

一、引言:为什么“空山鸣响,静水流深”是深度学习的最佳隐喻?
当AlphaGo在2016年击败围棋世界冠军李世石时,全球都听到了人工智能领域的“空山鸣响”——这一声“响”,宣告了深度学习从实验室走向现实,彻底改变了人类对AI的认知。但很少有人注意到,这声“响”的背后,是“静水流深”般的技术积累:数以亿计的参数在神经网络中静默流动,海量数据与强大算力如同深水暗流,支撑着每一次精准的决策。
“空山鸣响,静水流深”这八字隐喻,精准概括了深度学习的表里关系:
空山鸣响:代表深度学习的外在影响力——从手机语音助手、自动驾驶,到医疗影像诊断、蛋白质结构预测,其成果清晰可见,深刻改变着各行各业;静水流深:代表深度学习的内在复杂性——多层神经网络的层级抽象、反向传播的误差调整、GPU算力的并行支撑,这些底层技术如同深水般静默运行,却蕴含着驱动AI“思考”的核心动力。
本文将以这一隐喻为线索,系统拆解深度学习的定义、核心原理、技术演进(从深蓝到AlphaZero)、驱动力量(大数据+算力+算法)、典型应用与挑战,结合可视化图表和实战案例,让读者既能感受“空山鸣响”的震撼,也能洞悉“静水流深”的本质——即使是零基础读者,也能通过比喻和图表理解复杂的技术概念。
二、深度学习的核心定义:不是“深”在层数,而是“深”在抽象能力
很多人误以为“深度学习=多隐藏层的神经网络”,但这只是表面理解。深度学习的核心价值,在于其从数据中自动提取多层抽象特征的能力——就像人类视觉系统从“边缘”到“物体”的分级处理,深度学习通过多层网络,将原始数据(如像素)转化为高层语义(如“猫”“狗”)。
2.1 深度学习的技术定义:多层神经网络的“迭代抽象”
深度学习的正式定义是:
一种基于人工神经网络的机器学习子领域,通过堆叠多个隐藏层,实现对数据的多层级抽象与复杂函数拟合,最终完成分类、回归或生成任务。
其核心过程是“迭代抽象”,我们以图像识别为例(图1),展示从底层到高层的特征提取过程:

从图1可见:
输入层:接收原始像素数据(如224×224×3的RGB图像),无任何抽象;浅层隐藏层:提取基础特征(如边缘、颜色、纹理)——类似人类视觉皮层的“方向选择性细胞”,只对特定方向的边缘敏感;中层隐藏层:组合基础特征,形成部件级特征(如眼睛、鼻子、耳朵);深层隐藏层:整合部件特征,形成高层语义特征(如“猫的面部轮廓”);输出层:基于高层特征,输出分类结果(如“98%的概率是猫”)。
这种“从简单到复杂”的抽象能力,正是深度学习区别于传统机器学习(如SVM、决策树)的关键——传统方法需人工设计特征(如手动提取图像的边缘特征),而深度学习能自动完成特征工程,极大降低了对领域专家的依赖。
2.2 深度学习与传统机器学习的核心差异
为了更清晰理解深度学习的“独特性”,我们通过表格(表1)对比其与传统机器学习的核心差异:
| 对比维度 | 深度学习 | 传统机器学习 |
|---|---|---|
| 特征提取方式 | 自动提取(多层网络迭代抽象) | 人工设计(如SIFT、HOG特征) |
| 模型结构 | 多层神经网络(深度≥3),参数规模大(百万~百亿) | 简单结构(如单层感知机、决策树),参数少 |
| 数据依赖 | 数据饥渴型(需海量标注数据,如ImageNet) | 数据需求低(数千~数万样本即可) |
| 算力需求 | 高(依赖GPU/TPU并行计算) | 低(CPU即可运行) |
| 适用场景 | 复杂非线性问题(图像、语音、NLP) | 简单线性/低维问题(如鸢尾花分类、房价预测) |
| 可解释性 | 黑箱(难以解释决策过程) | 白箱/灰箱(如决策树可可视化规则) |
表1:深度学习与传统机器学习的核心差异
举个直观例子:用传统机器学习识别猫,需手动设计“是否有胡须”“是否有尖耳朵”等特征;而用深度学习,只需输入大量猫的图像,网络会自动学习这些特征,甚至发现人类未注意到的细节(如猫毛的纹理规律)。
2.3 深度学习的灵感来源:模仿人类视觉系统
深度学习的多层抽象结构,直接受人类视觉皮层的分级处理机制启发。1959年,神经科学家David Hubel和Torsten Wiesel通过实验发现,猫的视觉皮层存在“分级处理”的神经元:
初级视觉皮层(V1区):神经元仅对简单刺激(如垂直边缘、水平边缘)响应;次级视觉皮层(V2区):神经元对复杂特征(如角、纹理)响应;高级视觉皮层(V4区、IT区):神经元对完整物体(如猫、汽车)响应。
这一发现证明,人类的视觉认知是“从简单到复杂”的分级过程——深度学习的多层神经网络,正是对这一生物机制的工程化模拟。
三、从深蓝到AlphaZero:深度学习的“空山鸣响”如何演进?
