
一、存储过程
存储过程通常用于封装复杂的业务逻辑或数据库操作,存储过程在数据开发中广泛应用,因其具备以下核心价值:
提升执行效率
预编译的SQL语句集合减少了重复解析和编译的开销,尤其适用于高频调用的复杂操作。批量数据处理场景下,网络传输开销显著降低。
增强安全性与权限控制
通过封装业务逻辑限制直接表访问,仅暴露存储过程接口。结合数据库权限体系实现细粒度的操作授权(如仅允许执行特定存储过程)。
降低网络负载
将多语句逻辑封装为单次调用,减少应用层与数据库的交互次数。对分布式系统或高延迟环境尤为重要。
逻辑复用与标准化
统一业务规则实现,避免代码重复。确保不同应用模块使用一致的计算逻辑,减少维护成本。
简化事务管理
复杂事务可通过存储过程原子化执行,避免应用层处理分布式事务的复杂性。例如跨表更新时自动保证ACID特性。
典型应用场景
ETL流程:定时数据清洗转换任务报表预计算:聚合指标提前计算并缓存API数据层:为微服务提供高效数据访问接口数据迁移:批量历史数据处理
二、存储过程为什么需要挂上处理链?
提高任务执行的自动化程度
处理链允许存储过程在特定条件或时间触发,减少人工干预。例如,在ETL(数据抽取、转换、加载)流程中,多个存储过程可以按依赖关系依次执行,确保数据处理的正确性和完整性。
增强任务间的依赖管理
存储过程可能依赖其他过程或外部数据源完成前置操作。处理链能明确定义执行顺序,避免因依赖缺失导致错误。例如,数据清洗存储过程需在数据导入完成后执行,处理链可自动管理这种依赖关系。
提升错误处理与日志记录能力
处理链通常具备错误捕获和重试机制。如果某个存储过程执行失败,处理链可以记录日志、触发告警或尝试重新执行,提高系统的鲁棒性。
优化资源管理与性能
通过处理链调度,可以控制存储过程的并发执行,避免数据库资源过载。例如,在高峰时段限制某些高消耗存储过程的运行频率,平衡系统负载。
实现复杂的业务逻辑编排
某些业务场景需要结合存储过程、外部脚本和API调用。处理链可作为统一编排工具,协调多种组件的执行。例如,电商系统中的订单处理可能涉及库存更新、支付校验和物流通知,这些步骤可通过处理链串联存储过程完成。
便于监控与维护
处理链通常提供可视化监控界面,管理员可以直观查看存储过程的执行状态、耗时及资源占用情况,便于问题排查和性能优化。
典型应用场景
数据仓库定时作业:每日凌晨自动执行数据聚合存储过程。批量数据处理:按优先级依次运行数据迁移或报表生成存储过程。跨系统集成:在存储过程执行后触发消息队列或API调用。
三、如何把存储过程挂在处理链上执行?
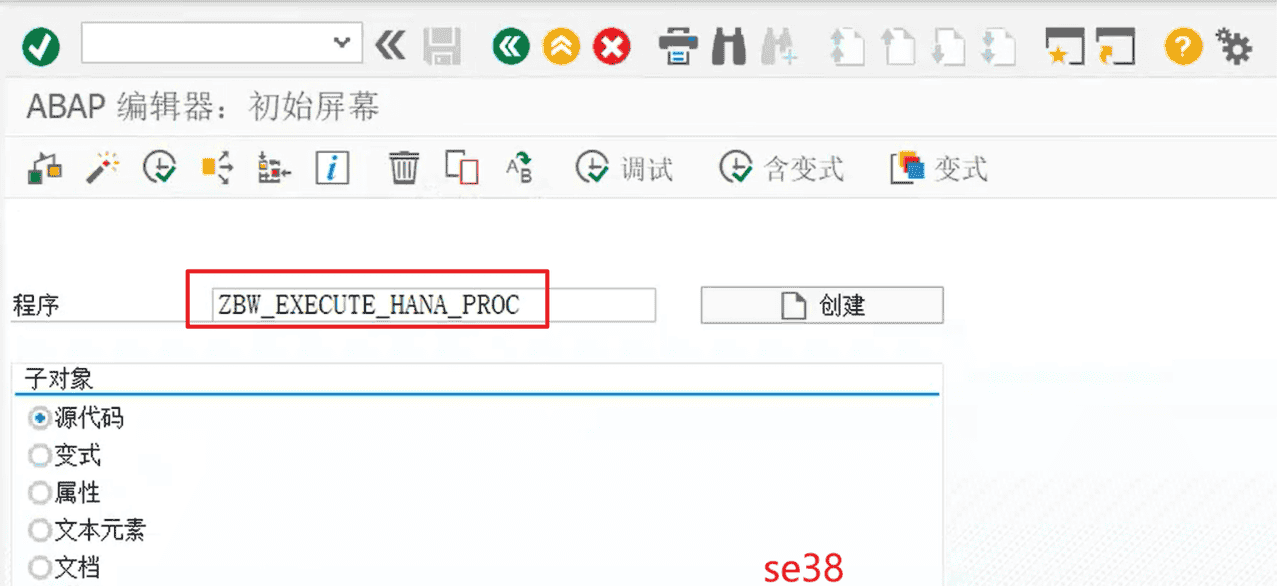
1、编写执行程序
进入SE38,编写调用存储过程的ABAP程序 ZBW_EXECUTE_HANA_PROC ;
程序代码可以参考如下代码:
*&---------------------------------------------------------------------*
*& Report ZBW_EXECUTE_HANA_PROC
*&---------------------------------------------------------------------*
REPORT ZBW_EXECUTE_HANA_PROC.
