

为什么需要配置? 配置管理是管理复杂软件系统的必要条件。缺乏配置管理可能会导致可靠性、正常运行时间和系统扩展能力方面的严重问题。
在python代码中添加配置有许多方法。主要的方法是:
- Command line arguments
- Configparser
- Argparser
- Dataclasses
- Hydra
还有其他的…
本文将介绍Hydra。
在这篇文章中,我将讨论以下主题:
- Hydra的基本知识
- 覆盖配置
- 在多个文件中拆分配置
- 变量插值
- 如何在不同的参数组合下运行模型?
Hydra的基本知识
第一步安装库
pip install hydra-core==1.1.0Hydra在OmegaConf的基础上运行,OmegaConf是一个基于YAML的分层配置系统,支持从多个源(文件、CLI参数、环境变量)合并配置,无论如何创建配置,都提供一致的API。
让我们看看一个基本的yaml文件并导入它:
preferences:
user: raviraja
trait: i_like_my_sleeping使用OmegaConf加载这个文件:
from omegaconf import OmegaConf
# loading
config = OmegaConf.load('config.yaml')
# accessing
print(config.preferences.user)
print(config["preferences"]["trait"])使用Hydra加载这个文件:
import hydra
from omegaconf import OmegaConf
@hydra.main(config_name="basic.yaml")
def main(cfg):
# Print the config file using `to_yaml` method which prints in a pretty manner
print(OmegaConf.to_yaml(cfg))
print(cfg.preferences.user)
if __name__ == "__main__":
main()输出:
preferences:
user: raviraja
trait: i_like_my_bed
raviraja配置也可以在不使用hydra的情况下加载,方式如下:
from hydra import initialize, compose
initialize(".") # Assume the configuration file is in the current folder
cfg = compose(config_name="basic.yaml")
print(OmegaConf.to_yaml(cfg))重写配置
默认情况下,将使用配置文件中分配的值。但我们也可以在运行时重写变量的值。
这可以通过重载语法来实现
>
https://hydra.cc/docs/next/advanced/override_grammar/basic/
python main.py perferences.trait=i_like_stars输出:
preferences:
user: raviraja
trait: i_like_stars现有代码转化成支持Hydra
让我们将现有代码中的所有参数转换为yaml格式,并使用hydra加载它
让我们创建一个名为configs的文件夹,并在其中创建一个文件config.yaml
文件夹结构如下所示
├── configs
│ └── config.yamlconfig.yaml的内容:
model:
name: google/bert_uncased_L-2_H-128_A-2
tokenizer: google/bert_uncased_L-2_H-128_A-2
processing:
batch_size: 64
max_length: 128
training:
max_epochs: 1
log_every_n_steps: 10
deterministic: true
limit_train_batches: 0.25
limit_val_batches: 0.25目前让我们将该文件加载到train.py代码中,并使用该文件中的值
# NOTE: Need to provide the path for configs folder and the config file name
@hydra.main(config_path="./configs", config_name="config")
def main(cfg):
# print(OmegaConf.to_yaml(cfg))
cola_data = DataModule(
cfg.model.tokenizer, cfg.processing.batch_size, cfg.processing.max_length
)
cola_model = ColaModel(cfg.model.name)
checkpoint_callback = ModelCheckpoint(
dirpath="./models",
filename="best-checkpoint.ckpt",
monitor="valid/loss",
mode="min",
)
wandb_logger = WandbLogger(project="MLOps Basics", entity="raviraja")
trainer = pl.Trainer(
max_epochs=cfg.training.max_epochs,
logger=wandb_logger,
callbacks=[checkpoint_callback, SamplesVisualisationLogger(cola_data)],
log_every_n_steps=cfg.training.log_every_n_steps,
deterministic=cfg.training.deterministic,
limit_train_batches=cfg.training.limit_train_batches,
limit_val_batches=cfg.training.limit_val_batches,
)
trainer.fit(cola_model, cola_data)在多个文件中拆分配置
在我们正在研究的例子中,变量的数量较少。但在实际场景中,可能有许多模块,每个模块可能有许多参数。将所有这些参数放在一个文件中可能看起来很混乱。幸运的是,Hydra提供了一种将配置放在多个文件中的方法,并且可以将其绑定在一起。这可以通过Hydra配置组完成。
让我们在configs文件夹中创建一个单独的文件夹模型,用于包含模型特定的配置。让我们创建一个名为default的文件。包含默认模型配置的Yaml
文件夹结构如下所示:
├── configs
│ ├── config.yaml
│ └── model
│ └── default.yamlmodel/default.yaml的内容如下:
name: google/bert_uncased_L-2_H-128_A-2 # model used for training the classifier
tokenizer: google/bert_uncased_L-2_H-128_A-2 # tokenizer used for processing the data目前让我们修改config.yaml
defaults:
- model: default让我们来了解一下要做的事。
我们所做的是:
- 创建了一个名为model的单独文件夹,然后创建了一个名为default.yaml的文件
- 将所有特定于模型的参数转移到该文件
- 在config.yaml文件中创建了一个名为defaults的键值(Hydra中的保留关键字)
- 这里默认是一个列表项
- 添加一个(键,值)到默认列表->模型(这必须与文件夹名一样):default(这必须与文件名一样)
这里我们说的是hydra,它引用模model/default.yaml中的模型特定参数。
访问保持不变。
model_name = cfg.model.name例如,如果有一个数据库,并且想配置不同类型的实例。列如postgres, mongodb,并希望保持postgres作为默认值。然后config.yaml的样子如下:
defaults:
- database: postgres对应的文件夹结构如下:
├── configs
│ ├── config.yaml
│ ├── database
│ │ └── postgres.yaml
│ │ └── mongodb.yaml目前让我们创建processing的文件夹和training的文件夹,并将相应的参数转移到该文件。
最终的文件夹结构如下:
├── configs
│ ├── config.yaml
│ ├── model
│ │ └── default.yaml
│ ├── processing
│ │ └── default.yaml
│ └── training
│ └── default.yamlconfig.yaml的内容如下:
defaults:
- model: default
- processing: default
- training: default变量插值
有时候,变量也会依赖于其他变量。例如,使用哪一层可能取决于数据集的类型。作为一个简单的示例,让我们设置与limit_training_batch一样的limit_val_batch变量值。
这个training/default.yaml的样子:
max_epochs: 1
log_every_n_steps: 10
deterministic: true
limit_train_batches: 0.25
limit_val_batches: ${training.limit_train_batches}当您加载并打印完整的配置时,该值将被打印为
print(OmegaConf.to_yaml(cfg))结果如下
${training.limit_train_batches}为了克服这个传入resolve=True 到 OmegaConf.to_yaml:
print(OmegaConf.to_yaml(cfg, resolve=True))输出:
0.25日志增加颜色
日志记录有助于理解程序的状态。拥有丰富多彩的日志将有助于更快地识别特定的日志(而且日志看起来也更美丽)。
这可以在hydra中轻松完成,而无需更改任何日志代码。(一般人们为每种日志方法定义颜色语法/使用不同的支持颜色的库)。在hydra中修改默认的日志记录模式就足够了。
为了做到这一点,我们需要安装hydra扩展:
pip install hydra_colorlog让我们覆盖hydra/job_logging和hydra/hydr_logging,config.yaml的如下:
defaults:
- override hydra/job_logging: colorlog
- override hydra/hydra_logging: colorlog在添加彩色之前,日志看起来像:

