
无线电发射机输出的射频信号功率,通过馈线(电缆)输送到天线,由天线以电磁波形式辐射出去。电磁波到达接收地点后,由天线接下来(仅仅接收很小很小一部分功率),并通过馈线送到无线电接收机。可见,天线是发射和接收电磁波的一个重大的无线电设备,没有天线也就没有无线电通信.
讲天线之前,我们先来理解几个概念。
无线电波:是一种能量传输形式,在传播过程中,电场和磁场在空间是相互垂直的,同时这两者又都垂直于传播方向。
导行波:由传输线所引导的,能沿必定方向传播的电磁波。
- 天线的概念
- 定义:能够有效地向空间某特定方向辐射电磁波或能够有效地接收空间某特定方向来的电磁波的装置。
- 功能:能量转换-导行波和自由空间波的转换;
- 定向辐射(接收)-具有必定的方向性。
- 问题:天线是否具有放大作用呢? ——大家可以在评论区留言哦!
- 天线的辐射原理
- 根据C(光速)=f(频率)×λ(波长) 得出波长与频率成反比
- 频率越低,波长越长,天线越大
- 当导线载有交变电流时,就可以形成电磁波的辐射;
- 如果两导线的距离很近,导线中电流方向相反,感应电动势相互抵消,因此辐射很微弱;
- 如果将两导线张开,由于两导线的电流方向一样,辐射较强;
- 当导线的长度可与波长相比拟时,导线上的电流就大大增加,因而就能形成较强的辐射;
- 一般将上述能产生显著辐射的直导线称为振子;
- 两臂长度均为1/4波长的振子叫做对称半波振子。
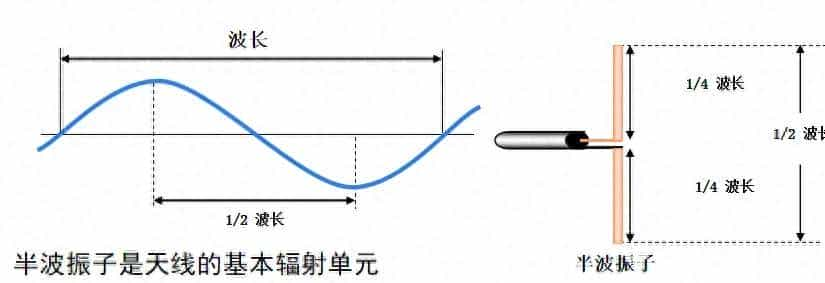
第一、半波振子天线的方向图是“8”字形,无副瓣,在一般性应用中,有必定优势。
第二、半波振子在输入端,电流是波腹点,输入阻抗是73.1+J42.5欧姆,通过必定的调节,容易实现谐振,能使输入阻抗为纯电阻,且易与特性阻抗为50欧姆的馈电网络匹配。
第三、当长度超过半波长时,线上出现反相电流,使得天线的方向性下降,增益降低。
常见的半波振子:


3.天线的主要性能和参数
3.1天线的方向性系数
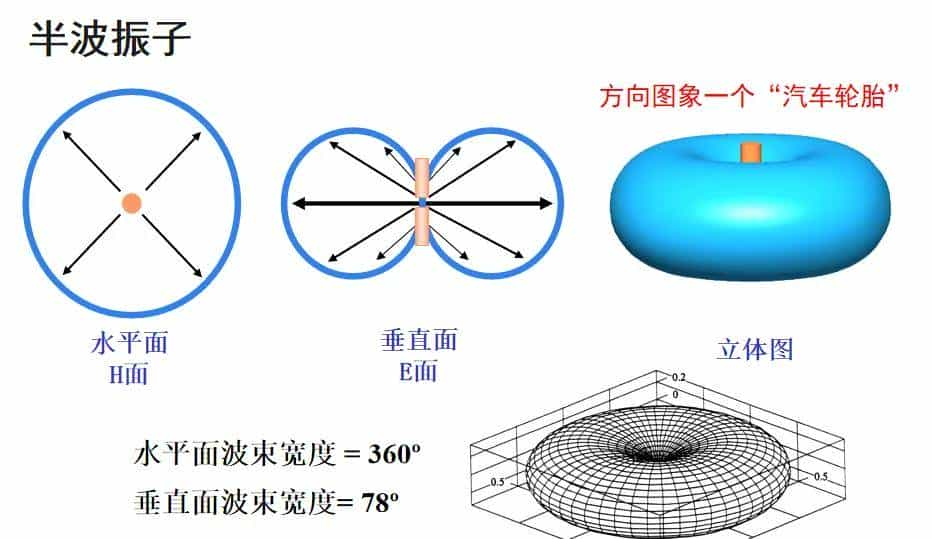
