
前文我们突破了内核大小的限制,这是CPU进保护模式的前提,现在我们正式准备将CPU切换到保护模式了~
保护模式与实模式显著的不同就在于内存寻址方式,实模式只分段,而保护模式采用“分段+分页”的方式。操作系统就是围绕内存转的,而内存不能随便操作,需要符合CPU的段页门机制,不懂道上的规矩,CPU就不听你的哈哈哈。接下来我们看看CPU在不同工作模式下段部件工作原理—分段机制。
CPU内存寻址方式
我们以如下的代码为例子
mov byte ds:[0x100],0
说白了就是往“ds:[0x100]”所指向的内存地址写一个0,其中0x100为段内偏移offset,ds里面的东西指向base,最终要拿到的地址为base+offset,而如何得到base,那就是段部件需要解决的核心问题。
实模式下的分段机制
16位CPU
在16CPU里面,实模式下寄存器只有16位,能找到的地址大小只有64K,但是实模式实际能访问的内存大小为1M,也就是20位地址总线,那么如何从16位地址地址扩展到20位呢,设计者们使用段寄存器左移4位的方法:
base = ds << 4
实际操作地址 = base + offset
= (ds << 4) + offset
32位CPU
在32位CPU里面,实模式的寻址方式不变,唯一不同的就是加了一个高速缓存器而已
保护模式下的分段机制
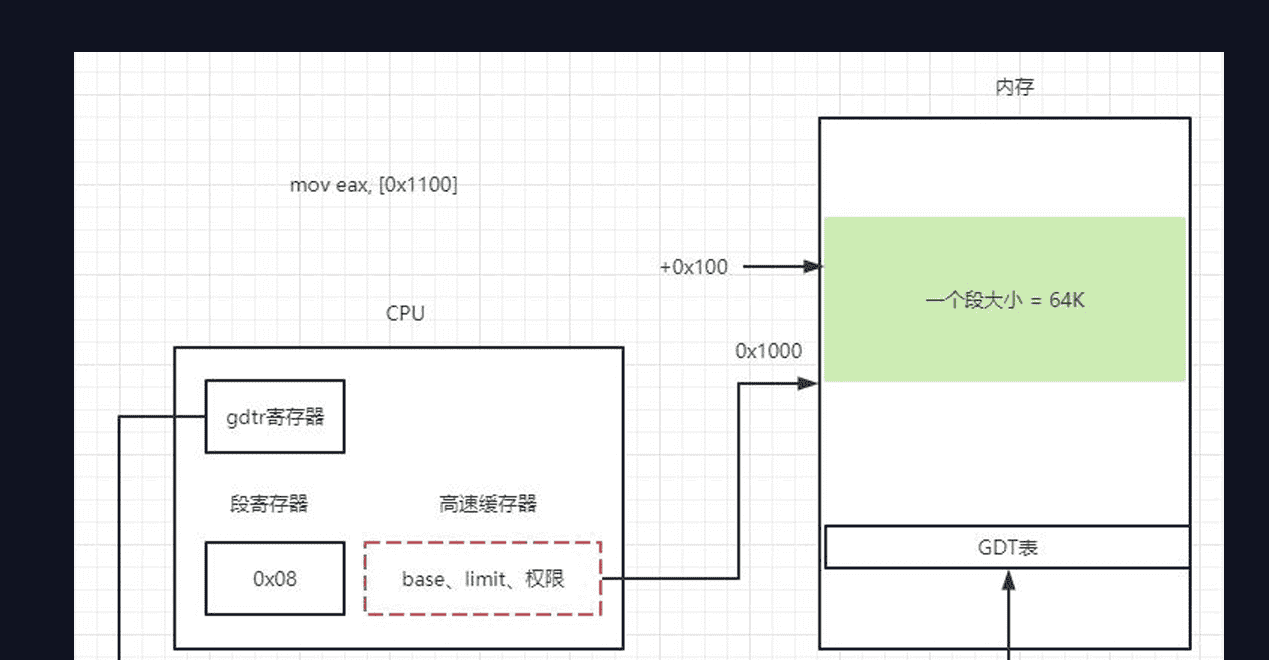
实模式只用分段机制,段部件可以直接找到物理地址。保护模式则不同,段部件得到的是可能是物理地址也可能是虚拟地址,如果是虚拟地址则还需要后面的页部件进行解析得到实际的物理地址,保护模式分段机制使用段描述符表,分GDT和LDT两种,本文使用GDT,同时本节对页部件工作原理不做阐述,只重点探讨段部件工作原理。
1)通过段寄存器的信息得到GDT表的索引
段寄存器中的信息名称和通用寄存器不一样,叫段选择子,占16位,不同段的段寄存器不一样,譬如数据段叫DS,代码段叫CS,段选择子内容如下所示:
![图片[1] - 【让CPU进保护模式之CPU的段部件工作流程以及GDT表格构建思路】 - 鹿快](https://img.lukuai.com/blogimg/20251121/166e62a69d6f43c2b589224d96c14c2e.png)
其中:
index:指的是要查找的GDT表的索引,可以看出12位最多索引8192的段
TI:指的是要查找的表的类型(0就是GDT)
