
目录
为什么要写这篇文章
前提说明
F5-TTS
环境安装
Create env
Install pytorch
2选1
安装ffmpeg
推理
总结
为什么要写这篇文章
因为要制作视频,就想要根据文本,生成不同音色的声音,发现很多都是收费的。
因此,找到了这款工具。经过博主在电脑上捣鼓【网速如果好,可能会更快一些】,终于跑通了。把踩过的坑和使用方法记录了下来,大家有需要的,自行照做,就可以得到任何自己想要的文本声音。
前提说明
硬件:有一台电脑【笔记本也行】,需要有显卡
软件:安装了python和conda环境【这个步骤比较简单,不懂可以评论或者私信】
F5-TTS
我们使用的技术是:F5-TTS。它的全称是 “Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching”,翻译成中文是“流匹配下的流畅忠实语音仿真专家”。据介绍,搭载 ConvNeXt V2 的扩散变换器,训练和推理速度更快。
环境安装
Create env
# Create a python 3.10 conda env (you could also use virtualenv)
conda create -n f5-tts python=3.10
conda activate f5-tts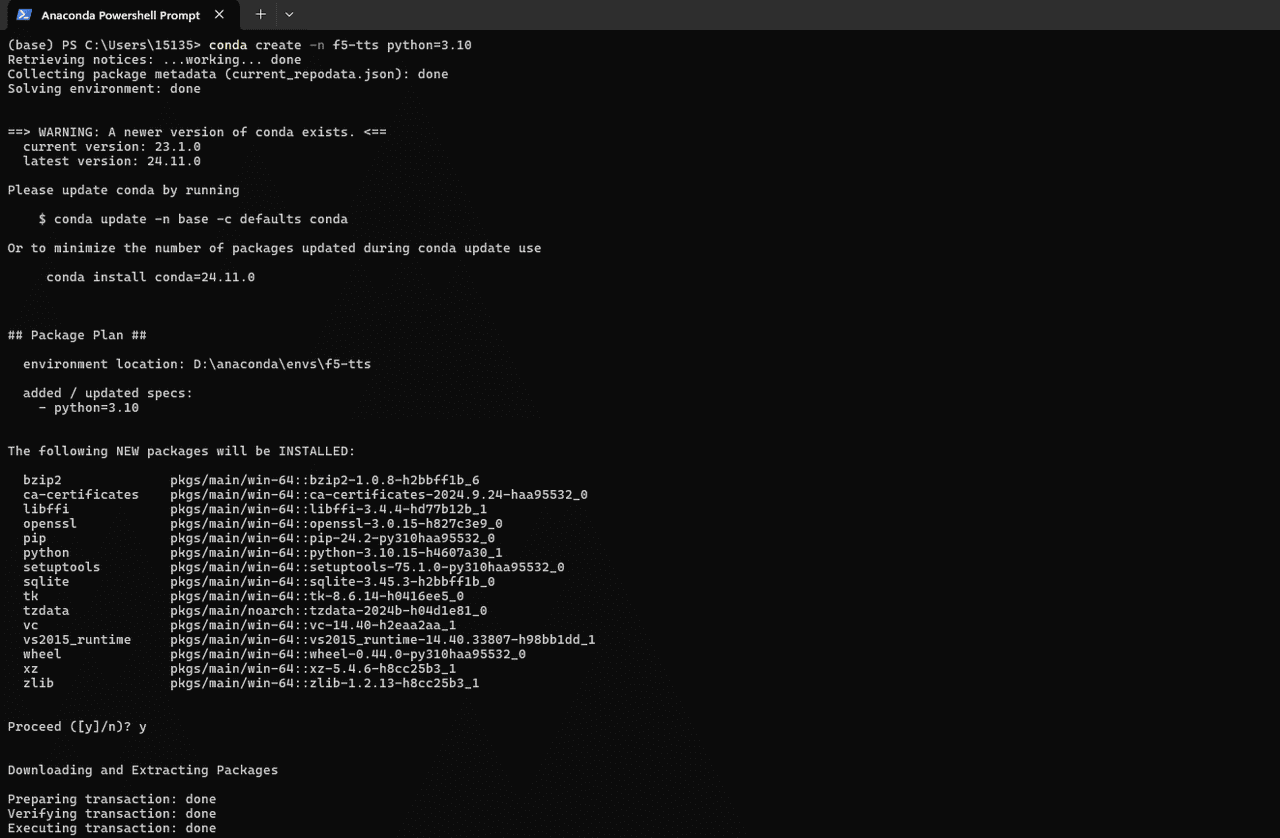
Install pytorch
# Install pytorch with your CUDA version, e.g.
pip install torch==2.3.0+cu118 torchaudio==2.3.0+cu118 --extra-index-url https://download.pytorch.org/whl/cu118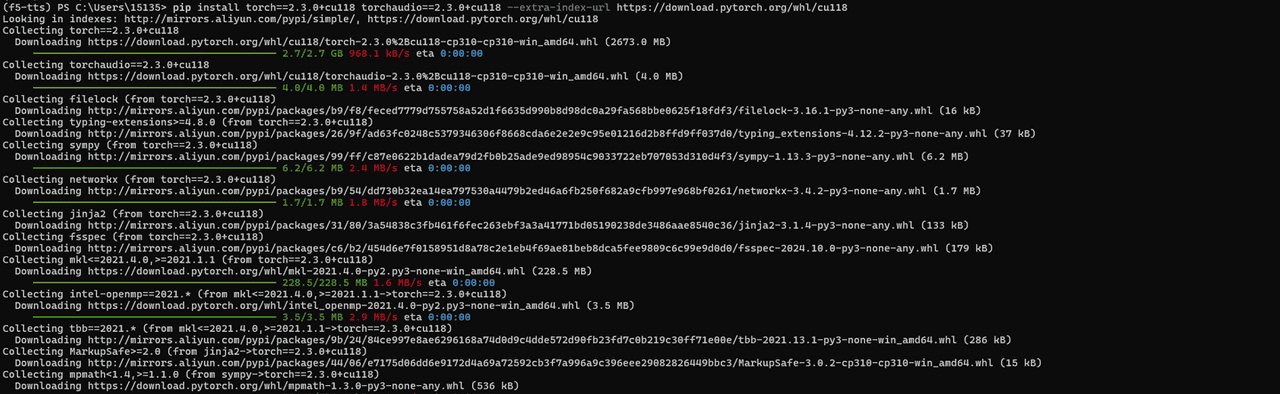