天线的方向特性可以用方向图来描述,一般以方向性系数表明天线辐射电磁波能量的聚焦程度。其定义是:在同样的辐射功率时,有方向性天线在最大辐射方向远区某点的功率通量密度(单位面积上通过的电场功率,正比于电场强度的平方)与无方向性天线在该点的功率通量密度之比,用于描述天线在特定方向上的能力聚焦的程度,用D来表明。
注:无方向性天线,一般指点源各向同性天线,其方向图为球形。

3.2天线的增益
天线的增益:G=η×D
其中,η和D分别是该天线的效率和方向性系数,对于驻波良好的天线η接近1,可以认为天线的增益与天线的方向性系数在数值上是相等的。
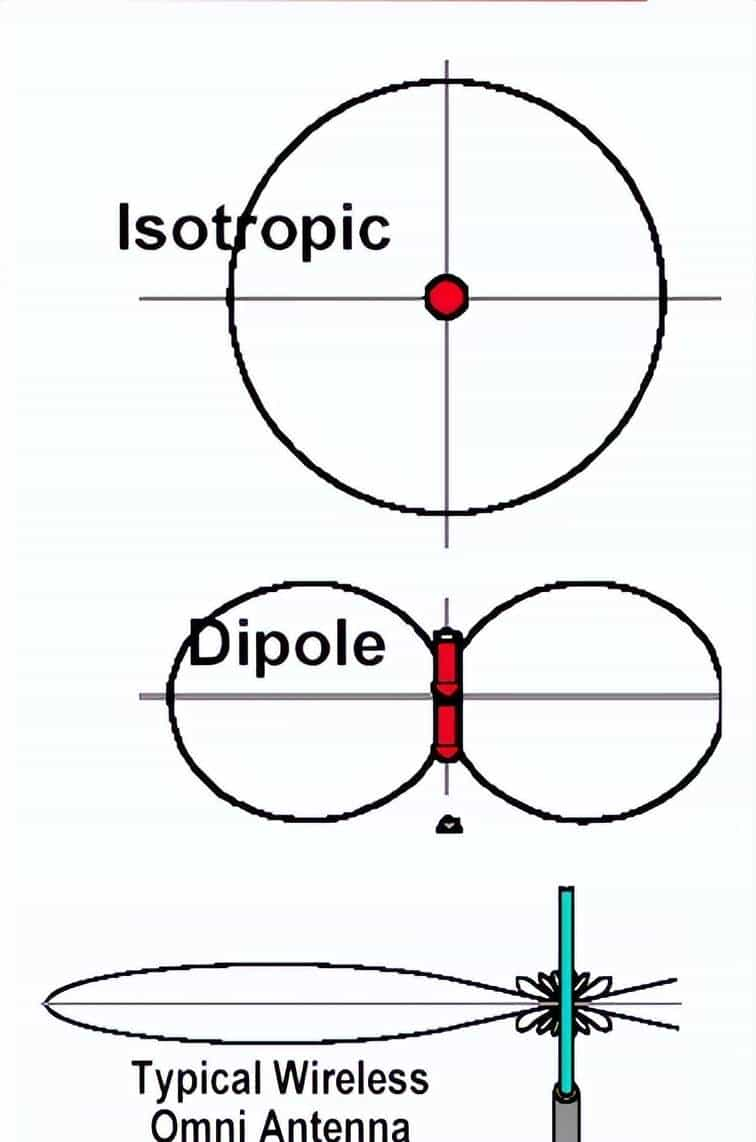
当用点源天线作为标准时,所得到的增益往往被称为天线的绝对增益用dBi表明。dBi定义为实际的方向性天线(包括全向天线)相对于各向同性天线能量聚焦的相对能力,“i”即表明各向同性——Isotropic。
当用半波振子作为标准时,所得到的增益被称为天线的相对增益,用dBd表明,两者相差2.15dB(1.64倍)。dBd定义为实际的方向性天线(包括全向天线)相对于半波阵子天线能量聚焦的相对能力,“d”即表明偶极子——Dipole。
即:dBi-dBd=2.15dB
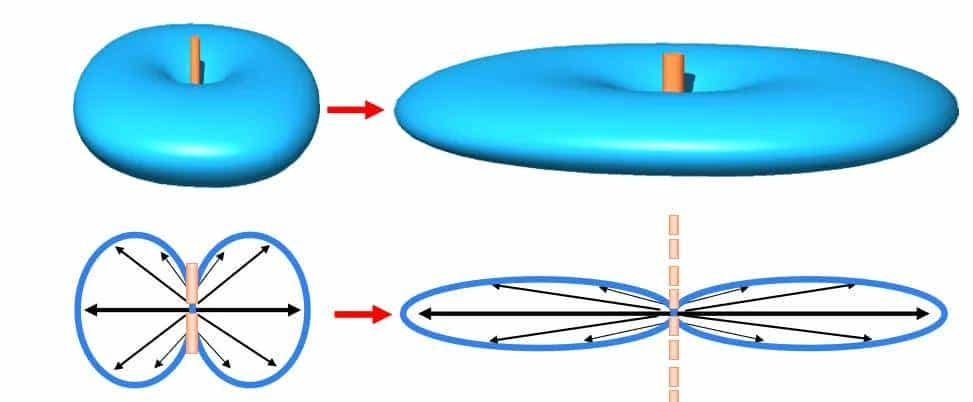
增益、方向图和天线尺寸之关系
将“轮胎”压扁,信号就越聚焦,增益就越高,天线尺寸就越大。
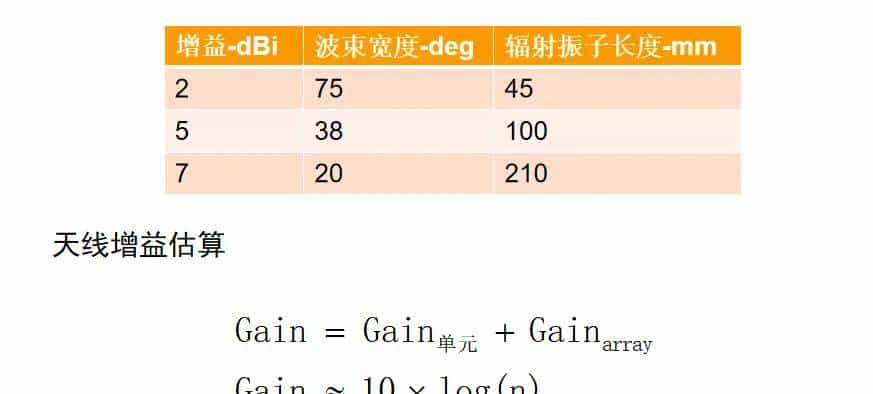
天线增益的几个要点:
天线是无源器件,不能产生能量。天线增益只是将能量有效聚焦向某特定方向辐射或接受电磁波的能力。
天线的增益由振子叠加而产生。增益越高,天线长度越长。增益每提高3dB,天线体积变大一倍。
天线增益越高,方向性越好,能量越聚焦,波瓣越窄。
3.3天线的驻波,反射系数,回波损耗
天线是有效的将传输线送来的高频传导电流转变为空间的电磁波,或者反过来将空间的电磁波转变为传输线中的信号功率。
