
从分页注意力、连续批处理、前缀缓存、推测解码等到多 GPU、多节点动态大规模服务
这篇文章中将逐步介绍构成现代高吞吐量 LLM 推理系统的所有核心系统组件和高级功能。重点拆解 vLLM 的工作原理。
本文分为五个部分:
- LLM 引擎与引擎核心 :vLLM 的基础(调度、Paged Attention、连续批处理等)
- 高级功能 :分块预填充、前缀缓存、引导式与推测解码、P/D 分离
- 规模扩展 :从单 GPU 执行到多 GPU 执行
- 服务层 :分布式/并发的 Web 服务框架
- 基准测试与自动调优 :衡量延迟与吞吐量
注:
- 分析基于 commit 42172ad (2025 年 8 月 9 日)。
- 目标读者:任何对最先进的 LLM 引擎工作原理感到好奇的人,以及有兴趣为 vLLM、SGLang 等项目做贡献的人。
- 本文重点关注 V1 引擎 。笔者也研究了 V0( 现已废弃 ),这对于理解项目的演变很有价值,并且许多概念依旧适用。
- 关于 LLM 引擎/引擎核心的第一部分可能有点信息过载/枯燥——但博客的其余部分有丰富的示例和图示。:)
LLM 引擎与引擎核心
LLM 引擎是 vLLM 的基本构建模块。它本身已经能实现高吞吐量推理——但仅限于离线场景。你还不能通过网络向客户提供服务。
我们将使用以下离线推理代码片段作为我们的示例(改编自 basic.py )。
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()环境变量:
-
VLLM_USE_V1="1"# 我们使用的是 V1 引擎 -
VLLM_ENABLE_V1_MULTIPROCESSING="0"# 我们在单个进程中运行
此配置为:
- 离线 (没有 Web/分布式系统框架)
- 同步 (所有执行都在单个阻塞进程中进行)
- 单 GPU (没有数据/模型/流水线/专家并行;DP/TP/PP/EP = 1)
- 使用标准的 Transformer (支持像 Jamba 这样的混合模型需要更复杂的混合 KV 缓存内存分配器)
从这里开始,我们将逐步构建一个在线、异步、多 GPU、多节点的推理系统——但依旧服务于标准的 Transformer。
在这个例子中,我们做了两件事:
- 实例化一个引擎
- 调用它的
generate方法,根据给定的提示词进行采样
让我们从分析构造函数开始。
LLM 引擎构造函数
引擎的主要组件包括:
- vLLM 配置 (包含所有用于配置模型、缓存、并行性等的参数)
- 处理器 (通过验证、Token 化和处理,将原始输入转换为
EngineCoreRequests) - 引擎核心客户端 (在我们的运行示例中,我们使用
InprocClient,它基本上等同于EngineCore;我们将逐步升级到DPLBAsyncMPClient,以实现大规模服务) - 输出处理器 (将原始的
EngineCoreOutputs转换为用户看到的RequestOutput)
注:随着 V0 引擎被废弃,类名和细节可能会发生变化。我将强调核心思想而非确切的函数签名。我会抽象掉部分但非全部细节。
引擎核心本身由几个子组件构成:
- 模型执行器 (Model Executor)(驱动模型的前向传播,目前我们处理的是
UniProcExecutor,它在单个 GPU 上有一个单独的Worker进程)。我们将逐步升级到支持多个 GPU 的MultiProcExecutor - 结构化输出管理器 (Structured Output Manager)(用于引导式解码——稍后会介绍)
- 调度器 (Scheduler)(决定哪些请求进入下一个引擎步骤)——它进一步包含:
- 策略设置 ——可以是 FCFS (先到先服务)或 priority (高优先级请求优先服务)
-
waiting和running队列 - KV 缓存管理器 ——Paged Attention 的核心
KV 缓存管理器维护一个 free_block_queue ——一个可用的 KV 缓存块池(数量级一般是数十万,取决于 VRAM 大小和块大小)。在 Paged Attention 期间,这些块作为索引结构,将 Token 映射到其计算出的 KV 缓存块。
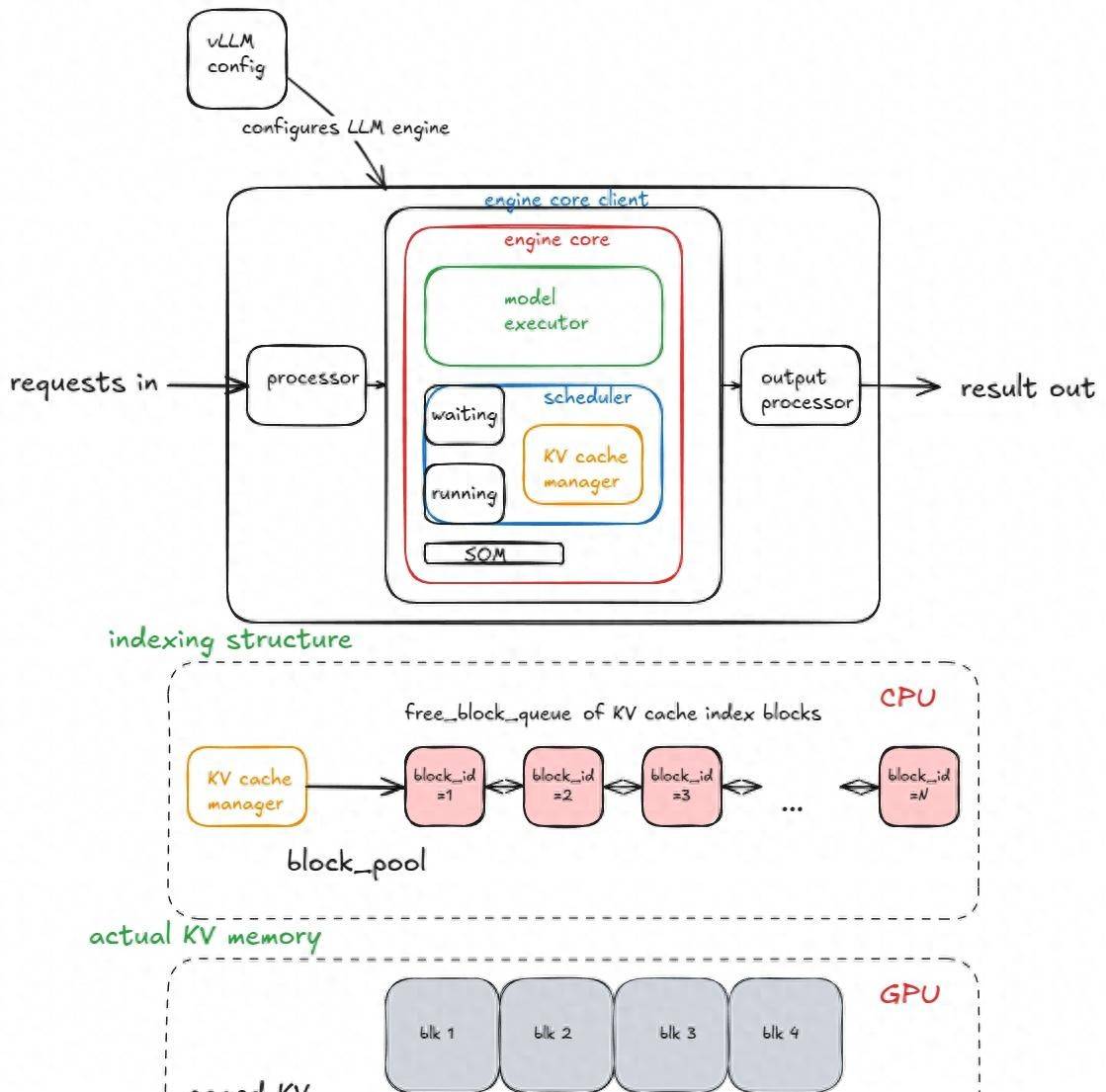 本节描述的核心组件及其关系
本节描述的核心组件及其关系
对于一个标准的 Transformer 层(非 MLA 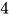 ),块大小计算如下:
),块大小计算如下: 2 * block_size (默认=16) * num_kv_heads * head_size * dtype_num_bytes (bf16 为 2)
在模型执行器构建期间,会创建一个 Worker 对象,并执行三个关键流程。(稍后,使用 MultiProcExecutor 时,这些一样的流程会在不同 GPU 上的每个 worker 进程中独立运行。)
1、初始化设备:
- 为 worker 分配一个 CUDA 设备(例如 “cuda:0″)并检查模型数据类型是否受支持(例如 bf16)
- 根据请求的
gpu_memory_utilization(例如 0.8 → 80% 的总 VRAM)验证是否有足够的 VRAM - 设置分布式配置(DP / TP / PP / EP 等)
- 实例化一个
model_runner(持有采样器、KV 缓存和前向传播缓冲区,如input_ids、positions等) - 实例化一个
InputBatch对象(持有 CPU 端的前向传播缓冲区、用于 KV 缓存索引的块表、采样元数据等)
2、加载模型:
- 实例化模型架构
- 加载模型权重
- 调用
model.eval()(PyTorch 的推理模式) - 可选:对模型调用
torch.compile()
3、初始化 KV 缓存:
- 获取每层的 KV 缓存规格。传统上这总是
FullAttentionSpec(同构 Transformer),但随着混合模型(如滑动窗口、类 Jamba 的 Transformer/SSM)的出现,情况变得更加复杂(参见 Jenga ) - 运行一次虚拟/性能分析的前向传播,并获取 GPU 内存快照,以计算可用 VRAM 中能容纳多少 KV 缓存块