2选1
作为 pip 包(如果仅用于推理)
pip install git+https://github.com/SWivid/F5-TTS.git本地可编辑(如果也进行训练,微调)
git clone https://github.com/SWivid/F5-TTS.git
cd F5-TTS
# git submodule update --init --recursive # (optional, if need bigvgan)
pip install -e .
# If initialize submodule, you should add the following code at the beginning of src/third_party/BigVGAN/bigvgan.py.
import os
import sys
sys.path.append(os.path.dirname(os.path.abspath(__file__)))本次,我选择仅仅推理,下次有需要我们再讨论微调。
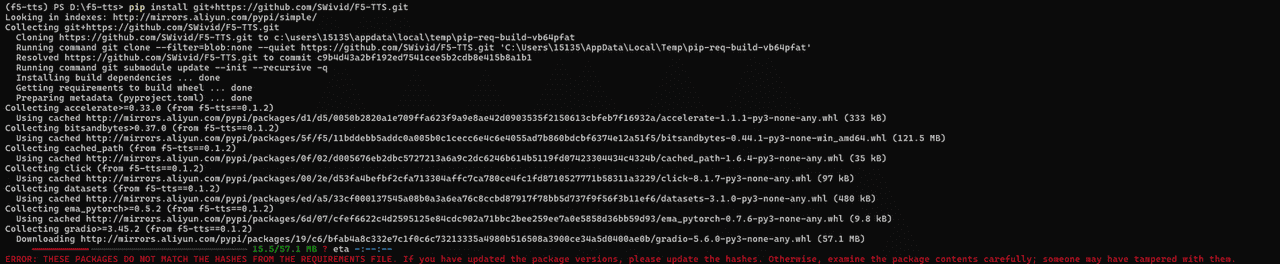
报错1:
ERROR: THESE PACKAGES DO NOT MATCH THE HASHES FROM THE REQUIREMENTS FILE. If you have updated the package versions, please update the hashes. Otherwise, examine the package contents carefully; someone may have tampered with them.