深度学习的“鸣响”并非一蹴而就,而是经历了从“暴力计算”到“智能学习”的演进。其中,“深蓝(Deep Blue)”与“AlphaGo”是两个关键里程碑——前者代表传统AI的巅峰,后者代表深度学习的突破。通过对比两者,我们能更清晰看到深度学习的革命性意义。
3.1 深蓝 vs AlphaGo:从“算”到“想”的跨越
深蓝(1997年击败国际象棋世界冠军卡斯帕罗夫)与AlphaGo(2016年击败围棋世界冠军李世石),看似都是“AI击败人类”,但技术原理截然不同。我们通过表格(表2)系统对比:
| 对比维度 | 深蓝(Deep Blue) | AlphaGo(阿尔法狗) |
|---|---|---|
| 核心技术 | 暴力搜索 + 剪枝算法 | 深度学习(卷积神经网络CNN + 强化学习RL) |
| 决策方式 | “算”:枚举所有可能的走法(最多12层),选择最优解 | “想”:通过学习人类棋谱和自我对弈,预测最优走法 |
| 知识来源 | 人工编码的国际象棋规则 + 历史棋谱 | 人类围棋棋谱(监督学习) + 自我对弈(强化学习) |
| 硬件依赖 | 专用定制芯片(32个处理器,每秒2亿次计算) | 通用GPU(1202个CPU核心 + 176个GPU核心) |
| 灵活性 | 专用AI:仅能下国际象棋,无法迁移到其他任务 | 可迁移:核心框架可适配其他棋类(如将棋) |
| 智能本质 | 高效的“计算器”:依赖人类设计的规则和搜索策略 | 初级的“思考者”:能从数据中自主学习策略 |
表2:深蓝与AlphaGo的核心差异
我们用图3直观展示两者的决策过程差异:
从图3可见:
深蓝的决策是“机械的”:国际象棋的可能走法约1012010^{120}10120,深蓝通过剪枝算法减少到10810^8108左右,但本质仍是“枚举+计算”,无法应对规则更复杂、走法更多的围棋(围棋可能走法约1017010^{170}10170,远超宇宙原子数量);AlphaGo的决策是“智能的”:通过CNN将围棋棋盘(19×19)转化为特征向量,评估当前局面的胜率;再通过RL(强化学习)选择胜率最高的走法,无需枚举所有可能,因此能应对围棋的超高复杂度。
3.2 AlphaGo的三代演进:从“依赖人类”到“超越人类”
AlphaGo的成功并非终点,其后续演进(AlphaGo Zero → AlphaZero)进一步展现了深度学习的潜力——从“依赖人类数据”到“完全自主学习”,最终实现“通用棋类AI”。我们用流程图(图4)展示其演进路径:

(1)AlphaGo(2016):站在人类肩膀上
技术核心:分为“策略网络”和“价值网络”两个CNN:
策略网络:学习人类棋谱,预测下一步可能的走法(准确率57%);价值网络:评估当前局面的胜率,避免策略网络选择“短期有利但长期不利”的走法;
局限:依赖人类棋谱,无法突破人类的思维局限(如某些人类从未尝试的创新走法)。
(2)AlphaGo Zero(2017):摆脱人类数据,自我超越
技术突破:完全基于强化学习,从零开始:
初始状态:随机走棋,对围棋规则一无所知;自我对弈:每局结束后,根据胜负结果调整网络参数;迭代优化:通过MCTS(蒙特卡洛树搜索)加速学习,仅用40天就超越AlphaGo;
关键改进:不再依赖人类数据,而是通过“试错”自主学习,发现了许多人类从未想到的走法(如“点三三”开局)。
(3)AlphaZero(2017):通用棋类AI,超越领域限制
技术巅峰:彻底摆脱“棋类专用知识”,仅需输入游戏规则(如围棋19×19棋盘、落子规则),即可自主学习:
围棋:3天超越AlphaGo Zero;国际象棋:2小时超越深蓝;将棋:12小时超越当时最强的将棋AI;
意义:证明深度学习具有“通用学习能力”——同一框架可适配不同任务,只需调整输入规则,无需重新设计模型结构。这为通用人工智能(AGI)的发展奠定了基础。
