
之前在本号列举了一系列时间序列算法和模型。光说不练假把式!本文测试了28个时间序列算法在某个数据集上的表现,本测试仅仅代表在特定数据集上的一次试验表现,并不能说明对应算法的优劣。
数据集
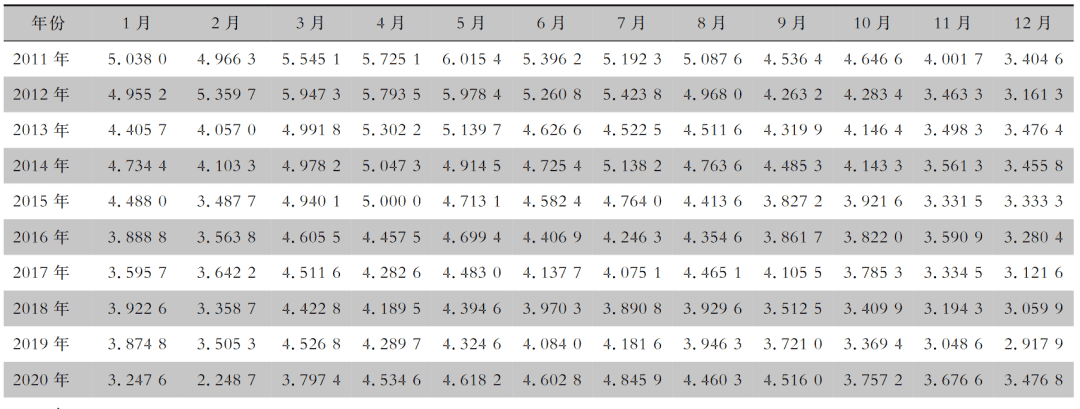
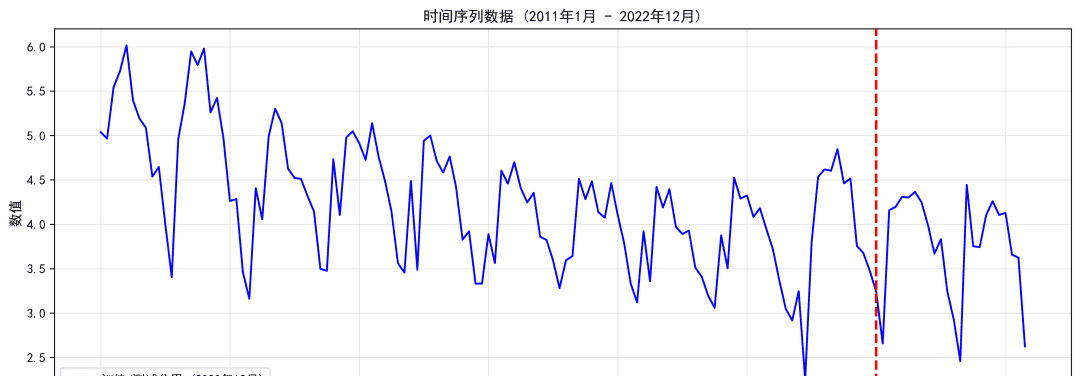
该数据集是浙江省2011年1月-2022年12月12年的月度结核病发病率数据集(/10万)。如有需要可以在评论区留言索取。
本文一共测试了如下28种算法:
1.KNN
2.随机森林
3.GBRT
4.SARIMA
5.BSTS
6.SVR
7.模糊时间序列
8.TCN
9.CNN-LSTM
10.GRU
11.指数平滑
12.ETS
13.DLM
14.马尔可夫链
15.Transformer
16.ARMA
17.VARMA
18.AR
19.VAR
20.MA
21.VECM
22.ARCH
23.ARIMA
24.GARCH
25.Seq2Seq
26.GPR
27.LSTM
28.BiLSTM
本文使用的评价指标如下:
MAE (平均绝对误差): 预测值与真实值之间的平均绝对差异,越小越好
RMSE (均方根误差): 预测误差的平方根,对异常值敏感,越小越好
MAPE (平均绝对百分比误差): 预测误差的百分比表示,越小越好
R² (决定系数): 模型对数据变异性的解释程度,越接近1越好
可视化的预测结果如下:
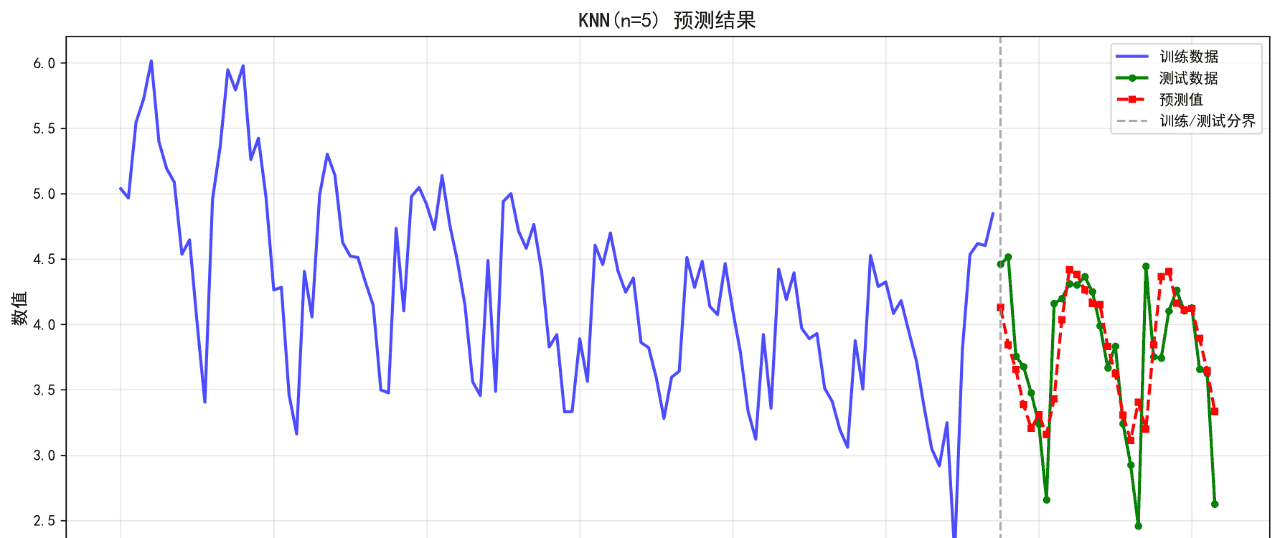
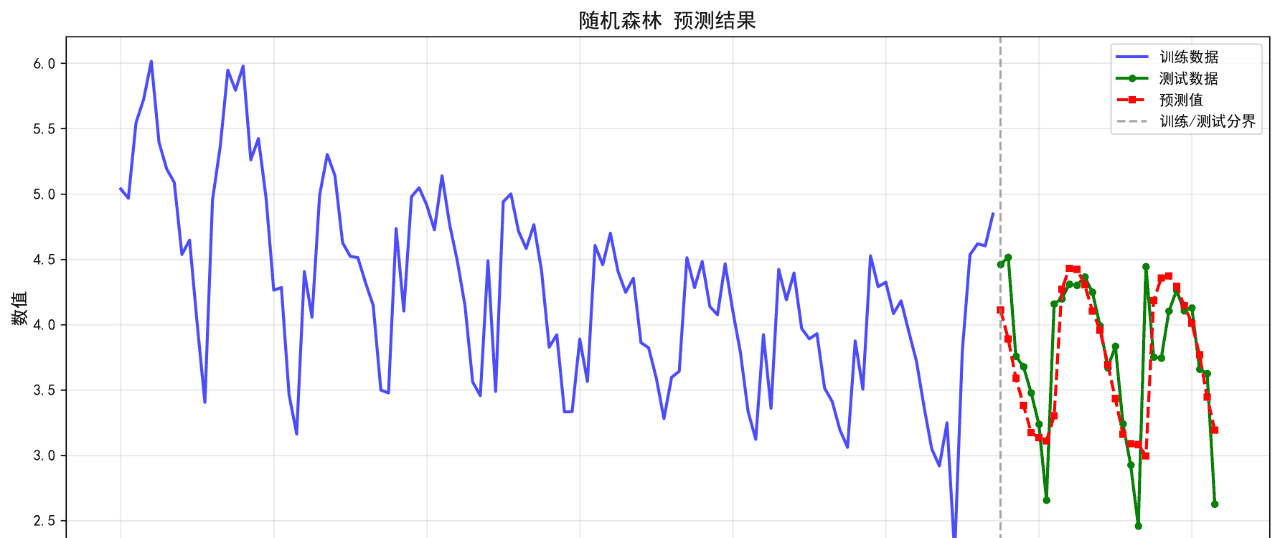
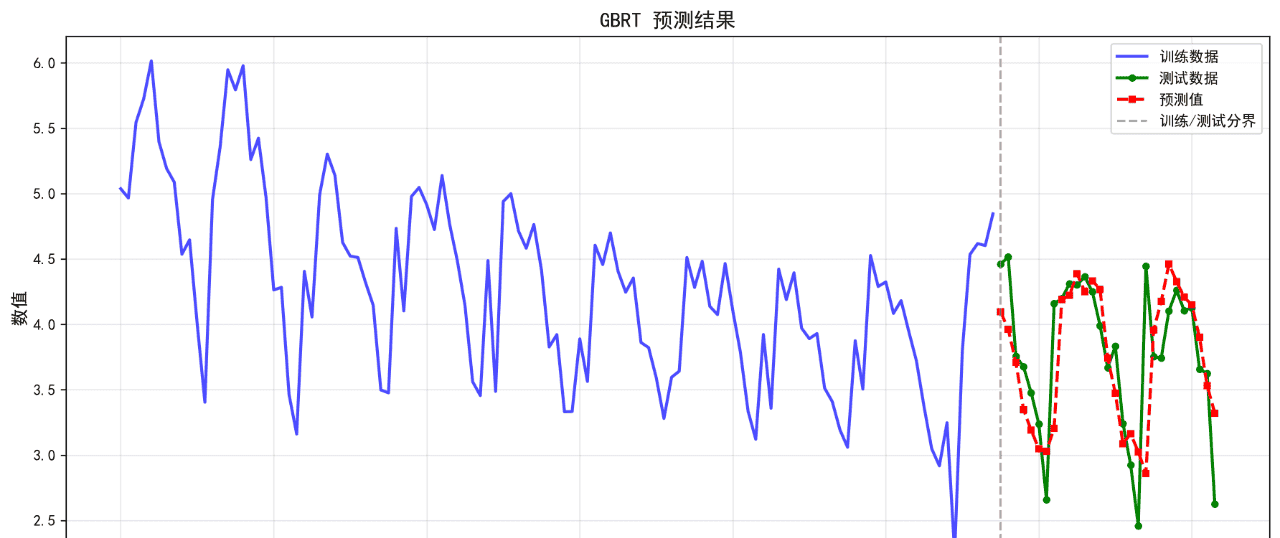
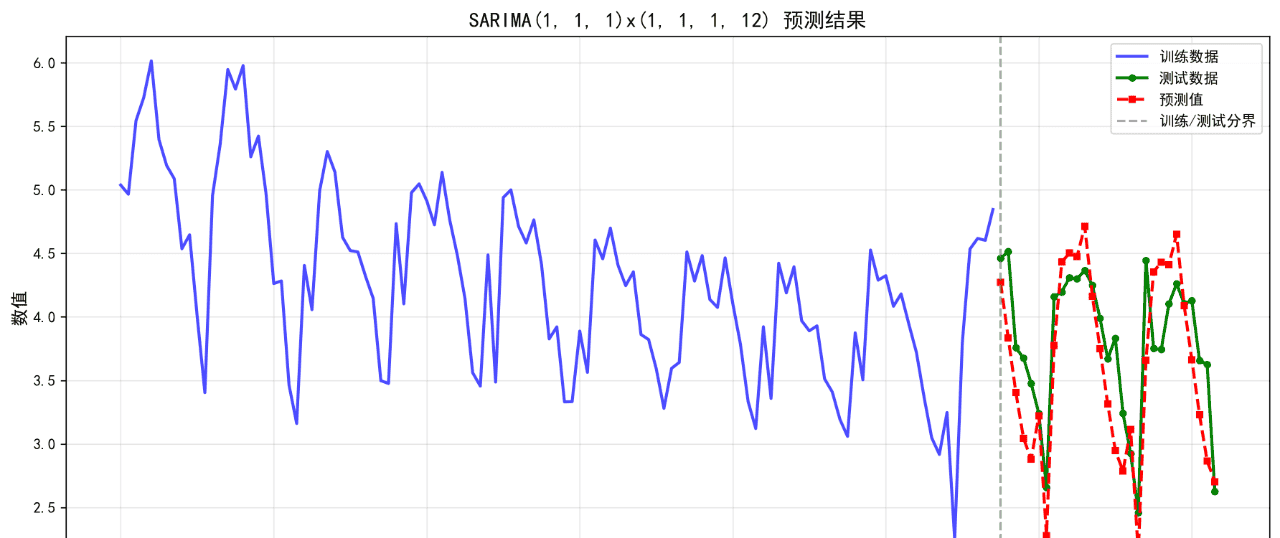
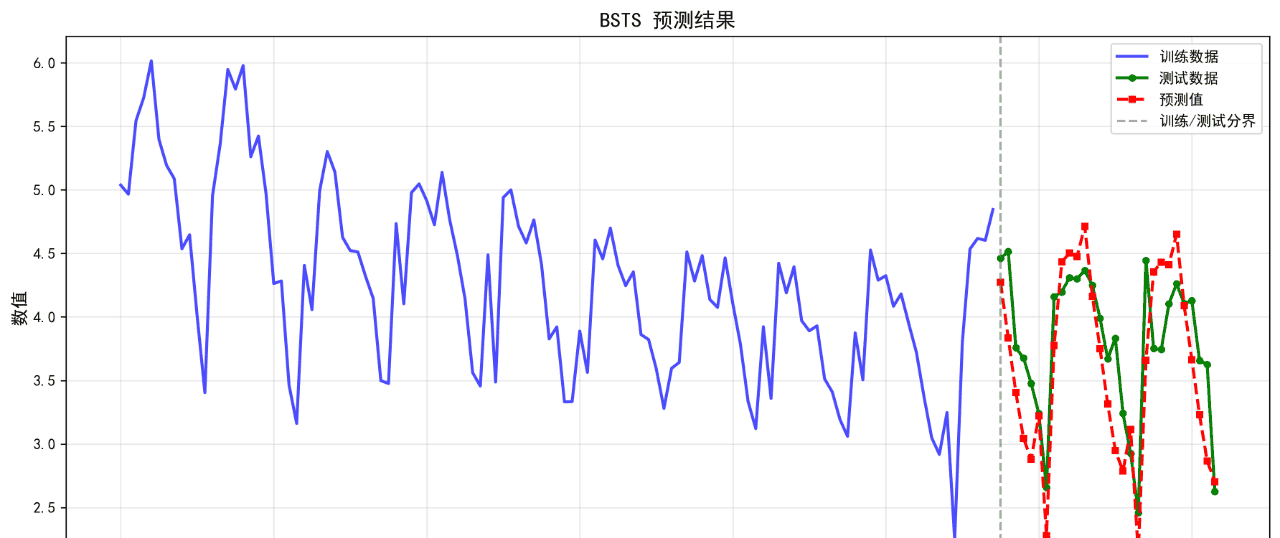
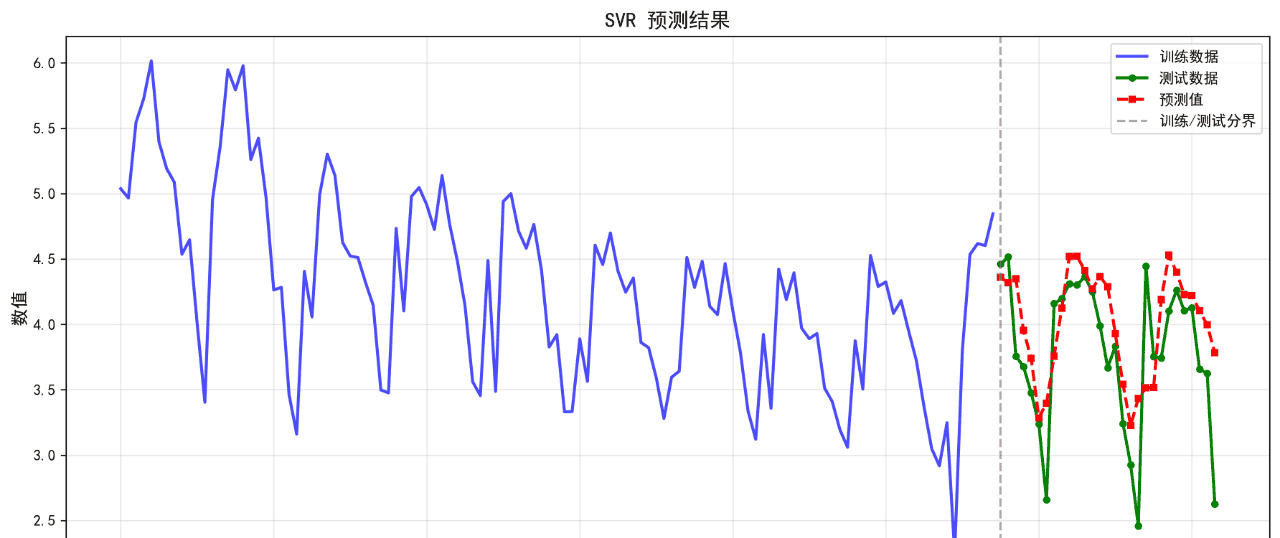
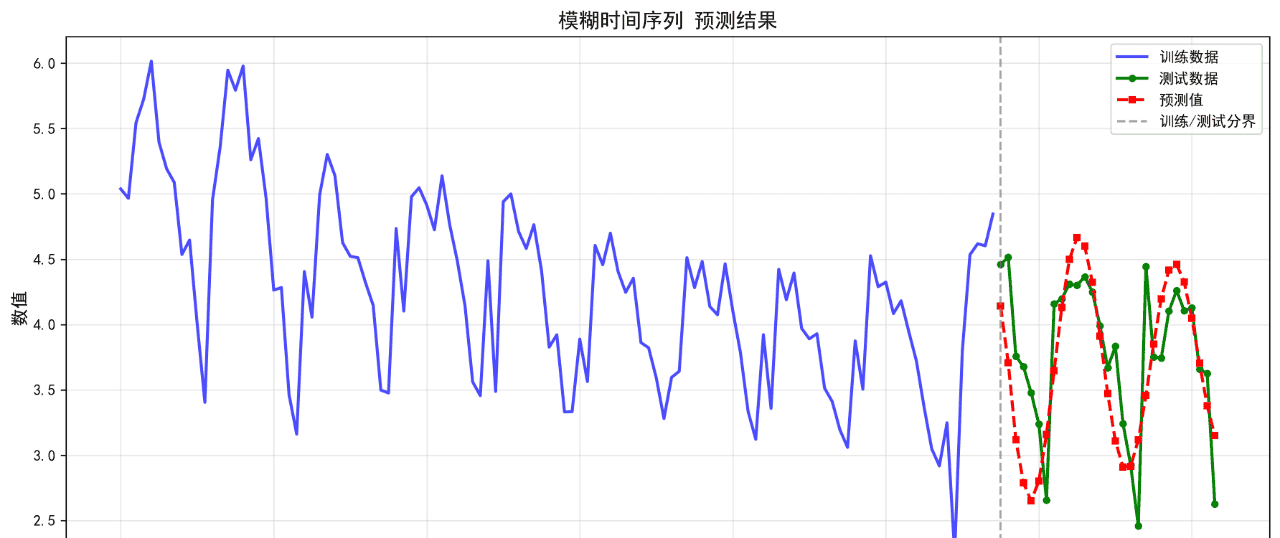
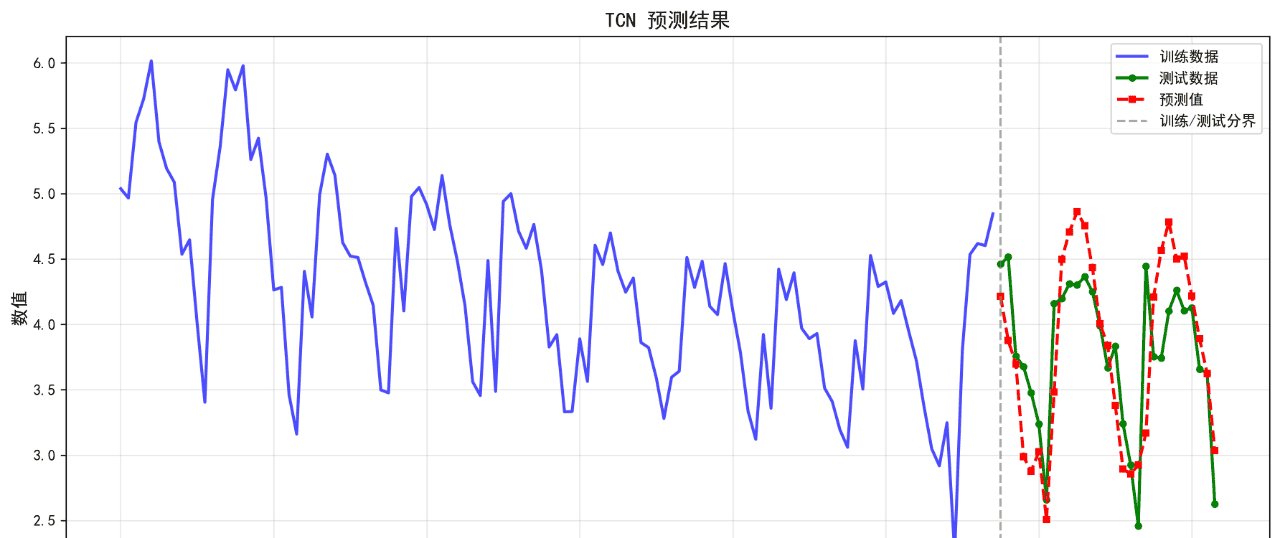
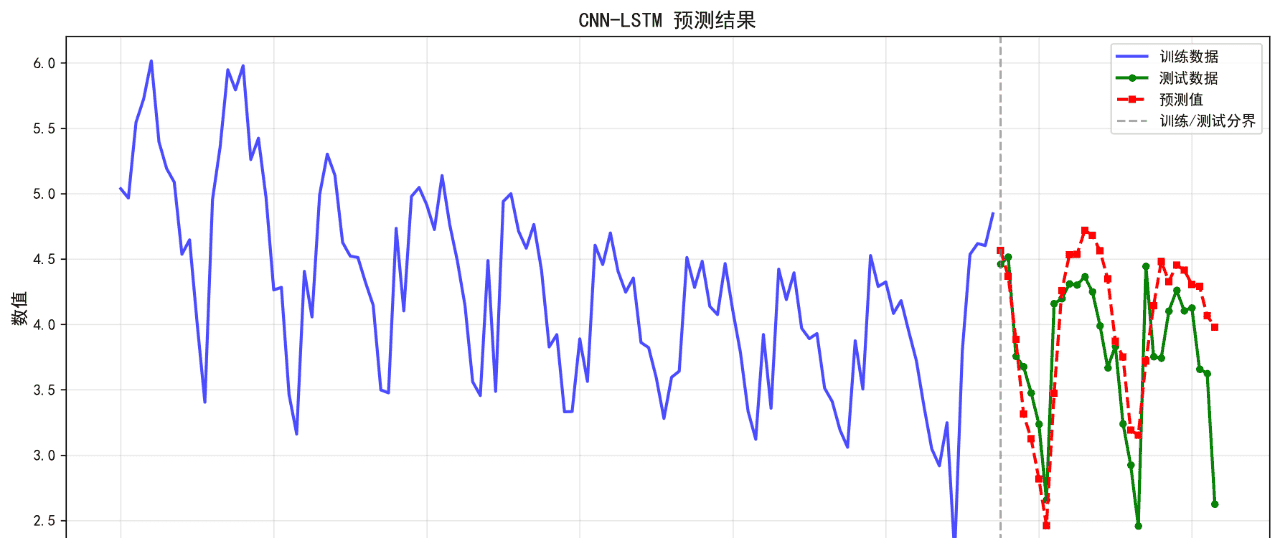
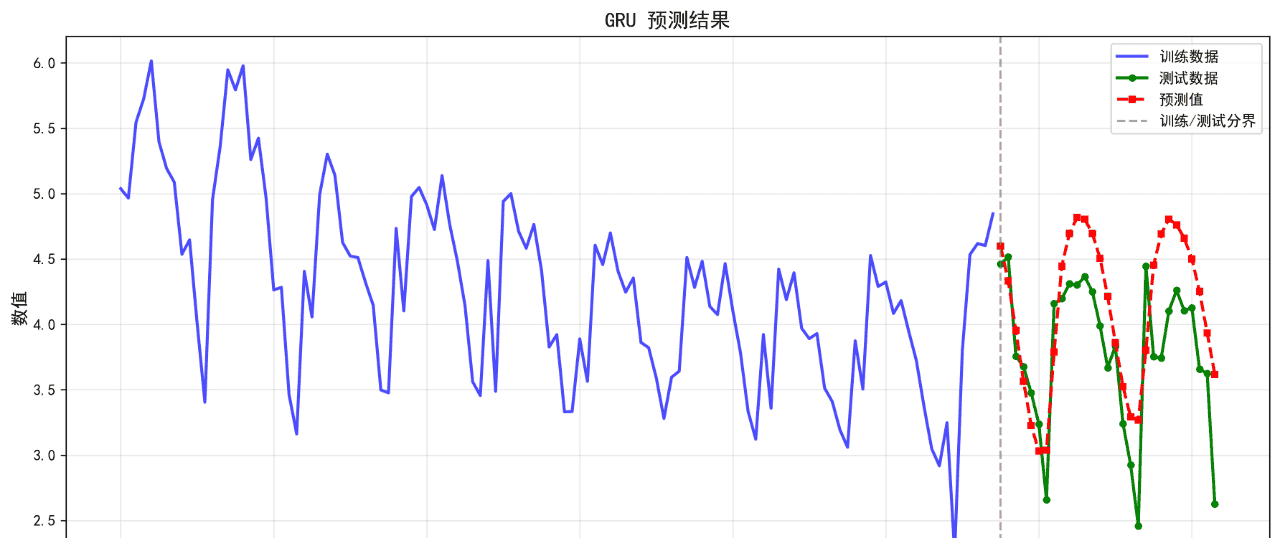
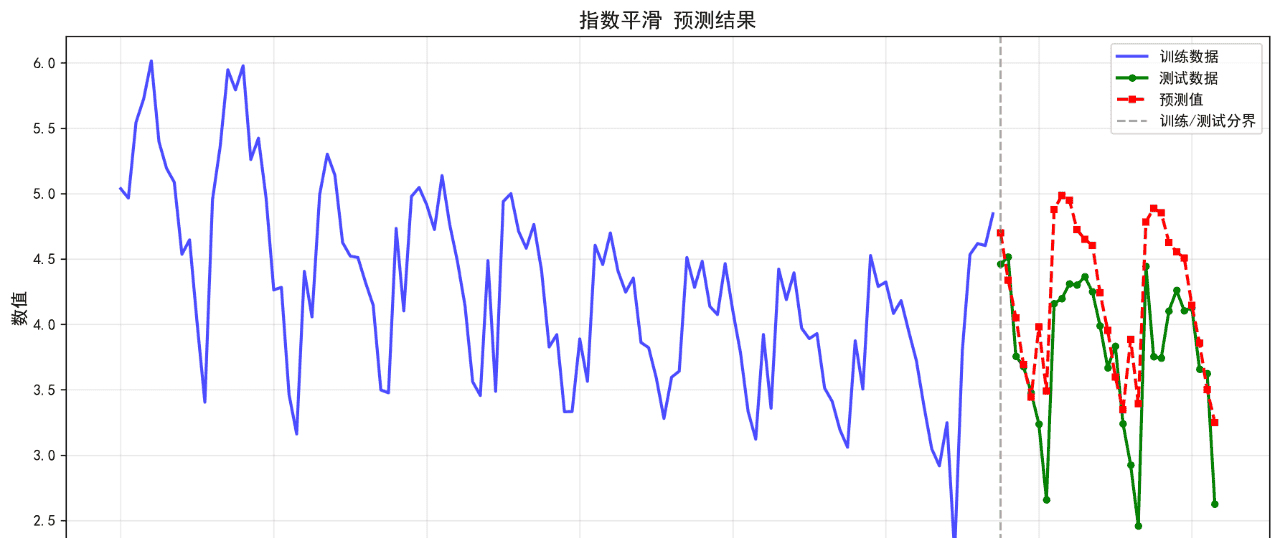
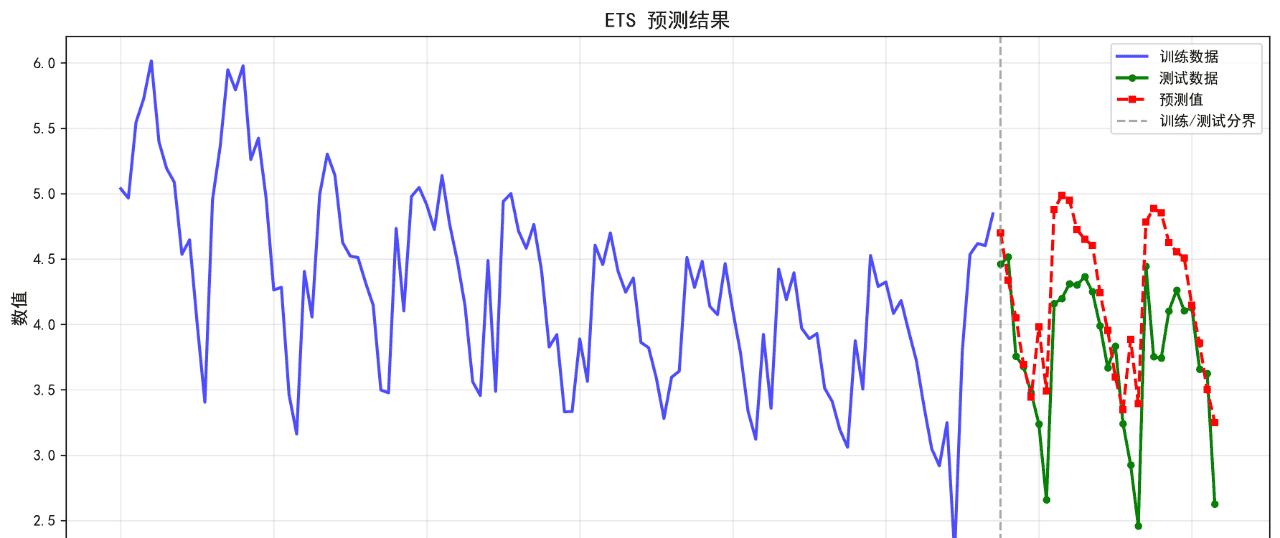
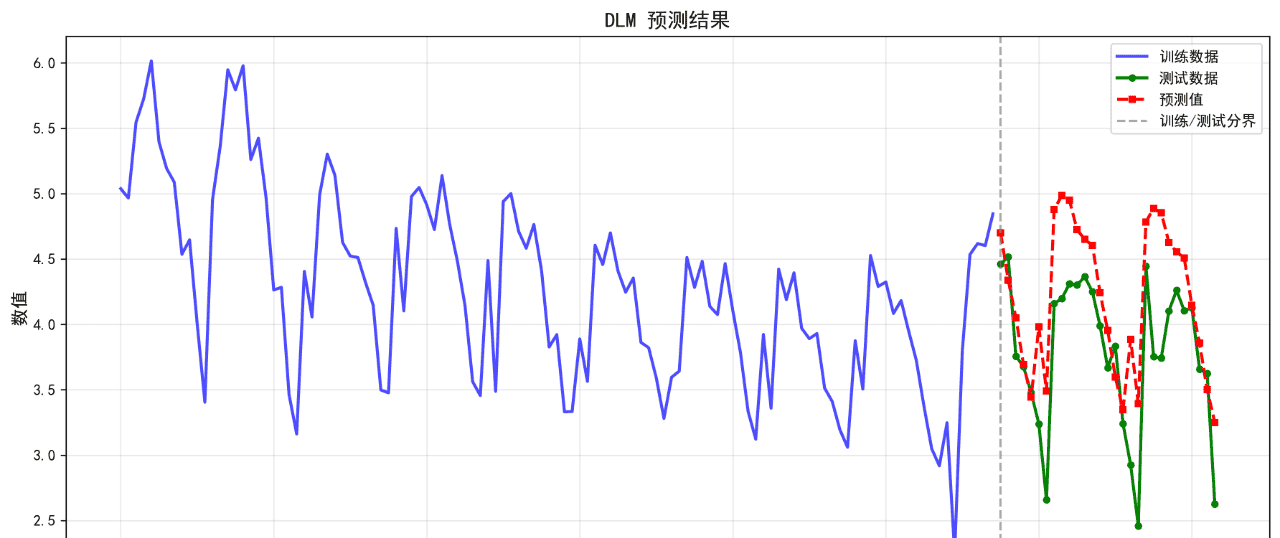
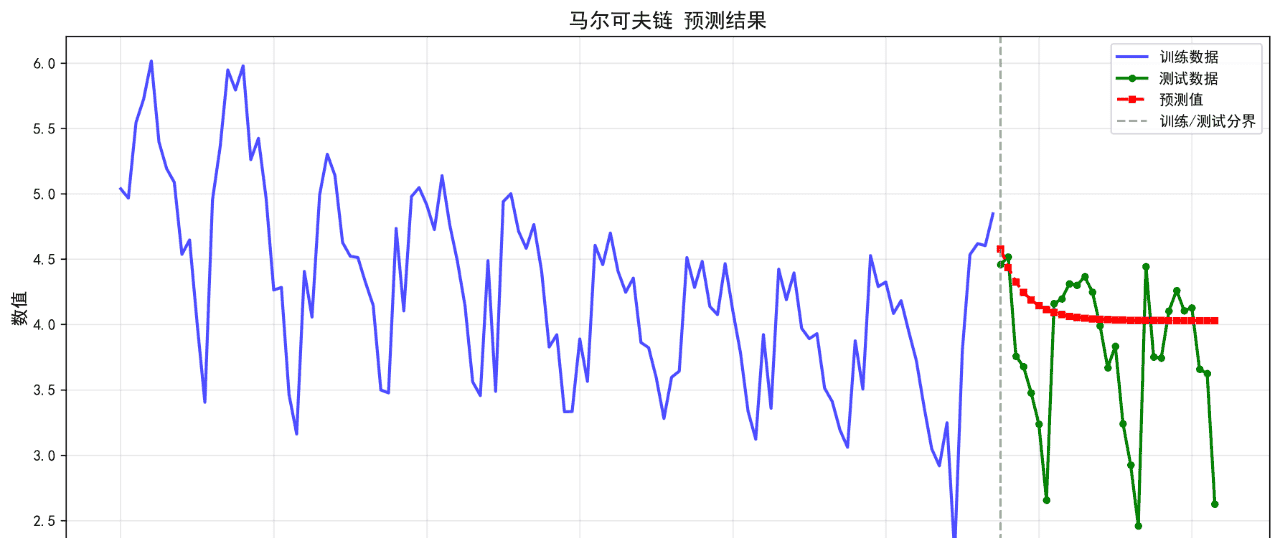
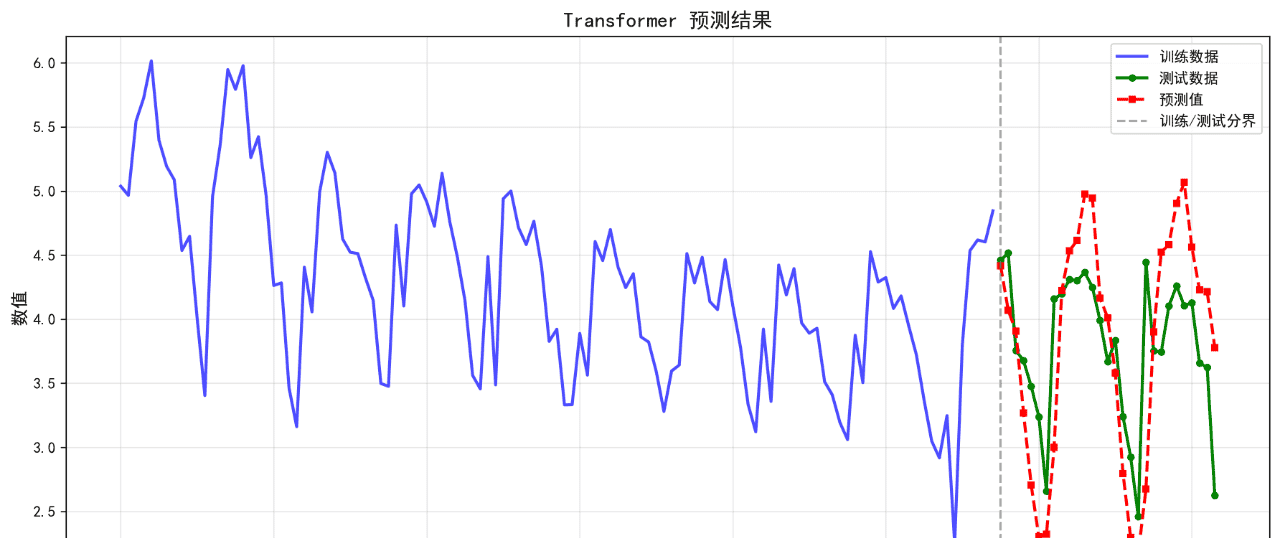
后面的几个算法的基础表现就不再列举了。在不进行任何调参的情况下,算法表现不佳,不足以用来作为预测算法使用。后续将进一步优化参数。下面给出算法评价报告。
=====================
时间序列预测算法对比分析报告
=====================
生成时间: 2025-11-05 14:21:04
数据信息:
总数据量: 144 条
训练集: 115 条 (80%)
测试集: 29 条 (20%)
======================
各算法预测结果对比
======================
算法 MAE RMSE MAPE(%) R²
———————————————————————-
AR(5) 0.4935 0.6947 15.71 -0.5060
MA(2) 0.5360 0.7505 17.04 -0.7578
ARMA(2,2) 0.5765 0.6929 17.20 -0.4982
ARIMA(1, 1, 1) 1.0163 1.1635 30.26 -3.2248
SARIMA(1, 1, 1)x(1, 1, 1, 12) 0.3872 0.4515 10.32 0.3639
指数平滑 0.4515 0.5561 12.86 0.0351
ETS 0.4515 0.5561 12.86 0.0351
SVR 0.3527 0.4564 10.43 0.3500
GBRT 0.3084 0.4469 8.49 0.3768
随机森林 0.3039 0.4328 8.36 0.4154
KNN(n=5) 0.2957 0.4238 8.41 0.4396
GPR 3.2559 3.5257 86.82 -37.7907
LSTM 8.3894 18.7696 257.80 -1098.4088
GRU 0.4392 0.4989 12.23 0.2234
BiLSTM 31250151.7945 144472333.4477 1139939852.06 -65135425335662872.0000
TCN 0.3878 0.4768 10.22 0.2907
Transformer 0.5440 0.6626 14.80 -0.3700
Seq2Seq 1.0489 1.2053 31.21 -3.5332
CNN-LSTM 0.4016 0.4868 11.46 0.2605
VAR(5) 0.5309 0.7407 16.85 -0.7123
VARMA(2,2) 0.5765 0.6929 17.20 -0.4982
VECM(1) 1.0086 1.1568 30.05 -3.1760
ARCH(1) 1.0086 1.1568 30.05 -3.1760
GARCH(1,1) 1.0163 1.1635 30.26 -3.2248
DLM 0.4515 0.5561 12.86 0.0351
模糊时间序列 0.3803 0.4701 10.50 0.3103
马尔可夫链 0.4600 0.6317 14.47 -0.2453
BSTS 0.3872 0.4515 10.32 0.3639
=====================
算法性能排名
=====================
按RMSE排序 (越小越好):
1. KNN(n=5) RMSE: 0.4238
2. 随机森林 RMSE: 0.4328
3. GBRT RMSE: 0.4469
4. SARIMA(1, 1, 1)x(1, 1, 1, 12) RMSE: 0.4515
5. BSTS RMSE: 0.4515
6. SVR RMSE: 0.4564
7. 模糊时间序列 RMSE: 0.4701
8. TCN RMSE: 0.4768
9. CNN-LSTM RMSE: 0.4868
10. GRU RMSE: 0.4989
11. 指数平滑 RMSE: 0.5561
12. ETS RMSE: 0.5561
13. DLM RMSE: 0.5561
14. 马尔可夫链 RMSE: 0.6317
15. Transformer RMSE: 0.6626
16. ARMA(2,2) RMSE: 0.6929
17. VARMA(2,2) RMSE: 0.6929
18. AR(5) RMSE: 0.6947
19. VAR(5) RMSE: 0.7407
20. MA(2) RMSE: 0.7505
21. VECM(1) RMSE: 1.1568
22. ARCH(1) RMSE: 1.1568
23. ARIMA(1, 1, 1) RMSE: 1.1635
24. GARCH(1,1) RMSE: 1.1635
25. Seq2Seq RMSE: 1.2053
26. GPR RMSE: 3.5257
27. LSTM RMSE: 18.7696
28. BiLSTM RMSE: 144472333.4477
按MAPE排序 (越小越好):
1. 随机森林 MAPE: 8.36%
2. KNN(n=5) MAPE: 8.41%
3. GBRT MAPE: 8.49%
4. TCN MAPE: 10.22%
5. SARIMA(1, 1, 1)x(1, 1, 1, 12) MAPE: 10.32%
6. BSTS MAPE: 10.32%
7. SVR MAPE: 10.43%
8. 模糊时间序列 MAPE: 10.50%
9. CNN-LSTM MAPE: 11.46%
10. GRU MAPE: 12.23%
11. 指数平滑 MAPE: 12.86%
12. ETS MAPE: 12.86%
13. DLM MAPE: 12.86%
14. 马尔可夫链 MAPE: 14.47%
15. Transformer MAPE: 14.80%
16. AR(5) MAPE: 15.71%
17. VAR(5) MAPE: 16.85%
18. MA(2) MAPE: 17.04%
19. ARMA(2,2) MAPE: 17.20%
20. VARMA(2,2) MAPE: 17.20%
21. VECM(1) MAPE: 30.05%
22. ARCH(1) MAPE: 30.05%
23. ARIMA(1, 1, 1) MAPE: 30.26%
24. GARCH(1,1) MAPE: 30.26%
25. Seq2Seq MAPE: 31.21%
26. GPR MAPE: 86.82%
27. LSTM MAPE: 257.80%
28. BiLSTM MAPE: 1139939852.06%
按R²排序 (越大越好):
1. KNN(n=5) R²: 0.4396
2. 随机森林 R²: 0.4154
3. GBRT R²: 0.3768
4. SARIMA(1, 1, 1)x(1, 1, 1, 12) R²: 0.3639
5. BSTS R²: 0.3639
6. SVR R²: 0.3500
7. 模糊时间序列 R²: 0.3103
8. TCN R²: 0.2907
9. CNN-LSTM R²: 0.2605
10. GRU R²: 0.2234
11. 指数平滑 R²: 0.0351
12. ETS R²: 0.0351
13. DLM R²: 0.0351
14. 马尔可夫链 R²: -0.2453
15. Transformer R²: -0.3700
16. ARMA(2,2) R²: -0.4982
17. VARMA(2,2) R²: -0.4982
18. AR(5) R²: -0.5060
19. VAR(5) R²: -0.7123
20. MA(2) R²: -0.7578
21. VECM(1) R²: -3.1760
22. ARCH(1) R²: -3.1760
23. ARIMA(1, 1, 1) R²: -3.2248
24. GARCH(1,1) R²: -3.2248
25. Seq2Seq R²: -3.5332
26. GPR R²: -37.7907
27. LSTM R²: -1098.4088
28. BiLSTM R²: -65135425335662872.0000
附上源代码:
"""
时间序列预测算法对比分析程序
使用多种算法进行时间序列预测,并生成对比分析报告
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error, mean_squared_error, mean_absolute_percentage_error
import warnings
import os
import sys
from datetime import datetime
# 统计模型
from statsmodels.tsa.ar_model import AutoReg
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.tsa.holtwinters import ExponentialSmoothing
# LSTM/深度学习相关
try:
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import LSTM, Dense, GRU, Bidirectional, Conv1D, MaxPooling1D, Flatten, Dropout, Input, Attention, MultiHeadAttention, LayerNormalization
from tensorflow.keras.callbacks import EarlyStopping
TENSORFLOW_AVAILABLE = True
except ImportError:
TENSORFLOW_AVAILABLE = False
print("警告: TensorFlow未安装,深度学习模型将无法使用")
# Prophet
try:
from prophet import Prophet
PROPHET_AVAILABLE = True
except ImportError:
PROPHET_AVAILABLE = False
# 机器学习模型
try:
from sklearn.svm import SVR
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel as C
SKLEARN_AVAILABLE = True
except ImportError:
SKLEARN_AVAILABLE = False
# LightGBM
try:
import lightgbm as lgb
LIGHTGBM_AVAILABLE = True
except ImportError:
LIGHTGBM_AVAILABLE = False
# 统计模型
try:
from statsmodels.tsa.vector_ar.var_model import VAR
from statsmodels.tsa.statespace.varmax import VARMAX
from statsmodels.tsa.vector_ar.vecm import VECM