- 分配、重塑并将 KV 缓存张量绑定到注意力层
- 准备注意力元数据(例如,将后端设置为 FlashAttention),这些元数据将在前向传播期间被内核使用
- 除非提供了
--enforce-eager,否则对每个预热批次大小进行一次虚拟运行并捕获 CUDA 图。CUDA 图将整个 GPU 工作序列记录到一个有向无环图(DAG)中。稍后在前向传播期间,我们启动/重放预先生成好的图,从而减少内核启动开销,进而改善延迟。
我在这里抽象掉了许多底层细节——但这些是我目前要介绍的核心部分,由于我会在接下来的章节中反复引用它们。
目前引擎已经初始化完毕,让我们继续看 generate 函数。
Generate 函数
第一步是验证请求并将其送入引擎。对于每个提示词,我们:
- 创建一个唯一的请求 ID 并记录其到达时间
- 调用一个输入预处理器,它将提示词 Token 化并返回一个包含
prompt、prompt_token_ids和type(文本、Token、嵌入等)的字典 - 将此信息打包成一个
EngineCoreRequest,并添加优先级、采样参数和其他元数据 - 将请求传递给引擎核心,引擎核心将其包装在一个
Request对象中,并将其状态设置为WAITING。然后该请求被添加到调度器的waiting队列中(如果是 FCFS 则追加,如果是 priority 则堆推送)
此时,引擎已经接收到输入,可以开始执行。在同步引擎的例子中,这些初始提示词是我们唯一要处理的——没有机制可以在运行中注入新的请求。相比之下,异步引擎支持这一点(即 连续批处理 ):在每个步骤之后,新旧请求都会被思考。
由于前向传播将批次展平为单个序列,并且自定义内核能高效处理它,所以即使在同步引擎中,连续批处理也从根本上得到了支持。
接下来,只要有请求需要处理,引擎就会重复调用其 step() 函数。每个步骤有三个阶段:
- 调度 :选择在此步骤中运行哪些请求(解码,和/或(分块)预填充)
- 前向传播 :运行模型并采样 Token
- 后处理 :将采样的 Token ID 附加到每个
Request,进行反 Token 化,并检查停止条件。如果一个请求完成,则进行清理(例如,将其 KV 缓存块返回到free_block_queue)并提前返回输出
停止条件是:
- 请求超出了其长度限制(
max_model_length或其自身的max_tokens) - 采样的 Token 是 EOS ID(除非启用了
ignore_eos-> 这在基准测试中很有用,当我们想强制生成特定数量的输出 Token 时) - 采样的 Token 匹配采样参数中指定的任何
stop_token_ids - 输出中出现了停止字符串——我们将输出截断到第一个停止字符串出现的位置,并在引擎中中止该请求(注意
stop_token_ids会出目前输出中,但停止字符串不会)。
 引擎循环 在流式模式下,我们会在生成中间 Token 时立即发送它们,但目前我们先忽略这一点。
引擎循环 在流式模式下,我们会在生成中间 Token 时立即发送它们,但目前我们先忽略这一点。
接下来,我们将更详细地研究调度。
调度器
推理引擎处理两种主要类型的工作负载:
- 预填充(Prefill) 请求——对所有提示词 Token 进行一次前向传播。这些一般是 计算密集型 (阈值取决于硬件和提示词长度)。最后,我们从最后一个 Token 位置的概率分布中采样一个 Token。
- 解码(Decode) 请求——仅对最近一个 Token 进行一次前向传播。所有之前的 KV 向量都已缓存。这些是 内存带宽密集型 ,由于我们依旧需要加载所有 LLM 权重(和 KV 缓存)才能计算一个 Token。
在 基准测试部分 ,我们将分析所谓的 GPU 性能的 roofline 模型。届时将更详细地探讨预填充/解码的性能特征。
得益于更智能的设计选择,V1 调度器可以在同一步骤中混合处理这两种类型的请求。相比之下,V0 引擎一次只能处理预填充或解码。
调度器优先处理解码请求——即那些已经在 running 队列中的请求。对于每个这样的请求,它会:
- 计算要生成的新 Token 数量(由于推测解码和异步调度,并不总是 1——稍后会详细介绍)。
- 调用 KV 缓存管理器的
allocate_slots函数(详见下文)。 - 通过减去步骤 1 中的 Token 数量来更新 Token 预算。
之后,它会处理来自 waiting 队列的预填充请求,它会:
- 获取已计算块的数量(如果前缀缓存被禁用,则返回 0——我们稍后会介绍)。
- 调用 KV 缓存管理器的
allocate_slots函数。 - 将请求从 waiting 队列中弹出并移至 running 队列,将其状态设置为
RUNNING。 - 更新 Token 预算。
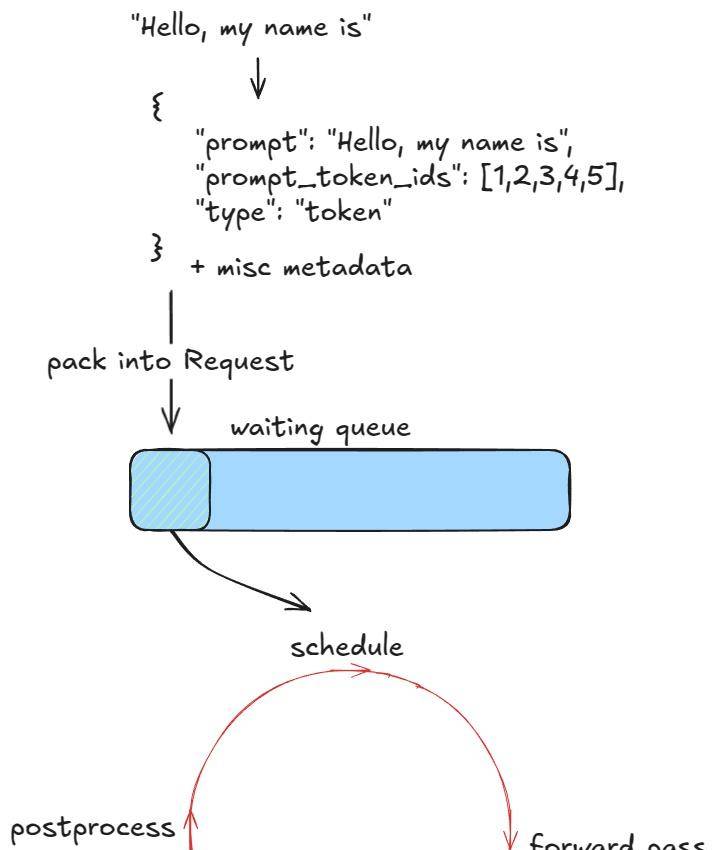
目前让我们看看 allocate_slots 做了什么,它:
- 计算块数 ——确定必须分配多少个新的 KV 缓存块(
n)。每个块默认存储 16 个 Token。例如,如果一个预填充请求有 17 个新 Token,我们需要ceil(17/16) = 2个块。 - 检查可用性 ——如果管理器池中没有足够的块,则提前退出。根据是解码还是预填充请求,引擎可能会尝试重计算抢占(V0 支持交换抢占)通过驱逐低优先级请求(调用
kv_cache_manager.free将 KV 块返回到块池),或者它可能会跳过调度并继续执行。 - 分配块 ——通过 KV 缓存管理器的协调器,从块池(前面提到的
free_block_queue双向链表)中获取前n个块。存储到req_to_blocks,这是一个将每个request_id映射到其 KV 缓存块列表的字典。
 KV 缓存块
KV 缓存块
我们终于准备好进行前向传播了!
运行前向传播
我们调用模型执行器的 execute_model ,它委托给 Worker , Worker 再委托给模型运行器。
以下是主要步骤:
- 更新状态 ——从
input_batch中修剪已完成的请求;更新与前向传播相关的杂项元数据(例如,每个请求的 KV 缓存块,将用于索引到分页 KV 缓存内存中)。 - 准备输入 ——将缓冲区从 CPU 复制到 GPU;计算位置;构建