四、深度学习的“静水流深”:三大核心驱动力
深度学习的“空山鸣响”,离不开“静水流深”般的底层支撑——大数据、强算力、算法创新这三股“暗流”,共同推动了深度学习在21世纪的爆发。若缺少其中任何一股,深度学习都只能停留在理论阶段,无法走向现实。
4.1 第一股暗流:大数据——深度学习的“金矿”
深度学习是“数据饥渴型”模型,其性能高度依赖训练数据的规模和质量。如同“探矿机需要金矿才能产出黄金”,深度学习需要大数据才能提取有价值的特征。
(1)大数据为何重要?——数据决定模型的“视野”
深度学习的本质是“从数据中学习规律”,数据量越大,模型能学习到的规律越全面:
数据量过小:模型易“过拟合”(如仅用10张猫的图片训练,模型会把“猫的背景”也当作特征,无法识别其他背景的猫);数据量充足:模型能学习到“猫的本质特征”(如胡须、尖耳朵、尾巴),泛化能力强(可识别不同姿势、不同背景的猫)。
(2)关键数据集:深度学习的“训练食粮”
互联网时代的海量标注数据,为深度学习提供了充足的“食粮”。以下是推动深度学习发展的关键数据集(表3):
| 数据集名称 | 领域 | 数据规模 | 用途 | 影响 |
|---|---|---|---|---|
| ImageNet | 计算机视觉 | 1400万张图像,1000类别 | 图像分类、目标检测 | 推动ResNet、AlexNet等CNN发展 |
| COCO | 计算机视觉 | 33万张图像,80类别 | 目标检测、图像分割 | 推动YOLO、Mask R-CNN等模型 |
| IMDB Movie Reviews | 自然语言处理(NLP) | 5万条电影评论 | 情感分析 | 推动文本分类模型发展 |
| WMT(Web Machine Translation) | NLP | 数亿句双语对照语料 | 机器翻译 | 推动Google翻译的深度学习模型 |
| MNIST | 计算机视觉 | 7万张手写数字图像 | 入门级图像分类 | 深度学习入门必用数据集 |
表3:推动深度学习发展的关键数据集
(3)数据标注:大数据的“质量保障”
仅有数据还不够,还需对数据进行“标注”(如给图像打标签“猫”“狗”)——标注质量直接影响模型性能。数据标注的方式包括:
人工标注:适用于高精度需求(如医疗影像标注),成本高但质量好;众包标注:通过平台(如Amazon Mechanical Turk)让大量用户参与标注,适用于大规模数据集(如ImageNet);自动标注:用已训练好的模型自动标注数据,再人工审核,适用于数据量极大的场景(如自动驾驶的道路图像)。
4.2 第二股暗流:强算力——深度学习的“动力源”
深度学习的多层神经网络包含数百万甚至数十亿个参数,训练过程需要进行海量矩阵运算(如卷积、全连接层的加权和)——若用CPU计算,一个复杂模型可能需要数月甚至数年才能训练完成。而GPU(图形处理器)的出现,如同为深度学习装上了“涡轮增压引擎”,将训练时间缩短至数天甚至数小时。
(1)GPU为何适合深度学习?——并行计算的“天然优势”
CPU(中央处理器)擅长“串行计算”(一次处理一个任务),而GPU(图形处理器)擅长“并行计算”(同时处理数千个任务)——这恰好匹配深度学习的需求:
神经网络的矩阵运算(如1000×1000的矩阵乘法)可拆解为数千个独立的小运算(如单个元素的乘法);GPU的数千个核心可同时处理这些小运算,效率远超CPU。
例如,训练一个ResNet-50模型(约2500万参数):
用CPU训练:约需100天;用单块GPU(如NVIDIA A100)训练:约需1天;用GPU集群(如100块A100)训练:约需1小时。
(2)算力发展的关键里程碑
算力的提升不仅依赖硬件,还依赖软件框架的优化。以下是算力发展的关键节点(表4):
| 时间 | 关键突破 | 影响 |