gradio>=3.45.2 from http://mirrors.aliyun.com/pypi/packages/19/c6/bfab4a8c332e7c1f0c6c73213335a4980b516508a3900ce34a5d0400ae0b/gradio-5.6.0-py3-none-any.whl#sha256=6eba135b32fb2fcb5d83fa845f6ad57c033894d5218fd3010de8fb4d735b9b6d (from f5-tts==0.1.2):
Expected sha256 6eba135b32fb2fcb5d83fa845f6ad57c033894d5218fd3010de8fb4d735b9b6d
Got bb4001742e028c50aa30f9a978492a58665b4db28e6a009783b3e47a0fba1092解决方案:
pip install gradio --index-url https://pypi.org/simple/然后继续pip install git+https://github.com/SWivid/F5-TTS.git下载。
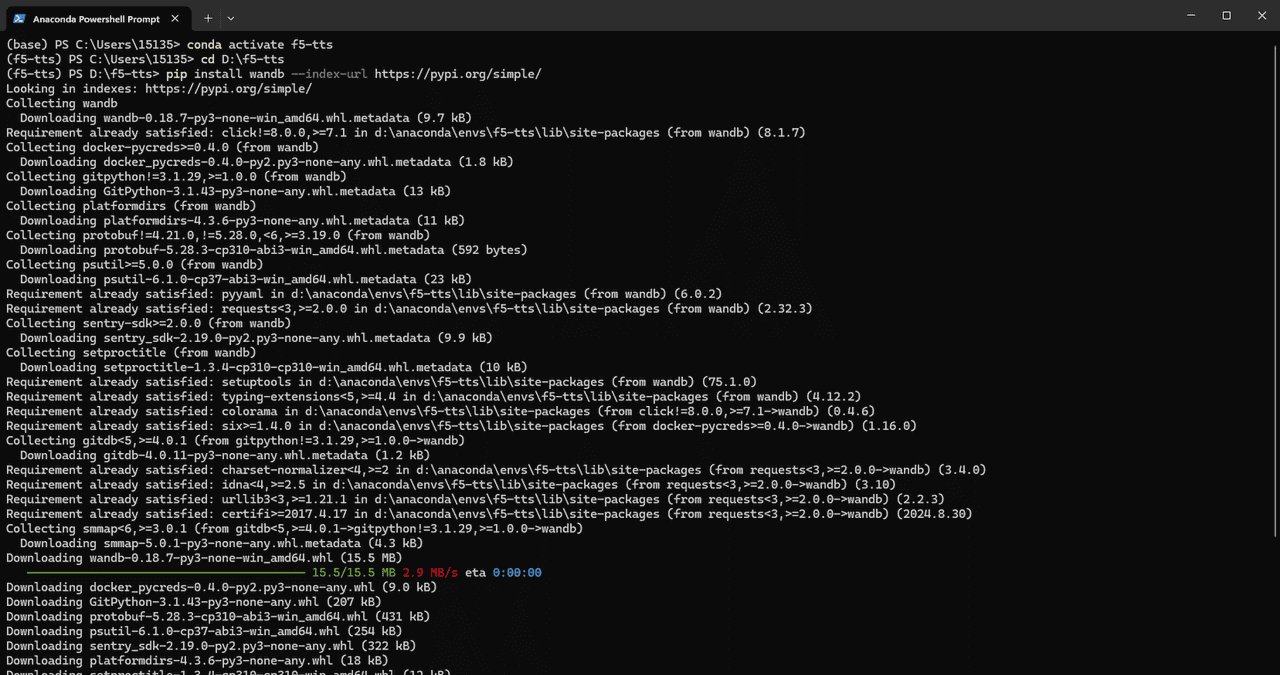
报错2【卡住】:
Collecting wandb (from f5-tts==0.1.2)
Downloading http://mirrors.aliyun.com/pypi/packages/1f/d3/1996ef42e58a049d6b2d6c3e3f0c8d7d38a286f707c515672a928fd9eb6c/wandb-0.18.7-py3-none-win_amd64.whl (15.