slot_mapping(示例中会详细介绍);构造注意力元数据。 - 前向传播 ——使用自定义的分页注意力(paged attention)核函数运行模型。所有序列都被展平并连接成一个长的「超级序列」。位置索引和注意力掩码确保每个序列只关注自己的 Token,这使得连续批处理无需右填充即可实现。
- 收集末位 Token 状态 ——提取每个序列最后一个位置的隐藏状态并计算 logits。
- 采样 ——根据采样配置(贪婪、温度、top-p、top-k 等)从计算出的 logits 中采样 Token。
前向传播步骤本身有两种执行模式:
- Eager 模式 ——当启用 eager 执行时,运行标准的 PyTorch 前向传播。
- 「捕获」模式 ——当不强制使用 eager 时,执行/重放一个预先捕获的 CUDA Graph(还记得我们在引擎构造期间的初始化 KV 缓存流程中捕获了这些)。
这里有一个具体的例子,应该能让连续批处理和 Paged Attention 的概念更清晰:
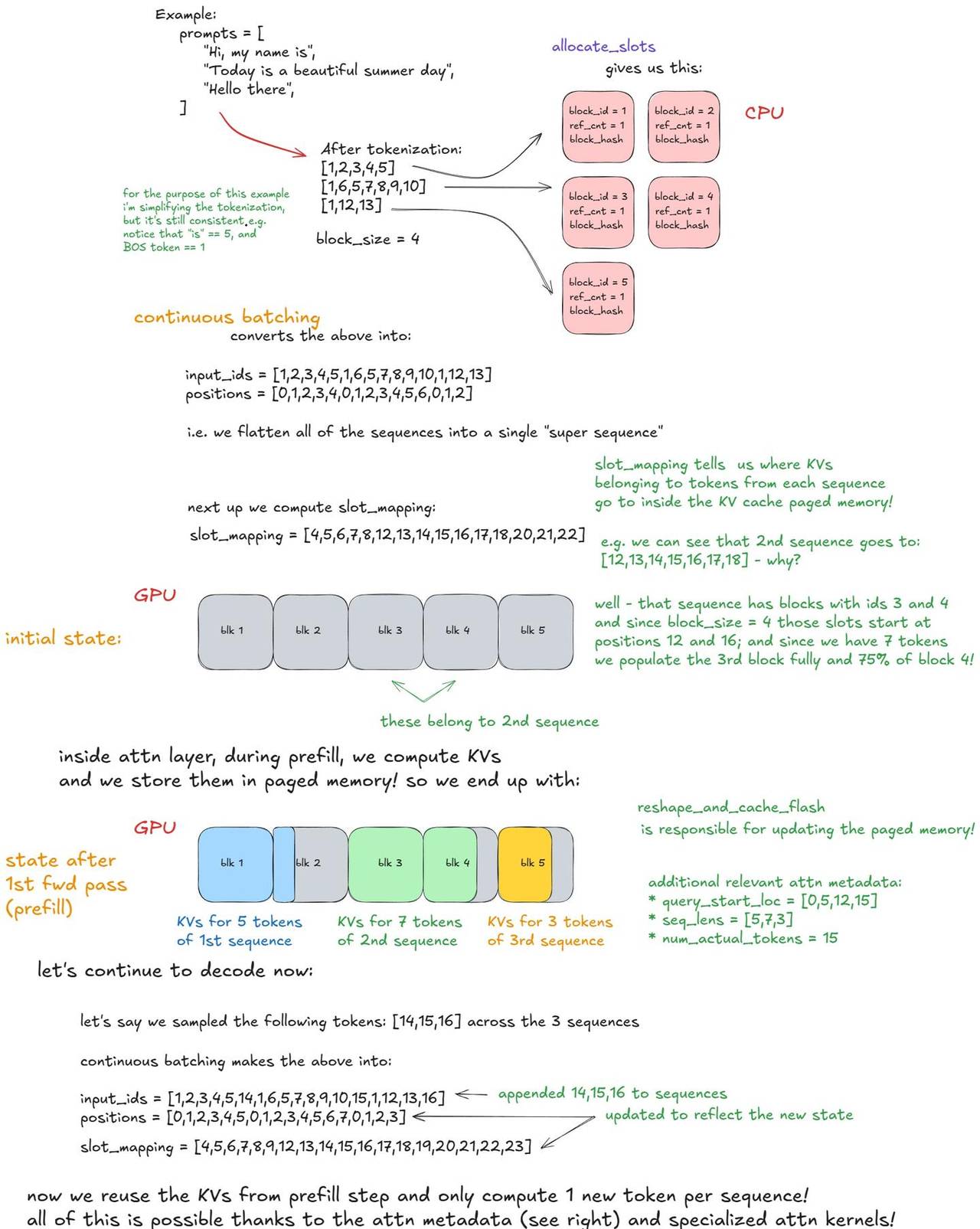 前向传播 – 连续批处理和 Paged Attention
前向传播 – 连续批处理和 Paged Attention
高级功能——扩展核心引擎逻辑
在掌握了基本的引擎流程之后,我们目前可以看看高级功能。
我们已经讨论了抢占、Paged Attention 和连续批处理。
接下来,我们将深入探讨:
- 分块预填充
- 前缀缓存
- 引导式解码(通过基于语法的有限状态机)
- 推测解码
- P/D 分离(预填充/解码)
分块预填充
分块预填充是一种处理长提示词的技术,它将其预填充步骤分成更小的块。没有它,我们可能会遇到单个超级长的请求独占一个引擎步骤,从而阻止其他预填充请求运行的情况。这将推迟所有其他请求并增加它们的延迟。
例如,假设每个块包含 n (=8)个 Token,用小写字母和「-」分隔。一个长提示词 P 可能看起来像 x-y-z ,其中 z 是一个不完整的块(例如 2 个 Token)。执行 P 的完整预填充将需要 ≥ 3 个引擎步骤(如果它在某个步骤中没有被调度执行,可能会 > 3),并且只有在最后一个分块预填充步骤中我们才会采样一个新的 Token。
下面是同一个例子的直观展示:
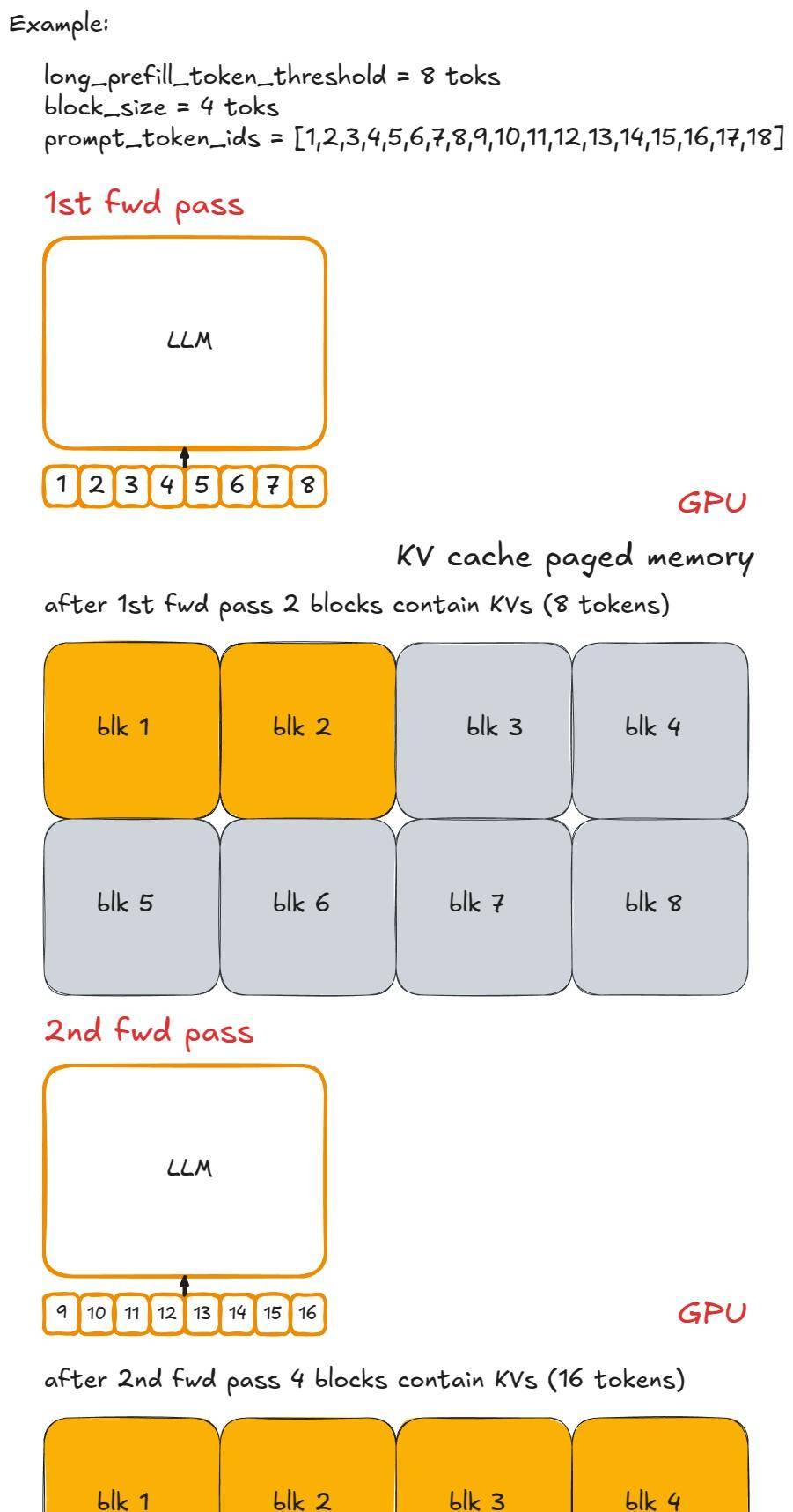 分块预填充 – 第 1 部分
分块预填充 – 第 1 部分
实现很简单:限制每一步的新 Token 数量。如果请求的数量超过 ,就将其重置为该确切值。底层的索引逻辑(如前所述)会处理剩下的事情。
long_prefill_token_threshold
在 vLLM V1 中,您可以通过将 设置为一个正整数来启用分块预填充。(严格来说,无论如何都可能发生,如果提示词长度超过 Token 预算,我们会截断它并运行分块预填充。)
long_prefill_token_threshold
前缀缓存
为了解释前缀缓存的工作原理,让我们对原始代码示例稍作调整:
from vllm import LLM, SamplingParams
long_prefix = "<一段被编码成多于 block_size 个 Token 的文本>"
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(long_prefix + prompts[0], sampling_params)
outputs = llm.generate(long_prefix + prompts[1], sampling_params)
if __name__ == "__main__":
main()前缀缓存避免了重复计算多个提示词在开头共享的 Token——因此称为 前缀 。
关键部分是 long_prefix :它被定义为任何长度超过一个 KV 缓存块(默认为 16 个 Token)的前缀。为简化示例,我们假设 long_prefix 的长度恰好是 n x block_size (其中 n ≥ 1 )。
也就是说,它与块边界完美对齐——否则我们将不得不重新计算 long_prefix_len % block_size 个 Token,由于我们无法缓存不完整的块。
没有前缀缓存,每次我们处理一个带有一样 long_prefix 的新请求时,我们都会重新计算所有 n x block_size 个 Token。
有了前缀缓存,这些 Token 只计算一次(它们的 KVs 存储在 KV 缓存分页内存中)然后被重用,所以只需要处理新的提示词 Token。这加速了预填充请求(尽管对解码没有协助)。
这在 vLLM 中是如何工作的?
在第一次 generate 调用期间,在调度阶段,在 内部,引擎会调用
kv_cache_manager.get_computed_blocks hash_request_tokens :
- 这个函数将
long_prefix + prompts[0]分成 16 个 Token 的块。 - 对于每个完整的块,它计算一个哈希值(使用内置的
hash或 SHA-256,后者更慢但冲突更少)。哈希值结合了前一个块的哈希、当前 Token 和可选的元数据。 - 每个结果都存储为一个
BlockHash对象,包含哈希值及其 Token ID。我们返回一个块哈希列表。
可选元数据包括:MM 哈希、LoRA ID、缓存盐值(注入到第一个块的哈希中,确保只有带有此缓存盐的请求才能重用块)。
该列表存储在 self.req_to_block_hashes[request_id] 中。
接下来,引擎调用 find_longest_cache_hit 来检查这些哈希中是否有任何一个已经存在于 中。在第一个请求上,没有找到命中。
cached_block_hash_to_block
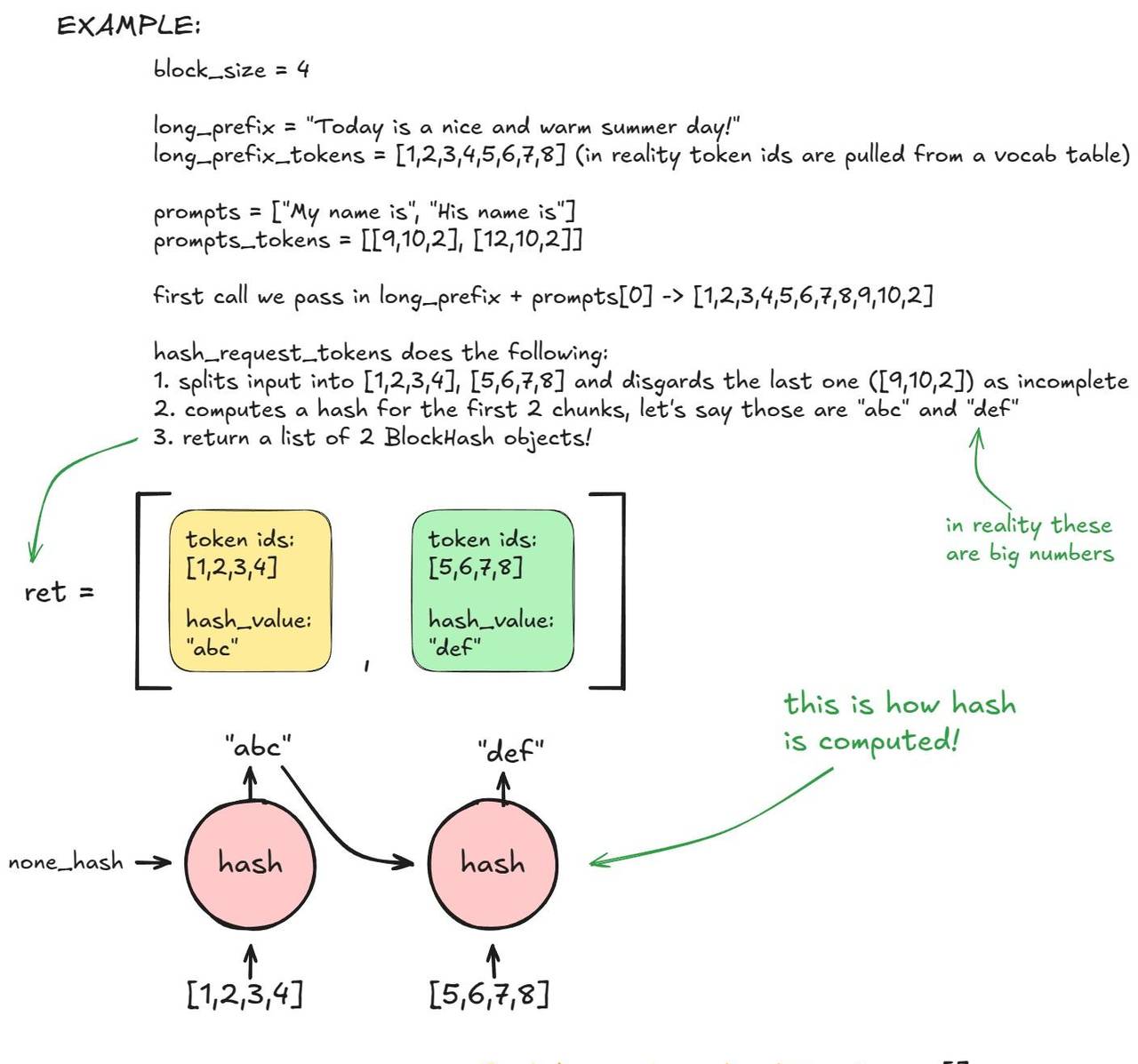 前缀缓存逻辑 – 第 1 部分
前缀缓存逻辑 – 第 1 部分
然后我们调用 allocate_slots ,它会调用 coordinator.cache_blocks ,这个函数将新的 BlockHash 条目与分配的 KV 块关联起来,并记录在 中。
