
俗话说,好记性不如烂笔头。我习惯把工作中碰上的技术问题记录起来,定期整理。这样才不容易忘记做过的事情,能更好积累开发经验。
20250929:
今天发现mybatils有一个sleectKey功能,用于在insert操作后,将id回填到bean里面
<insert id="insert" parameterType="com.xxxx.PlayState">
<selectKey keyProperty="id" order="AFTER" resultType="java.lang.Integer">
SELECT LAST_INSERT_ID()
</selectKey>
INSERT INTO
xxx_play_state (site_id,node_id,play_state,message_state,project_id)
values
(#{siteId,jdbcType=INTEGER}, #{nodeId,jdbcType=BIGINT},
#{playState,jdbcType=INTEGER},#{messageState,jdbcType=INTEGER}, #{projectId,jdbcType=BIGINT})
</insert>
20250927:
今天发现idea的搜索功能很强劲,除了常规的区分大小写,整字搜索外,还支持正则(正则还支持负向断言排除指定内容)。搜索范围也可以指定本文件,多个文件,指定类型文件,忽略指定类型文件等选项。而且还支持结构化搜索:在搜索框右侧三个点按钮左边的漏斗按钮点开,可以设置查询范围为只包含字符串/注释或者不包含字符串/注释。
20250926:
今天用idea搜索出现了异常:在根目录下搜索某个关键字,出来的结果跟分别在多个子目录下搜索同样关键字的结果汇总不一样。在子目录下搜索结果会多许多。 尝试重启idea,并将重建索引没效。尝试过重新加载项目,也没效。最后试了一下文件菜单里面的修复IDE选项,按导航操作,最后有部分关键字搜索恢复正常,但还是有一些关键字有问题。分析了一下,有问题的关键字查找结果比较多,本来以为是idea的搜索功能有bug,当返回结果比较多时,不能正确完整显示。网上也有许多人反馈搜索结果不准,但他们都是使用”Invalidate Caches”就可以修复,我这个不行。但偶然间看到csdn上有个文章说:“IDEA全局搜索默认只展示100条”,并且介绍了配置修改方法:在高级设置找到“Maximum number of results to show in Find in Files/Show Usages preview”(中文版需要找对应的中文),默认值是100,可以根据自己需要改大点。
感觉idea这交互做得不友善,应该在超过100条的界面,提示用户只显示了前100条。不然用户会以为只有这么多或者以为搜索功能出现bug了。
今天发现系统代码有许多子类没有加上@ToString(callSuper = true)和@EqualsAndHashCode(callSuper = true)注解。本来以为是有问题量后面发现原来是使用了Lombok的全局配置功能加上这些注解的。Lombok 的全局配置需要通过一个名为 lombok.config 的文件来实现,这个文件可以放在项目的根目录、src/main/java 或 src/main/resources 等源码目录下(Lombok 会自动扫描项目中的 lombok.config 文件并应用配置)。
我们系统是这样配置的
config.stopBubbling = true
lombok.tostring.callsuper=CALL
lombok.equalsandhashcode.callsuper=CALL
lombok.accessors.chain=true
不过豆包说这样会导致非子类生成的equal和toString方法逻辑有错误,判断是相等的逻辑变成判断是否一样对象的逻辑,也不知道是不是真的。
20250915:
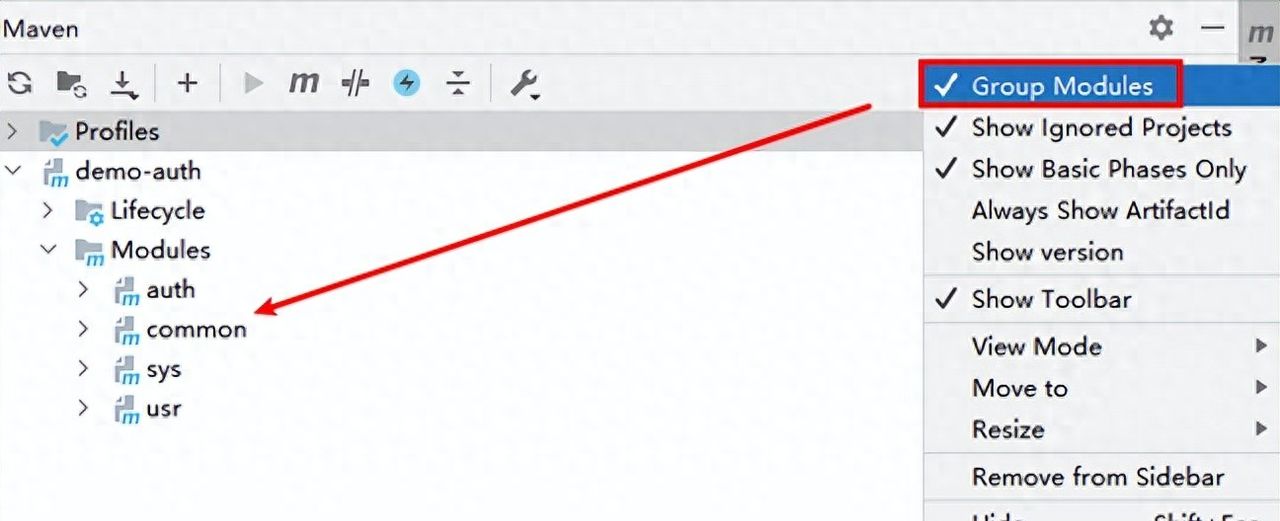
今天换了一台机,idea显示的maven项目结构出现异常。本来设计的 Maven 项目结构里,有一个父模块,下面应该包含两个子模块。正常来说,在 IDEA 的 Maven 窗口里,应该能看到父模块在上,两个子模块像分支一样显示在父模块的下面,形成一个包含关系。但目前的情况是,这三个模块都并排放在一起,子模块没有像预想的那样归在父模块下面,而是和父模块平级展示,看起来就像三个互不相关的独立模块。
查了半天,才发现可以修改显示方式,在Maven窗口右侧有一个竖排的三个点符号按钮,点击它,弹出菜单有 “Group Modules”(或 “按模块分组” )的选项,打上钩即可。
20250821:
今天才知道spring框架提供了RequestBodyAdvice 和 ResponseBodyAdvice,可以在这里截获所有请求和返回,对请求或者返回的bean或者http流进行处理,之前只知道可以用ResponseBodyAdvice做全局异常捕获,不知道它们功能这么强劲。在这里的http流可以重复读,不需要像过滤器一样,数据流读了就要重新包装一份。RequestBodyAdvice 和 ResponseBodyAdvice 是 Spring 中基于消息转换机制(HttpMessageConverter)的请求 / 响应增强接口,通过 @ControllerAdvice 全局生效。前者在请求体解析为 Java 对象的前 / 后介入,可实现解密、日志记录、参数预处理等;后者在响应对象转换为 JSON 等响应体前拦截,常用于统一响应格式、数据加密等,核心是在消息转换关键节点嵌入横切逻辑。
