
没想到内燃机的风还是吹到了机器人。
十年的数据鸿沟,缩短至一个月,前几天的模仿学习三天,如今24小时?1000项任务。
science.org/journal/scirobotics
抱抱脸的Co-Founder 汤姆斯评论其项目内容~
这个项目的全名是 Learning a Thousand Tasks in a Day
一天内学习一千个任务,真简单粗暴,信息量大!
robot-learning.uk/learning-1000-tasks
论文全称一样,有兴趣的小伙伴可以去看看~
DOI: 10.1126/scirobotics.adv7594
论文全文内容与项目网站上po的大体一致,可以先瞅网站(即前文项目地址)。
论文的摘要主要说多任务轨迹迁移MT3框架,将机器人的学习与模仿任务变得简单,还可以泛化到未见过的实例,从而实现24小时内让机器人学会1000个不同的日常任务。
详细的看下文。
摘要:人类通过演示样本学习任务的效率极高,但如今用于机器人操作的模仿学习方法,每个任务通常需要数百或数千个演示样本。本研究探究了两种提升学习效率的核心先验知识:将操作轨迹分解为连续的对齐阶段与交互阶段,以及基于检索的泛化机制。通过 3450 次真实世界滚动实验,我们系统研究了这种分解方法。我们对比了对齐阶段和交互阶段的不同设计选择,并考察了其相对于当前主流的单阶段整体策略行为克隆范式的泛化性能与缩放趋势。在每个任务仅含少量演示样本(少于 10 个)的场景下,分解方法的 data efficiency 较单阶段学习提升了一个数量级,且在对齐阶段和交互阶段中,检索机制均持续优于行为克隆。基于这些发现,我们提出了多任务轨迹迁移(MT3)方法:一种基于分解与检索的模仿学习框架。MT3 仅需每个日常操作任务提供单个演示样本即可完成学习,同时还能泛化到此前未见过的物体实例。这种高效性使我们能在不到 24 小时的人类演示者时间内,教会机器人 1000 个不同的日常任务。通过额外 2200 次真实世界滚动实验,我们揭示了 MT3 在不同任务类别中的性能表现与局限性。
从演示结果视频来看,且不论做的活细不细,这个思路真的挺不错。

全是我们日常干的活,懒人福音呐~
MT3有点东西,和我们常用的思路不太一样。
日常我们主要是模仿学习,即行为克隆,先演示训练,再基于训练的神经网络预测动作。
MT3属于是检索算法,在训练阶段不需要机器人数据,在自主检索,使其可以自选最优演示样本,相比以往的思路,效率高一些。
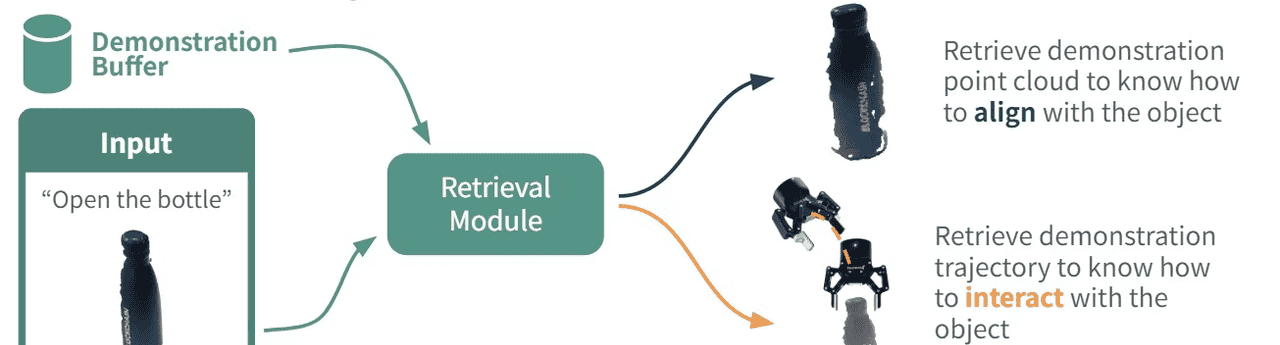
MT3思路框架
对齐交互与执行交互,效率有明显的提升。