移动通信系统中,常用的馈线特性阻抗是:50Ω。因此,常用的天线特性阻抗也必须是50Ω;但由于天线是频变器件及天线特性随着频率变化的特性比较明显,必须有一个指标来描述天线阻抗和特性阻抗偏离程度。
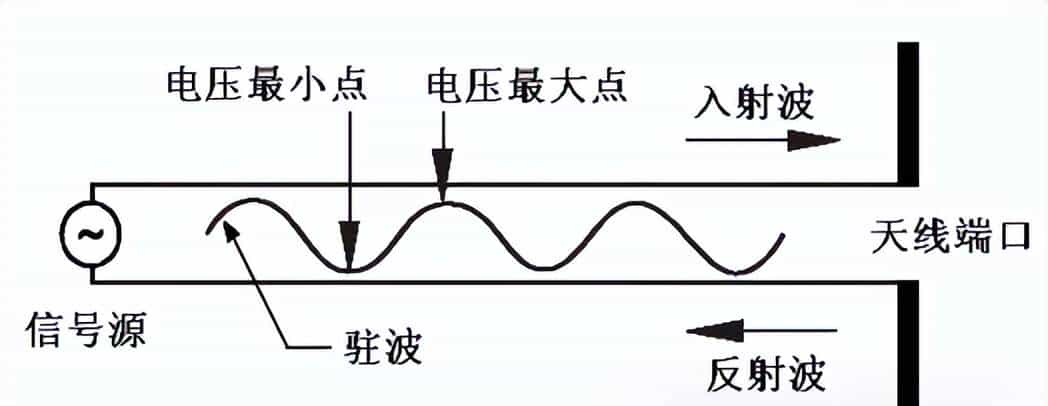
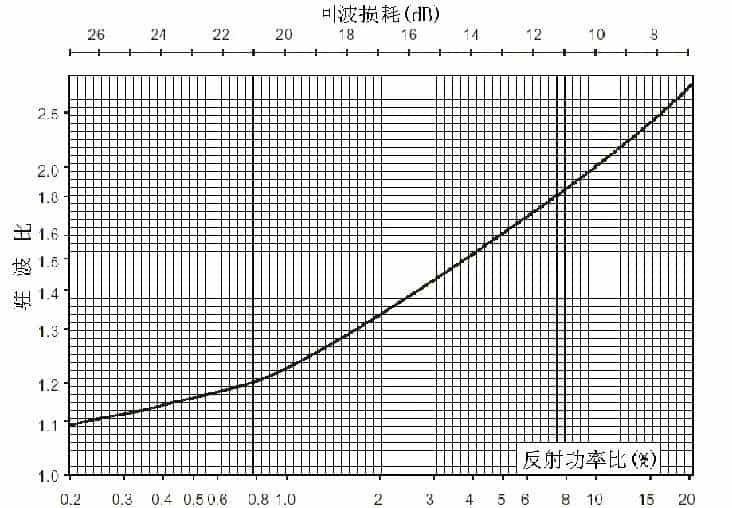
实际上对阻抗的偏差要规定一个容限,其表明方法是驻波比,驻波比即用来描述相当于标称值的偏差程度。
驻波比也即电压驻波比,简写为VSWR,它定义为该端点上电压最大值与电压最小值之比,显然,电压最大值为入射波与反射波之复数模相加,而电压最小值为入射波和反射波的复数模相减。
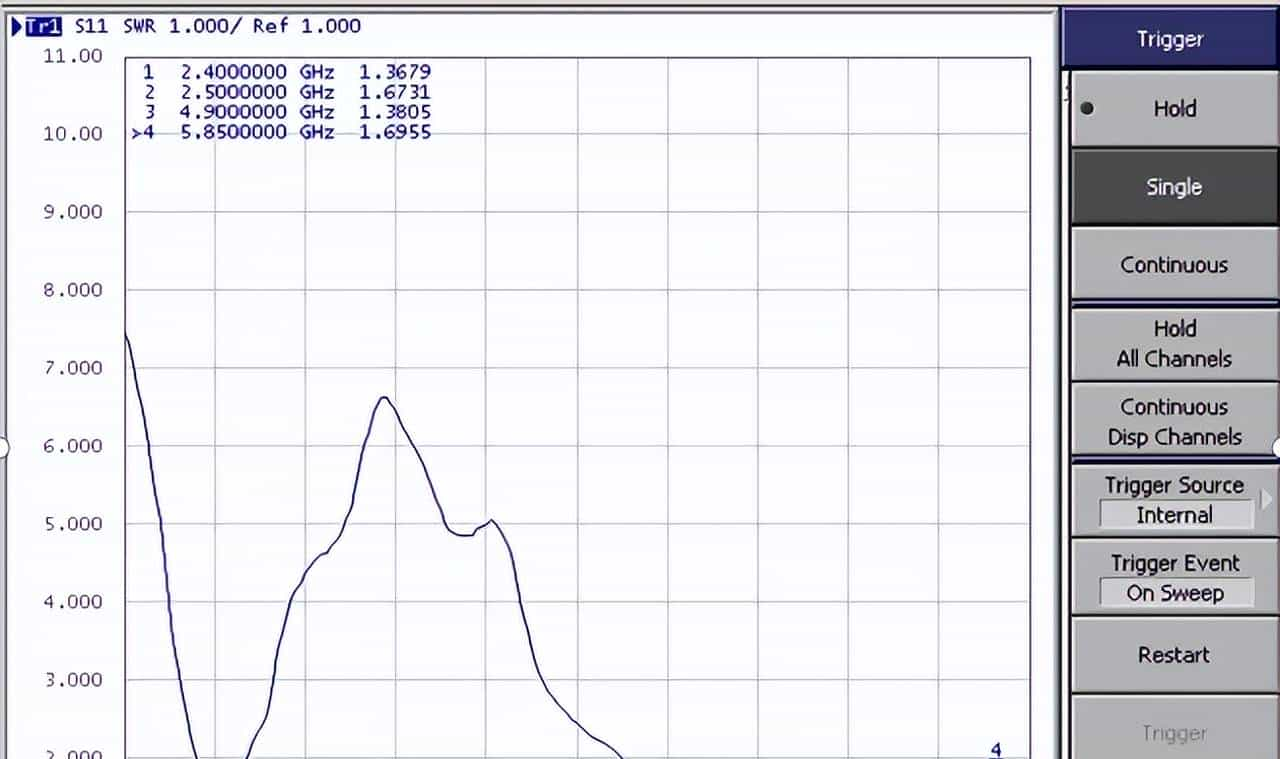
一般,工程上要求天线的VSWR≤2,部分多频和宽频带天线需要放宽驻波指标。如下为网分实测的天线VSWR。
由于天线和传输线之间的阻抗存在匹配,因此,存在反射波,反射波与入射波之比称为反射系数Γ,Γ为一复数。
电压驻波比VSWR和反射系数Γ之间的关系为:
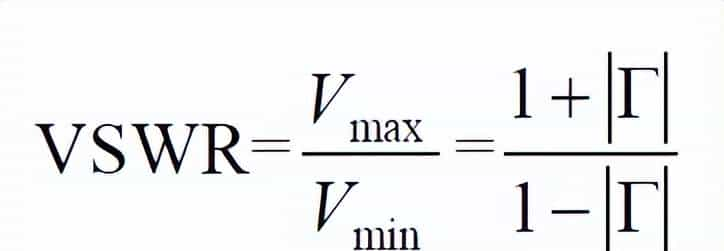
反射系数复模的对数分贝值即回波损耗RL
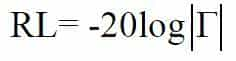
反射系数复模的平方即为反射功率比
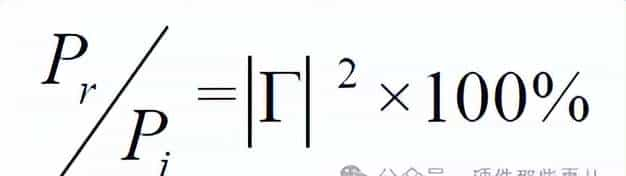
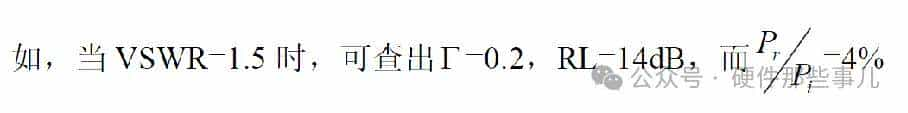
3.4.天线极化
极化”是指电场强度矢量在空间运动的轨迹或变化的状态。一般电场强度矢量末端在空间的运动轨迹是一个椭圆,所以我们定义这种天线的极化为椭圆极化。
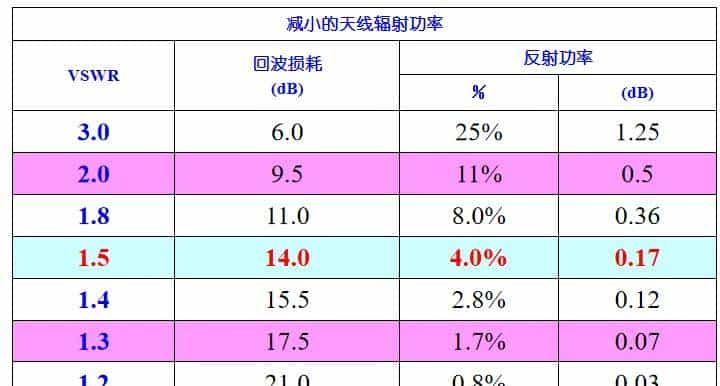
特殊情况当x向和y向的电场强度矢量等幅同相是电场末端轨迹为圆,称为圆极化。当电场强度矢量等幅反向是电场末端轨迹为线,称为线极化。
当线极化的方向与地面垂直时,称为垂直极化。在通信系统中,天线一般采用垂直极化。
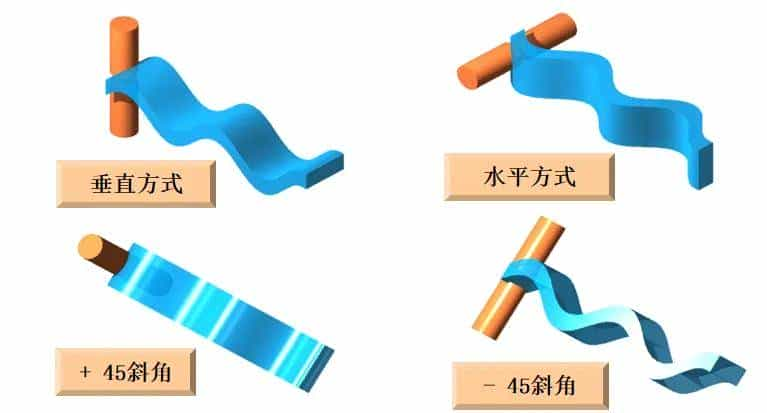