20250814:
今天跟同事讨论系统热备方案,同事提出定时拷贝mysql文件。我提了反对意见,由于拷贝动作不是原子性的,如果出现系统正好在写数据,可能会导致只拷了redo没拷表数据的情况。最后还是决定用mysqldump备份。 如果想用文件备份mysql,要么停机再拷文件,要么装个监控软件,反所有磁盘操作都复制一遍。不然就有可能出现备份文件损坏无法使用的情况。
20250813:
jenkins升级插件,重启后出现提示:“com.thoughtworks.xstream.mapper.CannotResolveClassException: com.michelin.cio.hudson.plugins.rolestrategy.RoleBasedAuthorizationStrategy”。按网上提议屏幕了权限插件后,进去系统发现许多任务丢失了。仔细看日志,发现这些出错的日志都是由于缺少插件导致识别失败。原来是我的jenkins版本太旧,插件升级后许多插件无法加载导致。 解决方法,把jenkins重大数据复制出来,下载新版本jenkins插件启动即可。
20250812:
在调试基于 Docker 部署的 Java 服务时,目标服务的 5383 端口被配置为远程 Debug 端口(JDWP 协议),出现了以下现象:
本地 IDE 能成功建立远程 Debug 连接,说明 5383 端口的 JDWP 服务正常,且网络路径允许 Debug 协议通信;
执行 netstat -antp | grep 5383 查看宿主机端口状态,仅显示 docker-proxy 进程在监听 5383 端口(LISTEN 状态),无任何 ESTABLISHED(已建立)的连接记录;
20250811:
idea总是不能正确识别maven项目,要么完全把maven项目当普通目录,无法正确识别源代码根目录,要么识别了项目,但认为jdk版本是1.5,。这里可以强制在pom里面加上build节点,然后重新加载即可正确识别。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<!-- 指定源版本,即使用的 Java 语言版本,这里设置为 1.8,表明使用 JDK 8 的语法 -->
<source>1.8</source>
<!-- 指定目标版本,即编译生成的字节码适配的 Java 运行环境版本,这里设置为 1.8,表明生成的字节码能在 JDK 8 及以上版本运行 -->
<target>1.8</target>
<!-- 可以根据需要添加额外的编译参数,列如开启更多的警告信息 -->
<compilerArgs>
<arg>-Xlint:all</arg>
</compilerArgs>
<!-- 可以指定编译器的路径,确保使用正确的 JDK 进行编译,若不指定,Maven 会使用系统环境变量中配置的 JDK -->
<!-- <compilerPath>C:Program FilesJavajdk1.8.0_91injavac</compilerPath> -->
</configuration>
</plugin>
</plugins>
</build>
(提议所有项目都加载一个根的pom,这样只需要在根pom修改即可)
20250810:
处于域环境的Windows电脑,访问未加入域的另一台电脑时,系统会自动强制带上当前域的前缀,即使手动输入“目标计算机名本地用户名”的格式,仍提示用户名或密码不正确。
可以在命令行里面,强制把目标机计算机的目录映射成网络磁盘访问,绕过这个限制。
net use H: 目标计算机D /USER:Administrator 目标计算机密码
20250809:
idea进行debug的一些小技巧:1 左侧的调用堆栈最上层可以删除,删除后会重新调用该函数。有时错过断点,可以用这个方法退回上个函数重新来,不用整个业务流程重跑。 2 在函数中按F8,可以跳到结束并显示返回值。3 如果某个表达式没赋值给变量,可以在watch窗口里面写上表达式查看值 4 lombok生成getter/setter的情况,可以在字段定义处加断点(显示成眼睛图标,与普通的断点不同),并且可以通过右键配置是访问断点还是修改断点 5 mapper接口函数也可以加断点,此时断点图标是菱形。(但我很少用,由于每次加这种断点服务就跑得很慢,不知道为什么)
20250808:
今天测试反馈一个bug,说分页查询没返回数据。由于不方便加断点,所以我用arthas跟踪了一下sql查询情况:
watch com.xxx.MediaBoxGroupMapper queryMediaBoxList “{params,returnObj}” -x 3
watch org.apache.ibatis.executor.statement.StatementHandler query ‘target.getBoundSql().getMappedStatement().getId(),target.getBoundSql().getSql(), target.getBoundSql().getParameterObject(), returnObj’ -x 3
跟踪发现查询结果有70条数据,但最终在页面还是没显示数据,也不知道啥情况。最后还是在本机上,通过断点跟踪,发现是由于
PageHelper.startPage(queryMediaBoxQO.getCurPage(), queryMediaBoxQO.getPageSize());
第一个参数是0,取的第0页
20250806:
IDEA 中 Java Compiler 配置(当前截图界面)和 Project Structure 里的配置,作用与生效范围有明显区别,以下详细拆解:
一、核心区别:作用层级与优先级
|
配置入口 |
作用范围 |
优先级 |
控制内容 |
|
Project Structure → Project |
全局项目级(所有模块继承) |
基础优先级(低 → 高) |
项目 SDK、语言级别(-source) |
|
Project Structure → Modules |
单个模块级(覆盖项目级) |
模块级(高于项目级) |
模块 SDK、依赖、源码目录 |
|
Java Compiler(当前界面) |
编译字节码版本(-target) |
编译参数级(最高) |
字节码版本、编译器选项 |
20250728:
今天有个前同事问我,java项目里面怎么对post请求的json报文进行md5较验的。他是用@RequestBody把请求映射到java对象的,之前进行md5较验的做法是将对象反序列化为json,再进行md5检查。但这样有时会由于json字段顺序与请求报文不一样导致md5较验制作 。我提议他加一个http filter,在请求时复制一份数据流,用拿到的原始数据源进行md5较验,这样就避免json转换对java对象,再转换回来与原报文有差异的风险。
20250726:
今天才知道有一种叫oql的语言:
OQL(对象查询语言)
OQL是用于查询Java堆的类SQL查询语言。OQL允许过滤/选择从Java堆中获取的信息。虽然HAT已经支持预定义的查询,例如“显示类X的所有实例”,但OQL增加了更多的灵活性。OQL基于JavaScript表达式语言。
可以把java堆栈信息当数据库一样,使用OQL语言进行查询:
select s from java.lang.String s where s.value.length >= 100
20250725:
1
在使用 Maven 架型(Archetype)生成子项目时,父级项目的 pom.xml 文件有时会被修改为非 UTF-8 编码(例如 GBK),导致文件内容出现乱码或其他问题。
解决方案
只需在执行 mvn archetype:generate 命令之前设置环境变量 JAVA_TOOL_OPTIONS 为 -Dfile.encoding=UTF-8,即可确保生成的文件保持 UTF-8 编码。
步骤
设置环境变量:
打开命令提示符,输入以下命令:
bash
深色版本
set JAVA_TOOL_OPTIONS=-Dfile.encoding=UTF-8
验证环境变量:
输入以下命令验证 JAVA_TOOL_OPTIONS 是否生效:
bash
深色版本
echo %JAVA_TOOL_OPTIONS%
应该输出 -Dfile.encoding=UTF-8。
2
脚手架工程里面的配置文件的注释里面有连续的#,maven根据脚手架生成的项目会把这些注释过滤掉(单#号不会出问题)
20250717:
前段时间入职时,上级交待任务说要做公司的“脚手架”,我一直以为是写一些util工具。今天才知道他说的是maven的脚本架。
豆包是这样介绍的:
Maven 脚手架就像项目的 “快速模板”,能帮你跳过手动建文件夹、写配置的麻烦,一键生成符合规范的项目结构。举两个简单例子:
列如你想搭一个普通 Java 项目,不用自己建src/main/java、src/test/java这些文件夹,只需在命令行输入:mvn archetype:generate -DgroupId=com.example -DartifactId=myjavaapp -DarchetypeArtifactId=maven-archetype-quickstart,回车后,脚手架就会自动生成完整的项目骨架,包括基础的pom.xml配置文件和一个简单的App.java主类。
再列如开发 Spring Boot 项目时,打开 Spring Initializr 网页(一个基于 Maven 的脚手架工具),选择 “Java”“Maven”“2.7.x”,勾选 “Web” 依赖,填写项目名,点击 “Generate”,就能下载一个包含Application.java启动类、pom.xml(已自动引入 Spring Web 依赖)的完整项目,解压后直接能用 IDE 打开运行,不用手动配任何基础依赖。
简单说,它就像外卖的 “套餐模板”,选好类型就能直接拿到搭配好的全套食材,不用自己买菜切菜,大大节省从头搭项目的时间。
20250715:
今天看项目代码,发现有些代码很长,跨行了不好看。研究了一下,才知道idea有自动换行阅读的功能:
IntelliJ IDEA 有自动换行阅读的功能,可通过开启 “软换行(Soft Wraps)” 功能来实现1。具体操作步骤如下:
1.进入设置界面。如果是 Windows 或 Linux 系统,点击菜单栏中的 “File”,选择 “Settings”;如果是 macOS 系统,点击菜单栏中的 “IntelliJ IDEA”,选择 “Preferences”。
2.在设置窗口中,导航到 “Editor”→“General”,找到 “Soft Wraps” 选项。
3.勾选 “Use soft wraps in editor” 即可启用代码自动换行。此外,还可以针对特定文件类型设置自动换行,只需点击 “Wrap text in:” 下拉框并选择对应的文件类型。
4.点击 “OK” 或 “Apply” 保存设置,之后代码就会根据编辑器窗口宽度自动换行,方便阅读长代码行。
另外,也可以在显示行数的位置右侧空白处右击,勾选 “Soft-Wrap”,来为当前脚本临时设置代码自动换行
