

无需卷积,直接关注全局,Vision Transformer正在重新定义计算机视觉的规则。
在传统的计算机视觉领域,卷积神经网络(CNN)长期占据主导地位。但2020年,谷歌研究人员提出了一种全新方法——Vision Transformer(ViT),它将自然语言处理中大放异彩的Transformer架构创新性地应用于图像识别任务,开启了计算机视觉的新时代。
ViT的核心思想是将图像分割为固定大小的图像块(patches),将这些图像块视为序列数据,然后使用标准的Transformer编码器进行处理。这种方法使模型能够从一开始就捕捉图像的全局上下文信息,而非像CNN那样逐步扩展感受野。
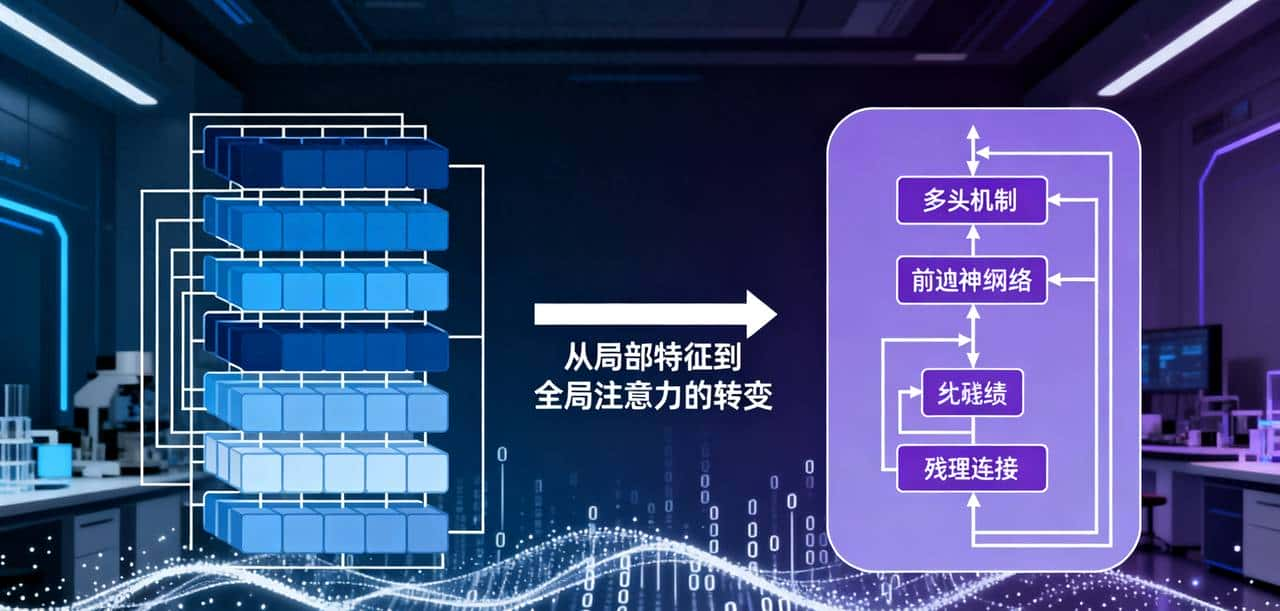
ViT的核心原理
与传统CNN不同,ViT不依赖于卷积操作,而是完全基于自注意力机制。其处理过程主要包括以下几个关键步骤:
- 图像分块:将输入图像划分为固定大小的块(如16×16像素)。例如,一张224×224的图像会被分成196个块。

- 线性投影:每个图像块被展平并通过线性投影转换为向量表明,这个过程称为Patch Embedding。
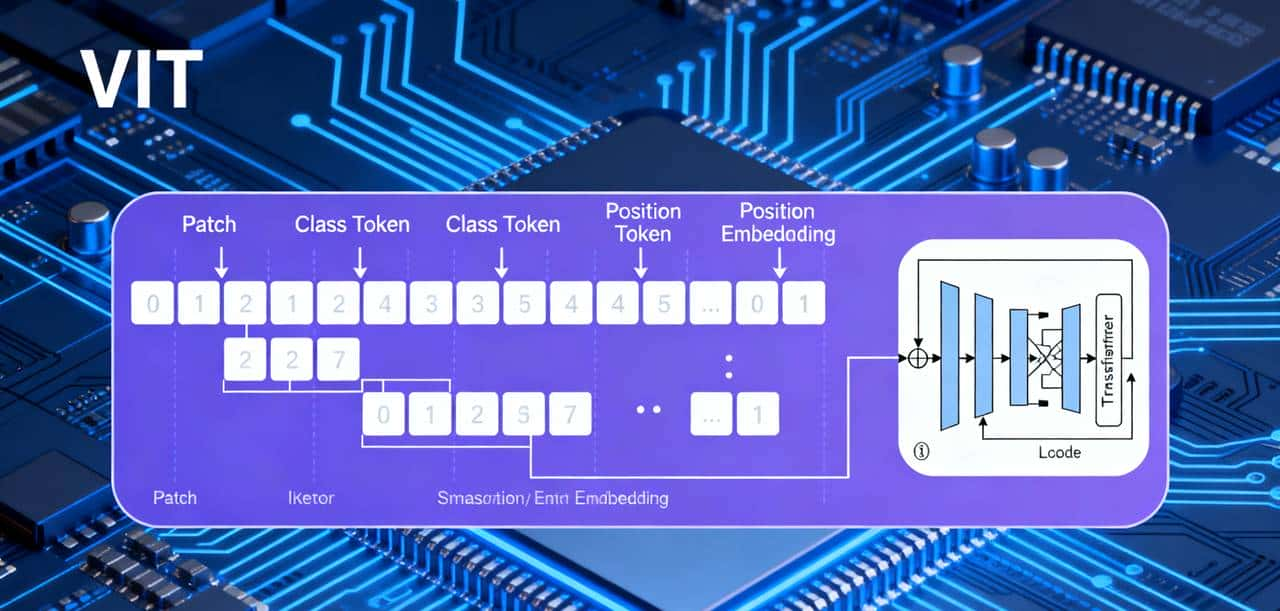
- 位置编码:由于Transformer本身不具备空间感知能力,需要添加可学习的位置编码来保留图像块的空间位置信息。
- Transformer编码器:处理后的图像块序列输入到由多头自注意力机制和前馈网络组成的Transformer编码器中。
- 分类头:最终使用[CLS] token的输出通过全连接层进行分类预测。
ViT的这种结构使其在大规模数据集上表现出色,尤其是在需要全局上下文理解的任务中,其性能往往优于传统CNN模型。
ViT与CNN的关键区别
ViT与CNN在多个方面存在显著差异:
|
对比点 |
CNN |
Vision Transformer |
|
感受野 |
局部卷积,逐层扩展 |
全局建模 |
|
参数共享 |
卷积核参数共享 |
不共享 |
|
归纳偏置 |
强(平移不变性、局部性) |
弱(需要更多数据学习) |
|
数据需求 |
中等 |
大量数据 |
如何部署和使用ViT
接下来,我们将详细讲解如何在实践中部署和使用ViT进行图像分类任务。
环境配置
第一需要配置合适的开发环境。推荐使用Python 3.9及以上版本和PyTorch框架:
# 创建虚拟环境
conda create -n vit_env python=3.9
conda activate vit_env
# 安装核心依赖库
pip install torch torchvision matplotlib pillow
# 如果需要使用预训练模型,还可以安装timm库
pip install timm加载预训练模型
使用PyTorch和torchvision可以轻松加载预训练的ViT模型:
import torch
from torchvision.models import vit_b_16, ViT_B_16_Weights
from PIL import Image
# 加载预训练模型和权重
weights = ViT_B_16_Weights.IMAGENET1K_V1
model = vit_b_16(weights=weights)