cached_block_hash_to_block
之后,前向传播将在分页 KV 缓存内存中填充与我们上面分配的 KV 缓存块相对应的 KVs。
经过许多引擎步骤后,它会分配更多的 KV 缓存块,但这对于我们的例子来说不重大,由于前缀在 long_prefix 之后立即就分叉了。 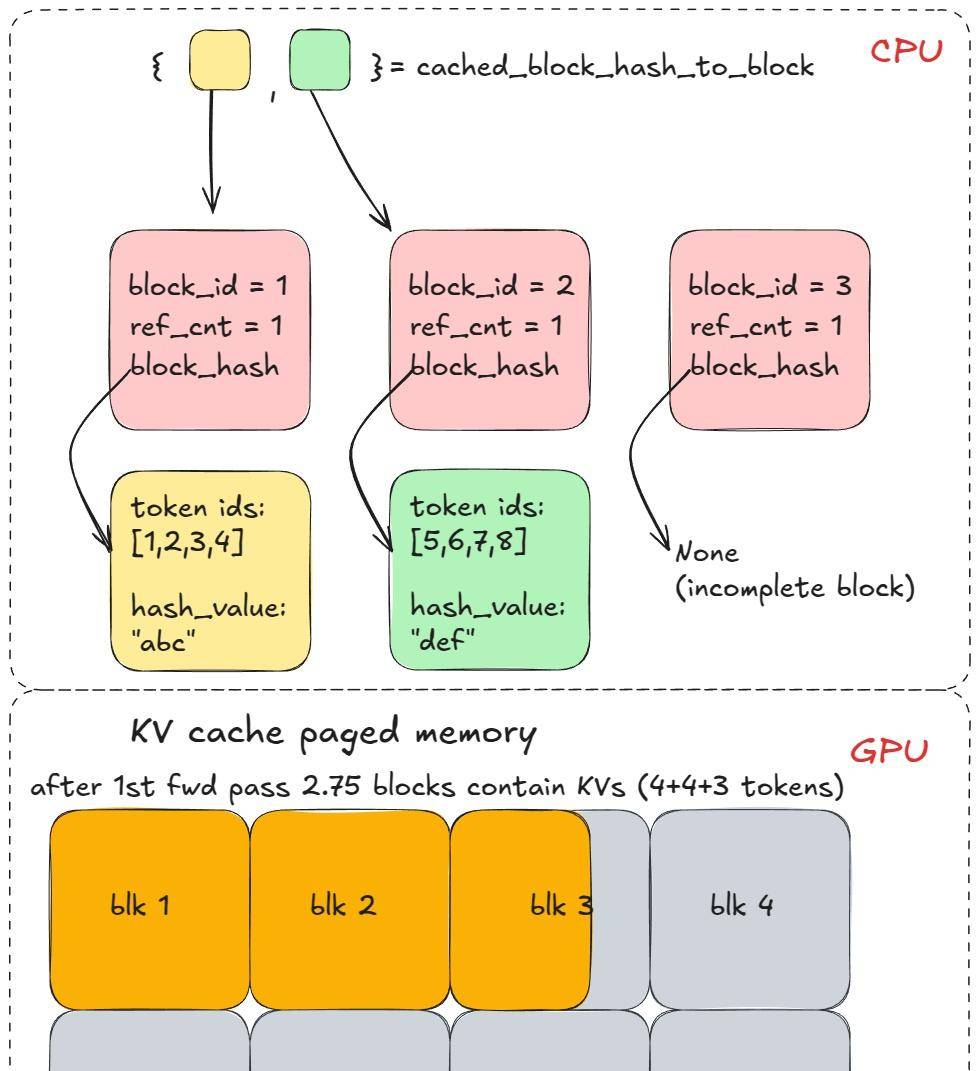 前缀缓存逻辑 – 第 2 部分
前缀缓存逻辑 – 第 2 部分
在第二次使用一样前缀调用 generate 时,步骤 1-3 会重复,但目前 find_longest_cache_hit 会为所有 n 个块找到匹配项(通过线性搜索)。引擎可以直接复用那些 KV 块。
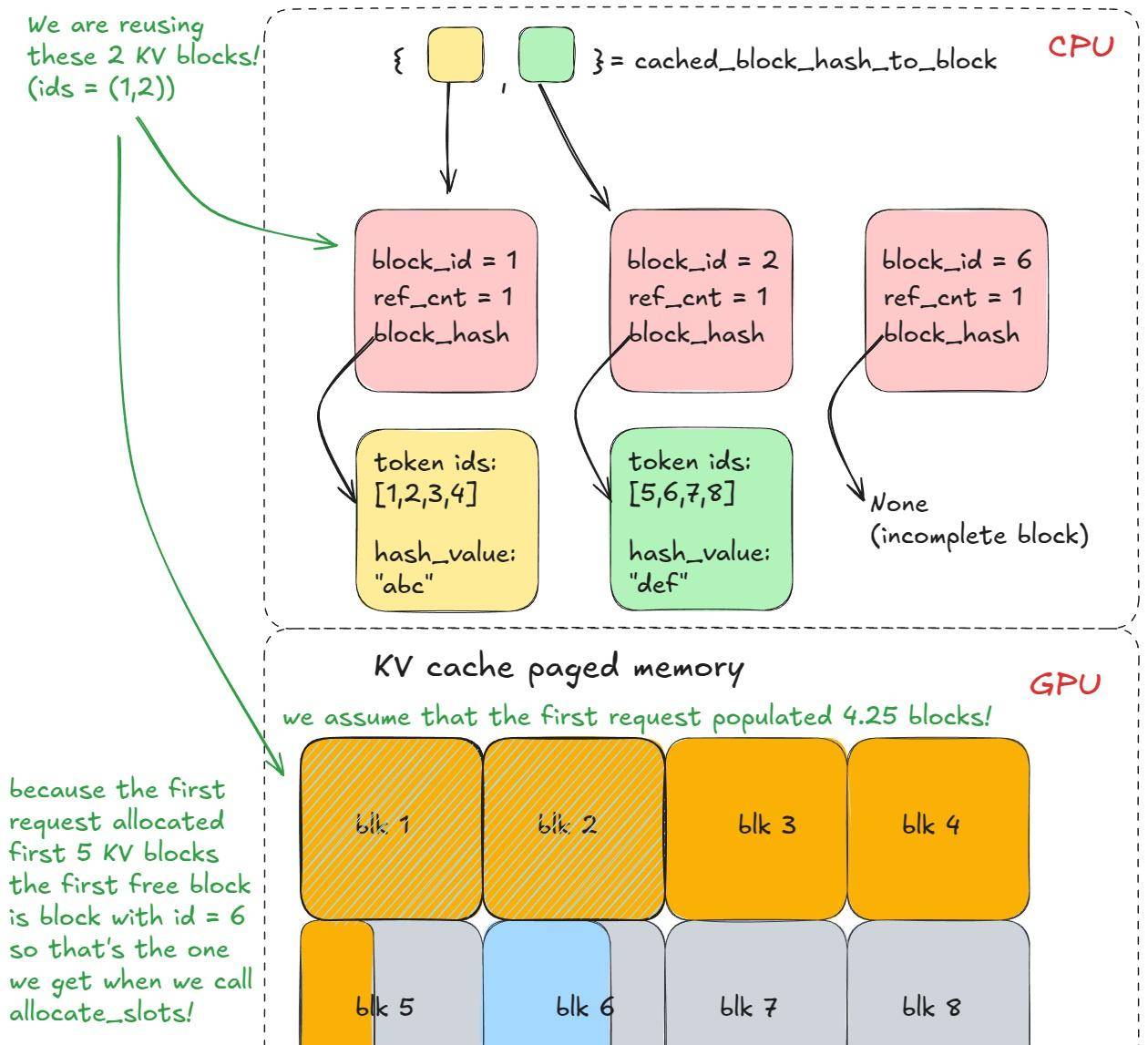 前缀缓存逻辑 – 第 3 部分
前缀缓存逻辑 – 第 3 部分
如果原始请求依旧存活,这些块的引用计数会增加(例如,增加到 2)。在这个例子中,第一个请求已经完成,所以这些块被释放回池中,它们的引用计数被重置为 0。由于我们能够从 中检索到它们,我们知道它们是有效的(KV 缓存管理器的逻辑就是这样设置的),所以我们只需再次将它们从
cached_block_hash_to_block free_block_queue 中移除。
高级笔记:
KV 缓存块只有在即将从 free_block_queue (从左侧弹出)中重新分配时才会失效,并且我们发现该块依旧有关联的哈希并且存在于 cached_block_hash_to_block 中。在那一刻,我们清除该块的哈希并从 cached_block_hash_to_block 中删除其条目,确保它不能通过前缀缓存被重用(至少对于那个旧前缀而言)。
这就是前缀缓存的核心思想: 不要重新计算你已经见过的前缀——只需重用它们的 KV 缓存!
如果你理解了这个例子,你也理解了 Paged Attention 的工作原理。
前缀缓存是默认启用的。要禁用它需要修改: enable_prefix_caching = False 。
引导式解码 (FSM)
引导式解码是一种技术,在每个解码步骤中,logits 会受到基于语法的有限状态机(finite state machine)的约束。这确保了只有语法允许的 Token 才能被采样。
这是一个强劲的设置:你可以强制执行从正则语法(乔姆斯基 3 型,例如任意正则表达式模式)到上下文无关语法(2 型,涵盖大多数编程语言)的任何东西。
为了让这个概念不那么抽象,让我们从最简单的例子开始,在我们之前的代码基础上构建:
from vllm import LLM, SamplingParams
from vllm.sampling_params import GuidedDecodingParams
prompts = [
"This sucks",
"The weather is beautiful",
]
guided_decoding_params = GuidedDecodingParams(choice=["Positive", "Negative"])
sampling_params = SamplingParams(guided_decoding=guided_decoding_params)
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()在我给出的这个玩具示例中(假设是字符级 Token 化):在预填充阶段,FSM 会屏蔽 logits,因此只有「P」或「N」是可行的。如果采样到「P」,FSM 会移动到「Positive」分支;下一步只允许「o」,依此类推。
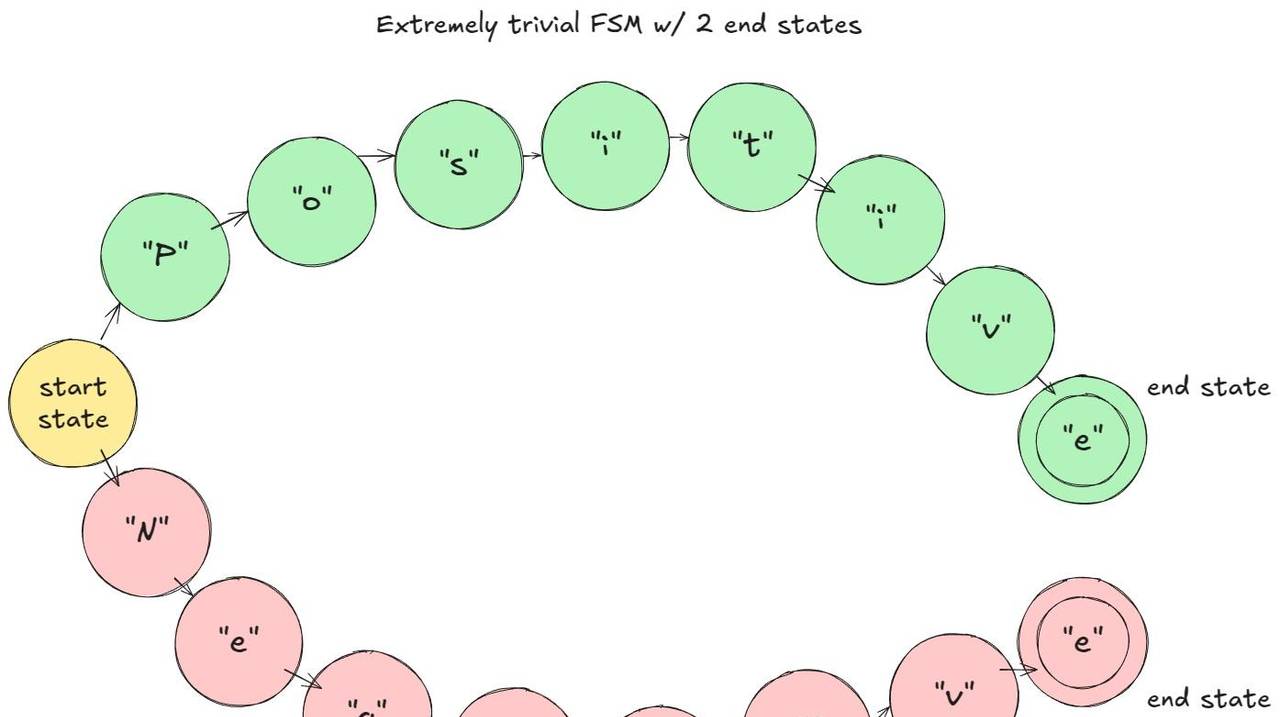 FSM
FSM
vLLM 中的工作原理:
- 在 LLM 引擎构建时,会创建一个
StructuredOutputManager;它可以访问 Tokenizer 并维护一个_grammar_bitmask张量。 - 当添加一个请求时,其状态被设置为
WAITING_FOR_FSM,grammar_init会选择后端编译器(例如,xgrammar;注意后端是第三方代码)。 - 该请求的语法被异步编译。
- 在调度期间,如果异步编译已完成,状态切换到
WAITING,并且request_id被添加到structured_output_request_ids;否则它被放入skipped_waiting_requests以在下一个引擎步骤重试。 - 在调度循环之后(仍在调度内部),如果有 FSM 请求,
StructuredOutputManager会要求后端准备/更新_grammar_bitmask。 - 在前向传播产生 logits 后,
xgr_torch_compile的函数会将位掩码扩展到词汇表大小(使用 32 位整数,因此扩展比为 32x),并将不允许的 logits 屏蔽为 –∞。 - 在采样下一个 Token 后,通过
accept_tokens推进请求的 FSM。在 FSM 图上,我们直观地移动到下一个状态。
步骤 6 值得进一步说明。
如果 vocab_size = 32 , _grammar_bitmask 是一个单一的整数;它的二进制表明编码了哪些 Token 是允许的(「1」)和不允许的(「0」)。例如,「101…001」会扩展为一个长度为 32 的数组 [1, 0, 1, …, 0, 0, 1] ;位置为 0 的 logits 会被设置为 –∞。对于更大的词汇表,会使用多个 32 位字并相应地进行扩展/连接。后端(例如, xgrammar )负责使用当前的 FSM 状态生成这些位模式。
注:这里的大部分复杂性都隐藏在像 xgrammar 这样的第三方库中。
这是一个更简单的例子,词汇表大小为 8,使用 8 位整数(为喜爱可视化的读者准备):
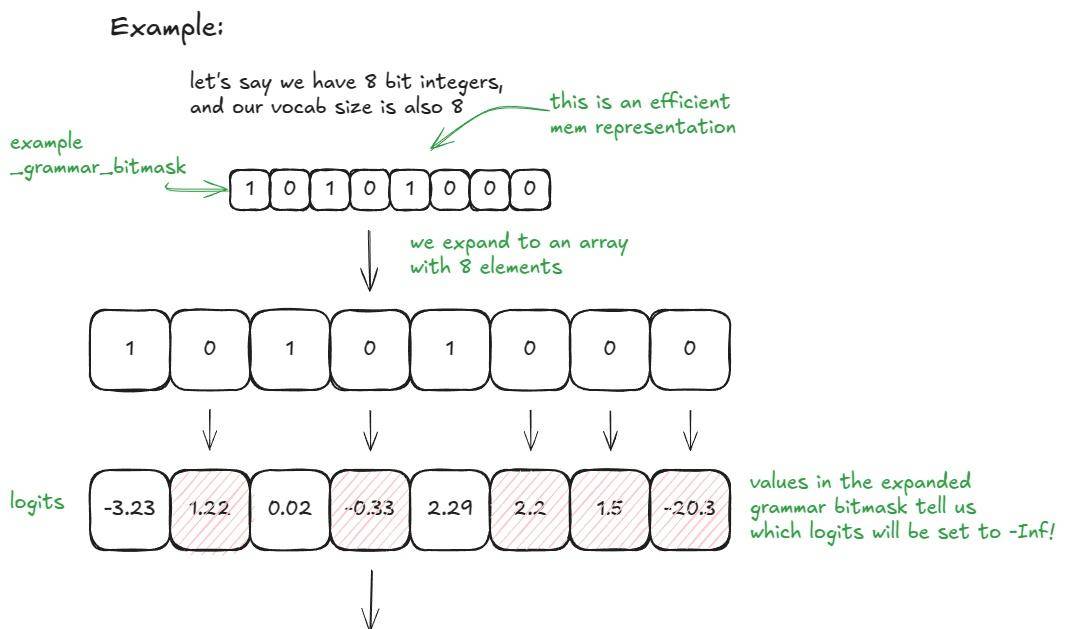 FSM
FSM
您可以通过传入所需的 guided_decoding 配置在 vLLM 中启用此功能。
推测解码
在自回归生成中,每个新 Token 都需要对大型语言模型(LM)进行一次前向传播。这代价高昂——每一步都要重新加载并应用所有模型权重,只为计算一个 Token!(假设批次大小为 1,一般情况下是 B )