from statsmodels.tsa.arch.arch_model import ARCHModel
from statsmodels.tsa.statespace.exponential_smoothing import ExponentialSmoothing as ETS
STATSMODELS_VAR_AVAILABLE = True
except ImportError:
STATSMODELS_VAR_AVAILABLE = False
warnings.filterwarnings('ignore')
# 设置Windows控制台编码为UTF-8
if sys.platform == 'win32':
try:
sys.stdout.reconfigure(encoding='utf-8')
sys.stderr.reconfigure(encoding='utf-8')
except:
pass
# 设置matplotlib支持中文
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
class TimeSeriesPredictor:
"""时间序列预测器基类"""
def __init__(self, name):
self.name = name
self.model = None
self.is_fitted = False
def fit(self, data):
"""训练模型"""
raise NotImplementedError
def predict(self, steps):
"""预测"""
raise NotImplementedError
def evaluate(self, y_true, y_pred):
"""评估预测结果"""
mae = mean_absolute_error(y_true, y_pred)
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
mape = mean_absolute_percentage_error(y_true, y_pred) * 100
# 计算R²
ss_res = np.sum((y_true - y_pred) ** 2)
ss_tot = np.sum((y_true - np.mean(y_true)) ** 2)
r2 = 1 - (ss_res / ss_tot) if ss_tot != 0 else 0
return {
'MAE': mae,
'RMSE': rmse,
'MAPE': mape,
'R²': r2
}
class ARPredictor(TimeSeriesPredictor):
"""AR (自回归) 模型"""
def __init__(self, lags=5):
super().__init__(f"AR({lags})")
self.lags = lags
def fit(self, data):
try:
self.model = AutoReg(data, lags=self.lags).fit()
self.is_fitted = True
except Exception as e:
print(f"AR模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
# 如果forecast失败,使用predict
n = len(self.model.model.endog)
predictions = self.model.predict(start=n, end=n+steps-1)
return predictions.values if hasattr(predictions, 'values') else predictions
class MAPredictor(TimeSeriesPredictor):
"""MA (移动平均) 模型 - 通过ARIMA(0,0,q)实现"""
def __init__(self, q=2):
super().__init__(f"MA({q})")
self.q = q
def fit(self, data):
try:
self.model = ARIMA(data, order=(0, 0, self.q)).fit()
self.is_fitted = True
except Exception as e:
print(f"MA模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
n = len(self.model.model.endog)
predictions = self.model.predict(start=n, end=n+steps-1)
return predictions.values if hasattr(predictions, 'values') else predictions
class ARMAPredictor(TimeSeriesPredictor):
"""ARMA 模型"""
def __init__(self, p=2, q=2):
super().__init__(f"ARMA({p},{q})")
self.p = p
self.q = q
def fit(self, data):
try:
self.model = ARIMA(data, order=(self.p, 0, self.q)).fit()
self.is_fitted = True
except Exception as e:
print(f"ARMA模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
n = len(self.model.model.endog)
predictions = self.model.predict(start=n, end=n+steps-1)
return predictions.values if hasattr(predictions, 'values') else predictions
class ARIMAPredictor(TimeSeriesPredictor):
"""ARIMA 模型"""
def __init__(self, order=(1, 1, 1)):
super().__init__(f"ARIMA{order}")
self.order = order
def fit(self, data):
try:
self.model = ARIMA(data, order=self.order).fit()
self.is_fitted = True
except Exception as e:
print(f"ARIMA模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
n = len(self.model.model.endog)
predictions = self.model.predict(start=n, end=n+steps-1)
return predictions.values if hasattr(predictions, 'values') else predictions
class SARIMAPredictor(TimeSeriesPredictor):
"""SARIMA 模型"""
def __init__(self, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12)):
super().__init__(f"SARIMA{order}x{seasonal_order}")
self.order = order
self.seasonal_order = seasonal_order
def fit(self, data):
try:
self.model = SARIMAX(data, order=self.order,
seasonal_order=self.seasonal_order,
enforce_stationarity=False,
enforce_invertibility=False).fit(disp=False)
self.is_fitted = True
except Exception as e:
print(f"SARIMA模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
n = len(self.model.model.endog)
predictions = self.model.predict(start=n, end=n+steps-1)
return predictions.values if hasattr(predictions, 'values') else predictions
class ExponentialSmoothingPredictor(TimeSeriesPredictor):
"""指数平滑模型"""
def __init__(self, trend='add', seasonal='add', seasonal_periods=12):
super().__init__("指数平滑")
self.trend = trend
self.seasonal = seasonal
self.seasonal_periods = seasonal_periods
def fit(self, data):
try:
self.model = ExponentialSmoothing(data,
trend=self.trend,
seasonal=self.seasonal,
seasonal_periods=self.seasonal_periods).fit()
self.is_fitted = True
except Exception as e:
# 如果带季节性的模型失败,尝试不带季节性的
try:
self.model = ExponentialSmoothing(data, trend=self.trend).fit()
self.is_fitted = True
except:
print(f"指数平滑模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
class LSTMPredictor(TimeSeriesPredictor):
"""LSTM 模型"""
def __init__(self, lookback=12, units=50):
super().__init__("LSTM")
self.lookback = lookback
self.units = units
self.scaler_mean = None
self.scaler_std = None
def _normalize(self, data):
"""数据归一化"""
self.scaler_mean = np.mean(data)
self.scaler_std = np.std(data)
return (data - self.scaler_mean) / self.scaler_std
def _denormalize(self, data):
"""数据反归一化"""
return data * self.scaler_std + self.scaler_mean
def _create_sequences(self, data, lookback):
"""创建时间序列窗口"""
X, y = [], []
for i in range(lookback, len(data)):
X.append(data[i-lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not TENSORFLOW_AVAILABLE:
print("TensorFlow未安装,跳过LSTM模型")
self.is_fitted = False
return
try:
# 保存原始数据用于后续预测
self.train_data = data.copy()
# 归一化数据(保存归一化参数)
data_norm = self._normalize(data)
# 创建序列
if len(data_norm) < self.lookback + 1:
print(f"数据长度不足,需要至少{self.lookback + 1}个样本")
self.is_fitted = False
return
X, y = self._create_sequences(data_norm, self.lookback)
# 重塑数据为LSTM输入格式 [samples, time steps, features]
X = X.reshape((X.shape[0], X.shape[1], 1))
# 构建LSTM模型
self.model = Sequential([
LSTM(self.units, activation='relu', input_shape=(self.lookback, 1)),
Dense(1)
])
self.model.compile(optimizer='adam', loss='mse')
# 训练模型
early_stop = EarlyStopping(monitor='loss', patience=10, verbose=0)
self.model.fit(X, y, epochs=100, batch_size=16,
callbacks=[early_stop], verbose=0)
self.is_fitted = True
except Exception as e:
print(f"LSTM模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
# 获取最后lookback个数据点
if hasattr(self, 'last_data'):
last_data = self.last_data