说明:垂直极化波要用具有垂直极化特性的天线来接收,水平极化波要用具有水平极化特性的天线来接收。右旋圆极化波要用具有右旋圆极化特性的天线来接收,而左旋圆极化波要用具有左旋圆极化特性的天线来接收.当来波的极化方向与接收天线的极化方向不一致时,接收到的信号都会变小,也就是说,发生极化损失。
3.5天线的方向图
3.5.1波束(波瓣)宽度
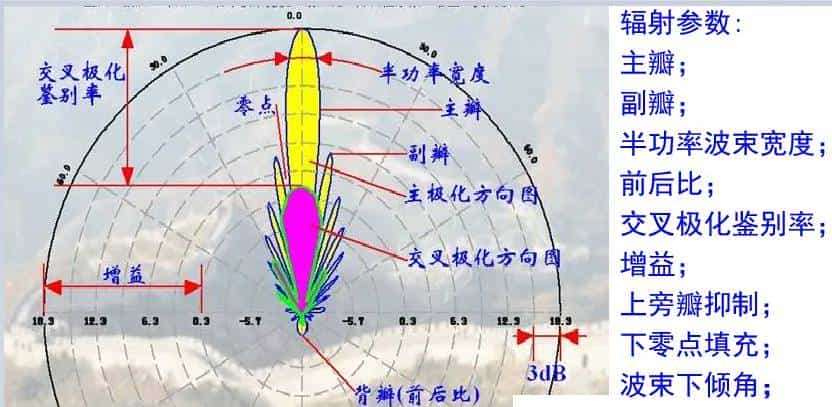
下图中一般都有两个瓣或多个瓣,其中最大的瓣称为主瓣,其余的瓣称为副瓣。主瓣两半功率点间的夹角定义为天线方向图的波瓣宽度。称为半功率(角)瓣宽。主瓣瓣宽越窄,则方向性越好,抗干扰能力越强。
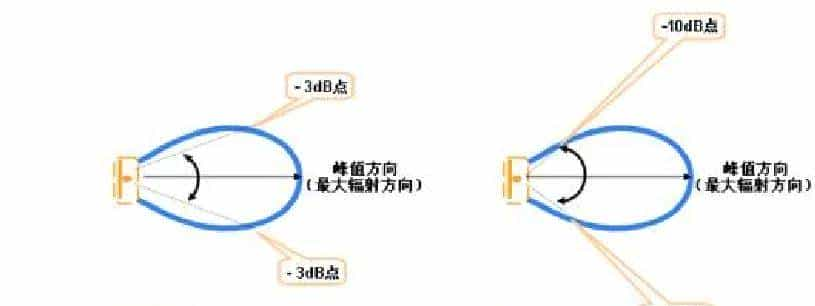
3.5.2旁瓣抑制、波束下倾角
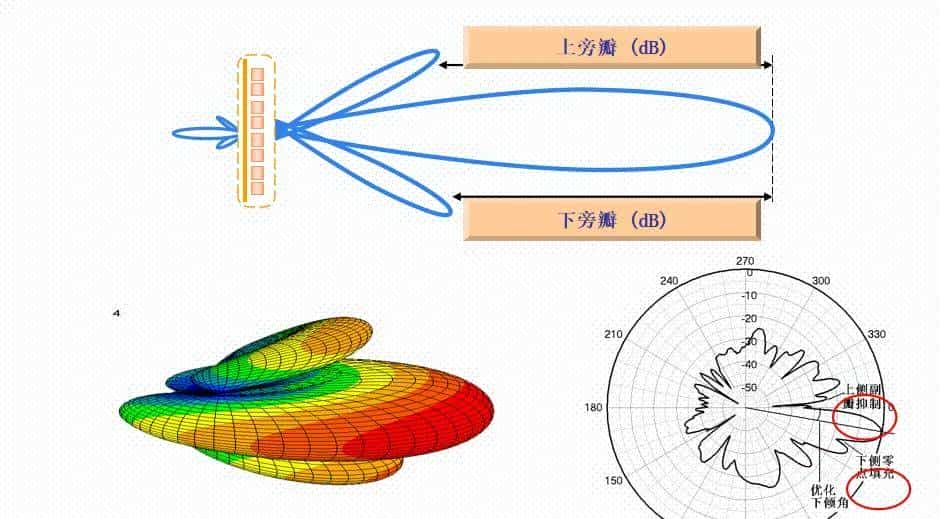
旁瓣抑制:对于基站天线,常常要求它的垂直面(即俯仰面)方向图中,主瓣上方第一旁瓣尽可能弱一些。这就是所谓的上旁瓣抑制 。基站的服务对象是地面上的移动电话用户,指向天空的辐射是毫无意义的。
3.5.3前后比
方向图中,前后瓣最大电平之比称为前后比,记为 F / B 。前后比越大,天线的后向辐射(或接收)越小。前后比F / B 的计算十分简单— F / B = 10 Lg {(前向功率密度) /( 后向功率密度)},对天线的前后比F / B 有要求时,其典型值为 (18 — 30)dB,特殊情况下则要求达(35 — 40)dB。


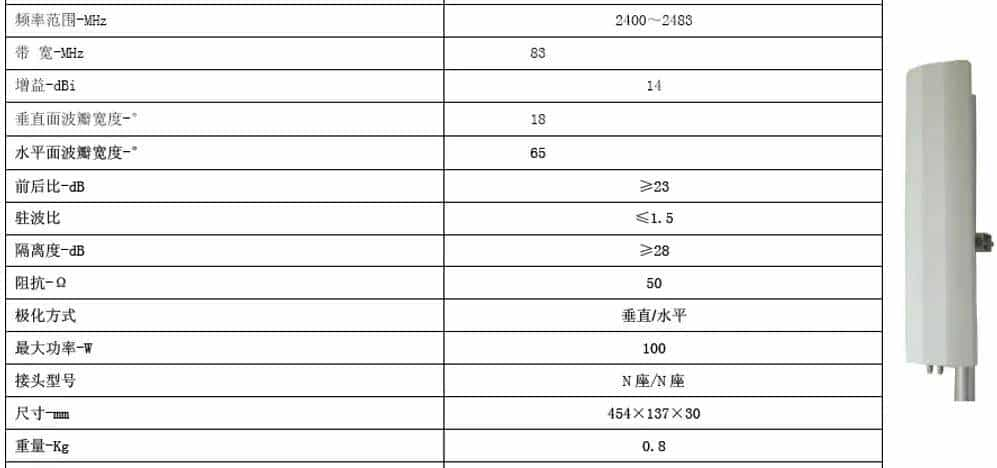
如下图为一款室外天线的的规格参数:
天线的种类繁多,有基站天线,终端天线,传统的终端天线可以根据天线所处的位置分为外置天线和内置天线两大类,终端天线按传统的天线单元形式可分为:单极天线,螺旋天线,PCB天线,贴片天线,缝隙天线,IFA天线和倒L天线,PIFA等等。不同应用可以选择不同的天线,同时不同种类的天线思考的天线参数也不尽一样。
为什么要关注WiFi干扰问题?