PARAMETERS:ZVARIANT(2550) TYPE C. "存储过程
DATA remote_exception TYPE REF TO CX_SFW_REMOTE_ERROR.
DATA msg TYPE c LENGTH 255.
DATA:ZRESULT(10) TYPE C.
TYPES:
BEGIN OF result_t,
key TYPE i,
value TYPE string,
END OF result_t.
DATA: stmt_ref TYPE REF TO cl_sql_statement,
cx_sql_exception TYPE REF TO cx_sql_exception,
lv_text TYPE string,
res_ref TYPE REF TO cl_sql_result_set,
d_ref TYPE REF TO DATA,
result_tab TYPE TABLE OF result_t,
result_line TYPE result_t,
row_cnt TYPE i,
con_ref TYPE REF TO cl_sql_connection.
TRY.
con_ref = cl_sql_connection=>get_connection( 'DBMS_USER_MGT' ).
stmt_ref = con_ref->create_statement( ).
CONCATENATE 'CALL ' ZVARIANT ' ()' into lv_text .
* lv_text = 'CALL "CRRC"."CRRC.PRO::SP_CRRC_D" ()'.
stmt_ref = con_ref->create_statement( ).
res_ref = stmt_ref->execute_query( lv_text ).
con_ref->COMMIT( ).
CATCH CX_SFW_REMOTE_ERROR INTO remote_exception.
msg = remote_exception->get_text( ).
WRITE / msg.
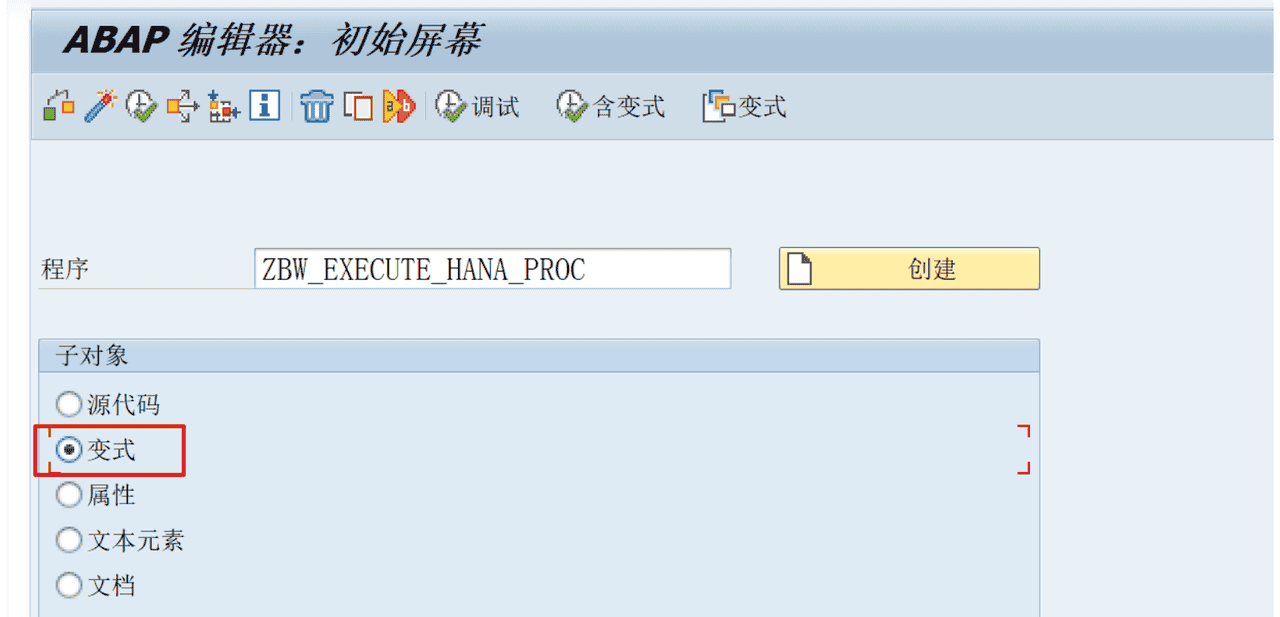
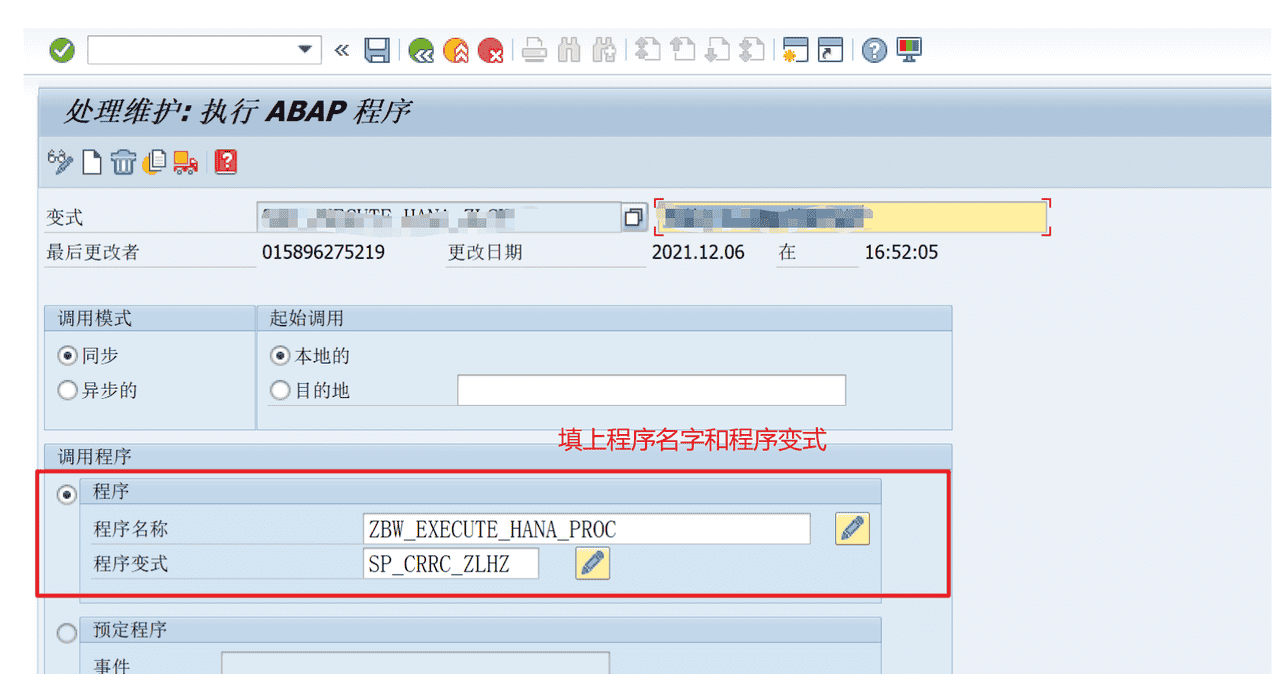
ENDTRY.2、创建程序变式
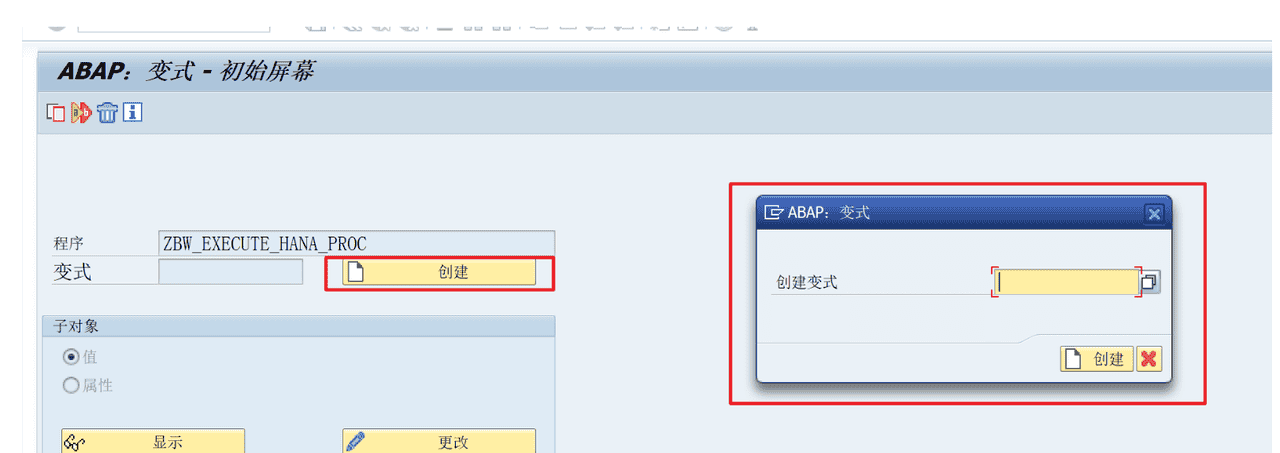
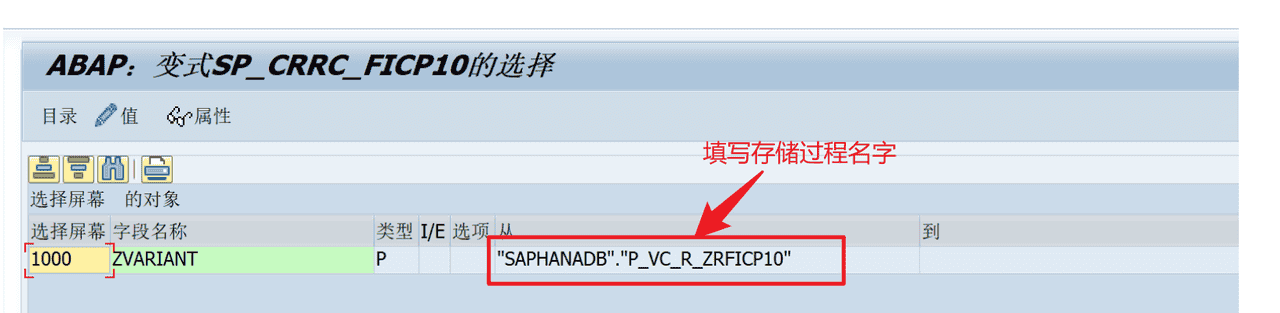
如下图所示操作,创建一个程序变式
3、把ABAP程序挂上处理链
进入RSA1,找到需要挂载的处理链位置,点击对应 编辑
找到 执行ABAP程序;把它拖出来,新建处理链变式,指定要执行的程序和程序变式
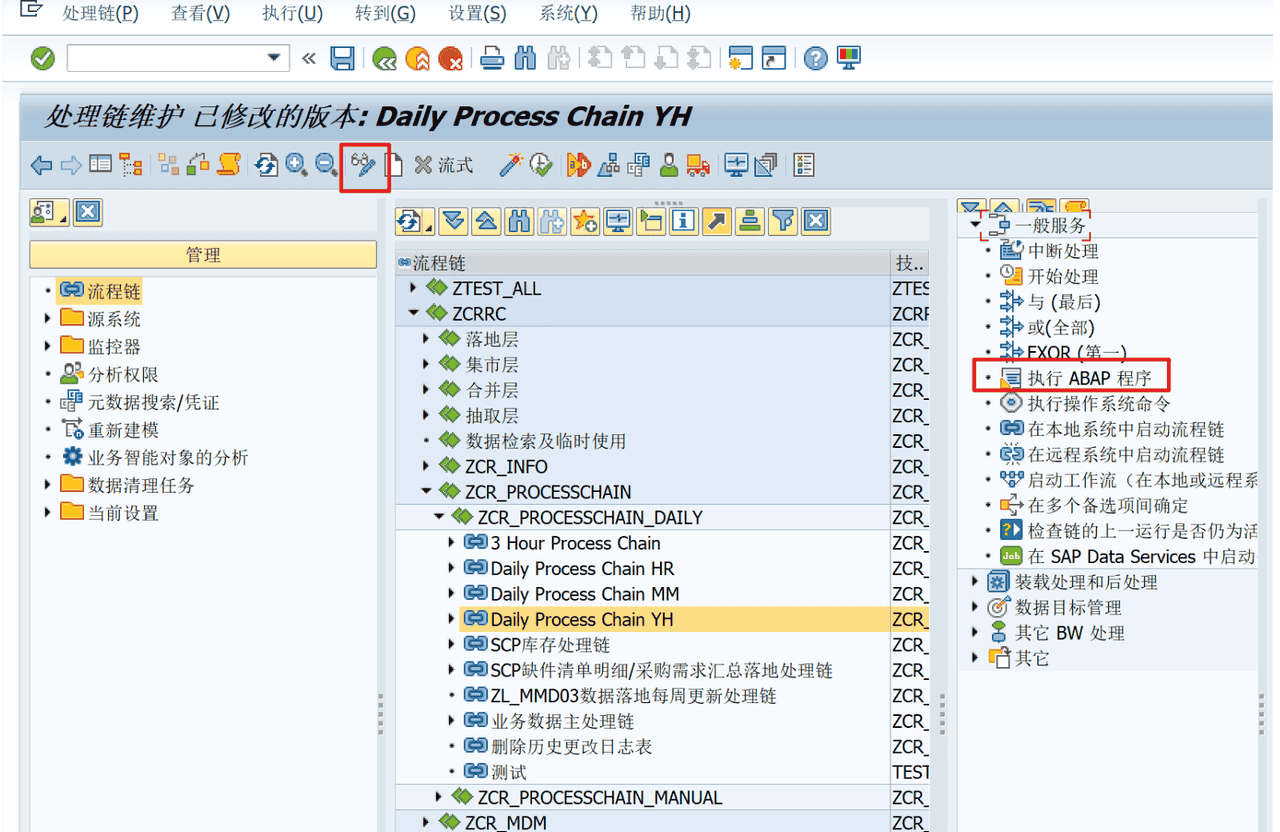
4、连好处理链,保存激活即可
5、测试与验证