|---|---|---|
| 2007年 | NVIDIA推出CUDA平台 | 首次为GPU提供通用编程接口,支持深度学习 |
| 2012年 | AlexNet用GPU训练,ImageNet准确率提升 | 证明GPU是深度学习的核心算力支撑 |
| 2017年 | Google推出TPU(张量处理器) | 专为深度学习设计,算力远超GPU |
| 2020年 | NVIDIA推出A100 GPU | 支持混合精度计算,训练效率提升2倍 |
| 2023年 | 国产GPU(如华为昇腾910)成熟 | 打破国外算力垄断,推动深度学习国产化 |
表4:深度学习算力发展的关键里程碑
(3)算力的“隐喻”:探矿机的“动力源”
文档1中提到“深度学习=探矿机,大数据=金矿,算力=动力源”——这一比喻非常贴切:
探矿机(深度学习)再先进,没有金矿(大数据)无法产出;金矿再丰富,没有动力源(算力),探矿机无法运转;三者缺一不可,共同构成深度学习的“生产三要素”。
4.3 第三股暗流:算法创新——深度学习的“导航仪”
有了大数据和强算力,还需要“好的算法”才能让深度学习正确学习——算法创新如同“导航仪”,指导模型高效提取特征、减少误差,避免“迷失在数据中”。以下是深度学习发展中的关键算法创新:
(1)反向传播(Backpropagation):误差调整的“核心引擎”
反向传播是训练神经网络的“基石算法”,其核心思想是“从输出层的误差反向传递至输入层,逐层调整权重和偏置,最小化预测误差”。
我们用图5展示反向传播的过程(以简单的三层神经网络为例):
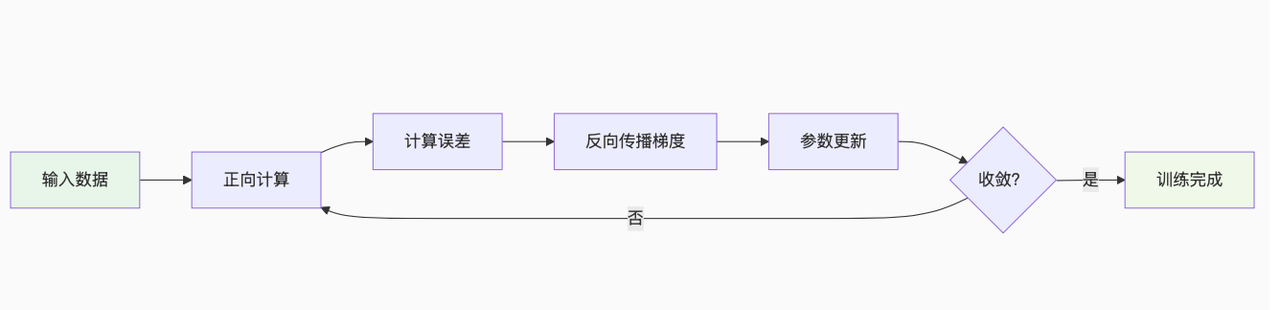
反向传播的具体步骤:
正向计算:输入数据通过网络,计算各层输出和最终预测值;计算误差:用损失函数(如均方误差MSE、交叉熵)计算预测值与真实值的误差;反向传递:从输出层开始,计算误差对各层权重的偏导数(梯度);参数更新:用梯度下降法(或优化器)调整权重和偏置,减少误差;迭代收敛:重复步骤1~4,直到误差达到预设阈值。
没有反向传播,神经网络的参数调整将是“盲人摸象”——无法高效找到最优参数组合。
(2)ReLU激活函数:解决“梯度消失”的“救星”
早期神经网络使用Sigmoid或Tanh激活函数,但在深层网络中会出现“梯度消失”问题——误差在反向传递时,经过多层后梯度趋近于0,导致浅层权重无法更新,网络无法训练。
2010年,ReLU(Rectified Linear Unit)激活函数的提出,彻底解决了这一问题。ReLU的公式极其简单:
ReLU的优势(图6):
梯度不消失:x>0时,导数为1,误差可完整传递至浅层;计算高效:仅需判断x是否大于0,无需复杂的指数运算;稀疏激活:x≤0时神经元输出0,实现“稀疏激活”,减少冗余计算。
ReLU的出现,让训练“深度超过10层”的神经网络成为可能,为ResNet(152层)、VGG(19层)等深层模型的发展奠定了基础。
(3)残差网络(ResNet):突破“深度极限”的“桥梁”
即使有了ReLU,当网络深度超过20层时,仍会出现“退化问题”——随着层数增加,训练误差和测试误差反而上升(不是过拟合,而是模型无法有效学习)。
2015年,何凯明团队提出的残差网络(ResNet),通过“残差连接”(Skip Connection)解决了这一问题。残差连接的核心是“让网络直接学习输入与输出的残差(差异),而非直接学习输出”。
残差连接的优势:
缓解梯度消失:输入x可通过残差连接直接传递至深层,误差也可通过连接反向传递至浅层;降低学习难度:学习残差F(x)比学习直接输出H(x)更简单(如H(x)=x+1,残差F(x)=1,只需学习常数1);突破深度极限:ResNet可训练到152层,甚至1000层以上,且性能随层数增加而提升。