推测解码通过引入一个较小的草稿 LM 来加速这一过程。草稿模型以较低成本地生成 k 个 Token。但我们最终并不想从较小的模型中采样——它只是用来猜测候选的后续内容。大型模型依旧决定什么是有效的。
以下是步骤:
- 草稿 :在当前上下文上运行小模型,并提出
k个 Token。 - 验证 :在上下文 +
k个草稿 Token 上运行一次大模型。这将为这k个位置以及额外一个位置生成概率(因此我们得到k+1个候选)。 - 接受/拒绝 :从左到右遍历
k个草稿 Token:
- 如果大模型对草稿 Token 的概率 ≥ 草稿模型的概率,则接受它。
- 否则,以
p_large(token)/p_draft(token)的概率接受它。 - 在第一次拒绝时停止,或者接受所有
k个草稿 Token。 - 如果所有
k个草稿 Token 都被接受,也从大模型中「免费」采样额外的第(k+1)个 Token(我们已经计算了那个分布)。 - 如果发生了拒绝,就在那个位置创建一个新的重新平衡的分布(
p_large - p_draft,最小值钳位在 0,归一化使总和为 1)并从中采样最后一个 Token。
原理 :虽然我们使用小模型来提出候选,但接受/拒绝规则保证了在期望上,序列的分布与我们从大模型逐个 Token 采样完全一样。这意味着推测解码在统计上等同于标准的自回归解码——但可能快得多,由于一次大模型的前向传播最多可以产生 k+1 个 Token。
注:我推荐查看 gpt-fast 以获取简单的实现,以及 原始论文 以了解数学细节和与从完整模型采样等价的证明。
vLLM V1 不支持 LLM 草稿模型方法,而是实现了更快但准确性较低的提议方案:n-gram、EAGLE 和 Medusa 。
对每种方法的一句话总结:
1、n-gram :取最后 prompt_lookup_max 个 Token;在序列中找到一个先前的匹配项;如果找到,则提议该匹配项之后的 k 个 Token;否则递减窗口并重试,直到 prompt_lookup_min 。
当前实现返回 第一个 匹配项之后的 k 个 Token。引入新近度偏见并反转搜索方向似乎更自然?(即最后一个匹配项)
2、Eagle :对大型 LM 进行「模型手术」——保留嵌入和 LM 头,用一个轻量级的 MLP 替换 Transformer 栈;将其微调作为一个廉价的草稿模型。
3、Medusa :在大型模型的顶部(LM 头之前的嵌入层)训练辅助线性头,以并行预测接下来的 k 个 Token;使用这些头来比运行一个单独的小型 LM 更高效地提议 Token。
以下是如何在 vLLM 中使用 ngram 作为草稿方法来调用推测解码:
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
speculative_config={
"method": "ngram",
"prompt_lookup_max": 5,
"prompt_lookup_min": 3,
"num_speculative_tokens": 3,
}
def main():
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", speculative_config=speculative_config)
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
main()这在 vLLM 中是如何工作的?
设置(在引擎构造期间):
- 初始化设备:创建一个
drafter(草稿模型,例如NgramProposer)和一个rejection_sampler(其部分是用 Triton 编写的)。 - 加载模型:加载草稿模型权重(对于 n-gram 是无操作)。
之后在 generate 函数中 (假设我们得到一个全新的请求):
- 用大模型运行常规的预填充步骤。
- 在前向传播和标准采样之后,调用
propose_draft_token_ids(k)从草稿模型中采样k个草稿 Token。 - 将这些存储在
request.spec_token_ids中(更新请求元数据)。 - 在下一个引擎步骤中,当请求在运行队列中时,将
len(request.spec_token_ids)添加到「新 Token」计数中,以便allocate_slots为前向传播保留足够的 KV 块。 - 将
spec_token_ids复制到input_batch.token_ids_cpu中,形成(上下文 + 草稿)Token。 - 通过
_calc_spec_decode_metadata计算元数据(这会从input_batch.token_ids_cpu复制 Token,准备 logits 等),然后对草稿 Token 运行一次大模型的前向传播。 - 不使用常规的从 logits 采样,而是使用
rejection_sampler从左到右进行接受/拒绝,并生成output_token_ids。 - 重复步骤 2-7,直到满足停止条件。
理解这一点的最佳方式是启动你的调试器并逐步执行代码库,但希望本节能让你对此有所了解。这张图也一样:
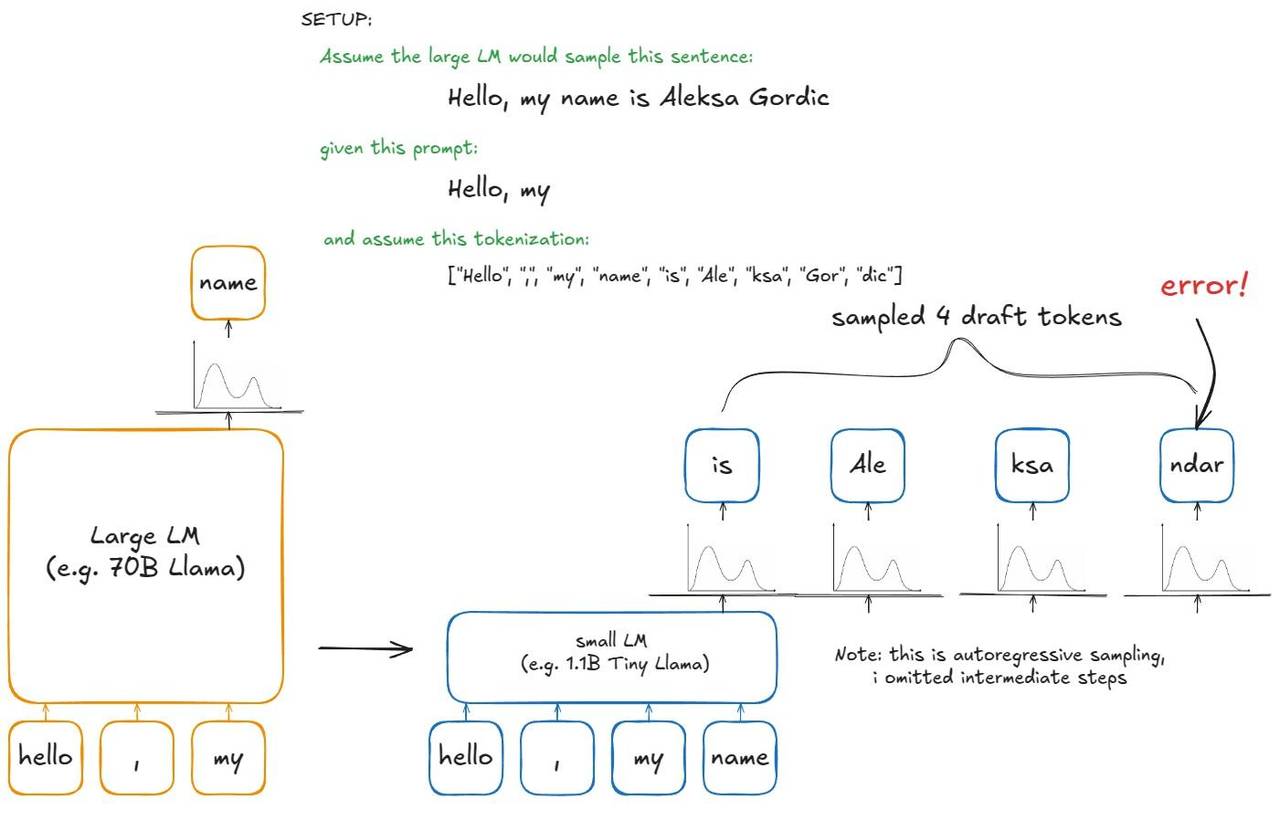 草稿阶段
草稿阶段 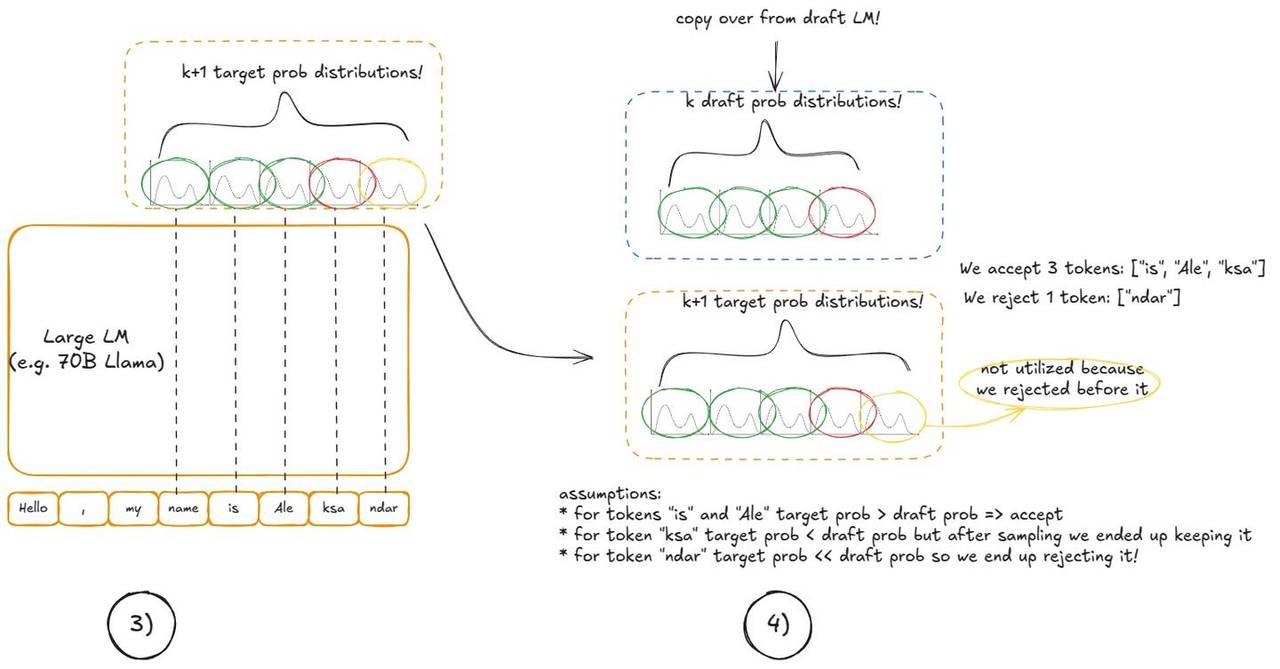 验证阶段与拒绝采样阶段
验证阶段与拒绝采样阶段
P/D 分离
我之前已经暗示了 P/D 分离(预填充/解码)背后的动机。
预填充和解码具有超级不同的性能特征(计算密集型 vs. 内存带宽密集型),因此将它们的执行分离开来是一种明智的设计。它能更严格地控制延迟——包括 TFTT (首 Token 时间)和 ITL (Token 间延迟)——更多内容将在 基准测试 部分讨论。
在实践中,我们运行 N 个 vLLM 预填充实例和 M 个 vLLM 解码实例,并根据实时请求组合对它们进行自动伸缩。预填充工作节点将 KV 写入专用的 KV 缓存服务;解码工作节点则从中读取。这将长的、突发性的预填充与稳定的、对延迟敏感的解码隔离开来。
这在 vLLM 中是如何工作的?