model.eval() # 设置为评估模式
# 获取图像预处理函数
preprocess = weights.transforms()
# 加载和预处理图像
image = Image.open("your_image.jpg").convert("RGB")
input_tensor = preprocess(image).unsqueeze(0) # 添加批次维度
# 模型推理
with torch.no_grad():
output = model(input_tensor)
prediction = output.argmax(dim=1).item()
print(f"预测类别: {prediction}")图像预处理
ViT模型需要特定的图像预处理流程,包括调整大小、归一化等:
from torchvision import transforms
# 定义预处理流程
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
),
])创建交互式应用
可以使用ipywidgets创建交互式界面,让用户上传图像并查看实时预测结果:
import ipywidgets as widgets
from IPython.display import display, HTML
import matplotlib.pyplot as plt
# 创建文件上传控件
upload = widgets.FileUpload(accept='image/*', multiple=False)
display(upload)
def on_upload_change(change):
# 处理上传的图像
uploaded_image = Image.open(io.BytesIO(upload.value[0]['content']))
# 预处理和模型推理
input_tensor = preprocess(uploaded_image).unsqueeze(0)
with torch.no_grad():
output = model(input_tensor)
probs = torch.nn.functional.softmax(output[0], dim=0)
# 显示结果
plt.imshow(uploaded_image)
plt.axis('off')
plt.title(f'预测结果: {predicted_label}
置信度: {confidence:.2f}%')
plt.show()
upload.observe(on_upload_change, names='value')模型微调
对于特定领域(如花卉分类),可以使用预训练ViT模型进行微调:
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.datasets import Oxford102Flowers
# 定义微调模型
class ViTForFlowerClassification(nn.Module):
def __init__(self, num_classes=102):
super().__init__()
self.vit = vit_b_16(weights=ViT_B_16_Weights.IMAGENET1K_V1)
self.classifier = nn.Linear(1000, num_classes)