20250714:
今天看到代码里面有用到@Import注解,学习了一下用法:“在配置类(标注 @Configuration 的类)上使用 @Import,主要是为了整合多个分散的配置类 —— 只需在主配置类上通过 @Import ({配置类 1.class, 配置类 2.class}) 导入其他配置类,Spring 容器就会自动加载这些被导入配置类中定义的 Bean,无需额外扫描。例如,主配置类 MainConfig 用 @Import 导入了 DbConfig(含数据源 Bean)和 MqConfig(含消息队列 Bean),容器就会同时管理这两个配置类及 MainConfig 自身的所有 Bean,实现配置的模块化整合。”
20250710:
今天看到某个模块里面有引用Lombok,但我的应用引用了这个模块,却一直报缺少Lombok。一开始不知道啥缘由,后来仔细看了,发现里面是这样引用的
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
这里<optional>true</optional> 表明该依赖不会传递给依赖当前项目的其他项目,所以我需要在应用里面额外再引用lombok才行
使用Lombok时需注意:IDE 需安装 Lombok 插件,否则可能出现idea编译或语法提示异常,但maven编译不报错的情况。
20250709:
今天看到代码里面有用到EnvironmentPostProcessor扩展,学习了一下才知道:EnvironmentPostProcessor 是 Spring Boot 的扩展接口,作用是在应用启动时,环境(Environment)初始化完成后、上下文刷新前,自定义环境配置(列如加载额外配置文件、动态添加参数等)。
它的生效时间很早,早于日志组件注入,在EnvironmentPostProcessor里面不能使用log输出日志
20250701:
今天编译时总报错:
Failed to execute goal on project xxx-demo-starter: Could not resolve dependencies for project com.xxx:xxx-demo-starter:jar:scene-4.0: Failed to collect dependencies at com.xxx:xxx-starter-web:j
ar:scene-4.0: Failed to read artifact descriptor for com.xxx:xxx-starter-web:jar:scene-4.0: Could not transfer artifact com.xxx:xxx-starter:pom:scene-4.0 from/to allow-all-http (http://0.0.0.0/): transfer failed for http://0.0.0.0/com/xxx/xxx-starter/scene-4.0/xxx-starter-scene-4.0.pom: Connect to 0.0.0.0:80 [/0.0.0.0] failed: Connection refused: connect -> [Help 1]
[ERROR]
Failed to read artifact descriptor for com.xxx:xxx-starter-web:jar:scene-4.0:
Could not transfer artifact com.xxx:xxx-starter:pom:scene-4.0
from/to allow-all-http (http://0.0.0.0/):
transfer failed for http://0.0.0.0/com/xxx/xxx-starter/scene-4.0/xxx-starter-scene-4.0.pom
让豆包分析了一下,说是:“Maven 在查找 xxx-starter-web 的依赖描述符(POM)时,第一需要其父项目 xxx-starter 的 POM。
本地仓库中可能缺少 xxx-starter 的 POM,导致 Maven 直接转向远程仓库。
远程请求被 allow-all-http 镜像拦截,导向无效地址 http://0.0.0.0/,最终失败。”
最后查了一下,是maven的settings.xml配置有问题。之前由于我们的仓库只支持http协议,不支持https,所以让豆包给我生成一个兼容的配置。它没生成好,虽然能用但埋了一些坑。我综合了多个ai的推荐,最终搞出来一个比较好的,让maven支持本地http协议仓库的 settings.xml:
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<!-- 本地仓库位置 -->
<localRepository>D:dev.m2
epository</localRepository>
<!-- 镜像配置(优先内部仓库,再阿里云) -->
<mirrors>
<!-- 内部Nexus仓库:优先匹配中央仓库和内部仓库 -->
<mirror>
<id>nexus-mirror</id>
<mirrorOf>nexus,central</mirrorOf>
<url>http://内部仓库ip:8081/repository/maven-public/</url>
</mirror>
<!-- 内部私有仓库:匹配xxx_public -->
<mirror>
<id>xxx-mirror</id>
<mirrorOf>xxx_public</mirrorOf>