当前,通讯技术已然渗透到人们生活、工作的方方面面,极大改变了人们的生活方式。而无线通信有最明显的优点,提供人们移动性。故而也得到了广泛的应用。wifi 作为当今超级流行的无线通信技术,已经成为是一种超级简便的网络接入方式。WiFi信号是看不见摸不着的,很可能您的智能手机或平板电脑上的信号明明是满格却还是卡顿,明明买了价格不菲的路由器,可是情况并没有太大的改善,这可能就是你的WiFi网络受到了干扰,于是就需要我们要进行 WiFi 分析,找出根本缘由,从而彻底解决问题。
简单来说,影响 WiFi 速率的关键因素只有两个 ,干扰和信号强度。本质上,提升 WiFi 质量也只有两个办法,通俗点说是降低干扰和提升信号强度,专业名词叫提高信噪比(SNR)。
WIFI干扰原理
IEEE 802 家族是由一系列局域网络(local area network,简称 LAN)技术规格所组成,802.11 属于其中成员之一 802.11 规格的关键在于 MAC(介质访问控制层)。MAC 位于各种物理层之上,控制数据的传输。不同的物理层可以提供不同的传输速度,不过物理层之间必须彼此互通。802.11 并未大幅偏离之前的 IEEE 802 标准。802.11 成功地将以太网形式的网络应用到无线链路之上。和以太网一样,802.11 采用载波侦听(carrier sense multiple access,简称 CSMA)机制,来控制传输媒质的访问。不过,碰撞会浪费宝贵的传输资源,因此 802.11 转而使用冲突避免(CSMA/CA)机制,而非使用以太网所采用的碰撞检测(CSMA/CD)机制。
由于WIFI在MAC层采用的是CSMA/CA (Carrier Sense Multiple Access /Collision, CSMA/CA)即载波侦听多路接入/冲突避免。其基本思想是:每个站在发送数据前,先侦听信道上有无其它站正在发送信息,如果没有(即信道空闲),则发送数据;否则(信道忙)暂不发送,退避一段时间后再尝试。而GSM,3G等无线系统都没有这种退让机制因此WLAN的干扰分析跟它们都不一样。GSM,3G等更多的是思考干扰信号与有用信号之比(C/I)即载干比。
在采用CSMA/CA机制的网络中,用户如果侦听到介质闲置时间长于 DIFS(分布式帧间隔-DIFS 是竞争式服务中最短的介质闲置时间)。则判断此时信道可用,为了避免冲突随即启动随机回退计数器,在回退期间如果无其他用户抢占信道,则发送数据帧;收端在SIFS(短帧间隔)时间间隔后发回ACK确认。

SIFS 用于高优先级的传输场合,例如 RTS/CTS 以及正面应答帧。经过一段 SIFS(时间),即可进行高优先级的传输。一旦高优先级传输开始,介质即处于忙碌状态,因此相较于必须等待较长时间才能传输的帧,SIFS 消逝后即可进行传输的帧优先级较高。
在IEEE802.11中载波侦听的实现是通过两种机制:物理载波侦听和虚拟载波侦听。物理载波侦听机制依赖于物理层的调制方案。也即当接收机侦听到信道有高于某个门限的信号时便认为信道忙。该门限我们称为载波侦听门限CS Thresh)。
隐藏节点不能通过物理载波侦听来检测。所以为了避免冲突,我们还提出虚拟载波侦听。虚拟载波侦听机制是通过MAC层的网络分配矢量(NAV)来实现。通过在每个帧里分发预留信息来宣布对媒介的未来使用。NAV是个存放媒介预期忙的固定时间。NAV是一个倒计时计时器,随时间的流逝逐渐减少,当倒计时为0时,虚拟载波检测将认为介质处于空闲状态。
无线干扰的分类
无线干扰按照类型可划分为WLAN干扰和非WLAN干扰。WLAN干扰是指干扰源发送的RF信号也符合802.11标准,除此之外都是非WLAN干扰。对WLAN干扰,可进一步按照频率范围分为同频干扰和邻频干扰。按照来源划分,可分为WLAN网络自身的互干扰和网络外的干扰。
我们先讨论非WLAN干扰
在5G频带与WLAN重用的主要是雷达波。为了避免WLAN设备与雷达波之间干扰相互干扰WLAN设备在5G频带会增加DFS即动态频率选择功能(DFS:Dynamic Frequency Selection),这个功能基本上是芯片方案已经支持。动态选频包含了一组程序,可以让 802.11 设备根据量测结果(measurement)与管制要求(regulatory requirement)变更无线电波频道。它可以影响一开始的连接程序以及后续的网络过程。
在2.4G ISM频带使用的系统许多包括RFID,Bluetooth,Zigbee等此外ISM频带还存在微波炉、无绳电话等设备。由于这些设备影响的范围有限所以对于我们WiFi设备这些不是我们的主要干扰源。只是我们在网络布局时需要注意远离这些干扰源。
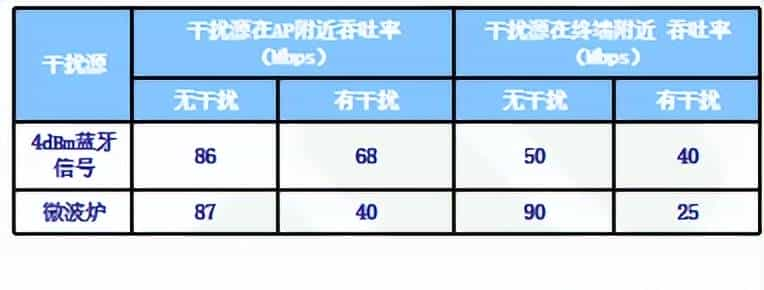
我们再来讨论WLAN干扰
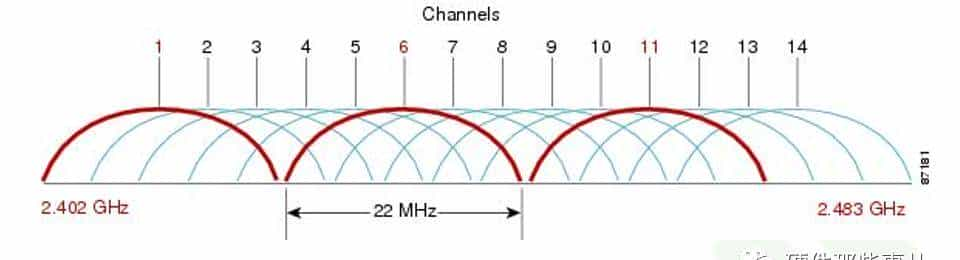
对于WLAN干扰我们可以分为同频干扰和邻频干扰。在2.4G频段上,互不干扰的频段十分有限,一般只有1、6、11信道(如下图所示)。可知信道1与信道6频谱没有重叠,因此我们称信道1与信道6为邻信道。
邻频干扰原理
在讨论邻频干扰原理之前,我们先思考几个问题?
1、不重叠的两个信道列如信道1和信道6为什么存在干扰?
2、如果存在干扰那么11b信号和11g信号对邻道的干扰有什么区别?
3、降低发送功率对减小邻信道干扰到底有多大作用 ?
