
摘要:本文意在为读者呈现 APM 系列网络电力仪表。此系列仪表于电力监测范畴意义重大,其融合了诸多先进性能,能够精准测定各类电力参量,拥有强劲的电能统计以及质量剖析能力,并且具备灵活的通讯模式和丰富的拓展功能。借由详尽阐释其功能特质、技术参数、操作形式以及在实际运用中的优势,使读者深度知悉 APM 系列网络电力仪表于电力系统、工矿企业等场景里的重大价值。
关键词:APM 系列;网络电力仪表;电力监测;智能管理
一、引言

于当今电力工业迅猛发展之时代,针对电力系统的效率监测以及精准管理之需求与日俱增。APM 系列网络电力仪表作为一款先进的电力监测装置,应时而生,为电力行业的进步给予了有力支撑。
二、APM 系列网络电力仪表概述

APM 系列网络电力仪表乃是依循 IEC 标准精心打造的高科技产物,与国际前沿技术并驱前行。其具备完备的全电量测量功能,能够确切地对三相三线或三相四线网络中的电流、电压、有功功率、无功功率、实在功率、频率、功率因数等参量进行实时测度。与此同时,其电能统计功能不单能够准确计量电能,还能够对电能质量展开深度剖析,诸如检测电流、电压的不平衡度,解析电压电流谐波含量等。另外,该系列仪表拥有强劲的网络通讯本领,能够达成与其他设备的数据交互,系电力系统中达成智能化监测与管理的关键装置。
三、功能特点
- 准确测量与统计
- APM 系列仪表能够精准测度各类电力参量,为电力系统的稳健运行给予确切的数据支撑。于电能统计层面,能够达成四象限电能的准确计量,同时还能够统计三相电流、有功功率、无功功率、视在功率的实时需量及最大需量,并记录其发生的时间戳,助力用户全方位把控电力消耗状况。
- 譬如,在工业生产当中,借由对有功功率和无功功率的精准测度,企业能够优化用电设备的运行,降低能耗,提升生产效率。
- 电能质量分析
- 该系列仪表能够对电能质量展开详尽剖析,检测电流、线电压、相电压不平衡度,计算电压相间角度、电流相间角度,以及解析电压电流总(奇、偶)谐波含量、分次波(2 – 63 次)谐波含量、波峰系数、电话波形因子、电流 K 系数等。这对于保障电力系统的稳定运转,规避因电能质量问题引发的设备损毁和生产中断具备关键意义。
- 例如在数据中心等对电能质量要求颇高的场所,APM 系列仪表能够实时监测谐波含量,及时察觉潜在的电能质量问题,采取相应举措予以治理,确保设备正常运作。
- 丰富的报警与记录功能
- APM 系列仪表拥有多达 66 种报警类别,每种类别可记录最近 16 条报警记录,并且支持 SD 卡拓展记录。同时,仪表主体至多可存储 128 条事件记录,当 DI/DO 状态发生转变时,能够详细记录事件发生的时间、序号以及动作类型等信息。这些报警和记录功能为故障排查以及设备维护提供了重大凭据。
- 例如,在电力系统出现故障时,通过查阅报警记录和事件记录,可以迅速定位故障缘由,缩减故障修复时长,降低经济损失。
- 灵活的扩展功能
- 秉持模块化设计理念,APM 系列仪表能够依据实际需求灵活配置各类扩展模块。如 MD82 模块提供 8 路开关量输入和 2 路转换触点继电器输出,适用于对开关量状态监测和控制要求较高的场景;MLOG 模块支持 Micro SD 卡存储,利于数据记录和分析;MA84 模块具备 8 路模拟量输入和 4 路模拟量输出,能够实现对模拟信号的采集和输出控制;MCE 模块提供以太网接口,支持多种网络协议,便于接入以太网进行远程监控和数据传输。