RPL:以什么样的权限去访问段(00 01 10 11分别代表R0 R1 R2 R3)
2)通过gdtr寄存器得到GDT表的基地址
GDT表相当于一个元素占8字节的数组,每个元素都描述了一个段所需要的信息,称为段描述符,我们要让CPU操作位于某个段下的某个地址,首先就需要让CPU找到GDT表的首地址,该首地址通过lgdt指令写入到了gdtr寄存器中:
占据六个字节,高位填充GDT表的基地址,低位填充GDT表占据大小(一般我们设计GDT表大小一页4096字节,可以放512个段描述符,当然设计要求第一个段描述符需要是全0)
3)通过GDT表的索引和基地址得到段描述符
有了GDT表的基地址以及段描述符的索引后,就可以根据这两个参数得到段描述符的位置了
段描述符地址 = index_ds * 8 + base_gdt
4)检查段描述符的权限
GDT表中每个占用八字节的段描述符,其结构如下所示
![图片[2] - 【让CPU进保护模式之CPU的段部件工作流程以及GDT表格构建思路】 - 鹿快](https://img.lukuai.com/blogimg/20251121/b93be5b363bb4938885aeb6f8d0cbc9f.png)
其中base代表该段所在的基地址
limit代表该段所占空间的大小范围
P:表示该段描述符是否有效(1为有效)
DPL:表示可访问该段的权限等级
S:表示该段的类型(1表示数据段或者代码段,0表示系统段)
TYPE:根据S的结果,再次对段类型进行细分
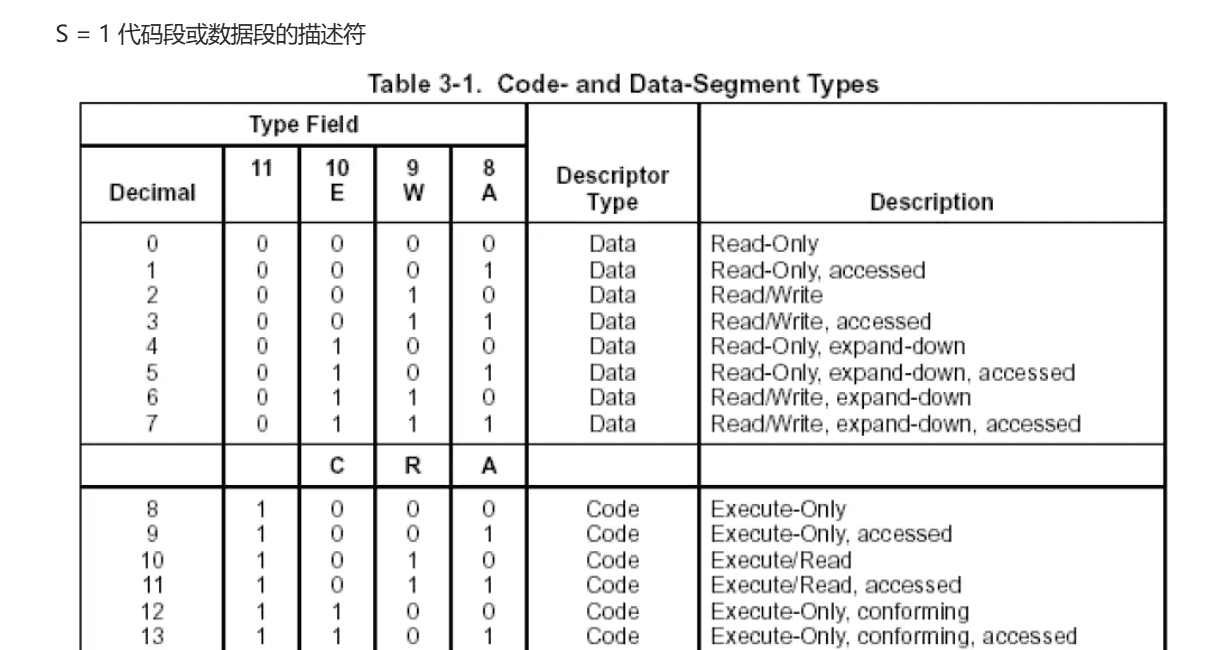
AVL:用户自定义位
D/B:表示16位段还是32位段
G:表示limit的单位(limt最大是20位,如果单位为字节表示1M空间,如果单位为4KB,最大表示到4G空间)
所以在本文的场景下段部件检查过程如下:
1)检查段描述符是否有效,如P为1,则检查通过
2)检查段类型是否是数据段,如果S为1,则检查通过
3)继续检查段类型是否数据段,TYPE表示数据段,则检查通过
4)检查操作权限,如果当前特权等级CPL小于等于段描述等级DPL,则检查通过
5)得到base+offset
5)结合段的base地址和程序指定的offset得到最终的操作地址
检查base+offset是否超过base+limit,如果没有,则输出base+offset
构建GDT表