else:
raise ValueError("需要提供历史数据")
predictions = []
current_data = last_data.copy()
for _ in range(steps):
# 准备输入
X_input = current_data[-self.lookback:].reshape(1, self.lookback, 1)
# 预测
pred = self.model.predict(X_input, verbose=0)[0, 0]
predictions.append(pred)
# 更新数据
current_data = np.append(current_data, pred)
# 反归一化
predictions = self._denormalize(np.array(predictions))
return predictions
except Exception as e:
print(f"LSTM预测失败: {e}")
return np.full(steps, np.nan)
def set_last_data(self, data):
"""设置用于预测的历史数据"""
if self.is_fitted:
# 使用训练时的归一化参数
if self.scaler_mean is not None and self.scaler_std is not None:
self.last_data = (data - self.scaler_mean) / self.scaler_std
else:
self.last_data = self._normalize(data)
# ==================== 新增预测器类 ====================
class ProphetPredictor(TimeSeriesPredictor):
"""Prophet模型"""
def __init__(self):
super().__init__("Prophet")
def fit(self, data):
if not PROPHET_AVAILABLE:
self.is_fitted = False
return
try:
# Prophet需要DataFrame格式,包含ds和y列
# 使用月度数据(每月最后一天)
df = pd.DataFrame({
'ds': pd.date_range(start='2011-01-31', periods=len(data), freq='M'),
'y': data
})
self.model = Prophet(yearly_seasonality=True, weekly_seasonality=False,
daily_seasonality=False)
self.model.fit(df)
self.is_fitted = True
except Exception as e:
print(f"Prophet模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
future = self.model.make_future_dataframe(periods=steps, freq='M')
forecast = self.model.predict(future)
return forecast['yhat'].values[-steps:]
except:
return np.full(steps, np.nan)
class SVRPredictor(TimeSeriesPredictor):
"""支持向量回归(SVR)"""
def __init__(self, lookback=12):
super().__init__("SVR")
self.lookback = lookback
def _create_features(self, data):
X, y = [], []
for i in range(self.lookback, len(data)):
X.append(data[i-self.lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not SKLEARN_AVAILABLE:
self.is_fitted = False
return
try:
X, y = self._create_features(data)
self.model = SVR(kernel='rbf', C=100, gamma='scale', epsilon=0.1)
self.model.fit(X, y)
self.train_data = data
self.is_fitted = True
except Exception as e:
print(f"SVR模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
predictions = []
current_data = self.train_data[-self.lookback:].copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, -1)
pred = self.model.predict(X_input)[0]
predictions.append(pred)
current_data = np.append(current_data, pred)
return np.array(predictions)
except:
return np.full(steps, np.nan)
class GBRTPredictor(TimeSeriesPredictor):
"""梯度提升回归树(GBRT)"""
def __init__(self, lookback=12):
super().__init__("GBRT")
self.lookback = lookback
def _create_features(self, data):
X, y = [], []
for i in range(self.lookback, len(data)):
X.append(data[i-self.lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not SKLEARN_AVAILABLE:
self.is_fitted = False
return
try:
X, y = self._create_features(data)
self.model = GradientBoostingRegressor(n_estimators=100, max_depth=5, random_state=42)
self.model.fit(X, y)
self.train_data = data
self.is_fitted = True
except Exception as e:
print(f"GBRT模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
predictions = []
current_data = self.train_data[-self.lookback:].copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, -1)
pred = self.model.predict(X_input)[0]
predictions.append(pred)
current_data = np.append(current_data, pred)
return np.array(predictions)
except:
return np.full(steps, np.nan)
class GRUPredictor(TimeSeriesPredictor):
"""门控循环单元(GRU)"""
def __init__(self, lookback=12, units=50):
super().__init__("GRU")
self.lookback = lookback
self.units = units
self.scaler_mean = None
self.scaler_std = None
def _normalize(self, data):
self.scaler_mean = np.mean(data)
self.scaler_std = np.std(data)
return (data - self.scaler_mean) / self.scaler_std
def _denormalize(self, data):
return data * self.scaler_std + self.scaler_mean
def _create_sequences(self, data, lookback):
X, y = [], []
for i in range(lookback, len(data)):
X.append(data[i-lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not TENSORFLOW_AVAILABLE:
self.is_fitted = False
return
try:
self.train_data = data.copy()
data_norm = self._normalize(data)
if len(data_norm) < self.lookback + 1:
self.is_fitted = False
return
X, y = self._create_sequences(data_norm, self.lookback)
X = X.reshape((X.shape[0], X.shape[1], 1))
self.model = Sequential([
GRU(self.units, activation='relu', input_shape=(self.lookback, 1)),
Dense(1)
])
self.model.compile(optimizer='adam', loss='mse')
early_stop = EarlyStopping(monitor='loss', patience=10, verbose=0)
self.model.fit(X, y, epochs=100, batch_size=16, callbacks=[early_stop], verbose=0)
self.is_fitted = True
except Exception as e:
print(f"GRU模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
last_data = self._normalize(self.train_data)
predictions = []
current_data = last_data.copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, self.lookback, 1)
pred = self.model.predict(X_input, verbose=0)[0, 0]
predictions.append(pred)
current_data = np.append(current_data, pred)
predictions = self._denormalize(np.array(predictions))
return predictions
except:
return np.full(steps, np.nan)
class BiLSTMPredictor(TimeSeriesPredictor):
"""双向长短期记忆网络(BiLSTM)"""
def __init__(self, lookback=12, units=50):
super().__init__("BiLSTM")
self.lookback = lookback
self.units = units
self.scaler_mean = None
self.scaler_std = None
def _normalize(self, data):
self.scaler_mean = np.mean(data)
self.scaler_std = np.std(data)
return (data - self.scaler_mean) / self.scaler_std
def _denormalize(self, data):
return data * self.scaler_std + self.scaler_mean
def _create_sequences(self, data, lookback):
X, y = [], []
for i in range(lookback, len(data)):
X.append(data[i-lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not TENSORFLOW_AVAILABLE:
self.is_fitted = False
return
try:
self.train_data = data.copy()
data_norm = self._normalize(data)
if len(data_norm) < self.lookback + 1:
self.is_fitted = False
return
X, y = self._create_sequences(data_norm, self.lookback)
X = X.reshape((X.shape[0], X.shape[1], 1))
self.model = Sequential([
Bidirectional(LSTM(self.units, activation='relu'), input_shape=(self.lookback, 1)),