<url>http://内部仓库ip:8081/repository/xxx_public/</url>
</mirror>
<!-- 阿里云仓库:作为外部 fallback -->
<mirror>
<id>aliyun-mirror</id>
<mirrorOf>aliyun,central</mirrorOf>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror>
</mirrors>
<!-- 仓库配置(与镜像ID对应) -->
<profiles>
<!-- 内部私有仓库 -->
<profile>
<id>xxx_public</id>
<repositories>
<repository>
<id>xxx_public</id>
<url>http://内部仓库ip:8081/repository/xxx_public/</url>
<releases>
<enabled>true</enabled>
<updatePolicy>daily</updatePolicy>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>xxx_public</id>
<url>http://内部仓库ip:8081/repository/xxx_public/</url>
<releases>
<enabled>true</enabled>
<updatePolicy>daily</updatePolicy>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</profile>
<!-- 内部Nexus仓库 -->
<profile>
<id>nexus</id>
<repositories>
<repository>
<id>nexus</id>
<url>http://内部仓库ip:8081/repository/maven-public/</url>
<releases>
<enabled>true</enabled>
<updatePolicy>daily</updatePolicy>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>interval:60</updatePolicy>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>nexus</id>
<url>http://内部仓库ip:8081/repository/maven-public/</url>
<releases>
<enabled>true</enabled>
<updatePolicy>daily</updatePolicy>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>interval:60</updatePolicy>
</snapshots>
</pluginRepository>
</pluginRepositories>
</profile>
<!-- 阿里云仓库 -->
<profile>
<id>aliyun</id>
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
<updatePolicy>daily</updatePolicy>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
<updatePolicy>daily</updatePolicy>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</profile>
</profiles>
<!-- 激活的仓库(内部优先,阿里云最后) -->
<activeProfiles>
<activeProfile>xxx_public</activeProfile>
<activeProfile>nexus</activeProfile>
<activeProfile>aliyun</activeProfile>
</activeProfiles>
<!-- 仓库认证信息(若需要) -->
<servers>
<server>
<id>xxx_public</id>
<username>内部仓库用户名</username>
<password>内部仓库密码</password>
</server>
</servers>
</settings>
20250624:
新公司项目不能在本机开发,调试时需要使用idea的远程调试功能。方法是先找出启动参数:例如-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5381 ,这里说明远程debug端口是5381,在idea里面添加远程debug,连接上这个端口就行。后在调试跟在本地一样。
20250620:
公司项目部署时需要依次执行多个jenkins项目,我有时会点了一个任务后,忘了等任务完成后点第二个。为此我写了一个聚合任务,可以实现完成一个任务后自动执行下一个jenkins任务:
pipeline {
agent any
// 设置失败后立即终止
options {
buildDiscarder(logRotator(numToKeepStr: '10'))
skipDefaultCheckout(true)
timeout(time: 60, unit: 'MINUTES')
}
parameters {