为清晰起见,下面的例子依赖于 SharedStorageConnector ,这是一个用于说明机制的调试连接器实现。
Connector 是 vLLM 用于处理实例间 KV 交换的抽象。Connector 接口尚不稳定,近期有一些改善计划,其中会涉及一些变更,部分可能是破坏性的。
我们启动 2 个 vLLM 实例(GPU 0 用于预填充,GPU 1 用于解码),然后在它们之间传输 KV 缓存:
import os
import time
from multiprocessing import Event, Process
import multiprocessing as mp
from vllm import LLM, SamplingParams
from vllm.config import KVTransferConfig
prompts = [
"Hello, my name is",
"The president of the United States is",
]
def run_prefill(prefill_done):
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
sampling_params = SamplingParams(temperature=0, top_p=0.95, max_tokens=1)
ktc=KVTransferConfig(
kv_connector="SharedStorageConnector",
kv_role="kv_both",
kv_connector_extra_config={"shared_storage_path": "local_storage"},
)
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", kv_transfer_config=ktc)
llm.generate(prompts, sampling_params)
prefill_done.set() # 通知解码实例 KV 缓存已准备好
# 保持预填充节点运行,以防解码节点未完成;
# 否则,脚本可能过早退出,导致解码不完整。
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
print("脚本被用户停止。")
def run_decode(prefill_done):
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
sampling_params = SamplingParams(temperature=0, top_p=0.95)
ktc=KVTransferConfig(
kv_connector="SharedStorageConnector",
kv_role="kv_both",
kv_connector_extra_config={"shared_storage_path": "local_storage"},
)
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", kv_transfer_config=ktc)
prefill_done.wait() # 阻塞等待来自预填充实例的 KV 缓存
# 内部它会先获取 KV 缓存,然后开始解码循环
outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__":
prefill_done = Event()
prefill_process = Process(target=run_prefill, args=(prefill_done,))
decode_process = Process(target=run_decode, args=(prefill_done,))
prefill_process.start()
decode_process.start()
decode_process.join()
prefill_process.terminate() 注:我也尝试过 LMCache ,它是最快的生产级连接器(后端使用 NVIDIA 的 NIXL),但它仍处于前沿技术阶段,我遇到了一些 bug。由于其大部分复杂性存在于一个外部仓库中, SharedStorageConnector 是一个更好的解释选择。
以下是 vLLM 中的步骤:
1、实例化 — 在引擎构建期间,连接器在两个地方被创建:
- 在 worker 的 init device 流程中(在 init worker distributed environment 函数下),角色为 “worker”。
- 在调度器构造函数中,角色为 “scheduler”。
2、缓存查找 — 当调度器处理来自 waiting 队列的预填充请求时(在本地前缀缓存检查之后),它会调用连接器的 。这会检查 KV 缓存服务器中是否有外部缓存的 Token。预填充在这里总是看到 0;解码可能会有缓存命中。在调用
get_num_new_matched_tokens allocate_slots 之前,结果会加到本地计数中。
3、状态更新 — 调度器然后调用 ,它记录了有缓存的请求(对预填充是无操作)。
connector.update_state_after_alloc
4、元数据构建 — 在调度结束时,调度器调用 meta = :
connector.build_connector_meta
- 预填充会添加所有
is_store=True的请求(用于上传 KV)。 - 解码会添加所有
is_store=False的请求(用于获取 KV)。
5、上下文管理器 — 在前向传播之前,引擎进入一个 KV 连接器上下文管理器:
- 进入时:调用
kv_connector.start_load_kv。对于解码,这会从外部服务器加载 KV 并将其注入到分页内存中。对于预填充,这是无操作。 - 退出时:调用
kv_connector.wait_for_save。对于预填充,这会阻塞直到 KV 上传到外部服务器。对于解码,这是无操作。
以下是可视化示例:
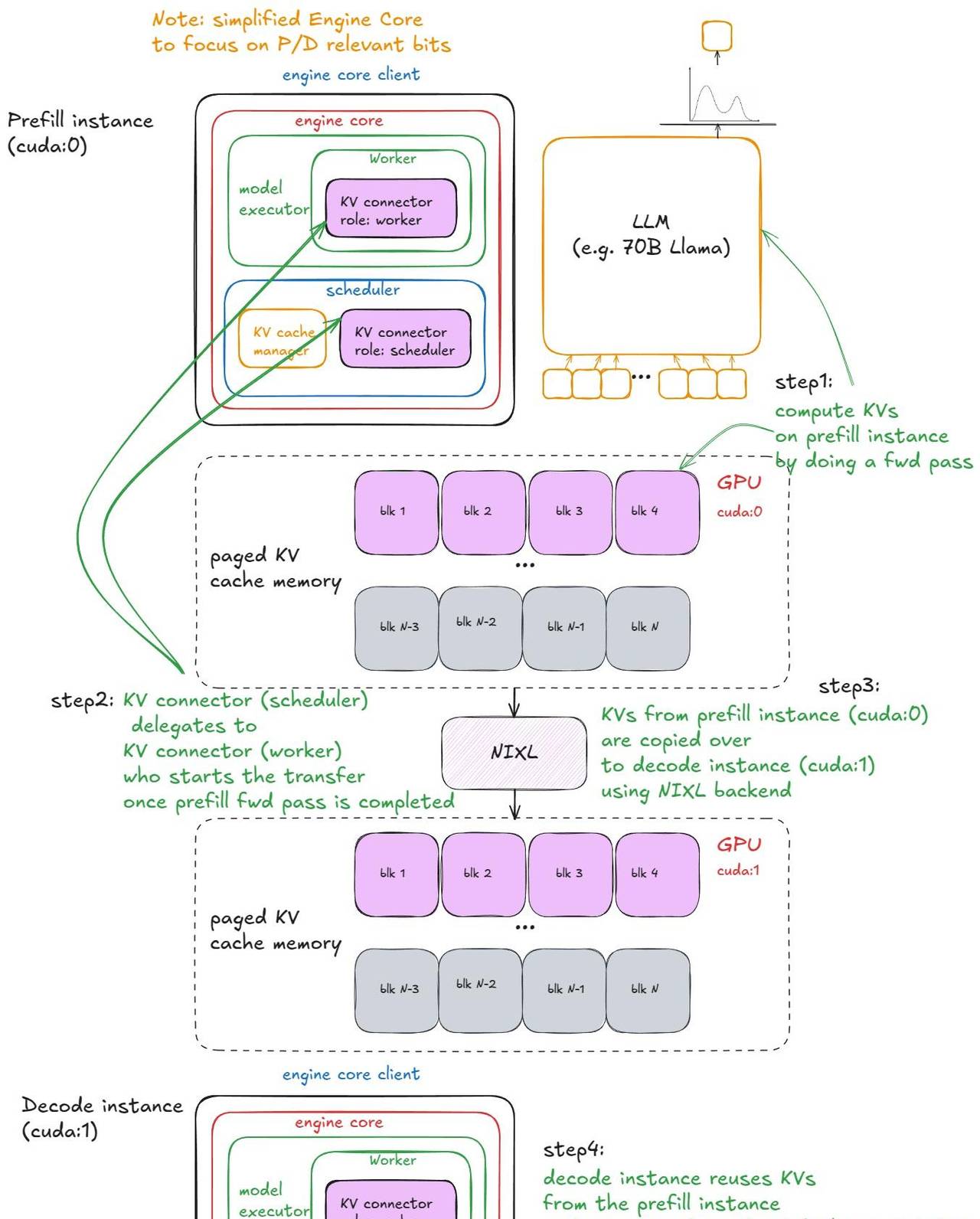 P/D 分离
P/D 分离
补充说明:
- 对于
SharedStorageConnector,「外部服务器」只是一个本地文件系统。 - 根据配置,KV 传输也可以逐层进行(在每个注意力层之前/之后)。
- 解码只在其请求的第一步加载一次外部 KV;之后它在本地计算/存储。
从 UniprocExecutor 到 MultiProcExecutor
有了核心技术的基础,我们目前可以讨论规模扩展了。
假设你的模型权重不再能装入单个 GPU 的 VRAM。
第一个选择是使用张量并行(tensor parallelism)(例如, TP=8 )将模型分片到同一节点上的多个 GPU。如果模型依旧装不下,下一步是跨节点进行流水线并行(pipeline parallelism)。
注:
- 节点内带宽远高于节点间带宽,这就是为什么张量并行(TP)一般优于流水线并行(PP)。(当然,PP 传输的数据量比 TP 少也是实际。)
- 这里没有涵盖专家并行(EP),由于我们关注的是标准 Transformer 而非 MoE,也没有涵盖序列并行,由于 TP 和 PP 在实践中最为常用。
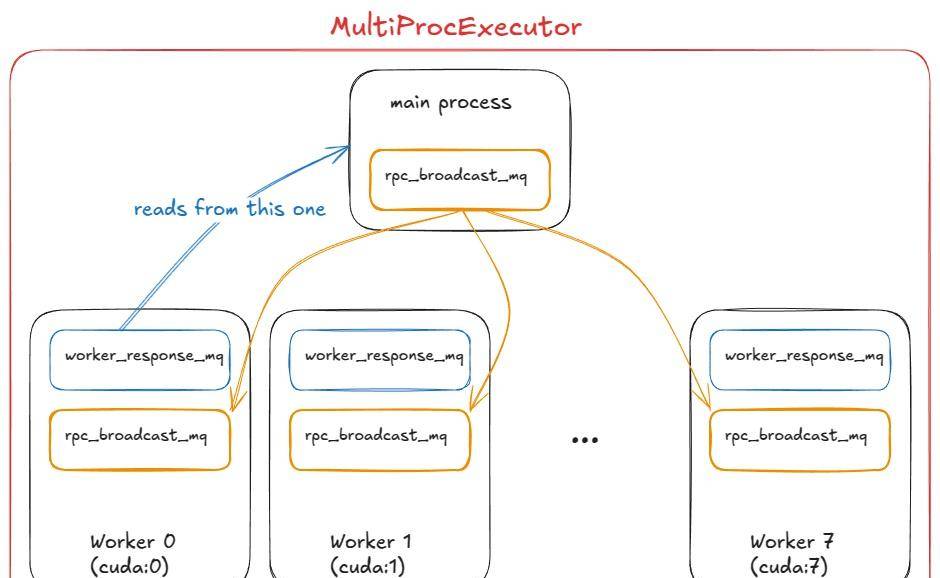
在这个阶段,我们需要多个 GPU 进程(worker)和一个协调层来协调它们。这正是 MultiProcExecutor 提供的功能。
 MultiProcExecutor
MultiProcExecutor
在 TP=8 设置中的 MultiProcExecutor(驱动 worker 为 rank 0)
这在 vLLM 中是如何工作的:
1、 MultiProcExecutor 初始化一个 rpc_broadcast_mq 消息队列(底层用共享内存实现)。
2、构造函数遍历 world_size (例如 TP=8 ⇒ world_size=8 ),并通过 为每个 rank 派生一个守护进程。
WorkerProc.make_worker_process
3、对于每个 worker,父进程第一创建一个读取器和写入器管道。
4、新进程运行 WorkerProc.worker_main ,它实例化一个 worker(经历与 UniprocExecutor 中一样的「初始化设备」、「加载模型」等过程)。
5、每个 worker 确定它是否是驱动者(TP 组中的 rank 0)或普通 worker。每个 worker 设置两个队列:
-
rpc_broadcast_mq(与父进程共享)用于接收工作。 -
worker_response_mq用于发回响应。
6、在初始化期间,每个子进程通过管道将其 worker_response_mq 句柄发送给父进程。一旦全部接收完毕,父进程解除阻塞——这完成了协调。
7、然后,worker 进入一个忙碌循环,阻塞在 rpc_broadcast_mq.dequeue 上。当工作项到达时,它们执行它(就像在 UniprocExecutor 中一样,但目前是 TP/PP 特定的分区工作)。结果通过 发回。
worker_response_mq.enqueue
8、在运行时,当一个请求到达时, MultiProcExecutor 将其入队到所有子 worker 的 rpc_broadcast_mq 中(非阻塞)。然后它在指定的输出 rank 的 上等待以收集最终结果。
worker_response_mq.dequeue
从引擎的角度来看,什么都没有改变——所有这些多进程的复杂性都通过调用模型执行器的 execute_model 被抽象掉了。
- 在
UniProcExecutor的情况下:execute_model直接导致在 worker 上调用execute_model。 - 在
MultiProcExecutor的情况下:execute_model间接通过rpc_broadcast_mq导致在每个 worker 上调用execute_model。
至此,我们可以使用一样的引擎接口运行资源允许的任意大小的模型。
下一步是横向扩展:启用数据并行( DP > 1 )在节点间复制模型,添加一个轻量级的 DP 协调层,引入副本间的负载均衡,并在前面放置一个或多个 API 服务器来处理传入流量。
vLLM 的分布式系统
建立服务基础设施有许多方法,但为了保持具体,这里有一个例子:假设我们有两个 H100 节点,并希望在它们上面运行四个 vLLM 引擎。
如果模型需要 TP=4 ,我们可以这样配置节点。
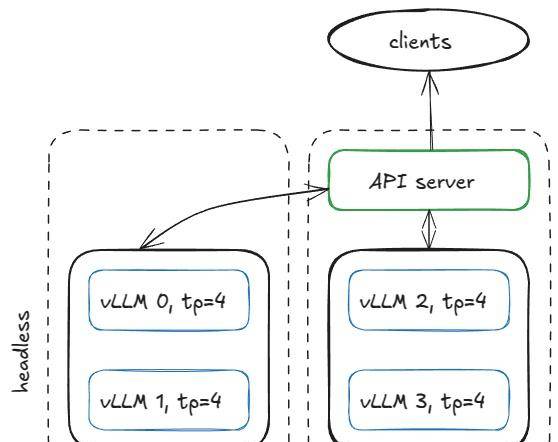 使用 2 个 8xH100 节点的服务器配置
使用 2 个 8xH100 节点的服务器配置
使用 2 个 8xH100 节点的服务器配置(1 个无头,1 个 API 服务器)
在第一个节点上,以无头模式(headless mode)(没有 API 服务器)运行引擎,并使用以下参数:
vllm serve <model-name>
--tensor-parallel-size 4
--data-parallel-size 4
--data-parallel-size-local 2
--data-parallel-start-rank 0
--data-parallel-address <master-ip>
--data-parallel-rpc-port 13345
--headless然后在另一个节点上运行一样的命令,但做一些调整:
- 没有
--headless - 修改 DP 起始 rank
vllm serve <model-name>
--tensor-parallel-size 4
--data-parallel-size 4
--data-parallel-size-local 2
--data-parallel-start-rank 2
--data-parallel-address <master-ip>
--data-parallel-rpc-port 13345注:这里假设网络已配置好,所有节点都可以访问指定的 IP 和端口。
VLLM 中如何实现这一机制?
在无头服务器节点上
在无头节点上,一个 CoreEngineProcManager 会启动 2 个进程(根据 ),每个进程运行
--data-parallel-size-local 。这些函数中的每一个都会创建一个
EngineCoreProc.run_engine_core DPEngineCoreProc (引擎核心),然后进入其忙碌循环。
DPEngineCoreProc 初始化其父类 EngineCoreProc ( EngineCore 的子类),它会:
- 创建一个
input_queue和output_queue(queue.Queue)。 - 使用一个
DEALERZMQ 套接字(异步消息库)与另一节点上的前端进行初始握手,并接收协调地址信息。 - 初始化 DP 组(例如,使用 NCCL 后端)。
- 用
MultiProcExecutor(如前所述,在 4 个 GPU 上TP=4)初始化EngineCore。 - 创建一个
ready_event(threading.Event)。 - 启动一个输入守护线程(
threading.Thread),运行process_input_sockets(…, ready_event)。类似地,启动一个输出线程。 - 仍在主线程中,等待
ready_event,直到跨越 2 个节点的所有 4 个进程中的所有输入线程都完成了协调握手,最终执行ready_event.set()。 - 一旦解除阻塞,就向前端发送一个「就绪」消息,并附带元数据(例如,分页 KV 缓存内存中可用的
num_gpu_blocks)。 - 然后,主线程、输入线程和输出线程进入各自的忙碌循环。
简而言之:我们最终得到 4 个子进程(每个 DP 副本一个),每个进程运行一个主线程、一个输入线程和一个输出线程。它们与 DP 协调器和前端完成协调握手,然后每个进程的三个线程都在稳态的忙碌循环中运行。
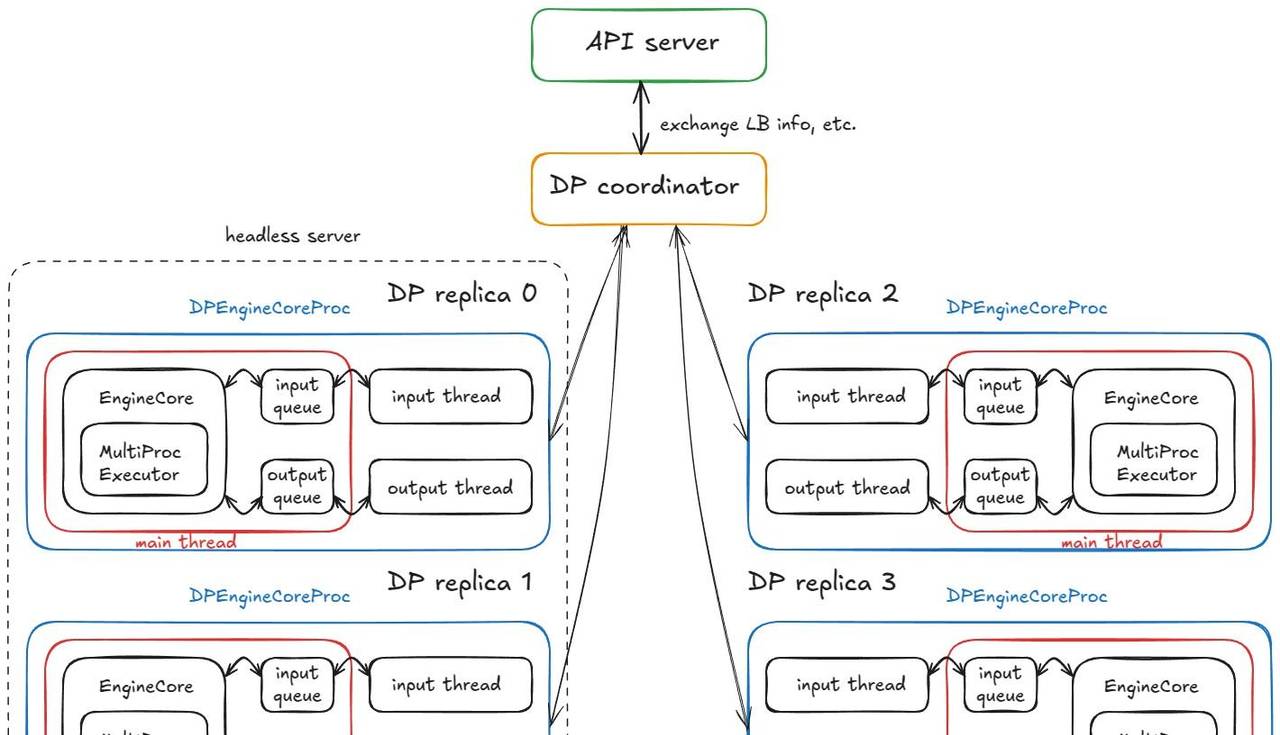 拥有 4 个 DPEngineCoreProc 的分布式系统
拥有 4 个 DPEngineCoreProc 的分布式系统
当前的稳定状态:
- 输入线程 — 阻塞在输入套接字上,直到一个请求从 API 服务器路由过来;收到后,它解码有效载荷,通过
input_queue.put_nowait(...)将一个工作项入队,然后返回到套接字的阻塞状态。 - 主线程 — 在
input_queue.get(...)上被唤醒,将请求送入引擎;MultiProcExecutor运行前向传播并将结果入队到output_queue。 - 输出线程 — 在
output_queue.get(...)上被唤醒,将结果发回 API 服务器,然后恢复阻塞。
其他机制:
- DP 波次计数器 — 系统跟踪「波次」;当所有引擎都变为空闲时,它们会静默,当新工作到达时计数器会递增(对协调/指标有用)。
- 控制消息 — API 服务器可以发送的不仅仅是推理请求(例如,中止和实用程序/控制 RPC)。
- 用于同步的虚拟步骤 — 如果任何 DP 副本有工作,所有副本都会执行一个前向步骤;没有请求的副本会执行一个虚拟步骤以参与所需的同步点(避免阻塞活动副本)。
同步说明:这实际上只对 MoE 模型是必需的,其中专家层形成一个 EP 或 TP 组,而注意力层依旧是 DP。目前它总是与 DP 一起完成——这只是由于「内置」的非 MoE DP 用途有限,由于你可以只运行多个独立的 vLLM,并以正常方式在它们之间进行负载均衡。
目前来到第二部分,API 服务器节点上发生了什么?