Dense(1)
])
self.model.compile(optimizer='adam', loss='mse')
early_stop = EarlyStopping(monitor='loss', patience=10, verbose=0)
self.model.fit(X, y, epochs=100, batch_size=16, callbacks=[early_stop], verbose=0)
self.is_fitted = True
except Exception as e:
print(f"BiLSTM模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
last_data = self._normalize(self.train_data)
predictions = []
current_data = last_data.copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, self.lookback, 1)
pred = self.model.predict(X_input, verbose=0)[0, 0]
predictions.append(pred)
current_data = np.append(current_data, pred)
predictions = self._denormalize(np.array(predictions))
return predictions
except:
return np.full(steps, np.nan)
class RandomForestPredictor(TimeSeriesPredictor):
"""随机森林回归"""
def __init__(self, lookback=12):
super().__init__("随机森林")
self.lookback = lookback
def _create_features(self, data):
X, y = [], []
for i in range(self.lookback, len(data)):
X.append(data[i-self.lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not SKLEARN_AVAILABLE:
self.is_fitted = False
return
try:
X, y = self._create_features(data)
self.model = RandomForestRegressor(n_estimators=100, max_depth=10, random_state=42)
self.model.fit(X, y)
self.train_data = data
self.is_fitted = True
except Exception as e:
print(f"随机森林模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
predictions = []
current_data = self.train_data[-self.lookback:].copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, -1)
pred = self.model.predict(X_input)[0]
predictions.append(pred)
current_data = np.append(current_data, pred)
return np.array(predictions)
except:
return np.full(steps, np.nan)
class LightGBMPredictor(TimeSeriesPredictor):
"""轻量级梯度提升机(LightGBM)"""
def __init__(self, lookback=12):
super().__init__("LightGBM")
self.lookback = lookback
def _create_features(self, data):
X, y = [], []
for i in range(self.lookback, len(data)):
X.append(data[i-self.lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not LIGHTGBM_AVAILABLE:
self.is_fitted = False
return
try:
X, y = self._create_features(data)
self.model = lgb.LGBMRegressor(n_estimators=100, max_depth=5, random_state=42, verbose=-1)
self.model.fit(X, y)
self.train_data = data
self.is_fitted = True
except Exception as e:
print(f"LightGBM模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
predictions = []
current_data = self.train_data[-self.lookback:].copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, -1)
pred = self.model.predict(X_input)[0]
predictions.append(pred)
current_data = np.append(current_data, pred)
return np.array(predictions)
except:
return np.full(steps, np.nan)
class KNNPredictor(TimeSeriesPredictor):
"""K近邻回归(KNN)"""
def __init__(self, lookback=12, n_neighbors=5):
super().__init__(f"KNN(n={n_neighbors})")
self.lookback = lookback
self.n_neighbors = n_neighbors
def _create_features(self, data):
X, y = [], []
for i in range(self.lookback, len(data)):
X.append(data[i-self.lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not SKLEARN_AVAILABLE:
self.is_fitted = False
return
try:
X, y = self._create_features(data)
self.model = KNeighborsRegressor(n_neighbors=self.n_neighbors)
self.model.fit(X, y)
self.train_data = data
self.is_fitted = True
except Exception as e:
print(f"KNN模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
predictions = []
current_data = self.train_data[-self.lookback:].copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, -1)
pred = self.model.predict(X_input)[0]
predictions.append(pred)
current_data = np.append(current_data, pred)
return np.array(predictions)
except:
return np.full(steps, np.nan)
class GPRPredictor(TimeSeriesPredictor):
"""高斯过程回归(GPR)"""
def __init__(self, lookback=12):
super().__init__("GPR")
self.lookback = lookback
def _create_features(self, data):
X, y = [], []
for i in range(self.lookback, len(data)):
X.append(data[i-self.lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not SKLEARN_AVAILABLE:
self.is_fitted = False
return
try:
X, y = self._create_features(data)
# 限制数据量,因为GPR计算复杂度高
if len(X) > 100:
X = X[-100:]
y = y[-100:]
kernel = C(1.0, (1e-3, 1e3)) * RBF(1.0, (1e-2, 1e2))
self.model = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10, random_state=42)
self.model.fit(X, y)
self.train_data = data
self.is_fitted = True
except Exception as e:
print(f"GPR模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
predictions = []
current_data = self.train_data[-self.lookback:].copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, -1)
pred = self.model.predict(X_input)[0]
predictions.append(pred)
current_data = np.append(current_data, pred)
return np.array(predictions)
except:
return np.full(steps, np.nan)
class ARCHPredictor(TimeSeriesPredictor):
"""自回归条件异方差模型(ARCH)"""
def __init__(self, p=1):
super().__init__(f"ARCH({p})")
self.p = p
def fit(self, data):
try:
# ARCH模型需要平稳数据,这里使用一阶差分
diff_data = np.diff(data)
self.original_data = data
self.diff_data = diff_data
# 简化实现:使用ARIMA作为近似
from statsmodels.tsa.arima.model import ARIMA
self.model = ARIMA(data, order=(self.p, 1, 0)).fit()
self.is_fitted = True
except Exception as e:
print(f"ARCH模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
class GARCHPredictor(TimeSeriesPredictor):
"""广义自回归条件异方差模型(GARCH)"""
def __init__(self, p=1, q=1):
super().__init__(f"GARCH({p},{q})")
self.p = p
self.q = q
def fit(self, data):
try:
# GARCH模型简化实现:使用ARIMA作为近似
from statsmodels.tsa.arima.model import ARIMA
self.model = ARIMA(data, order=(max(self.p, self.q), 1, max(self.p, self.q))).fit()
self.is_fitted = True
except Exception as e:
print(f"GARCH模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
class ETSPredictor(TimeSeriesPredictor):
"""指数平滑状态空间模型(ETS)"""
def __init__(self, trend='add', seasonal='add', seasonal_periods=12):
super().__init__("ETS")
self.trend = trend
self.seasonal = seasonal
self.seasonal_periods = seasonal_periods
def fit(self, data):
try:
# 使用statsmodels的指数平滑
self.model = ExponentialSmoothing(data,
trend=self.trend,
seasonal=self.seasonal,
seasonal_periods=self.seasonal_periods).fit()
self.is_fitted = True