手动测试:在处理链界面右键选择「Execute Synchronously」,手动触发执行,查看执行日志(「Goto → Logs」);
结果验证:
查看 BW 处理链日志:确认 “ABAP 程序” 节点状态为 “绿色”(成功);
查看 HANA 执行记录:登录 HANA Studio,执行
SELECT *
FROM SYS.M_EXECUTED_PROCEDURES
WHERE PROCEDURE_NAME = 'ZSP_CUSTOMER_CLEAN'
ORDER BY EXECUTION_TIME DESC验证存储过程是否被调用;
业务数据验证:检查存储过程处理后的目标表数据(如清洗后的客户表)是否符合预期。
四、关键配置要点与易错点
参数传递技巧:
若参数需动态获取(如当前日期、处理链变量),可在 ABAP 程序中通过SY-DATUM(系统日期)、RSPC_VAR_GET(获取处理链变量)实现;
示例:动态传递当前日期作为参数:lv_sql = |CALL ZSCHEMA.ZSP_CLEAN( '{SY-DATUM}', ? )|.
权限常见问题:
若 ABAP 程序执行报错 “权限不足”,需给用户分配S_ADBC_AUTH(ADBC 访问权限)和 HANA 存储过程的EXECUTE权限;
权限分配路径:BW 系统 → PFCG → 角色 → 添加权限对象 → 维护权限值。
性能优化建议:
若存储过程处理数据量较大,建议在处理链中添加 “并行执行” 设置(右键节点 → 「Parallel Processing」);
