etc/security/limits.conf)或使用命令行工具(如ulimit -l unlimited)来增加 memlock 限制,然后重新启动应用程序并确认 memlock 限制已成功增加 。



















- 最新
- 最热
只看作者