问题一:
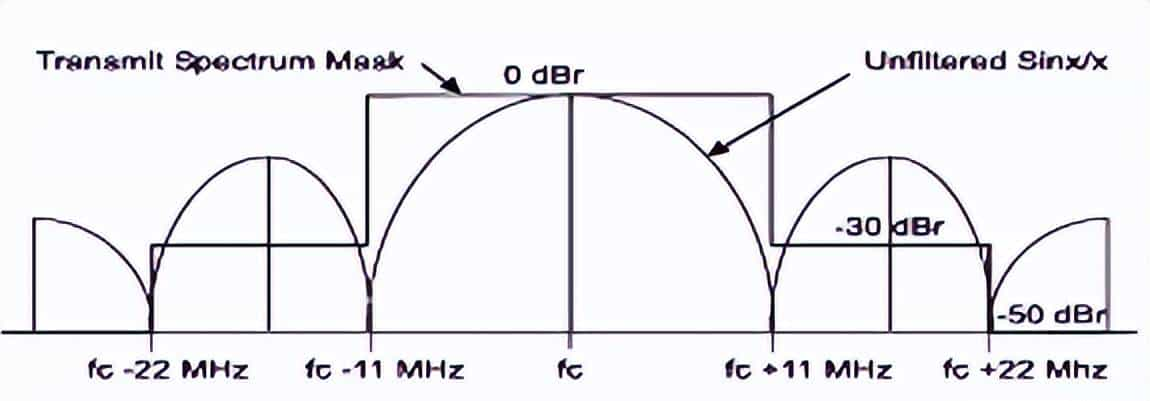
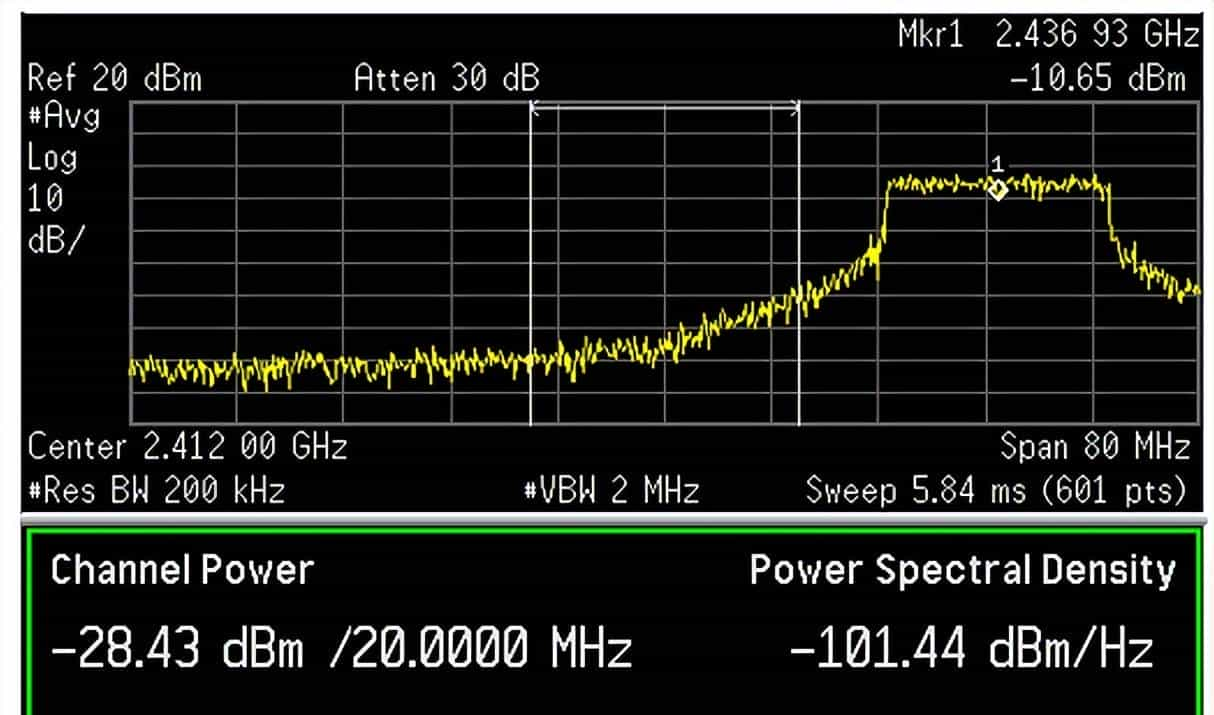
根据802.11标准,RF信号发送时其频谱宽度有必定的要求。以2.4G为例,信号的频谱掩码如下图所示。其发射频宽为22MHz,在距离中心频率11MHz之外时,要求衰减超过30dB。对任何WLAN发射机来说,在发射频宽之外,信号也不可能马上降低为0,而是逐渐衰减。如果两个中心频率不同的WLAN设备之间的发射频宽有重叠的部分,就会产生相互影响,形成了邻频干扰。即使对不重叠的相邻信道(如2.4G的1、6信道),如果两个设备之间距离过近且发送功率比较大,也会产生影响。
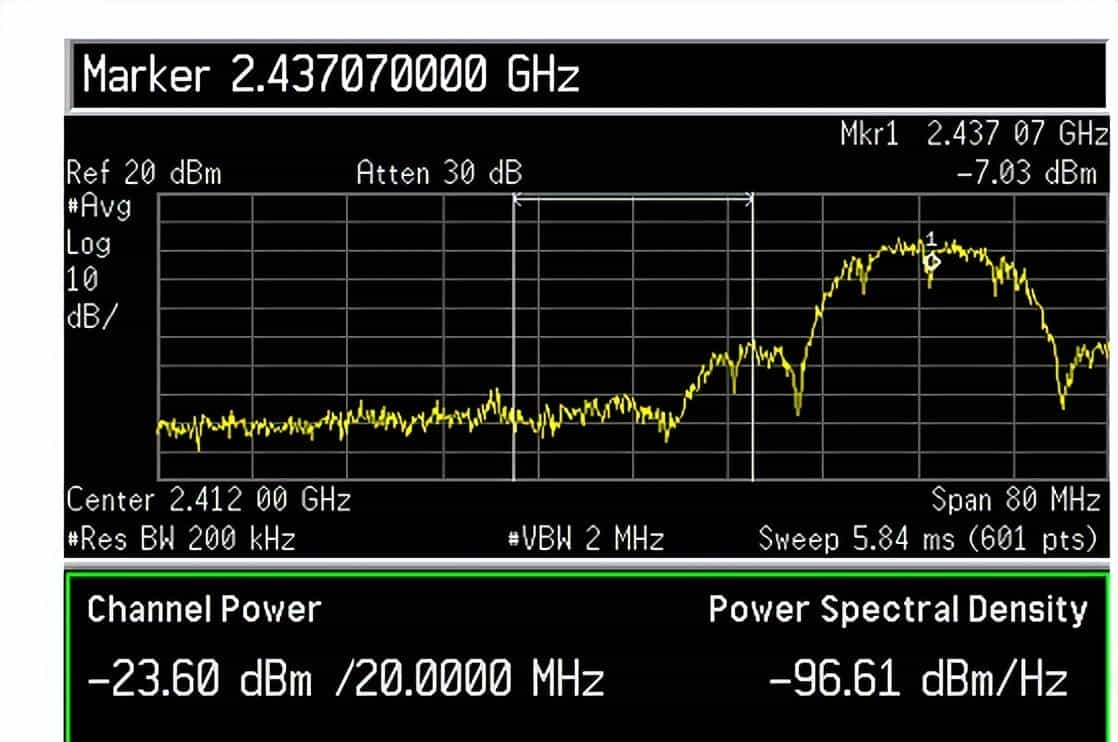
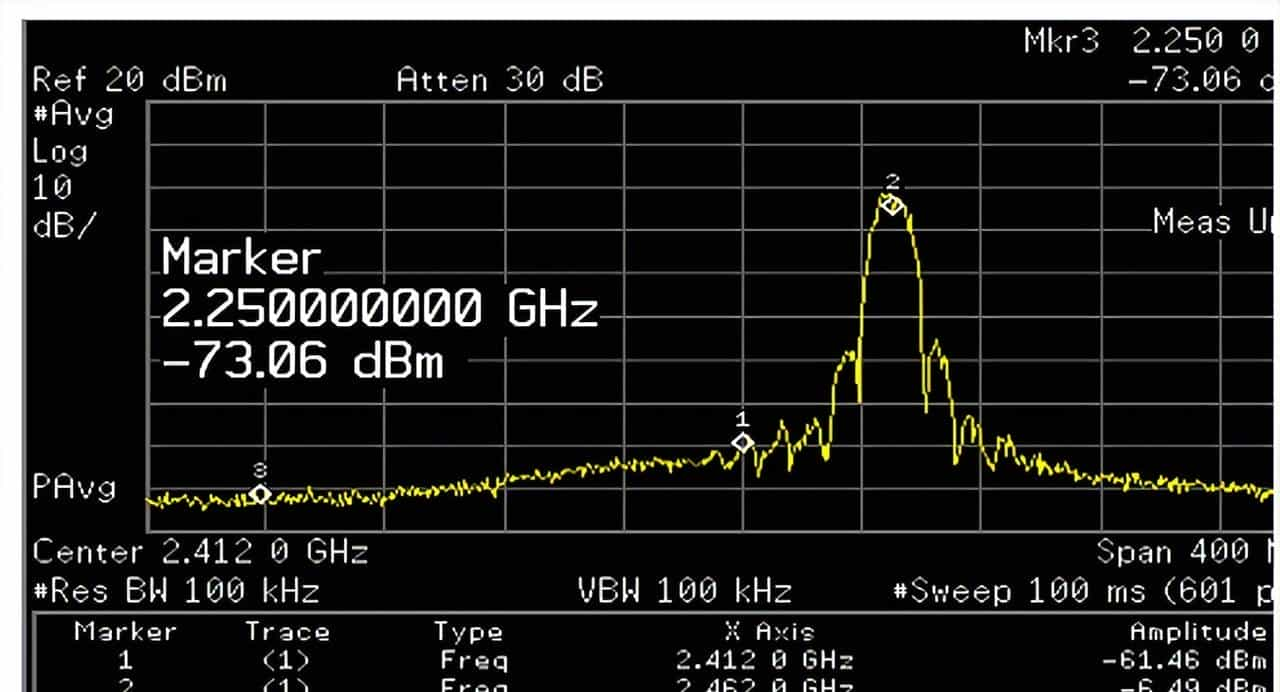
由WiFi信号发送时其频谱可知,即使对不重叠的相邻信道(如2.4G的1、6信道),也会由于两者之间的边带会产生相互影响。下图为Maxpower=19,工作在11b 1M模式时信道6对信道1的影响。
下图为Maxpower=19,工作在11b 1M模式时信道11对整个频带的影响。从下图可知由于功率放大器的非线性产生的边带功率随着离中心频率越远而逐渐减小。边带功率把噪低(N)抬高因此造成信噪比S/N降低。信噪比的降低从而会造成速率降低。
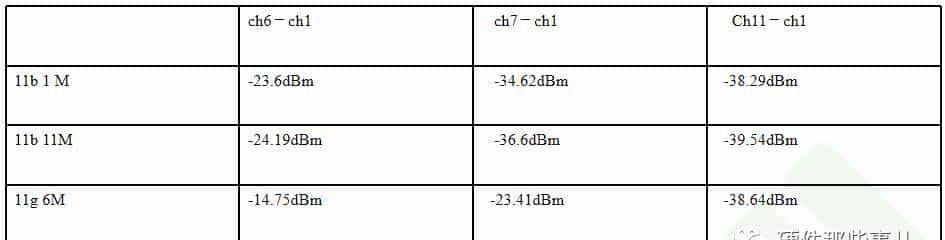
