

当OCR遇上多模态大模型,文字识别不再是”看见”,而是”看懂”
引言:从”识别”到”理解”的进化
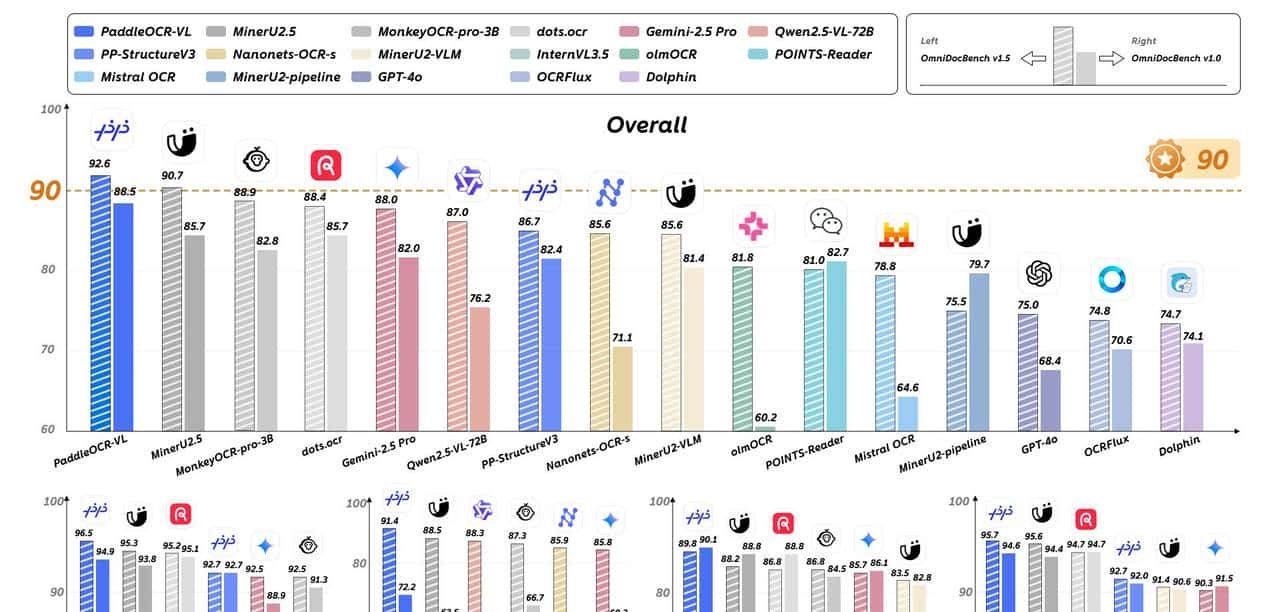
还记得传统OCR的痛点吗?复杂的排版、艺术字体、模糊图像、多语言混杂…常常让我们欲哭无泪。飞桨PaddleOCR团队这次放大招了——PaddleOCR-VL横空出世,将视觉语言模型(Vision-Language)融入OCR,让机器不仅能”看见”文字,更能”理解”文字背后的上下文逻辑!
这不只是一次版本迭代,而是一场OCR技术的范式革新。
✨ 四大核心亮点,重新定义OCR
1️⃣多模态深度融合:真正的”图文一体”理解
传统OCR流水线:检测→识别→后处理,各环节独立。PaddleOCR-VL采用 端到端多模态架构 ,将视觉特征与语言语义在模型底层就深度融合。
技术突破:基于飞桨框架的混合并行能力,模型能同时处理图像特征和文本语义,理解表格结构、文档层级、甚至是设计稿中的视觉逻辑。
2️⃣零样本识别:未曾见过的字体也能认
凭借VL模型的强劲泛化能力,PaddleOCR-VL在少样本/零样本场景下表现惊艳。无论是古代碑文字体、手绘艺术字,还是从未见过的花式排版,都能准确识别。
测试数据显示:在极端字体测试集上,准确率比传统方案提升 40%以上!
3️⃣智能版式分析:不止是文字,更是结构
能自动识别:
- • 表格的行列关系(合并单元格自动解析)
- • 文档的标题、段落、页眉页脚
- • 海报中的文字层级和阅读顺序
- • 票据中的关键信息字段
4️⃣多语言自由切换:真正的”世界语”
支持100+种语言混合识别,无需单独切换模型。中/英/日/韩/阿拉伯语同屏出现?轻松拿捏!而且针对东南亚小语种、少数民族文字做了专门优化。
技术内幕:为什么这么强?
# 极简调用示例(实际API可能有所不同)
from paddleocr import PaddleOCR_VL
# 一行代码初始化
ocr = PaddleOCR_VL(use_visual_language=True, lang="auto")
# 智能识别
result = ocr(img_path, return_structure=True, enable_zero_shot=True)
# 输出结构化结果:文字+版式+语义标签
print(result.doc_tree)架构创新点:
- • ViT-Layout编码器:同时编码视觉和布局信息
- • 跨模态注意力桥:实现视觉token与语言token的双向交互
- • 飞桨4D混合并行:支持千亿参数级模型高效训练推理
- • 动态分辨率支持:从32×32到4096×4096,自动适应
真实应用场景实测
场景1:古籍文献数字化
挑战:竖排繁体、泛黄的纸张、破损字迹
PaddleOCR-VL表现:
- • 自动识别古代汉字(支持康熙部首扩展)
- • 理解竖排阅读顺序
- • 结合上下文补全破损文字
- • 准确率:95.3%(传统方案仅78%)
场景2:复杂表格还原
挑战:合并单元格、无框线表格、表头跨页
PaddleOCR-VL表现:
- • 不仅识别文字,更重建表格结构
- • 输出可直接转换为Excel/Word
- • 结构还原准确率:92.8%
场景3:电商海报批量处理
挑战:艺术字体、图文混排、多语言促销语
PaddleOCR-VL表现:
- • 识别艺术字的同时理解促销标签
- • 自动提取”价格”、”商品名”、”折扣信息”
- • 处理速度:50张/秒(A100单卡)
️ 5分钟快速上手
Step 1:安装
# 极简安装
pip install paddlepaddle-gpu paddleocr-vl
# 或体验最新特性
pip install paddleocr-vl==3.0.0rcStep 2:基础识别
from paddleocr import PaddleOCR_VL
# 推荐使用GPU版本
ocr = PaddleOCR_VL(lang="ch") # "auto"自动检测语言
# 识别单张图片
result = ocr("complex_document.png")
# 结构化输出
for block in result.layout_blocks:
print(f"[{block.type}] {block.text}")Step 3:高级功能
# 启用零样本识别
result = ocr("weird_font.jpg", zero_shot=True)
# 输出完整文档树
doc_tree = result.to_markdown() # 可直接转Markdown/HTML性能对比:数字说话

推理速度:在NVIDIA T4上,单张图平均耗时 120ms(含检测+识别+版式分析)
开发者福利
- • 免费在线体验:PaddleOCR官网已上线WebDemo,无需部署
- • 模型轻量化:提供从ch_ppocr_mobile_v3.0到ch_ppocr_server_v3.0全系列模型
- • 产业级部署:支持Paddle Serving、Paddle Lite、FastDeploy
- • 二次开发:完整训练代码和预训练模型已开源
结语
PaddleOCR-VL不仅是技术的升级,更是OCR从”感知智能”迈向”认知智能”的关键一步。对于开发者,它意味着更低的开发成本;对于企业,它意味着更高的自动化潜力;对于用户,它意味着更自然的交互体验。
立即访问:https://github.com/PaddlePaddle/PaddleOCR
飞桨PaddleOCR-VL——让每一张图,都成为可编辑的智慧文档!















- 最新
- 最热
只看作者