- 在智能工厂建设之中,通过添加不同的扩展模块,APM 系列仪表能够与其他自动化设备无缝融合,达成对生产过程的全方位监控和智能化管理。
四、技术参数
- 输入输出参数
- 网络支持三相三线与三相四线模式,频率区间为 45 – 65Hz。电压额定值具备多样选择,诸如 AC 100V、110V、400V、690V,电流额定值涵盖 AC 1A、5A,能够满足不同电力系统的需求。于过负荷能力方面,电压和电流皆具有明晰的承受范畴,以保障仪表在异常状况下的安全运作。
- 例如,于高压输电系统当中,可以拣选适宜电压额定值的 APM 仪表予以监测;在低压配电系统里,则能够选用 AC 100V 或 400V 额定值的仪表。
- 测量精度
- 有功电能测量精度于不同型号存有差异,APM800 和 APM810 为 0.5s 级,APM801 可达 0.2s 级,无功电能测量精度为 2 级,谐波测量精度于 2 – 42 次谐波范畴内为 1%,43 – 63 次谐波范围内为 2%。高精度的测量保证了数据的可信度和准确性。
- 在电力计量领域,高精度的电能测量对于电费结算、能源管理等方面举足轻重,APM 系列仪表能够契合这些严苛的要求。
- 通讯接口
- 提供多元的通讯接口,包含 RS485 接口(支持 Modbus – RTU 协议和 DLT645 规约)、Profibus – DP 接口(遵循 Profibus – DP 协议)、以太网接口(支持 Modbus – TCP、http、DHCP 等协议)。各异的通讯接口可适配不同的应用场景,达成与各类设备和系统的互联互通。
- 例如,在工业自动化控制系统之中,可通过 RS485 接口与 PLC 进行数据通信;在智能电网建设中,以太网接口能够便捷地将仪表接入网络,实现远程监控和管理。
五、安装与操作
- 安装方法
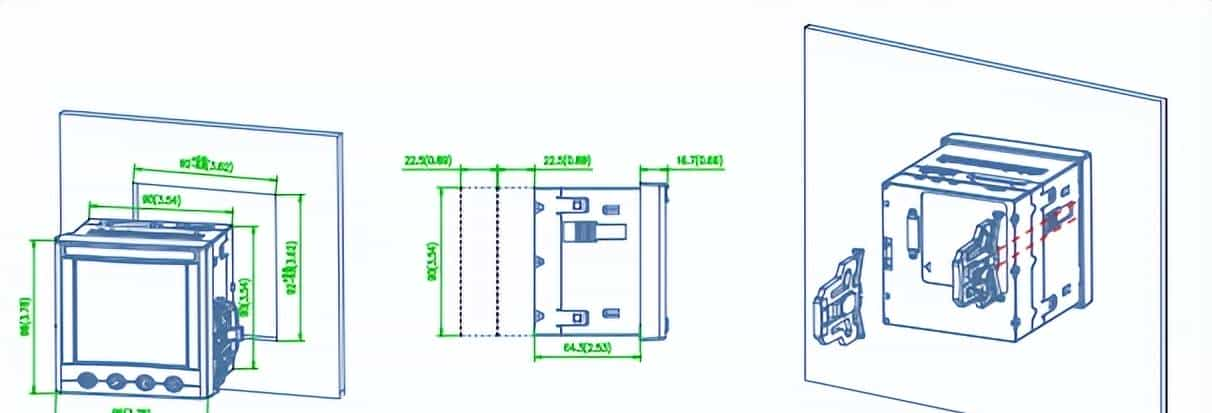
- APM 系列仪表采用嵌入式安装模式,安装流程简便易行。第一于配电盘上拣选适宜位置开一个与仪表开孔尺寸一样的安装孔,继而将仪表插入孔中,固定好安装支架以及定位螺钉便可。在接线方面,需留意依据不同的设计要求,于电源、电压输入端子增添保险丝,保证接线准确可靠,电流与电压相序相符,方向一致。
- 例如,在安装进程中,严格依照安装说明进行操作,能够确保仪表安装稳固,接线安全,降低因安装不当引发的故障风险。
- 操作说明
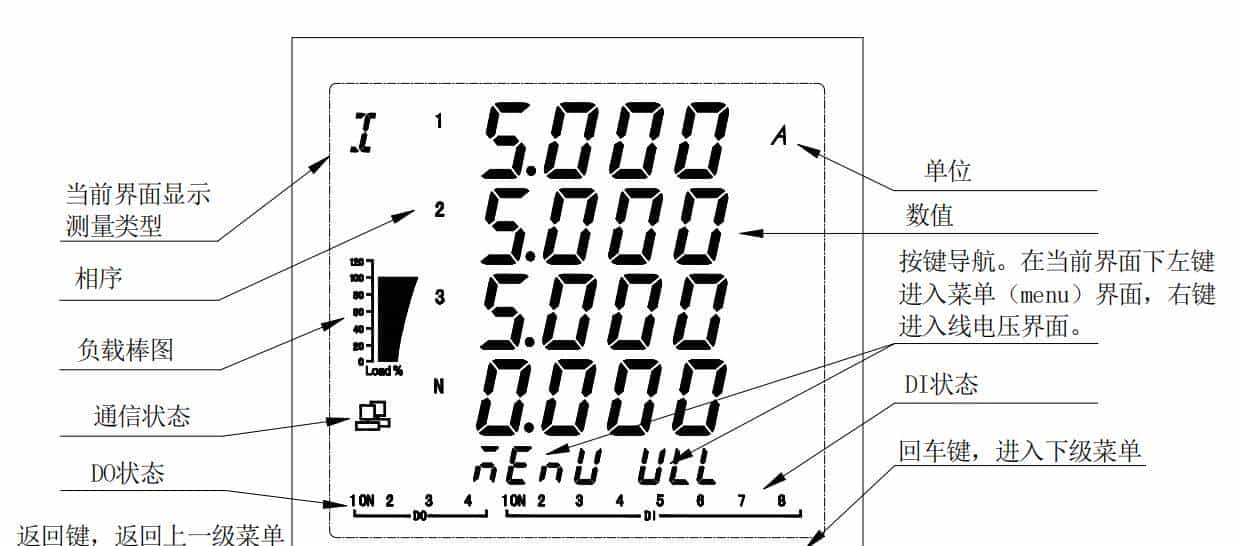
- 仪表借助按键操作达成各种功能。面板上的四个按键(键、<>键、<>键、键)可用以菜单导航、参数设定、数据查看等操作。用户能够通过按键轻松切换不同的显示界面,查看电流、电压、功率、电能、谐波、IO 状态、最大最小值、报警记录、温湿度等各类信息,并进行系统设置,诸如通信设置、电流变比设置、报警阈值设置等。
- 例如,在日常运行当中,操作人员能够便捷地通过按键查看电力参数,及时发觉异常状况,并依据需求调整仪表的设置。
六、应用场景
- 电力系统