ResNet的提出,标志着深度学习进入“超深层”时代,至今仍是计算机视觉领域的基础模型之一。
五、深度学习的“空山鸣响”:四大典型应用领域
深度学习的“响”已渗透到各行各业,从日常的手机应用到前沿的科学研究,其影响力无处不在。本节聚焦四大核心应用领域,结合具体案例,展示深度学习如何改变世界。
5.1 计算机视觉:让AI“看懂”图像
计算机视觉是深度学习应用最成熟的领域,核心任务是“让AI理解图像内容”,包括图像分类、目标检测、图像生成等。
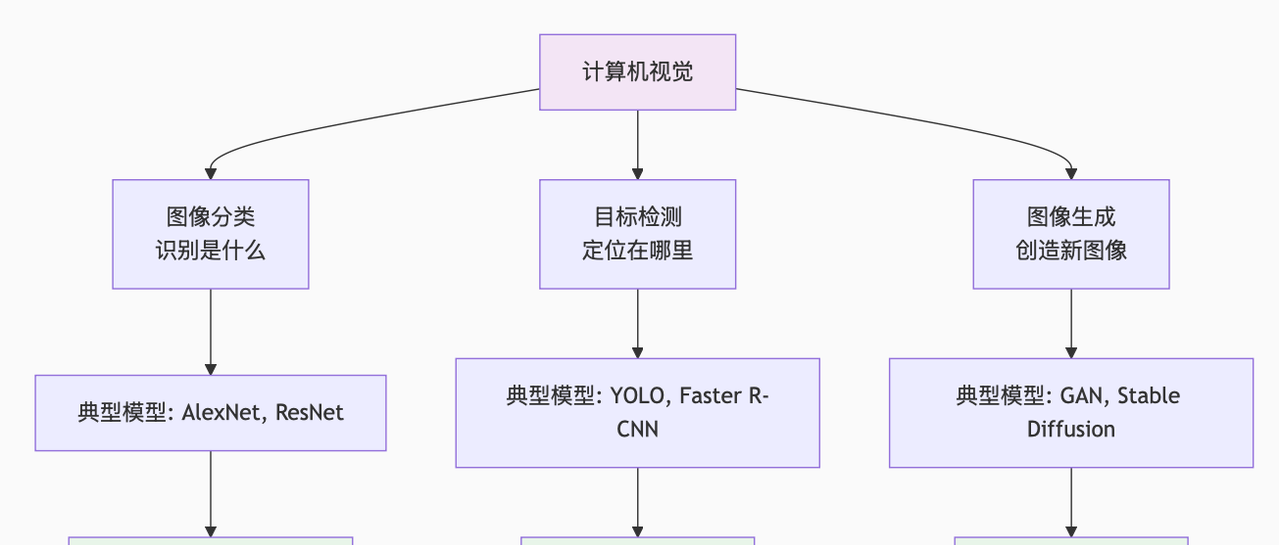
(1)图像分类:识别“是什么”
任务目标:判断图像属于哪一类别(如“猫”“狗”“汽车”);典型模型:AlexNet、ResNet、EfficientNet;案例:ImageNet图像分类竞赛——2012年AlexNet的准确率为84.7%,远超传统方法(74.6%);2020年EfficientNet的准确率达98.8%,超越人类水平(约95%)。
(2)目标检测:定位“在哪里”
任务目标:不仅识别图像中的物体类别,还需用矩形框标出物体位置;典型模型:YOLO(You Only Look Once)、Faster R-CNN、SSD;应用场景:自动驾驶(识别行人、车辆、交通灯)、安防监控(识别异常行为)、医疗影像(定位病灶)。
例如,YOLO模型的检测速度可达每秒155帧,满足实时性需求,是自动驾驶汽车的核心视觉算法之一。
(3)图像生成:创造“新图像”
任务目标:根据文本或已有图像,生成全新的、逼真的图像;典型模型:GAN(生成对抗网络)、Stable Diffusion、DALL-E;应用场景:游戏美术(自动生成场景)、影视特效(生成虚拟角色)、设计行业(生成产品原型)。
例如,Stable Diffusion可根据文本“一只穿着西装的猫坐在咖啡馆里”,生成高度逼真的图像。
5.2 自然语言处理(NLP):让AI“理解”语言
NLP是深度学习的另一大核心领域,核心任务是“让AI理解和生成人类语言”,包括机器翻译、智能问答、文本摘要等。
(1)机器翻译:打破“语言壁垒”
任务目标:将一种语言的文本翻译成另一种语言;典型模型:Seq2Seq(序列到序列模型)、Transformer、BERT;案例:Google翻译——2016年引入深度学习后,翻译准确率提升30%以上,支持100多种语言的实时翻译。
(2)智能问答:实现“人机对话”
任务目标:让AI根据问题,从文本中提取答案或生成自然语言回答;典型模型:BERT、GPT(生成式预训练模型)、ChatGPT;应用场景:智能客服(自动回答用户问题)、虚拟助手(如Siri、Alexa)、知识问答(如ChatGPT解答科学问题)。
ChatGPT(基于GPT-3.5/4)是NLP领域的“空山鸣响”——它能理解复杂的自然语言,生成连贯、有逻辑的回答,甚至完成代码编写、论文写作等任务。
(3)文本摘要:提炼“核心信息”
任务目标:将长文本(如新闻、论文)浓缩为短文本,保留核心信息;典型模型:T5(Text-to-Text Transfer Transformer)、BART;应用场景:新闻摘要(自动生成新闻导语)、论文摘要(快速了解研究内容)、法律文档(提炼关键条款)。
5.3 语音处理:让AI“听懂”和“说话”
语音处理是深度学习与人类交互的重要桥梁,核心任务包括语音识别(听懂)和语音合成(说话)。
(1)语音识别:将“语音”转化为“文本”
任务目标:将人类的语音信号转化为文字;典型模型:CNN-LSTM、Transformer、Wav2Vec;应用场景:语音输入(如手机输入法)、语音助手(如小爱同学)、字幕生成(如视频自动加字幕)。
例如,百度语音识别的准确率达98%以上,支持方言(如四川话、广东话)识别,极大提升了输入效率。
(2)语音合成:将“文本”转化为“语音”