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━ 13.9/15.5 MB 3.2 MB/s eta 0:00:01解决方案:
然后继续pip install git+https://github.com/SWivid/F5-TTS.git下载。
报错3:
Collecting multiprocess<0.70.17 (from datasets->f5-tts==0.1.2)
Downloading http://mirrors.aliyun.com/pypi/packages/bc/f7/7ec7fddc92e50714ea3745631f79bd9c96424cb2702632521028e57d3a36/multiprocess-0.70.16-py310-none-any.whl (134 kB)
ERROR: THESE PACKAGES DO NOT MATCH THE HASHES FROM THE REQUIREMENTS FILE. If you have updated the package versions, please update the hashes. Otherwise, examine the package contents carefully; someone may have tampered with them.
multiprocess<0.70.17 from http://mirrors.aliyun.com/pypi/packages/bc/f7/7ec7fddc92e50714ea3745631f79bd9c96424cb2702632521028e57d3a36/multiprocess-0.70.16-py310-none-any.whl#sha256=c4a9944c67bd49f823687463660a2d6daae94c289adff97e0f9d696ba6371d02 (from datasets->f5-tts==0.1.2):
Expected sha256 c4a9944c67bd49f823687463660a2d6daae94c289adff97e0f9d696ba6371d02
Got 33d22ae8e7044e62406ebbb2eb4df4da0435324d1ad8fd580a7d8dc967f8c20d解决方案:
pip install multiprocess==0.70.16 –index-url https://pypi.org/simple
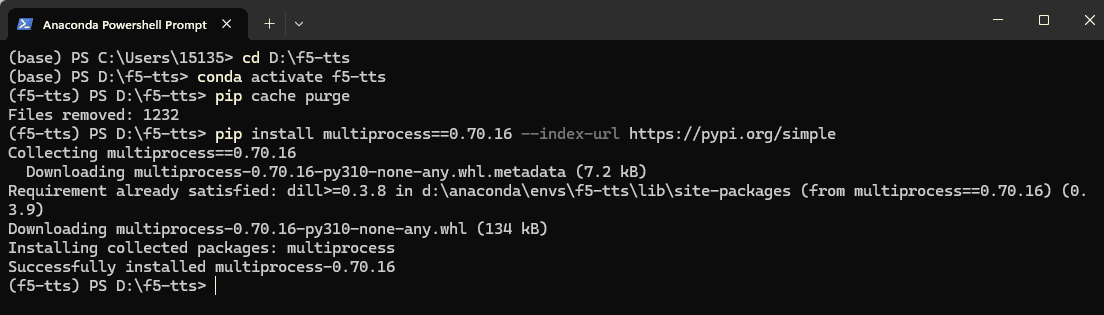
然后继续pip install git+https://github.com/SWivid/F5-TTS.git下载。
报错4:

解决方案:
pip install joblib –index-url https://pypi.org/simple/

然后继续pip install git+https://github.com/SWivid/F5-TTS.git下载。
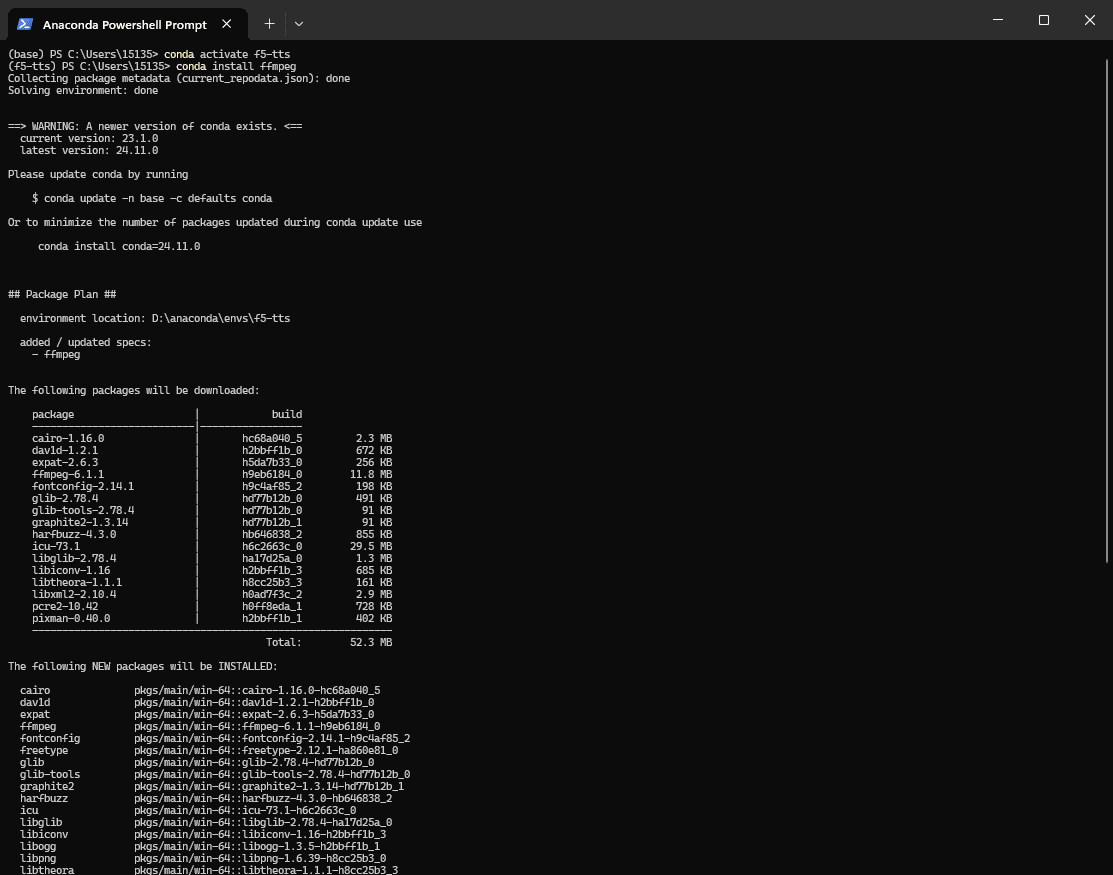
安装ffmpeg