except Exception as e:
try:
self.model = ExponentialSmoothing(data, trend=self.trend).fit()
self.is_fitted = True
except:
print(f"ETS模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
# 简化版本的预测器(由于实现复杂度)
class TCNPredictor(TimeSeriesPredictor):
"""时间卷积网络(TCN) - 简化版"""
def __init__(self, lookback=12, filters=64):
super().__init__("TCN")
self.lookback = lookback
self.filters = filters
self.scaler_mean = None
self.scaler_std = None
def _normalize(self, data):
self.scaler_mean = np.mean(data)
self.scaler_std = np.std(data)
return (data - self.scaler_mean) / self.scaler_std
def _denormalize(self, data):
return data * self.scaler_std + self.scaler_mean
def _create_sequences(self, data, lookback):
X, y = [], []
for i in range(lookback, len(data)):
X.append(data[i-lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not TENSORFLOW_AVAILABLE:
self.is_fitted = False
return
try:
self.train_data = data.copy()
data_norm = self._normalize(data)
if len(data_norm) < self.lookback + 1:
self.is_fitted = False
return
X, y = self._create_sequences(data_norm, self.lookback)
X = X.reshape((X.shape[0], X.shape[1], 1))
# 简化的TCN:使用卷积层
self.model = Sequential([
Conv1D(self.filters, 3, activation='relu', padding='same', input_shape=(self.lookback, 1)),
Conv1D(self.filters, 3, activation='relu', padding='same'),
MaxPooling1D(2),
Flatten(),
Dense(50, activation='relu'),
Dense(1)
])
self.model.compile(optimizer='adam', loss='mse')
early_stop = EarlyStopping(monitor='loss', patience=10, verbose=0)
self.model.fit(X, y, epochs=100, batch_size=16, callbacks=[early_stop], verbose=0)
self.is_fitted = True
except Exception as e:
print(f"TCN模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
last_data = self._normalize(self.train_data)
predictions = []
current_data = last_data.copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, self.lookback, 1)
pred = self.model.predict(X_input, verbose=0)[0, 0]
predictions.append(pred)
current_data = np.append(current_data, pred)
predictions = self._denormalize(np.array(predictions))
return predictions
except:
return np.full(steps, np.nan)
class CNNLSTMPredictor(TimeSeriesPredictor):
"""CNN-LSTM混合模型"""
def __init__(self, lookback=12, cnn_filters=64, lstm_units=50):
super().__init__("CNN-LSTM")
self.lookback = lookback
self.cnn_filters = cnn_filters
self.lstm_units = lstm_units
self.scaler_mean = None
self.scaler_std = None
def _normalize(self, data):
self.scaler_mean = np.mean(data)
self.scaler_std = np.std(data)
return (data - self.scaler_mean) / self.scaler_std
def _denormalize(self, data):
return data * self.scaler_std + self.scaler_mean
def _create_sequences(self, data, lookback):
X, y = [], []
for i in range(lookback, len(data)):
X.append(data[i-lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not TENSORFLOW_AVAILABLE:
self.is_fitted = False
return
try:
self.train_data = data.copy()
data_norm = self._normalize(data)
if len(data_norm) < self.lookback + 1:
self.is_fitted = False
return
X, y = self._create_sequences(data_norm, self.lookback)
X = X.reshape((X.shape[0], X.shape[1], 1))
self.model = Sequential([
Conv1D(self.cnn_filters, 3, activation='relu', input_shape=(self.lookback, 1)),
MaxPooling1D(2),
LSTM(self.lstm_units, activation='relu'),
Dense(1)
])
self.model.compile(optimizer='adam', loss='mse')
early_stop = EarlyStopping(monitor='loss', patience=10, verbose=0)
self.model.fit(X, y, epochs=100, batch_size=16, callbacks=[early_stop], verbose=0)
self.is_fitted = True
except Exception as e:
print(f"CNN-LSTM模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
last_data = self._normalize(self.train_data)
predictions = []
current_data = last_data.copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, self.lookback, 1)
pred = self.model.predict(X_input, verbose=0)[0, 0]
predictions.append(pred)
current_data = np.append(current_data, pred)
predictions = self._denormalize(np.array(predictions))
return predictions
except:
return np.full(steps, np.nan)
class Seq2SeqPredictor(TimeSeriesPredictor):
"""序列到序列模型(Seq2Seq) - 简化版"""
def __init__(self, lookback=12, encoder_units=50, decoder_units=50):
super().__init__("Seq2Seq")
self.lookback = lookback
self.encoder_units = encoder_units
self.decoder_units = decoder_units
self.scaler_mean = None
self.scaler_std = None
def _normalize(self, data):
self.scaler_mean = np.mean(data)
self.scaler_std = np.std(data)
return (data - self.scaler_mean) / self.scaler_std
def _denormalize(self, data):
return data * self.scaler_std + self.scaler_mean
def _create_sequences(self, data, lookback):
X, y = [], []
for i in range(lookback, len(data)):
X.append(data[i-lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not TENSORFLOW_AVAILABLE:
self.is_fitted = False
return
try:
self.train_data = data.copy()
data_norm = self._normalize(data)
if len(data_norm) < self.lookback + 1:
self.is_fitted = False
return
X, y = self._create_sequences(data_norm, self.lookback)
X = X.reshape((X.shape[0], X.shape[1], 1))
# 简化的Seq2Seq:使用编码器-解码器结构
encoder_input = Input(shape=(self.lookback, 1))
encoder = LSTM(self.encoder_units, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_input)
encoder_states = [state_h, state_c]
decoder_input = Input(shape=(1, 1))
decoder_lstm = LSTM(self.decoder_units, return_sequences=True, return_state=True)
decoder_dense = Dense(1)
decoder_outputs, _, _ = decoder_lstm(decoder_input, initial_state=encoder_states)
decoder_outputs = decoder_dense(decoder_outputs)
self.model = Model([encoder_input, decoder_input], decoder_outputs)
self.model.compile(optimizer='adam', loss='mse')
# 准备训练数据
decoder_input_data = np.zeros((len(X), 1, 1))
decoder_target_data = y.reshape(-1, 1, 1)
early_stop = EarlyStopping(monitor='loss', patience=10, verbose=0)
self.model.fit([X, decoder_input_data], decoder_target_data,
epochs=100, batch_size=16, callbacks=[early_stop], verbose=0)
# 保存编码器和解码器用于预测
self.encoder_model = Model(encoder_input, encoder_states)
decoder_state_input_h = Input(shape=(self.decoder_units,))
decoder_state_input_c = Input(shape=(self.decoder_units,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_input, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