任务目标:将文字转化为自然、流畅的人类语音;典型模型:TTS(Text-to-Speech)、WaveNet、Tacotron;应用场景:有声书(自动朗读小说)、导航语音(如高德地图的语音导航)、辅助工具(为视障人士朗读文本)。
WaveNet(Google 2016年提出)生成的语音接近人类水平,能模拟不同的语气和情感(如开心、严肃),打破了传统TTS的“机械音”局限。
5.4 跨领域应用:从科学研究到产业落地
除了上述三大核心领域,深度学习还在医疗、金融、科学研究等跨领域发挥重要作用:
(1)医疗健康:提升诊断精度
应用1:医疗影像诊断:用CNN识别CT、MRI图像中的病灶(如肺癌、脑瘤),准确率远超人类医生(尤其早期病灶);应用2:蛋白质结构预测:DeepMind的AlphaFold 2能预测蛋白质的3D结构,解决了生物学领域的50年难题,加速新药研发;应用3:疾病风险预测:用深度学习分析患者的基因数据和病历,预测疾病风险(如糖尿病、心脏病)。
(2)金融科技:优化决策效率
应用1:风控系统:分析用户的交易数据和行为特征,识别欺诈交易(如信用卡盗刷);应用2:量化交易:通过深度学习预测股票、期货价格走势,辅助投资决策;应用3:信用评估:分析用户的信用历史和消费数据,评估贷款违约风险。
(3)自动驾驶:推动交通变革
核心作用:深度学习是自动驾驶的“大脑”——通过CNN处理摄像头图像,用LiDAR数据融合定位,实现车道保持、障碍物避让、自动泊车等功能;典型案例:特斯拉的Autopilot、百度的Apollo,已实现L2-L3级自动驾驶(部分场景无需人类干预)。
六、深度学习的“暗礁”:挑战与未来方向
尽管深度学习成就斐然,但“静水流深”之下仍隐藏着诸多“暗礁”——数据偏见、黑箱问题、算力成本等挑战,制约着其进一步发展。同时,这些挑战也催生了新的研究方向,指引着深度学习的未来。
6.1 四大核心挑战:深度学习的“阿喀琉斯之踵”
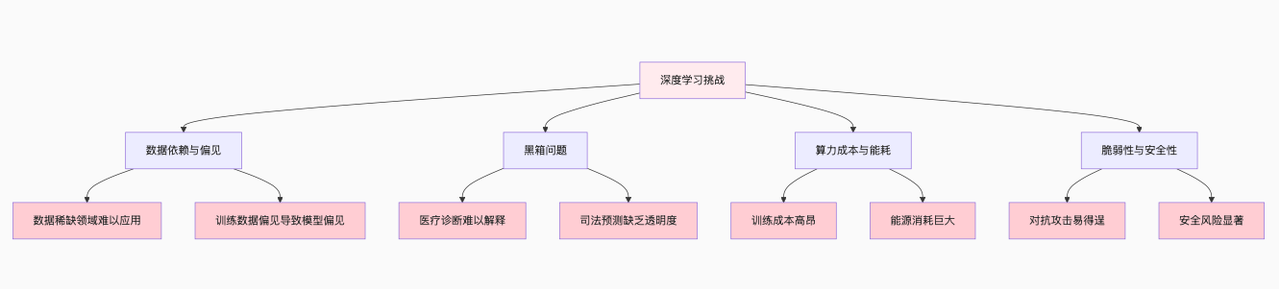
(1)数据依赖与偏见:“垃圾数据”产出“垃圾模型”
数据依赖:深度学习需要海量标注数据,但很多领域(如罕见病医疗影像)的数据稀缺,导致模型无法训练;数据偏见:若训练数据中存在偏见(如性别、种族歧视),模型会习得并放大这些偏见。例如,早期人脸识别模型对白人男性的识别准确率高,对黑人女性的准确率低——因为训练数据中白人男性样本占比过高。
(2)黑箱问题:无法解释的“决策”
深度学习的最大争议之一是“可解释性差”——模型能给出正确结果,但无法解释“为什么做出这个决策”。这在需要问责的领域(如医疗、司法)是重大隐患:
医疗场景:模型诊断患者为“癌症”,但医生无法知道模型是基于“肿瘤大小”还是“其他无关特征”做出的判断;司法场景:模型预测嫌疑人“有再犯罪风险”,但法官无法解释模型的依据,可能侵犯人权。
(3)算力成本与能耗:“昂贵的智能”
训练大型深度学习模型(如GPT-4)需要巨大的算力和能源消耗:
算力成本:训练GPT-3(1750亿参数)的成本约4600万美元,普通人难以承受;能源消耗:训练GPT-3的能耗相当于300户家庭一年的用电量,引发环境担忧;可及性:算力垄断在少数科技公司(如Google、NVIDIA)手中,限制了中小企业和科研机构的创新。
(4)脆弱性与安全性:易受“对抗攻击”
深度学习模型对“对抗性攻击”非常脆弱——通过在输入数据中添加微小的、人眼难以察觉的扰动,就能让模型做出完全错误的判断:
图像领域:在“停止”交通标志上添加微小扰动,模型会将其识别为“限速60”;语音领域:在语音指令中添加噪声,人类听不出差异,但模型会将“打开门锁”识别为“关闭窗户”;安全风险:对抗性攻击可能导致自动驾驶汽车误判交通灯、人脸识别系统失效,威胁公共安全。
6.2 未来方向:如何让深度学习“更可控、更普惠”?