对齐与交互策略双管齐下,比单一的效果要好。
可以看到整体实操过程还是比较流畅。

案例不止图片这么点,建议去项目网站上观摩GIF
设计的策略效果咋样,做5组对比参照,
BC-BC:对齐阶段采用行为克隆,交互阶段采用行为克隆;BC-Ret:对齐阶段采用行为克隆,交互阶段采用基于检索的方法;Ret-BC:对齐阶段采用基于检索的方法,交互阶段采用行为克隆;Ret-Ret(MT3):对齐阶段采用基于检索的方法,交互阶段采用基于检索的方法;MT-ACT+:在整个轨迹上训练的行为克隆策略。
通过在 70 种不同物体上进行的 3450 次真实世界实验(循环),实验结果明确表明,将操作轨迹分解为对齐阶段和交互阶段,其性能优于使用单一整体策略学习轨迹。与使用行为克隆替代方案相比,采用基于检索的方法进行物体对齐和交互,能实现更高效的学习。
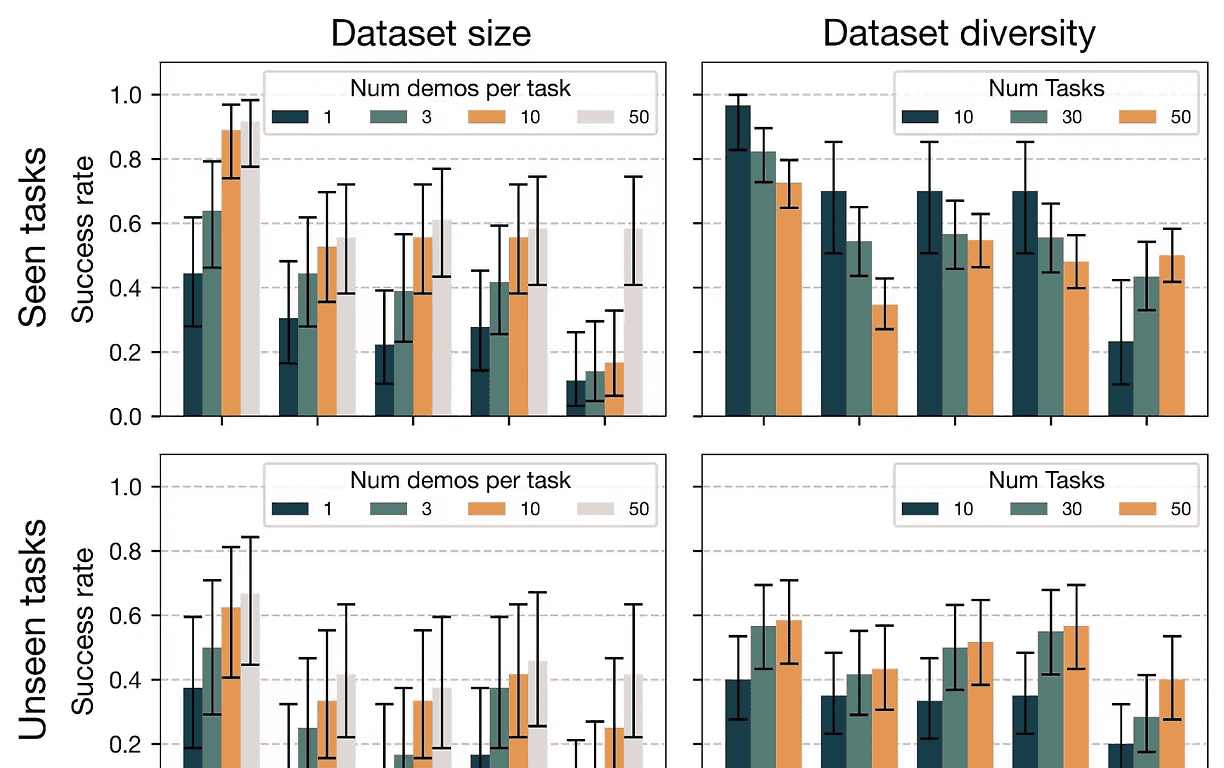
与其它策略相比,MT3有着还不错的表现

部分对照成果图
但凡是训练就不可能没有失败,团队po出了MT3失败模式的差异情况,问题主要是姿态估计误差和正确轨迹检索失误。

MT3失败举例
总的来说,不要高估任何一个新算法的能力,也不要低估任何一个新算法的潜力。
作为思路启发,还是挺耳目一新。
感觉接下来还能再压缩训练时间,
我有点期待1小时就训练好的算法是个什么路子:)



















暂无评论内容