添加颜色后:

默认情况下,Hydra在不同的目录中执行每个脚本,以避免覆盖不同运行的结果。目录的默认名称是outputs/<day>/<time>/
每个目录包含脚本的输出、一个.hydra文件夹,其中包含用于运行的配置文件,以及一个<name>.log文件,其中包含发送到记录器的所有数据。
不同参数组合的运行模型
有时您希望使用多个不同的配置运行同一个应用程序。这可以通过在hydra中通过multi-run来完成
参考:
https://hydra.cc/docs/next/tutorials/basic/running_your_app/multi-run/
使用–multirun (-m)标志,并传递一个逗号分隔的列表,指定要扫描的每个维度的值。
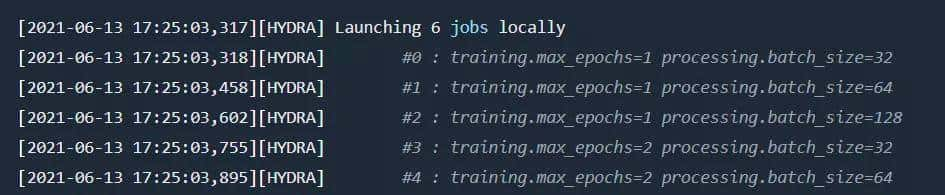
例如,为了运行epoch 1和2的应用程序,命令如下所示:
python train.py -m training.max_epochs=1,2然后hydra启动2个任务:

如果参数分布在不同的文件夹中,意味着将采用所有的组合。例如,通过执行命令
python train.py -m training.max_epochs=1,2 processing.batch_size=32,64,128将启动6个任务
这篇文章到此结束。这些只是hydra的一小部分功能。还有许多其他的功能,列如:
对象实例化
https://hydra.cc/docs/next/advanced/instantiate_objects/overview/
单元测试
https://hydra.cc/docs/next/advanced/unit_testing/
结构配置
https://hydra.cc/docs/next/tutorials/structured_config/schema/
更多可参考hydra的文档:
https://hydra.cc/docs/intro。
本文的完整代码也可以在这里找到:
https://github.com/graviraja/MLOps-Basics
参考资料
- https://hydra.cc/docs/intro
- https://www.sscardapane.it/tutorials/hydra-tutorial/#executing-multiple-runs
















暂无评论内容