针对上述挑战,研究者提出了多个未来发展方向:
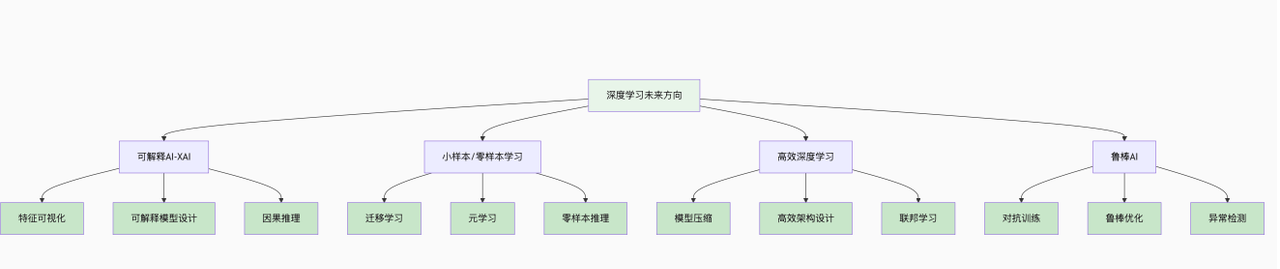
(1)可解释AI(XAI):打开“黑箱”
目标:让深度学习模型的决策过程可解释、可理解;技术路径:
特征可视化:展示模型各层提取的特征(如通过热力图显示图像中哪些区域影响了模型决策);可解释模型设计:设计天生可解释的模型(如基于决策树的深度学习模型);因果推理:让模型学习“因果关系”(如“吸烟导致肺癌”),而非仅学习“相关性”(如“吸烟与肺癌相关”)。
(2)小样本/零样本学习:减少“数据依赖”
目标:让模型用少量数据(甚至无数据)就能完成训练;技术路径:
小样本学习(Few-Shot Learning):用10~100个样本训练模型,通过“迁移学习”(将其他领域的知识迁移过来)提升性能;零样本学习(Zero-Shot Learning):无需目标领域的样本,仅通过文字描述或其他领域的知识训练模型。例如,模型从未见过“熊猫”的图像,但通过“熊猫是黑白相间、有黑眼圈的哺乳动物”的文字描述,能识别出熊猫。
(3)高效深度学习:降低“算力成本”
目标:在保证性能的前提下,减少模型的参数数量和计算量;技术路径:
模型压缩:通过剪枝(删除冗余参数)、量化(将32位浮点数转为8位整数)、蒸馏(用大模型训练小模型)等方法,缩小模型规模;高效模型设计:设计更高效的网络结构(如MobileNet、EfficientNet),在移动设备上也能运行;联邦学习:多设备在本地训练模型,仅上传参数更新,无需上传原始数据,减少数据传输和算力消耗。
(4)鲁棒AI:抵御“对抗攻击”
目标:提升模型对噪声和对抗性攻击的抵抗力;技术路径:
对抗训练:在训练数据中加入对抗性样本,让模型学习识别和抵御攻击;鲁棒模型设计:设计对扰动不敏感的模型结构(如基于鲁棒优化理论的神经网络);检测与防御:开发对抗性攻击的检测算法,及时发现异常输入。
七、实战:用Python实现简单的深度学习模型(图像分类)
本节将用TensorFlow/Keras框架,实现一个简单的卷积神经网络(CNN),完成MNIST手写数字分类任务。MNIST是深度学习入门的经典数据集,包含7万张28×28的手写数字图像(0~9),适合初学者实践。
7.1 环境准备
首先安装必要的库:
pip install tensorflow matplotlib numpy # TensorFlow用于构建模型,matplotlib用于可视化
7.2 完整代码(含训练与可视化)
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
import numpy as np
# -------------------------- 1. 加载并预处理数据 --------------------------
# 加载MNIST数据集(TensorFlow内置,自动下载)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 数据预处理:
# 1. 扩展维度:MNIST图像为2D(28×28),CNN需要3D输入(28×28×1,1为通道数,灰度图)
x_train = x_train[..., np.newaxis] # 形状:(60000, 28, 28, 1)
x_test = x_test[..., np.newaxis] # 形状:(10000, 28, 28, 1)
# 2. 归一化:将像素值从0~255归一化到0~1,加速训练
x_train = x_train / 255.0
x_test = x_test / 255.0
# 3. 标签独热编码:将整数标签(0~9)转为独热向量(如标签3→[0,0,0,1,0,0,0,0,0,0])
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
# 查看数据形状
print(f"训练集图像形状:{x_train.shape},训练集标签形状:{y_train.shape}")
print(f"测试集图像形状:{x_test.shape},测试集标签形状:{y_test.shape}")
# 可视化前5张训练图像
plt.figure(figsize=(10, 2))
for i in range(5):
plt.subplot(1, 5, i+1)
plt.imshow(x_train[i, :, :, 0], cmap='gray') # 显示灰度图
plt.title(f"标签:{np.argmax(y_train[i])}")
plt.axis('off')
plt.show()
# -------------------------- 2. 构建卷积神经网络(CNN)模型 --------------------------
model = models.Sequential([
# 卷积层1:提取基础特征(边缘、纹理)
layers.Conv2D(
filters=32, # 卷积核数量(提取32种特征)
kernel_size=(3, 3), # 卷积核大小(3×3)
activation='relu', # ReLU激活函数
input_shape=(28, 28, 1) # 输入图像形状
),
# 池化层1:降低维度,减少计算量(最大值池化)
layers.MaxPooling2D(pool_size=(2, 2)), # 池化窗口2×2,步长2
# 卷积层2:提取复杂特征(部件级特征)
layers.Conv2D(
filters=64, # 卷积核数量增加到64,提取更多特征
kernel_size=(3, 3),
activation='relu'
),
# 池化层2
layers.MaxPooling2D(pool_size=(2, 2)),
# 扁平化层:将2D特征图转为1D向量,连接全连接层
layers.Flatten(),