booleanParam(name: 'SKIP_COMMON', defaultValue: false, description: '跳过 xxx_common-dev')
booleanParam(name: 'SKIP_HUB_MANAGER', defaultValue: false, description: '跳过 iot_hub_manager-dev')
booleanParam(name: 'SKIP_ALLINONE', defaultValue: false, description: '跳过 iot-hub-allinone-dev')
}
stages {
stage('Execute xxx_common-dev') {
when {
expression { !params.SKIP_COMMON }
}
steps {
script {
try {
build job: 'xxx_common-dev', propagate: true
} catch (Exception e) {
echo "任务 xxx_common-dev 失败,终止后续任务"
currentBuild.result = 'FAILURE'
error("构建失败: ${e.message}")
}
}
}
}
stage('Execute iot_hub_manager-dev') {
when {
expression { !params.SKIP_HUB_MANAGER && currentBuild.result == null || currentBuild.result == 'SUCCESS' }
}
steps {
script {
try {
build job: 'iot_hub_manager-dev', propagate: true
} catch (Exception e) {
echo "任务 iot_hub_manager-dev 失败,终止后续任务"
currentBuild.result = 'FAILURE'
error("构建失败: ${e.message}")
}
}
}
}
stage('Execute iot-hub-allinone-dev') {
when {
expression { !params.SKIP_ALLINONE && currentBuild.result == null || currentBuild.result == 'SUCCESS' }
}
steps {
script {
try {
build job: 'iot-hub-allinone-dev', propagate: true
} catch (Exception e) {
echo "任务 iot-hub-allinone-dev 失败"
currentBuild.result = 'FAILURE'
error("构建失败: ${e.message}")
}
}
}
}
}
post {
success {
echo '所有任务执行成功'
}
failure {
echo '构建过程中出现错误,任务终止'
}
always {
cleanWs()
}
}
}
20260627:
今天第一次使用git tag功能:为了提测一个大规模重构过的版本,需要原来我们项目的test分支删除,按开发分支重建,删除之前使用git tag备份一下。豆包是这样介绍的:“Git Tag 就像是给代码仓库里的重大版本 “盖个章”,列如给正式发布的 “v1.0.0 版本”“v2.1 测试版” 做个标记,一眼就能找到这些关键节点。它特别实用的是,就算当初存放这个版本的分支被删了,只要这个 “印章” 还在,就能随时通过它找回对应的代码。不管是团队协作时标记发布版本,还是自己回头查旧版本,有了它,找代码就像翻带标签的笔记本一样方便。”
20260626:
今天用豆包写了一个方便进入容器里面调用arthas的脚本:
#!/bin/bash
# 用户可自定义配置
TARGET_USER="dev" # 默认目标用户
ROOT_USER="root" # 超级用户
ARTHAS_JAR="/root/hch/arthas/arthas-boot.jar" # Arthas启动器路径
DOWNLOAD_DIR="/tmp" # 下载目录
# 颜色定义
RED='33[0;31m'
GREEN='33[0;32m'
YELLOW='33[0;33m'
NC='33[0m' # 恢复默认颜色
# 检查docker命令是否存在
if ! command -v docker &> /dev/null
then
echo -e "${RED}错误: 未找到docker命令,请确保已安装Docker。${NC}"
exit 1
fi
# 检查arthas-boot.jar是否存在,不存在则下载到/tmp
if [ ! -f "$ARTHAS_JAR" ]; then
echo -e "${YELLOW}警告: 未找到Arthas启动器 ($ARTHAS_JAR),尝试下载到$DOWNLOAD_DIR...${NC}"
# 确保下载目录存在
mkdir -p "$DOWNLOAD_DIR"
# 下载到临时目录
TMP_JAR="$DOWNLOAD_DIR/arthas-boot.jar"
wget -q https://arthas.aliyun.com/arthas-boot.jar -O "$TMP_JAR" || {
echo -e "${RED}错误: 下载Arthas失败,请手动下载并放在$ARTHAS_JAR。${NC}"
exit 1
}