如下表所示对于11b信号信道7与信道1的隔离比信道6与信道1的隔离大10dB左右,而信道11与信道1的隔离比信道7与信道1的隔离只大4dB左右。而对于11g信号,信道7与信道1的隔离比信道6与信道1大10dB左右,而信道11与信道1的隔离比信道7与信道1的隔离大了15dB左右。信道11与信道1我们称为次邻道。
问题二:
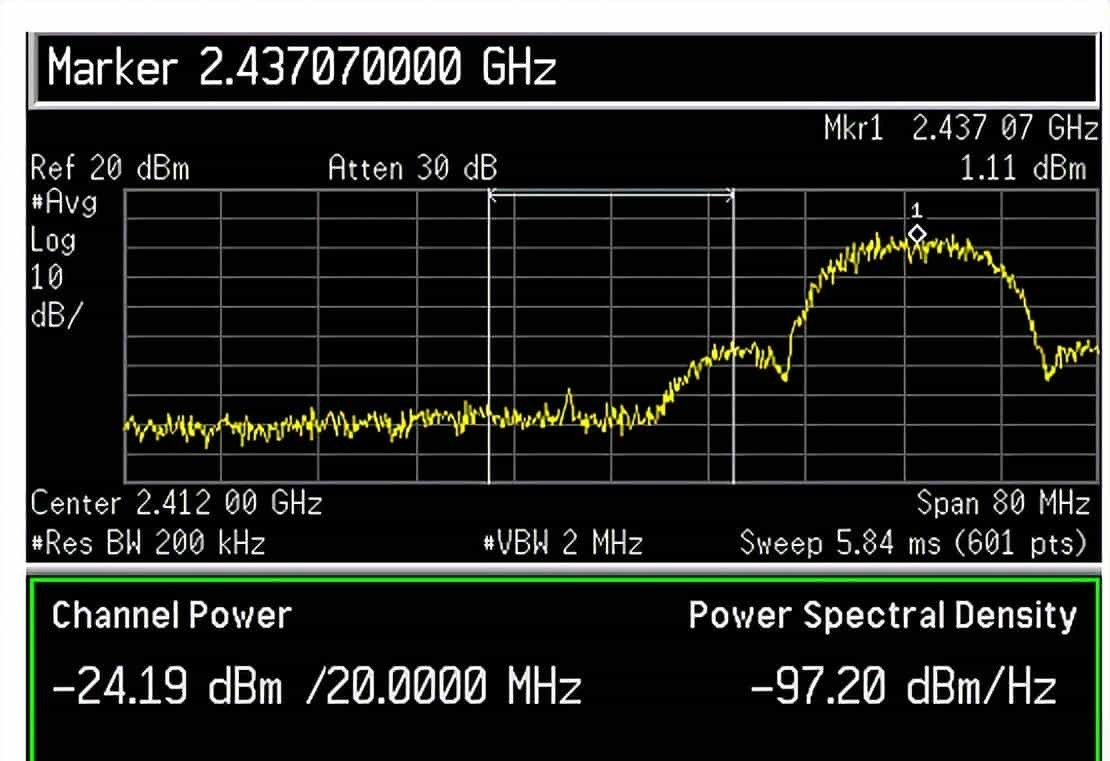
如下图Maxpower=19,工作在11b 11M模式时信道6对信道1的影响,可以发现与1M模式时无太大差别。
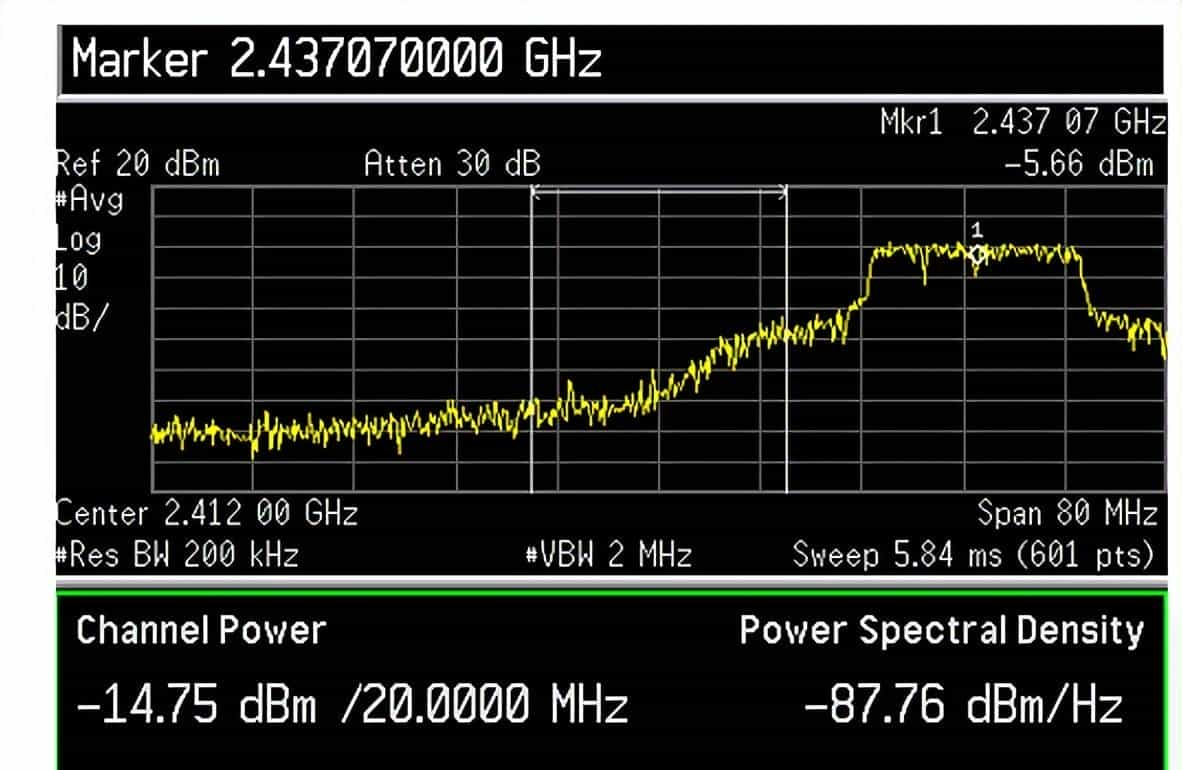
如下图Maxpower=19,工作在11g 6M模式时信道6对信道1的影响可知一样发送功率下11g对邻道的影响大于11b信号。
问题三:
如下图Maxpower=15dBm,工作在11g 6M模式时信道6对信道1的影响对比Maxpower=19dBm情况可知此时信道6对信道1的影响小了14dB。
邻频干扰的规避措施
1、降低发送功率使功率放大器远离非线性区域可以大大减小对邻频的干扰。
2、增大信道间隔可以减小相互间的干扰。
3、增加邻信道设备之间空间距离或者在使用定向天线时避免天线主波瓣直接相对。
同频干扰原理
同频干扰主要是由于WIFI的冲突避免(CSMA/CA)机制引起。这里又分为两种情况:
1.同频WiFi设备之间如果可见,以802.11为基础的WLAN,空口是所有设备的公共传输媒介,两个WiFi设备之间将根据CSMA/CA原则,进行相互退避,这势必会大大降低性能,两个AP的总性能将不会超过一个信道的性能。
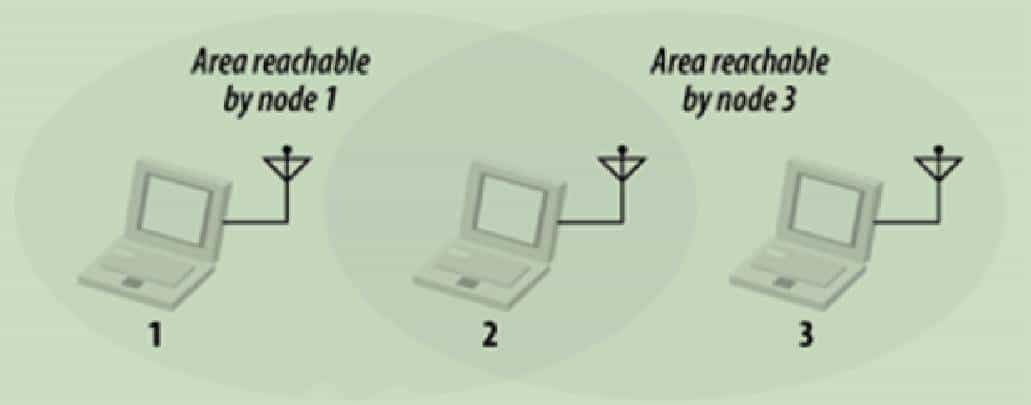
2.如果同频WiFi设备之间不可见但覆盖区域有交集,则对处于交集区域的Client而言可能会形成隐藏节点或暴露节点问题(如下图)。