避免存储过程中包含长时间锁表操作,防止处理链阻塞。
五、监控与故障排查
处理链监控:
路径:BW/4HANA Studio → 「Administration → Process Chains → Monitor」;
查看节点状态:红色(失败)、黄色(警告)、绿色(成功),双击失败节点可查看详细日志。
存储过程执行日志:
HANA 端:查询视图SYS.M_EXECUTED_PROCEDURES(执行历史)、SYS.M_PROCEDURE_ERRORS(错误信息);
示例:查询最近 7 天的错误记录:
SELECT * FROM SYS.M_PROCEDURE_ERRORS
WHERE ERROR_TIME >= CURRENT_DATE – 7
AND PROCEDURE_NAME = 'ZSP_CUSTOMER_CLEAN';
常见故障解决方案:
故障 1:存储过程执行超时 → 检查存储过程逻辑(如是否有冗余查询),调整 HANA 数据库的PROCEDURE_EXECUTION_TIMEOUT参数;
故障 2:参数类型不匹配 → 核对 ABAP 程序中 SQL 语句的参数类型与 HANA 存储过程定义一致(如 VARCHAR 长度、DATE 格式);
故障 3:存储过程不存在 → 确认 Schema 名、存储过程名拼写正确,且已激活(HANA 存储过程需激活后才能执行)。


















暂无评论内容