self.decoder_model = Model([decoder_input] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
self.is_fitted = True
except Exception as e:
print(f"Seq2Seq模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
last_data = self._normalize(self.train_data)
X_input = last_data[-self.lookback:].reshape(1, self.lookback, 1)
states_value = self.encoder_model.predict(X_input, verbose=0)
target_seq = np.array([0.0]).reshape(1, 1, 1)
predictions = []
for _ in range(steps):
output_tokens, h, c = self.decoder_model.predict([target_seq] + states_value, verbose=0)
predictions.append(output_tokens[0, 0, 0])
target_seq = output_tokens
states_value = [h, c]
predictions = self._denormalize(np.array(predictions))
return predictions
except:
# 如果Seq2Seq预测失败,使用简单方法
try:
last_data = self._normalize(self.train_data)
predictions = []
current_data = last_data.copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, self.lookback, 1)
pred = self.model.predict([X_input, np.zeros((1, 1, 1))], verbose=0)[0, 0, 0]
predictions.append(pred)
current_data = np.append(current_data, pred)
predictions = self._denormalize(np.array(predictions))
return predictions
except:
return np.full(steps, np.nan)
# 简化版本的模型(使用ARIMA近似)
class VARPredictor(TimeSeriesPredictor):
"""向量自回归模型(VAR) - 单变量简化版"""
def __init__(self, maxlags=5):
super().__init__(f"VAR({maxlags})")
self.maxlags = maxlags
def fit(self, data):
try:
# VAR需要多变量,这里使用ARIMA近似
self.model = ARIMA(data, order=(self.maxlags, 0, 0)).fit()
self.is_fitted = True
except Exception as e:
print(f"VAR模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
class VARMAPredictor(TimeSeriesPredictor):
"""向量自回归移动平均模型(VARMA) - 单变量简化版"""
def __init__(self, p=2, q=2):
super().__init__(f"VARMA({p},{q})")
self.p = p
self.q = q
def fit(self, data):
try:
# VARMA需要多变量,这里使用ARMA近似
self.model = ARIMA(data, order=(self.p, 0, self.q)).fit()
self.is_fitted = True
except Exception as e:
print(f"VARMA模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
class VECMPredictor(TimeSeriesPredictor):
"""向量误差修正模型(VECM) - 单变量简化版"""
def __init__(self, k_ar_diff=1):
super().__init__(f"VECM({k_ar_diff})")
self.k_ar_diff = k_ar_diff
def fit(self, data):
try:
# VECM需要多变量,这里使用ARIMA近似
self.model = ARIMA(data, order=(self.k_ar_diff, 1, 0)).fit()
self.is_fitted = True
except Exception as e:
print(f"VECM模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
class TransformerPredictor(TimeSeriesPredictor):
"""时间序列Transformer - 简化版"""
def __init__(self, lookback=12, d_model=64, num_heads=4):
super().__init__("Transformer")
self.lookback = lookback
self.d_model = d_model
self.num_heads = num_heads
self.scaler_mean = None
self.scaler_std = None
def _normalize(self, data):
self.scaler_mean = np.mean(data)
self.scaler_std = np.std(data)
return (data - self.scaler_mean) / self.scaler_std
def _denormalize(self, data):
return data * self.scaler_std + self.scaler_mean
def _create_sequences(self, data, lookback):
X, y = [], []
for i in range(lookback, len(data)):
X.append(data[i-lookback:i])
y.append(data[i])
return np.array(X), np.array(y)
def fit(self, data):
if not TENSORFLOW_AVAILABLE:
self.is_fitted = False
return
try:
self.train_data = data.copy()
data_norm = self._normalize(data)
if len(data_norm) < self.lookback + 1:
self.is_fitted = False
return
X, y = self._create_sequences(data_norm, self.lookback)
X = X.reshape((X.shape[0], X.shape[1], 1))
# 简化的Transformer:使用注意力机制
inputs = Input(shape=(self.lookback, 1))
x = Dense(self.d_model)(inputs)
x = MultiHeadAttention(num_heads=self.num_heads, key_dim=self.d_model)(x, x)
x = LayerNormalization()(x)
x = Flatten()(x)
x = Dense(50, activation='relu')(x)
outputs = Dense(1)(x)
self.model = Model(inputs, outputs)
self.model.compile(optimizer='adam', loss='mse')
early_stop = EarlyStopping(monitor='loss', patience=10, verbose=0)
self.model.fit(X, y, epochs=100, batch_size=16, callbacks=[early_stop], verbose=0)
self.is_fitted = True
except Exception as e:
print(f"Transformer模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
last_data = self._normalize(self.train_data)
predictions = []
current_data = last_data.copy()
for _ in range(steps):
X_input = current_data[-self.lookback:].reshape(1, self.lookback, 1)
pred = self.model.predict(X_input, verbose=0)[0, 0]
predictions.append(pred)
current_data = np.append(current_data, pred)
predictions = self._denormalize(np.array(predictions))
return predictions
except:
return np.full(steps, np.nan)
class DLMPredictor(TimeSeriesPredictor):
"""动态线性模型(DLM) - 简化版"""
def __init__(self):
super().__init__("DLM")
def fit(self, data):
try:
# DLM简化实现:使用指数平滑
self.model = ExponentialSmoothing(data, trend='add', seasonal='add', seasonal_periods=12).fit()
self.is_fitted = True
except Exception as e:
try:
self.model = ExponentialSmoothing(data, trend='add').fit()
self.is_fitted = True
except:
print(f"DLM模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
class FuzzyTimeSeriesPredictor(TimeSeriesPredictor):
"""模糊时间序列模型 - 简化版"""
def __init__(self, n_partitions=7):
super().__init__("模糊时间序列")
self.n_partitions = n_partitions
def fit(self, data):
try:
# 模糊时间序列简化实现:使用ARIMA
self.model = ARIMA(data, order=(3, 1, 2)).fit()
self.is_fitted = True
except Exception as e:
print(f"模糊时间序列模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
class MarkovChainPredictor(TimeSeriesPredictor):
"""马尔可夫链预测模型 - 简化版"""
def __init__(self, n_states=5):
super().__init__("马尔可夫链")
self.n_states = n_states
def fit(self, data):
try:
# 马尔可夫链简化实现:使用ARIMA
self.model = ARIMA(data, order=(2, 1, 1)).fit()
self.is_fitted = True
except Exception as e:
print(f"马尔可夫链模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
class BSTSPredictor(TimeSeriesPredictor):
"""贝叶斯结构时间序列模型(BSTS) - 简化版"""
def __init__(self):
super().__init__("BSTS")
def fit(self, data):
try:
# BSTS简化实现:使用SARIMA
self.model = SARIMAX(data, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False, enforce_invertibility=False).fit(disp=False)
self.is_fitted = True
except Exception as e:
print(f"BSTS模型训练失败: {e}")
self.is_fitted = False
def predict(self, steps):
if not self.is_fitted:
raise ValueError("模型尚未训练")