既然已经知道了保护模式下段部件工作流程,那可想而知GDT表是一切的基础,GDT表是若干段描述符的集合,构建GDT表的过程就是设计段(类型,基地址,limit,权限等)的过程,那我们可以做两个练习,练习非常重要,是后面写操作系统的基础。
汇编构建代码段(32位 0~4G)
代码如下:
1)定义base和Limit
base = 0
limit = 0xFFFFF
2)填充limit的低16位(两个字节)
dw limit & 0xffff
3)填充base的低16位(两个字节)
dw base & 0xffff
4)填充base的16~23位(一个字节)
db (base >> 16) & 0xff
5)填充高8~15位(一个字节)
db 0b1_00_1_1000
1:p位为1代表该描述符为有效描述符
00:DPL为0代表可访问权限必须为最高等级
1:s位为1代表数据段或者代码段
1000:TYPE为1000代表为代码段
6)填充高16~23位(一个字节)
db 0b1_1_0_0_0000 | (limit >> 16 & 0xf)
1:G位为1代表单位为4KB
1:DB位为1代表32位
0:默认值
0:AVL为0没有任何含义预留项
limit >> 16 & 0xf :limit的高4位
7)填充base段的高8位(一个字节)
db base >> 24 & 0xff
汇编构建数据段(32位 0~4G)
有了上面代码段的基础,我们构建数据段就简单很多了
1)标识变量:
base = 0
limit = 0xFFFFF
2)填充limit的低16位(两个字节)
dw limit & 0xFFFF
3)填充base的低16位(两个字节)
dw base & 0xffff
4)填充base的16~23位(一个字节)
db (base >> 16) & 0xFF
5)填充段描述符有效位、访问权限位、类型位
(p为1,DPL为00,S为1,Type为0010)
db 1_00_1_0010
6)填充单位位、DB位以及limit的高4位(一个字节)
(G为1,DB为1,AVL为00)
db 1_0_0_0_0000 | (limit >> 16 & 0xF)
7)填充base的24~31位(一个字节)
db base >> 24 & 0xFF



![[C++探索之旅] 第一部分第十一课:小练习,猜单词 - 鹿快](https://img.lukuai.com/blogimg/20251015/da217e2245754101b3d2ef80869e9de2.jpg)













暂无评论内容