conda install ffmpeg
推理
Gradio 应用
当前支持的特征:
基于块推理的基本文本到语音转换(TTS)
多风格/多说话者生成
由 Qwen2.5-3B-Instruct 支持的语音聊天
支持更多语言的自定义推理
# Launch a Gradio app (web interface)
f5-tts_infer-gradio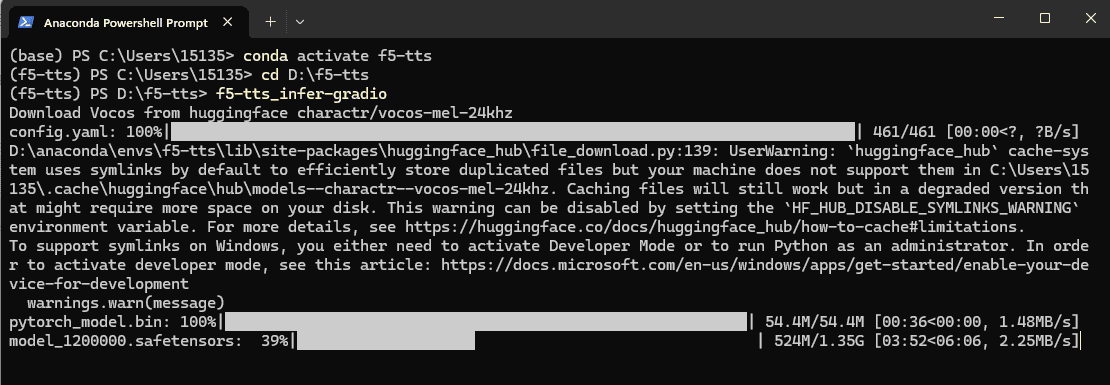
再次启动就会看到:
Ctrl+点击链接:
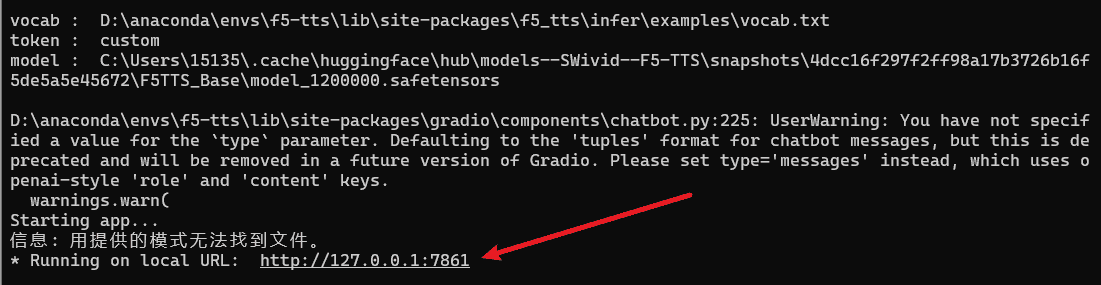
按照步骤操作:
上传音色文件【mp3/wav文件等】或者录音。
输入文本,点击按钮。

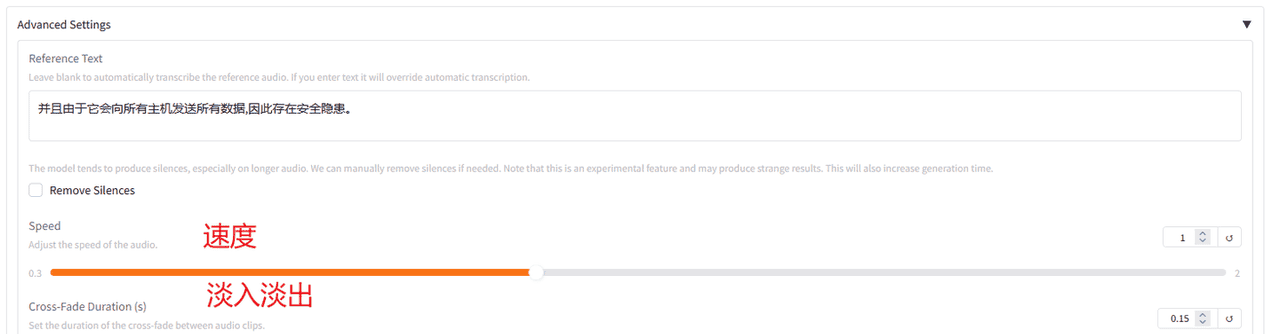
高级设置。
这里可以设置两个参数:
①说话速度
②音频剪辑之间交叉淡入淡出的效果的持续时间
注释:在音频编辑中,交叉淡入淡出(cross-fade)是一种技术,用于在两个音频片段之间平滑过渡,通过逐渐降低一个音频的音量同时逐渐增加另一个音频的音量,来避免音频之间的突兀切换。设置交叉淡入淡出的持续时间,就是确定这个过渡过程需要多长时间来完成。
例如,如果你设置了一个2秒的交叉淡入淡出,那么在两个音频片段的衔接处,前一个音频的音量会在2秒内逐渐降低至0,而后一个音频的音量会在同样的2秒内从0逐渐增加到正常水平。这样可以使得听众听到的音频流是连续且平滑的。
输出结果播放。

还可以看到声音指纹图。
总结
这个工具,可以说还不错,可以推荐,大家快去试试吧。



















暂无评论内容