# 复制到目标路径
mkdir -p "$(dirname "$ARTHAS_JAR")"
cp "$TMP_JAR" "$ARTHAS_JAR" || {
echo -e "${RED}错误: 复制Arthas到目标路径失败。${NC}"
exit 1
}
echo -e "${GREEN}Arthas启动器下载并复制成功。${NC}"
fi
echo -e "${GREEN}=== 正在列出所有Docker容器 ===${NC}"
# 获取容器列表并添加编号
container_list=$(docker ps -a --format "{{.ID}} {{.Names}} {{.Image}} {{.Status}}")
container_count=$(echo "$container_list" | wc -l)
if [ "$container_count" -eq 0 ]; then
echo -e "${RED}错误: 未找到任何Docker容器。${NC}"
exit 1
fi
echo -e "${YELLOW}编号 容器ID 容器名称 镜像 状态${NC}"
echo "$container_list" | awk '{print NR " " $0}'
echo
# 获取用户选择
read -p "请输入要调试的容器编号 (1-$container_count): " selection
# 验证选择是否为有效数字
if ! [[ "$selection" =~ ^[0-9]+$ ]]; then
echo -e "${RED}错误: 请输入有效的数字编号。${NC}"
exit 1
fi
# 验证选择是否在有效范围内
if [ "$selection" -lt 1 ] || [ "$selection" -gt "$container_count" ]; then
echo -e "${RED}错误: 选择的编号超出范围 (1-$container_count)。${NC}"
exit 1
fi
# 获取选中的容器名称
selected_container=$(echo "$container_list" | sed -n "${selection}p" | awk '{print $2}')
echo -e "${GREEN}=== 你选择了容器: ${selected_container} ===${NC}"
# 确认容器是否运行中
container_status=$(echo "$container_list" | sed -n "${selection}p" | awk '{print $4, $5}')
if ! echo "$container_status" | grep -q "Up"; then
echo -e "${YELLOW}警告: 所选容器未运行 (状态: ${container_status}),可能无法正常使用Arthas。${NC}"
read -p "是否继续? (y/n): " confirm
if [ "$confirm" != "y" ] && [ "$confirm" != "Y" ]; then
echo -e "${YELLOW}操作已撤销。${NC}"
exit 0
fi
fi
echo -e "${GREEN}=== 正在将arthas-boot.jar复制到容器中 ===${NC}"
docker cp "$ARTHAS_JAR" "$selected_container":/arthas-boot.jar || {
echo -e "${RED}错误: 复制文件失败,请确保容器支持文件操作。${NC}"
exit 1
}
echo -e "${GREEN}=== 检查容器内Java进程 ===${NC}"
# 优化:使用非交互式模式执行ps命令,并过滤掉grep自身
java_process_info=$(docker exec -u "$TARGET_USER" "$selected_container" /bin/bash -c "ps -ef | grep '[j]ava' | grep -v grep | grep -v grep")
has_java_process=false
java_process_user=""
if [ -n "$java_process_info" ]; then
has_java_process=true
# 确保至少有2个字段(用户和PID)
if echo "$java_process_info" | awk '{print NF}' | grep -q "^[2-9]" ; then
java_process_user=$(echo "$java_process_info" | awk '{print $1}')
echo -e "${GREEN}找到Java进程,运行用户: $java_process_user${NC}"
else
echo -e "${YELLOW}警告: 检测到异常进程信息,可能无Java进程${NC}"
has_java_process=false
fi
else
echo -e "${YELLOW}警告: 容器内未找到Java进程${NC}"
read -p "是否继续进入容器? (y/n): " confirm
if [ "$confirm" != "y" ] && [ "$confirm" != "Y" ]; then
echo -e "${YELLOW}操作已撤销。${NC}"
exit 0
fi
fi
echo -e "${GREEN}=== 准备启动Arthas ===${NC}"