- 在发电、输电、配电等环节之中,APM 系列仪表能够对电力设备的运行状态予以实时监测,涵盖对变电站、配电室里的变压器、开关柜等设备的监测。借由精准测量电力参数以及剖析电能质量,及时察觉设备故障隐患,提升电力系统的可靠性与稳定性。
- 例如,在变电站内,APM 仪表能够实时监测变压器的油温、绕组温度、负载电流等参数,当参数出现异常时及时告警,保障变电站的安全运行。
- 工矿企业

- 针对工矿企业里的各类生产设备,诸如电机、风机、泵等,APM 系列仪表能够监测其用电状况,助力企业优化设备运行,降低能耗,提高生产效率。同时,凭借报警和事件记录功能,能够及时发觉设备故障,缩减停机时间,降低维修成本。
- 例如,在工厂的生产线中,APM 仪表能够监测电机的运行电流、电压和功率因数,依据监测数据调整电机的运行状态,达成节能增效。
- 智能大厦与公用设施

- 在智能大厦里,APM 系列仪表可用以对楼内的电力系统、照明系统、空调系统等实施监测和管理,达成能源的合理分配与高效利用。在公用设施诸如医院、学校、商场等场所,也能够用于对电力设备的监测,确保设施的正常运转。
- 例如,在智能大厦的能源管理系统中,APM 仪表能够实时监测各个区域的用电情况,依照实际需求自动调整照明和空调设备的运行,实现节能减排。
七、结论
APM 系列网络电力仪表凭借其出众的功能特点、先进的技术参数、便捷的安装操作以及广泛的应用场景,于电力监测与管理领域发挥着关键作用。它不但为电力系统的稳定运行提供了强有力的保障,也为工矿企业、智能大厦等用户带来了显著的经济效益和社会效益。伴随科技的持续进步,APM 系列仪表有望在未来的电力智能化发展中发挥更为重大的作用。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