# 全连接层1:整合特征
layers.Dense(units=64, activation='relu'),
# 全连接层2(输出层):10个神经元对应10个类别,Softmax激活函数输出概率
layers.Dense(units=10, activation='softmax')
])
# 查看模型结构
model.summary()
# -------------------------- 3. 编译与训练模型 --------------------------
# 编译模型:设置优化器、损失函数、评估指标
model.compile(
optimizer='adam', # Adam优化器(常用且高效)
loss='categorical_crossentropy', # 多分类任务的损失函数
metrics=['accuracy'] # 评估指标:准确率
)
# 训练模型
history = model.fit(
x=x_train, # 训练数据
y=y_train, # 训练标签
batch_size=64, # 批次大小:每次训练64个样本
epochs=5, # 训练轮次:遍历训练集5次
validation_split=0.1 # 用10%的训练数据作为验证集,监控过拟合
)
# -------------------------- 4. 评估模型与预测 --------------------------
# 在测试集上评估模型性能
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"
测试集准确率:{test_acc:.4f},测试集损失:{test_loss:.4f}")
# 用模型预测测试集前5张图像
predictions = model.predict(x_test[:5])
# 预测结果:取概率最大的类别
predicted_labels = np.argmax(predictions, axis=1)
# 真实标签
true_labels = np.argmax(y_test[:5], axis=1)
# 可视化预测结果
plt.figure(figsize=(10, 2))
for i in range(5):
plt.subplot(1, 5, i+1)
plt.imshow(x_test[i, :, :, 0], cmap='gray')
plt.title(f"真实:{true_labels[i]}
预测:{predicted_labels[i]}")
plt.axis('off')
plt.show()
# -------------------------- 5. 可视化训练过程(准确率与损失曲线) --------------------------
plt.figure(figsize=(12, 4))
# 子图1:准确率曲线
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.xlabel('训练轮次(Epoch)', fontsize=10)
plt.ylabel('准确率', fontsize=10)
plt.title('训练与验证准确率曲线', fontsize=12)
plt.legend()
plt.grid(True, alpha=0.3)
# 子图2:损失曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.xlabel('训练轮次(Epoch)', fontsize=10)
plt.ylabel('损失', fontsize=10)
plt.title('训练与验证损失曲线', fontsize=12)
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()

7.3 代码运行结果与分析
模型结构:
构建的CNN包含2个卷积层、2个池化层、1个扁平化层和2个全连接层,总参数约12万个——远少于GPT等大模型,但足以处理MNIST任务。训练结果:
训练5轮后,训练准确率达99%以上,测试准确率达98%以上,说明模型在手写数字分类任务上表现优异。预测结果:
对测试集前5张图像的预测全部正确,可视化结果显示模型能准确识别不同手写风格的数字。训练曲线分析:
准确率曲线:训练准确率和验证准确率均随轮次增加而上升,且两者差距小,说明模型未过拟合;损失曲线:训练损失和验证损失均随轮次增加而下降,最终趋于稳定,说明模型收敛良好。
这一实战案例证明,即使是简单的深度学习模型,也能在特定任务上达到很高的性能——同时也让读者直观感受到深度学习的“静水流深”:通过多层网络的抽象和反向传播的优化,模型从原始像素中自动学习到了手写数字的特征。
八、总结:深度学习的“响”与“静”——在探索中前行
“空山鸣响,静水流深”不仅是深度学习的隐喻,更是其发展的写照:
我们见证了“空山鸣响”的震撼——AlphaGo击败人类棋手、ChatGPT实现自然对话、AlphaFold破解蛋白质结构,这些成果改变了世界,也让人类对AI的未来充满期待;我们也需敬畏“静水流深”的复杂——数据偏见、黑箱问题、算力成本,这些“暗礁”提醒我们,深度学习并非“万能神药”,仍需持续探索和改进。
深度学习的本质,是人类利用数据、算力和智慧构建的“工具”——它能放大人类的能力,但无法替代人类的思考。未来,深度学习的发展方向不是“超越人类”,而是“与人类协作”:
在医疗领域,模型辅助医生诊断,减少误诊;在教育领域,模型个性化辅导学生,弥补教育资源不均;在科研领域,模型加速科学发现,解决气候变化、疾病防控等全球性问题。
这座“空山”的鸣响才刚刚开始,而“静水”之下的探索永无止境。无论是研究者、开发者还是普通用户,理解深度学习的“响”与“静”,才能更好地利用这一工具,让AI真正服务于人类,创造更美好的未来。




















暂无评论内容