echo -e "${YELLOW}注意: 进入容器后,执行以下命令启动Arthas:${NC}"
echo -e "${YELLOW}cd / && java -jar /arthas-boot.jar${NC}"
echo -e "${YELLOW}如果无法连接,请尝试执行:"'pid=1 ;
touch /proc/${pid}/cwd/.attach_pid${pid} &&
kill -SIGQUIT ${pid} &&
sleep 2 &&
ls /proc/${pid}/root/tmp/.java_pid${pid}'
# 决定进入容器的用户
if $has_java_process && [ "$java_process_user" = "$TARGET_USER" ]; then
login_user="$TARGET_USER"
else
login_user="$ROOT_USER"
if $has_java_process; then
echo -e "${YELLOW}提示: Java进程由$java_process_user用户运行,将以$ROOT_USER用户进入容器${NC}"
else
echo -e "${YELLOW}提示: 未确认Java进程用户,将以$ROOT_USER用户进入容器${NC}"
fi
fi
# 进入容器(优化错误处理)
echo -e "${GREEN}=== 正在以 $login_user 用户进入容器 ===${NC}"
echo -e "${YELLOW}提示: 输入 'exit' 退出容器${NC}"
echo -e "${YELLOW}提示: 在Arthas中输入 'exit' 或 'stop' 可正常退出${NC}"
# 使用exec调用,避免子shell影响返回码
if ! docker exec -u "$login_user" -it "$selected_container" /bin/bash; then
# 仅在非零返回码且非交互退出时显示错误
if [ $? -ne 0 ]; then
echo -e "${RED}错误: 无法以 $login_user 用户进入容器。${NC}"
if [ "$login_user" = "$ROOT_USER" ]; then
echo -e "${YELLOW}尝试以$TARGET_USER用户进入...${NC}"
if ! docker exec -u "$TARGET_USER" -it "$selected_container" /bin/bash; then
echo -e "${RED}错误: 无法进入容器。请检查容器是否运行或用户权限是否正确。${NC}"
echo -e "${YELLOW}你可以手动执行: docker exec -u $TARGET_USER -it $selected_container /bin/bash${NC}"
exit 1
fi
else
echo -e "${YELLOW}你可以手动执行: docker exec -u $login_user -it $selected_container /bin/bash${NC}"
exit 1
fi
fi
fi
# 正常退出时不显示错误
echo -e "${GREEN}=== 已正常退出容器 ===${NC}"
exit 0
20250618:
系统里面的表id是使用mybatis plus的雪花算法生成的,但今天由于手工修复数据缘由,需要在insert之外场景获取id,问了豆包才知道 ,可以使用“ID_GENERATOR.nextId(null);”
20250617:
今天写了一个新的数据库实体类,没加上@TableId的注解,但奇怪的是插入数据库里,mybatis-plus依旧会自动给我填上一个雪花算法的id
查了一下,说是默认认为名字为id的字段是主键。没想到mybatis plus这么智能
20250616:
项目上一台机器,有时会突然出现cpu飙升的情况。排查异常时,由于缺少历史数据,不方便定位。今天在我推荐下,打算给安装“Prometheus 普罗米修斯”监控,把数据采集到Grafana,这样后面再出现故障时有历史数据,可以更清楚故障发生过程。
普罗米修斯 exporter架构 普罗米修斯 运维工具_mob64ca1410eb61的技术博客_51CTO博客
20250614:
今天发现项目的redis容器是有开启持久化的,感觉会有隐患。之前我碰上过断电后重启,持久化文件损坏,导致redis无法启动的情况。 后来我们重新打了一个redis镜像,启动前检查redis持久化文件有没有异常,如果有要删除才继续启动。
20250613:
今天发现项目的swagger界面很好看,比以前公司的swagger界面好许多。仔细研究了一下,原来是用了knife4j-spring-boot-starter,这是一个swagger增强组件。
20250612:
rsa加密,默认生成的密文是随机的。 所以如果要进行签名验证,不能直接使用密文较验,需要解密后检查原文是否匹配。
20250608:
新公司的项目分许多模块,每个模块在不同git仓库。我一开始看代码时是用idea分别打开不同仓库,但这样跳转代码不方便。由于有时代码调用是跨模块的。后来研究了一下,发现有两个改善方法:1 通过idea的import功能,把其它目录的模块导入到当前项目里面 2 把所有项目放在一个统一的目录下,用idea打开顶层目录。 我目前用的是方法2
程序员的进阶路上,经验从来不是负担。
关注我,跟你分享一个资深物联网应用开发者的见闻。
✨ 点击关注,不错过更多实战干货 ✨




















暂无评论内容