
面试结束后,我把 Redis 主从复制那套讲清楚了,面试官点头还不少。说白了,那天我没被当场刷下去,聊得挺深入,也把实战经验说出来了。
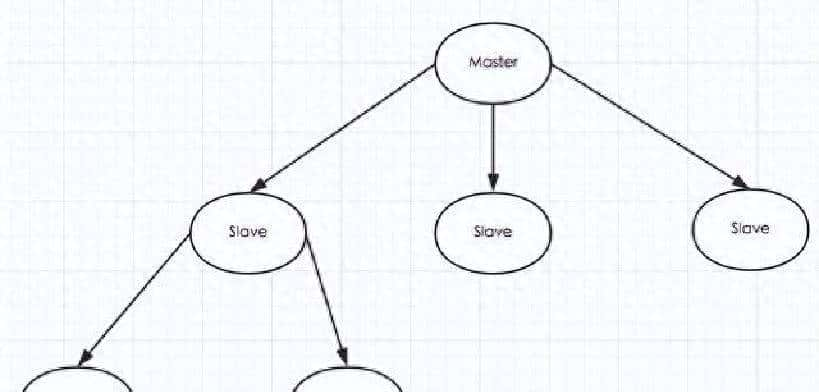
坐下来讲之前,回到现场的细节:那是下午三点,会议室空调开得很足,我套着优衣库那件薄外套,手里揣着打印好的简历,感觉自己有点像被系统踢出的旧缓存。对面的人很稳,敲了敲桌子,把第一个问题丢过来——关于主从复制怎么跑的,你在项目里怎么用的?我先把大体脉络画了个图,配合手势,把整体流程说清楚,再把关键点细化。
当时我先画了个架构图:一个主节点,几台从节点,写都走主,读走从。再用一句接地气的比喻来解释主从分工——主节点负责把最新的状态记录下来,然后把这些变化分发给副本。这样能把读压力分摊出去,提高并发和可用性。说到这里,我补了一句实践中的做法:线上我们通过一层中间件把读写分路,写直接到主,读由负载均衡分摊到多个从上。但也提醒面试官,这么干会有延迟,所以涉及金钱或库存等强一致性的操作必须强制走主库。
接下来我把同步过程拆成几个阶段讲清楚。第一步是建立连接和发起同步请求。当一个从节点启动或重连,它会主动向主节点发起连接并请求同步。第二步是全量复制。如果这是第一次连接,或者从节点中断时间太久,主节点会触发一次全量复制:生成 RDB 快照,把当前数据整包发过去。从节点接收到快照后加载,这是一个完整但耗时的过程。第三步是增量复制。关键点在于生成快照期间主节点不会停止接收写请求,这就需要把这段时间产生的写命令记录下来。主节点会把这些命令暂存到一个复制积压区域,等 RDB 发完,再把这部分增量发给从节点。之后进入实时同步阶段,主节点每写一条命令会被同步到所有从节点。
我还具体说了部分重同步的逻辑。要是从节点短暂断线再连,Redis 会先尝试做部分重同步。从节点会告知主自己同步到哪个偏移量,如果主节点的积压缓冲还保留着那段偏移之后的数据,就可以直接把缺失的增量补上,避免全量复制。这里我着重强调了积压缓冲区大小的影响:在高并发场景下,如果 backlog 太小,断线后可能就没法做部分重同步,只能走全量了,代价明显大。
面试官问到高并发下的风险,我列了几条实际遇到过的问题:主节点可能成为单点瓶颈,复制是异步的会带来数据延迟,从节点过多或网络不稳会给主节点带来同步压力,反而拖慢主的写入性能。对这些问题我也给出过处理办法:用哨兵或 Cluster 做故障转移和分片,读写分离再加中间件限流,关键业务直接走主库保证强一致性。
讲到具体的场景,我把之前的几个项目案例摆出来。想象一个电商系统:首页商品列表、购物车、秒杀库存、用户会话这些都压在 Redis 上。平时负载还好,到了双十一流量像潮水一般涌上来。如果还只有一台 Redis,马上就吃不消。这种场景下,主从复制加读写分离能把读请求分散,但库存类等对一致性要求高的场景要走主节点或用分布式锁、库存预扣策略来保障。面试时我补充说,许多团队在实战里会把热点数据做本地缓存、再用一致性哈希做分片,这些细节能显得更有深度。
我也讲了一个真实经历。之前在一家教育公司做直播抢课的系统,晚上上万人同时抢课,Redis QPS 突然暴涨。项目最开始只用单机 Redis,压力一上来就卡住。后来我们加了从节点、做了读写分离,还在关键路径上加了强制走主的策略和一些限流降级手段。那晚系统没炸,我站在公司天台吹风,觉得像捡回了一条命。那种感觉不好写成总结语,但的确 印象深刻。
面试里我还讲了实用的应试技巧:别只背概念,常常用手画一画数据流向,面试官能更快理解你在说什么。说清楚为什么要这样做,讲清楚边界条件和风险点,会比只背优点更有说服力。我当场把全量复制、增量复制、部分重同步、积压缓冲的关系画在白板上,解释完之后对方连连点头。
最后我提了一句在生产环境常见的配套方案:主从复制一般会配合哨兵来做故障转移,或在需要分片时上 Cluster。每种方案有自己的适用场景和限制,拿到一个业务场景,先把一致性需求、可用性要求和流量特性说清楚,再选对应方案,比单纯背架构要实用得多。
对了,我是小米,31岁,喜爱把这些实战经历写出来分享。那天的面试过去了,但那些细节和那些临场的应对还在记忆里。















暂无评论内容