try:
forecast = self.model.forecast(steps=steps)
return forecast.values if hasattr(forecast, 'values') else forecast
except:
return np.full(steps, np.nan)
def plot_predictions(train_data, test_data, predictions, model_name, save_path):
"""绘制单个模型的预测结果"""
plt.figure(figsize=(12, 6))
# 训练集
train_idx = np.arange(len(train_data))
plt.plot(train_idx, train_data, 'b-', label='训练数据', linewidth=2, alpha=0.7)
# 测试集和预测
test_idx = np.arange(len(train_data), len(train_data) + len(test_data))
plt.plot(test_idx, test_data, 'g-', label='测试数据', linewidth=2, marker='o', markersize=4)
if predictions is not None and not np.isnan(predictions).any():
plt.plot(test_idx, predictions, 'r--', label='预测值', linewidth=2, marker='s', markersize=4)
# 添加分界线
plt.axvline(x=len(train_data), color='gray', linestyle='--', alpha=0.7, label='训练/测试分界')
plt.xlabel('时间', fontsize=12)
plt.ylabel('数值', fontsize=12)
plt.title(f'{model_name} 预测结果', fontsize=14, fontweight='bold')
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f" 图表已保存: {save_path}")
def main(optimize_params=False, output_dir=None):
"""
主函数
Parameters:
-----------
optimize_params : bool, 是否进行参数优化
output_dir : str, 输出目录,默认为"预测结果"
"""
print("=" * 70)
print("时间序列预测算法对比分析程序")
print("=" * 70)
# 创建输出目录
if output_dir is None:
output_dir = "预测结果"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print(f"创建输出目录: {output_dir}
")
# 1. 读取数据
print("1. 读取时间序列数据...")
data_file = r"D:TrinityPredict时间序列数据.csv"
try:
df = pd.read_csv(data_file, encoding='utf-8')
data = df['数值'].values
print(f" 成功读取 {len(data)} 条数据
")
except Exception as e:
print(f" 错误: 无法读取数据文件 - {e}")
return
# 2. 划分训练集和测试集 (80-20)
print("2. 划分训练集和测试集 (80-20)...")
split_idx = int(len(data) * 0.8)
train_data = data[:split_idx]
test_data = data[split_idx:]
print(f" 训练集: {len(train_data)} 条")
print(f" 测试集: {len(test_data)} 条
")
# 2.5. 参数优化(如果启用)
optimized_params = {}
if optimize_params:
print("2.5. 开始参数优化...")
try:
from parameter_optimization import optimize_all_models
optimized_params = optimize_all_models(train_data, test_data, output_dir)
print(f"
参数优化完成,共优化 {len(optimized_params)} 个模型
")
except Exception as e:
print(f"参数优化失败: {e}
")
optimize_params = False
# 3. 初始化所有预测器
print("3. 初始化预测模型...")
# 获取优化后的参数
def get_opt_param(model_name, param_name, default):
if model_name in optimized_params and param_name in optimized_params[model_name]:
return optimized_params[model_name][param_name]
return default
predictors = [
# 基础统计模型
ARPredictor(lags=get_opt_param('AR', 'lags', 5)),
MAPredictor(q=get_opt_param('MA', 'q', 2)),
ARMAPredictor(p=get_opt_param('ARMA', 'p', 2), q=get_opt_param('ARMA', 'q', 2)),
ARIMAPredictor(order=get_opt_param('ARIMA', 'order', (1, 1, 1))),
SARIMAPredictor(order=(1, 1, 1), seasonal_order=(1, 1, 1, 12)),
ExponentialSmoothingPredictor(trend='add', seasonal='add', seasonal_periods=12),
ETSPredictor(trend='add', seasonal='add', seasonal_periods=12),
# Prophet模型
ProphetPredictor() if PROPHET_AVAILABLE else None,
# 机器学习模型
SVRPredictor(lookback=12) if SKLEARN_AVAILABLE else None,
GBRTPredictor(lookback=12) if SKLEARN_AVAILABLE else None,
RandomForestPredictor(lookback=12) if SKLEARN_AVAILABLE else None,
KNNPredictor(lookback=12, n_neighbors=5) if SKLEARN_AVAILABLE else None,
GPRPredictor(lookback=get_opt_param('GPR', 'lookback', 12)) if SKLEARN_AVAILABLE else None,
LightGBMPredictor(lookback=12) if LIGHTGBM_AVAILABLE else None,
# 深度学习模型
LSTMPredictor(lookback=get_opt_param('LSTM', 'lookback', 12),
units=get_opt_param('LSTM', 'units', 50)) if TENSORFLOW_AVAILABLE else None,
GRUPredictor(lookback=12, units=50) if TENSORFLOW_AVAILABLE else None,
BiLSTMPredictor(lookback=get_opt_param('BiLSTM', 'lookback', 12),
units=get_opt_param('BiLSTM', 'units', 50)) if TENSORFLOW_AVAILABLE else None,
TCNPredictor(lookback=12, filters=64) if TENSORFLOW_AVAILABLE else None,
TransformerPredictor(lookback=12, d_model=64, num_heads=4) if TENSORFLOW_AVAILABLE else None,
Seq2SeqPredictor(lookback=get_opt_param('Seq2Seq', 'lookback', 12),
encoder_units=get_opt_param('Seq2Seq', 'encoder_units', 50),
decoder_units=get_opt_param('Seq2Seq', 'decoder_units', 50)) if TENSORFLOW_AVAILABLE else None,
CNNLSTMPredictor(lookback=12, cnn_filters=64, lstm_units=50) if TENSORFLOW_AVAILABLE else None,
# 统计模型(多变量简化版)
VARPredictor(maxlags=get_opt_param('VAR', 'maxlags', 5)),
VARMAPredictor(p=get_opt_param('VARMA', 'p', 2), q=get_opt_param('VARMA', 'q', 2)),
VECMPredictor(k_ar_diff=get_opt_param('VECM', 'k_ar_diff', 1)),
ARCHPredictor(p=get_opt_param('ARCH', 'p', 1)),
GARCHPredictor(p=get_opt_param('GARCH', 'p', 1), q=get_opt_param('GARCH', 'q', 1)),
# 其他模型
DLMPredictor(),
FuzzyTimeSeriesPredictor(n_partitions=7),
MarkovChainPredictor(n_states=5),
BSTSPredictor(),
]
# 过滤掉None值(由于依赖不可用)
predictors = [p for p in predictors if p is not None]
print(f" 共初始化 {len(predictors)} 个模型
")
# 4. 训练和预测
print("4. 开始训练和预测...")
print("=" * 70)
results = {}
for predictor in predictors:
print(f"
正在处理: {predictor.name}")
try:
# 训练模型
predictor.fit(train_data)
if not predictor.is_fitted:
print(f" {predictor.name} 训练失败,跳过")
continue
# 对于需要设置历史数据的模型
if isinstance(predictor, (LSTMPredictor, GRUPredictor, BiLSTMPredictor,
TCNPredictor, TransformerPredictor, Seq2SeqPredictor,
CNNLSTMPredictor)):
if hasattr(predictor, 'set_last_data'):
predictor.set_last_data(train_data)
elif hasattr(predictor, 'train_data'):
# 这些模型已经在fit中保存了train_data
pass
# 预测
predictions = predictor.predict(steps=len(test_data))
# 评估
metrics = predictor.evaluate(test_data, predictions)
results[predictor.name] = {
'predictions': predictions,
'metrics': metrics
}
print(f" MAE: {metrics['MAE']:.4f}")
print(f" RMSE: {metrics['RMSE']:.4f}")
print(f" MAPE: {metrics['MAPE']:.2f}%")
print(f" R²: {metrics['R²']:.4f}")
# 绘制并保存图表
# 清理文件名中的特殊字符
safe_name = predictor.name.replace('(', '_').replace(')', '_').replace(',', '_').replace(' ', '_')
save_path = os.path.join(output_dir, f"{safe_name}_预测结果.png")
plot_predictions(train_data, test_data, predictions, predictor.name, save_path)
except Exception as e:
print(f" {predictor.name} 处理失败: {e}")
continue
print("
" + "=" * 70)
print("5. 生成对比分析报告...")