在 API 服务器节点上
我们实例化一个 AsyncLLM 对象(LLM 引擎的 asyncio 包装器)。在内部,这会创建一个 DPLBAsyncMPClient (数据并行、负载均衡、异步、多进程客户端)。
在 MPClient 的父类中, launch_core_engines 函数运行并:
- 创建用于启动握手的 ZMQ 地址(如在无头节点上看到的那样)。
- 派生一个
DPCoordinator进程。 - 创建一个
CoreEngineProcManager(与无头节点上一样)。
在 AsyncMPClient ( MPClient 的子类)中,我们:
- 创建一个
outputs_queue(asyncio.Queue)。 - 我们创建一个 asyncio 任务
process_outputs_socket,它(通过输出套接字)与所有 4 个DPEngineCoreProc的输出线程通信,并写入outputs_queue。 - 随后,来自
AsyncLLM的另一个 asyncio 任务output_handler从这个队列中读取,并最终将信息发送给create_completion函数。
在 DPAsyncMPClient 中,我们创建一个 asyncio 任务 ,它与 DP 协调器通信。
run_engine_stats_update_task
DP 协调器在前端(API 服务器)和后端(引擎核心)之间进行协调。它:
- 定期向前端的
run_engine_stats_update_task发送负载均衡信息(队列大小、等待/运行中的请求)。 - 通过动态更改引擎数量来处理来自前端的
SCALE_ELASTIC_EP命令(仅适用于 Ray 后端)。 - 向后端发送
START_DP_WAVE事件(当由前端触发时)并报告波次状态更新。
总结一下,前端 ( AsyncLLM ) 运行几个 asyncio 任务(记住:是并发,不是并行):
- 一类任务通过
generate路径处理输入请求(每个新的客户端请求都会派生一个新的 asyncio 任务)。 - 两个任务 (
process_outputs_socket,output_handler) 处理来自底层引擎的输出消息。 - 一个任务 (
run_engine_stats_update_task) 维护与 DP 协调器的通信:发送波次触发器、轮询负载均衡状态以及处理动态伸缩请求。
最后,主服务器进程创建一个 FastAPI 应用并挂载诸如 OpenAIServingCompletion 和 OpenAIServingChat 等端点,这些端点暴露了 /completion 、 /chat/completion 等。然后,这个堆栈通过 Uvicorn 提供服务。
综上所述,这就是完整的请求生命周期!
从终端发送:
curl -X POST http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"prompt": "The capital of France is",
"max_tokens": 50,
"temperature": 0.7
}'接下来会发生什么:
- 请求命中 API 服务器上
OpenAIServingCompletion的create_completion路由。 - 该函数异步地对提示词进行 Token 化,并准备元数据(请求 ID、采样参数、时间戳等)。
- 然后它调用
AsyncLLM.generate,其流程与同步引擎一样,最终调用DPAsyncMPClient.add_request_async。 - 这反过来又调用
get_core_engine_for_request,它根据 DP 协调器的状态在引擎间进行负载均衡(选择得分最低/负载最低的那个:score = len(waiting) * 4 + len(running))。 -
ADD请求被发送到所选引擎的input_socket。 - 在该引擎处:
- 输入线程 — 解除阻塞,从输入套接字解码数据,并将一个工作项放入主线程的
input_queue中。 - 主线程 — 在
input_queue上解除阻塞,将请求添加到引擎,并重复调用engine_core.step(),将中间结果入队到output_queue,直到满足停止条件。
提醒: step() 调用调度器、模型执行器(它本身可以是 MultiProcExecutor !)等。我们已经见过这个了!
- 输出线程 — 在
output_queue上解除阻塞,并通过输出套接字发回结果。 - 这些结果触发
AsyncLLM的输出 asyncio 任务(process_outputs_socket和output_handler),这些任务将 Token 传播回 FastAPI 的create_completion路由。 - FastAPI 附加元数据(完成缘由、logprobs、使用信息等)并通过 Uvicorn 向你的终端返回一个
JSONResponse!
就这样,你的补全回来了——整个分布式机器的运作都隐藏在一个简单的 curl 命令背后!
补充说明:
- 当添加更多 API 服务器时,负载均衡在操作系统/套接字级别处理。从应用程序的角度来看,没有什么重大变化——复杂性被隐藏了。
- 使用 Ray 作为 DP 后端,你可以暴露一个 URL 端点 (
/scale_elastic_ep),它能实现引擎副本数量的自动伸缩。
基准测试与自动调优 – 延迟 vs 吞吐量
到目前为止,我们一直在分析「气体粒子」——请求如何在引擎/系统中流动的内部机制。目前是时候放大视角,将系统视为一个整体,并提问:我们如何衡量一个推理系统的性能?
在最高层次上,有两个相互竞争的指标:
- 延迟(Latency) — 从提交请求到返回 Token 的时间
- 吞吐量(Throughput) — 系统每秒可以生成/处理的 Token/请求数
延迟 对于用户等待响应的交互式应用最为重大。
吞吐量 在离线工作负载中很重大,如为预/后训练运行生成合成数据、数据清洗/处理,以及一般而言——任何类型的离线批量推理作业。
在解释为什么延迟和吞吐量相互竞争之前,让我们定义几个常见的推理指标:
| 指标 | 定义 |
|---|---|
| TTFT (首 Token 时间) | 从提交请求到接收到第一个输出 Token 的时间 |
| ITL (Token 间延迟) | 两个连续 Token 之间的时间(例如,从 Token i-1 到 Token i) |
| TPOT (每输出 Token 时间) | 一个请求中所有输出 Token 的平均 ITL |
| Latency / E2E (端到端延迟) | 处理一个请求的总时间,即 TTFT + 所有 ITL 的总和,或者等效地,提交请求和接收到最后一个输出 Token 之间的时间 |
| Throughput (吞吐量) | 每秒处理的总 Token 数(输入、输出或两者),或者每秒请求数 |
| Goodput | 满足服务水平目标 (SLO) 的吞吐量,例如最大 TTFT、TPOT 或端到端延迟。例如,只计算满足这些 SLO 的请求的 Token |
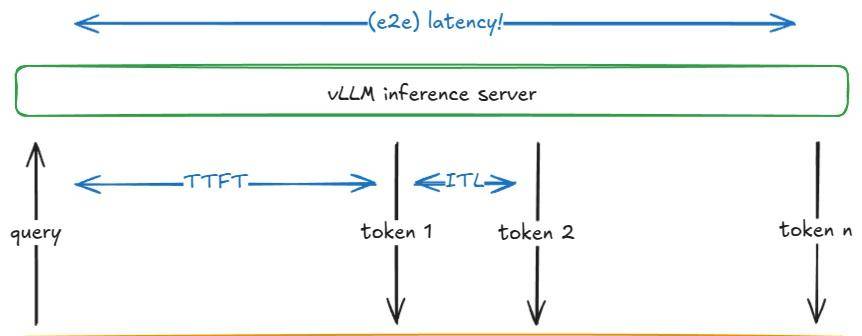 ttft, itl, e2e latency
ttft, itl, e2e latency
这里有一个简化的模型,解释了这两个指标的竞争性质。
假设:权重 I/O 而非 KV 缓存 I/O 占主导地位;也就是说,我们处理的是短序列。
当我们看批次大小 B 如何影响单个解码步骤时,这种权衡变得清晰。当 B ↓ 趋向 1 时,ITL 下降:每一步的工作量更少,Token 不会与其他 Token「竞争」。当 B ↑ 趋向无穷大时,ITL 上升,由于我们每一步做更多的 FLOPs——但吞吐量提高(直到我们达到峰值性能),由于权重 I/O 的成本被分摊到更多的 Token 上。
Roofline 模型有助于理解这一点:在饱和批次 B_sat 以下,步骤时间由 HBM 带宽主导(将权重逐层流式传输到片上内存),所以步骤延迟几乎是平的——计算 1 个 Token 和 10 个 Token 可能花费类似的时间。超过 B_sat ,核函数变为计算密集型,步骤时间大致随 B 增长;每个额外的 Token 都会增加 ITL。
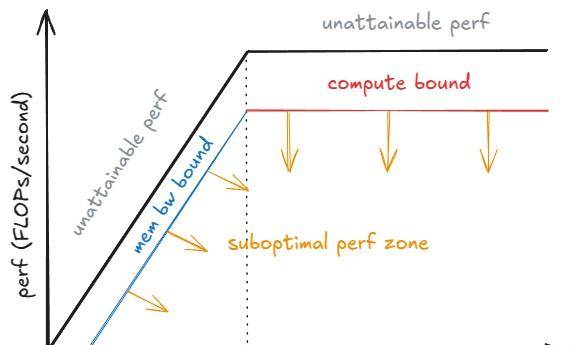 roofline 性能模型 注:为了更严谨的处理,我们必须思考核函数自动调优:随着
roofline 性能模型 注:为了更严谨的处理,我们必须思考核函数自动调优:随着 B 的增长,运行时可能会切换到对该形状更高效的核函数,从而改变实现的性能 P_kernel 。步骤延迟是 t = FLOPs_step / P_kernel ,其中 FLOPs_step 是该步骤的工作量。你可以看到,当 P_kernel 达到 P_peak 时,每一步更多的计算将直接导致延迟增加。
如何在 vLLM 中进行基准测试
vLLM 提供了一个 vllm bench {serve,latency,throughput} CLI 工具,它封装了 vllm/benchmarks/{server,latency,throughput}.py 。
以下是这些脚本的作用:
- latency — 使用短输入(默认 32 个 Token)并用小批量(默认 8)采样 128 个输出 Token。它运行几次迭代并报告该批次的端到端延迟。
- throughput — 一次性提交一组固定的提示词(默认:1000 个 ShareGPT 样本)(即
QPS=Inf模式),并报告整个运行过程中的输入/输出/总 Token 数和每秒请求数。 - serve — 启动一个 vLLM 服务器,并通过从泊松(或更一般的,Gamma)分布中采样请求到达间隔时间来模拟真实世界的工作负载。它在一个时间窗口内发送请求,测量我们讨论过的所有指标,并且可以选择性地强制执行服务器端的最大并发数(通过信号量,例如限制服务器为 64 个并发请求)。
这是一个如何运行延迟脚本的例子:
vllm bench latency
--model <model-name>
--input-tokens 32
--output-tokens 128
--batch-size 8
}' CI 中使用的基准测试配置位于 .buildkite/nightly-benchmarks/tests 下。
还有一个自动调优脚本,它驱动服务基准测试以找到满足目标 SLO 的参数设置(例如,「最大化吞吐量,同时保持 p99 端到端延迟 < 500 毫秒」),并返回提议的配置。
后记
我们从基本的引擎核心 ( UniprocExecutor ) 开始,添加了像推测解码和前缀缓存这样的高级功能,扩展到 MultiProcExecutor ( TP/PP > 1 ),最后横向扩展,将所有东西都包装在异步引擎和分布式服务堆栈中——最后以如何衡量系统性能收尾。
vLLM 还包括一些没有提及的处理机制。例如:
- 自定义硬件后端 :TPU、AWS Neuron (Trainium/Inferentia) 等。
- 架构/技术 :
MLA、MoE、编码器-解码器(例如 Whisper)、池化/嵌入模型、EPLB、m-RoPE、LoRA、ALiBi、无注意力变体、滑动窗口注意力、多模态 LM 和状态空间模型(例如 Mamba/Mamba-2, Jamba) - TP/PP/SP
- 混合 KV 缓存逻辑 (Jenga),更复杂的采样方法如束搜索 (beam sampling) 等
- 实验性 :异步调度
好处是,这些大部分都与上面描述的主流程正交——你几乎可以把它们当作「插件」(当然,在实践中存在一些耦合)。
我热爱理解系统。话虽如此,在这个高度上的分辨率肯定有所下降。在之后的文章中,我将放大到特定的子系统,并深入探讨其中的细节。



















暂无评论内容