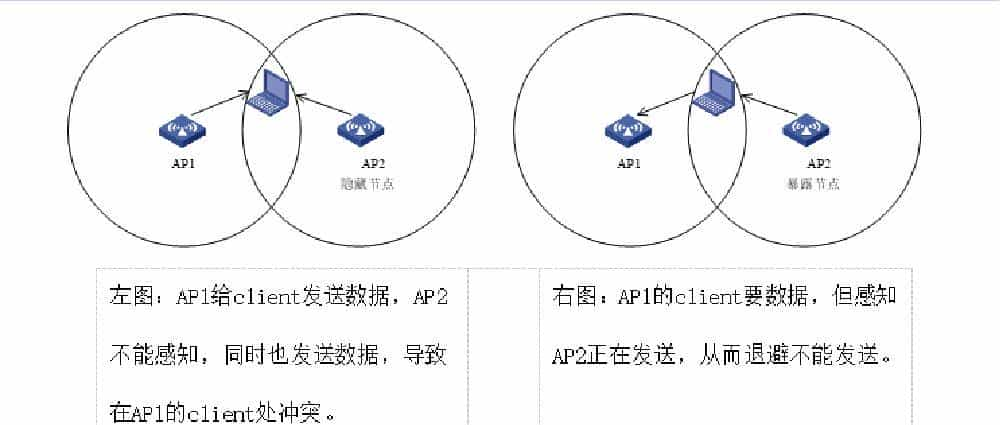
隐藏节点和暴露节点会产生两个方面的问题,其一是报文发送时需要退避或不断重传;其二是由于报文重传时会降低报文发送的物理速率,导致同一AP的影响范围扩大,也使得报文发送占用更多的空口时长,冲突几率加大,引起更多的重传。
同频干扰的规避措施
在实际同频干扰测试中可以发现接收灵敏度的降低的确 可以提高抗同频干扰能力。因此接收灵敏度实则是一把双刃剑。
1、当一些密集布网不能避免使用同一信道时提议降低发送功率。
2、尽量拉开工作在同频的AP之间的距离。具体多远需要根据实际的组网环境
3、降低设备的接收灵敏度。
4、避免工作在同频的AP天线主波瓣之间直接相对。
5.隐藏终端避免:引入握手机制(RTS-CTS),避免干扰
6.避免暴露终端影响:动态CCA(净空频道评估)调整
7.退避优化:竞争管理和竞争压制(过调整帧间隔时间DIFS、SIFS、CWmin、CWmax、Ack等待时间等,避免同频干扰。802.11e的WMM功能就采用了此种思想,即通过AIFS、CWmin、CWmax等参数的调整,达到增加信道竞争能力)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
![[945]ScalersTalk备战CPA小组第4周学习笔记](https://img.dunling.com/blogimg/20260111/ea6d2dc438db4454a73f9f902b8f517e.jpg)













学习了,谢谢
学习了
收藏了,感谢分享