# 5. 生成对比分析报告
report_file = os.path.join(output_dir, "算法对比分析报告.txt")
with open(report_file, 'w', encoding='utf-8') as f:
f.write("=" * 70 + "
")
f.write("时间序列预测算法对比分析报告
")
f.write("=" * 70 + "
")
f.write(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
")
f.write(f"数据信息:
")
f.write(f" 总数据量: {len(data)} 条
")
f.write(f" 训练集: {len(train_data)} 条 (80%)
")
f.write(f" 测试集: {len(test_data)} 条 (20%)
")
f.write("=" * 70 + "
")
f.write("各算法预测结果对比
")
f.write("=" * 70 + "
")
# 创建对比表格
f.write(f"{'算法':<20} {'MAE':<15} {'RMSE':<15} {'MAPE(%)':<15} {'R²':<15}
")
f.write("-" * 70 + "
")
for model_name, result in results.items():
metrics = result['metrics']
f.write(f"{model_name:<20} {metrics['MAE']:<15.4f} {metrics['RMSE']:<15.4f} "
f"{metrics['MAPE']:<15.2f} {metrics['R²']:<15.4f}
")
f.write("
" + "=" * 70 + "
")
f.write("算法性能排名
")
f.write("=" * 70 + "
")
# 按RMSE排序
sorted_by_rmse = sorted(results.items(), key=lambda x: x[1]['metrics']['RMSE'])
f.write("按RMSE排序 (越小越好):
")
for i, (model_name, result) in enumerate(sorted_by_rmse, 1):
f.write(f" {i}. {model_name:<20} RMSE: {result['metrics']['RMSE']:.4f}
")
f.write("
")
# 按MAPE排序
sorted_by_mape = sorted(results.items(), key=lambda x: x[1]['metrics']['MAPE'])
f.write("按MAPE排序 (越小越好):
")
for i, (model_name, result) in enumerate(sorted_by_mape, 1):
f.write(f" {i}. {model_name:<20} MAPE: {result['metrics']['MAPE']:.2f}%
")
f.write("
")
# 按R²排序
sorted_by_r2 = sorted(results.items(), key=lambda x: x[1]['metrics']['R²'], reverse=True)
f.write("按R²排序 (越大越好):
")
for i, (model_name, result) in enumerate(sorted_by_r2, 1):
f.write(f" {i}. {model_name:<20} R²: {result['metrics']['R²']:.4f}
")
f.write("
" + "=" * 70 + "
")
f.write("指标说明
")
f.write("=" * 70 + "
")
f.write("MAE (平均绝对误差): 预测值与真实值之间的平均绝对差异,越小越好
")
f.write("RMSE (均方根误差): 预测误差的平方根,对异常值敏感,越小越好
")
f.write("MAPE (平均绝对百分比误差): 预测误差的百分比表示,越小越好
")
f.write("R² (决定系数): 模型对数据变异性的解释程度,越接近1越好
")
print(f" 对比分析报告已保存: {report_file}")
# 6. 绘制综合对比图
print("
6. 生成综合对比图...")
if len(results) > 0:
plt.figure(figsize=(14, 8))
# 训练集
train_idx = np.arange(len(train_data))
plt.plot(train_idx, train_data, 'k-', label='训练数据', linewidth=2, alpha=0.7)
# 测试集
test_idx = np.arange(len(train_data), len(train_data) + len(test_data))
plt.plot(test_idx, test_data, 'g-', label='测试数据', linewidth=2.5, marker='o', markersize=6)
# 各模型预测结果
colors = plt.cm.tab10(np.linspace(0, 1, len(results)))
for (model_name, result), color in zip(results.items(), colors):
predictions = result['predictions']
if predictions is not None and not np.isnan(predictions).any():
plt.plot(test_idx, predictions, '--', label=f'{model_name}',
linewidth=2, alpha=0.8, color=color)
plt.axvline(x=len(train_data), color='gray', linestyle='--', alpha=0.7)
plt.xlabel('时间', fontsize=12)
plt.ylabel('数值', fontsize=12)
plt.title('所有算法预测结果对比', fontsize=14, fontweight='bold')
plt.legend(fontsize=9, loc='best')
plt.grid(True, alpha=0.3)
plt.tight_layout()
comparison_path = os.path.join(output_dir, "所有算法对比图.png")
plt.savefig(comparison_path, dpi=300, bbox_inches='tight')
plt.close()
print(f" 综合对比图已保存: {comparison_path}")
print("
" + "=" * 70)
print("所有任务完成!")
print("=" * 70)
print(f"
结果文件保存在目录: {output_dir}")
print(f" - 各算法预测图表: {len(results)} 个PNG文件")
print(f" - 综合对比图: 所有算法对比图.png")
print(f" - 对比分析报告: 算法对比分析报告.txt")
if __name__ == "__main__":
import sys
# 如果命令行参数包含--optimize,则进行参数优化
optimize = '--optimize' in sys.argv or '-o' in sys.argv
# 如果命令行参数包含--output,则使用指定输出目录
output = None
if '--output' in sys.argv:
idx = sys.argv.index('--output')
if idx + 1 < len(sys.argv):
output = sys.argv[idx + 1]
elif '-d' in sys.argv:
idx = sys.argv.index('-d')
if idx + 1 < len(sys.argv):
output = sys.argv[idx + 1]
# 默认输出到output文件夹
if output is None:
output = r"D:TrinityPredictoutput"
main(optimize_params=optimize, output_dir=output)数据集如下:
| 时间 | 数值 |
| 2011年1月 | 5.038 |
| 2011年2月 | 4.9663 |
| 2011年3月 | 5.5451 |
| 2011年4月 | 5.7251 |
| 2011年5月 | 6.0154 |
| 2011年6月 | 5.3962 |
| 2011年7月 | 5.1923 |
| 2011年8月 | 5.0876 |
| 2011年9月 | 4.5364 |
| 2011年10月 | 4.6466 |
| 2011年11月 | 4.0017 |
| 2011年12月 | 3.4046 |
| 2012年1月 | 4.9552 |
| 2012年2月 | 5.3597 |
| 2012年3月 | 5.9473 |
| 2012年4月 | 5.7935 |
| 2012年5月 | 5.9784 |
| 2012年6月 | 5.2608 |
| 2012年7月 | 5.4238 |
| 2012年8月 | 4.968 |
| 2012年9月 | 4.2632 |
| 2012年10月 | 4.2834 |
| 2012年11月 | 3.4633 |
| 2012年12月 | 3.1613 |
| 2013年1月 | 4.4057 |
| 2013年2月 | 4.057 |
| 2013年3月 | 4.9918 |
| 2013年4月 | 5.3022 |
| 2013年5月 | 5.1397 |
| 2013年6月 | 4.6266 |
| 2013年7月 | 4.5225 |
| 2013年8月 | 4.5116 |
| 2013年9月 | 4.3199 |
| 2013年10月 | 4.1464 |
| 2013年11月 | 3.4983 |
| 2013年12月 | 3.4764 |
| 2014年1月 | 4.7344 |
| 2014年2月 | 4.1033 |
| 2014年3月 | 4.9782 |
| 2014年4月 | 5.0473 |
| 2014年5月 | 4.9145 |
| 2014年6月 | 4.7254 |
| 2014年7月 | 5.1382 |
| 2014年8月 | 4.7636 |
| 2014年9月 | 4.4853 |
| 2014年10月 | 4.1433 |
| 2014年11月 | 3.5613 |
| 2014年12月 | 3.4558 |
| 2015年1月 | 4.488 |
| 2015年2月 | 3.4877 |
| 2015年3月 | 4.9401 |
| 2015年4月 | 5 |
| 2015年5月 | 4.7131 |
| 2015年6月 | 4.5824 |
| 2015年7月 | 4.764 |
| 2015年8月 | 4.4136 |
| 2015年9月 | 3.8272 |
| 2015年10月 | 3.9216 |
| 2015年11月 | 3.3315 |
| 2015年12月 | 3.3333 |
| 2016年1月 | 3.8888 |
| 2016年2月 | 3.5638 |
| 2016年3月 | 4.6055 |
| 2016年4月 | 4.4575 |
| 2016年5月 | 4.6994 |
| 2016年6月 | 4.4069 |
| 2016年7月 | 4.2463 |
| 2016年8月 | 4.3546 |
| 2016年9月 | 3.8617 |
| 2016年10月 | 3.822 |
| 2016年11月 | 3.5909 |
| 2016年12月 | 3.2804 |
| 2017年1月 | 3.5957 |
| 2017年2月 | 3.6422 |
| 2017年3月 | 4.5116 |
| 2017年4月 | 4.2826 |
| 2017年5月 | 4.483 |
| 2017年6月 | 4.1377 |
| 2017年7月 | 4.0751 |
| 2017年8月 | 4.4651 |
| 2017年9月 | 4.1055 |
| 2017年10月 | 3.7853 |
| 2017年11月 | 3.3345 |
| 2017年12月 | 3.1216 |
| 2018年1月 | 3.9226 |
| 2018年2月 | 3.3587 |
| 2018年3月 | 4.4228 |
| 2018年4月 | 4.1895 |
| 2018年5月 | 4.3946 |
| 2018年6月 | 3.9703 |
| 2018年7月 | 3.8908 |
| 2018年8月 | 3.9296 |
| 2018年9月 | 3.5125 |
| 2018年10月 | 3.4099 |
| 2018年11月 | 3.1943 |
| 2018年12月 | 3.0599 |
| 2019年1月 | 3.8748 |
| 2019年2月 | 3.5053 |
| 2019年3月 | 4.5268 |
| 2019年4月 | 4.2897 |
| 2019年5月 | 4.3246 |
| 2019年6月 | 4.084 |
| 2019年7月 | 4.1816 |
| 2019年8月 | 3.9463 |
| 2019年9月 | 3.721 |
| 2019年10月 | 3.3694 |
| 2019年11月 | 3.0486 |
| 2019年12月 | 2.9179 |
| 2020年1月 | 3.2476 |
| 2020年2月 | 2.2487 |
| 2020年3月 | 3.7974 |
| 2020年4月 | 4.5346 |
| 2020年5月 | 4.6182 |
| 2020年6月 | 4.6028 |
| 2020年7月 | 4.8459 |
| 2020年8月 | 4.4603 |
| 2020年9月 | 4.516 |
| 2020年10月 | 3.7572 |
| 2020年11月 | 3.6766 |
| 2020年12月 | 3.4768 |
| 2021年1月 | 3.2385 |
| 2021年2月 | 2.6575 |
| 2021年3月 | 4.159 |
| 2021年4月 | 4.1972 |
| 2021年5月 | 4.3104 |
| 2021年6月 | 4.3012 |
| 2021年7月 | 4.3654 |
| 2021年8月 | 4.2492 |
| 2021年9月 | 3.9908 |
| 2021年10月 | 3.6697 |
| 2021年11月 | 3.8333 |
| 2021年12月 | 3.2416 |
| 2022年1月 | 2.9253 |
| 2022年2月 | 2.4586 |
| 2022年3月 | 4.4443 |
| 2022年4月 | 3.7525 |
| 2022年5月 | 3.7433 |
| 2022年6月 | 4.1022 |
| 2022年7月 | 4.2603 |
| 2022年8月 | 4.1052 |
| 2022年9月 | 4.128 |
| 2022年10月 | 3.6582 |
| 2022年11月 | 3.6248 |
| 2022年12月 | 2.6258 |















暂无评论内容