def forward(self, x):
x = self.vit(x)
x = self.classifier(x)
return x
# 准备数据集
train_dataset = Oxford102Flowers(
root='./data',
split='train',
transform=preprocess,
download=True
)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 初始化模型、损失函数和优化器
model = ViTForFlowerClassification(num_classes=102)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 训练循环
for epoch in range(10):
for images, labels in train_loader:
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/10], Loss: {loss.item():.4f}')模型部署到移动设备
为了在资源受限的设备上部署ViT模型,可以进行模型量化和优化:
# 导出ONNX格式模型
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(
model,
dummy_input,
"vit_model.onnx",
opset_version=14,
input_names=['input'],
output_names=['output']
)
# 转换为RKNN格式(用于瑞芯微等嵌入式芯片)
from rknn.api import RKNN
rknn = RKNN(verbose=True)
rknn.config(mean_values=[[123.675, 116.28, 103.53]],
std_values=[[58.395, 58.395, 58.395]])
rknn.load_onnx(model="vit_model.onnx")
rknn.build(do_quantization=True, dataset='dataset.txt')
rknn.export_rknn('vit_model.rknn')
rknn.release()ViT的应用场景
ViT已经在多个计算机视觉任务中展现出强劲能力:
- 图像分类:ViT在大规模图像分类任务(如ImageNet)上表现优异,尤其擅长处理需要全局上下文理解的复杂图像。
- 目标检测与分割:ViT的变体(如DETR)用于目标检测和分割任务,通过自注意力机制直接建模全局关系,简化了传统方法中的区域提议网络。
- 医学影像分析:在医疗领域,ViT用于X光、MRI和CT影像的分析,能够准确识别肿瘤和异常区域。
- 多模态任务:ViT处理不同尺寸输入的能力使其适用于视频理解、图像生成等多模态任务。
ViT面临的挑战与未来方向
尽管ViT表现出色,但仍面临一些挑战:
- 计算复杂度:自注意力机制的二次复杂度使得处理高分辨率图像时计算成本较高。
- 数据需求:ViT需要大量训练数据才能发挥最佳性能,在小数据集上可能表现不佳。
- 局部特征捕捉:由于缺乏CNN固有的归纳偏置,ViT在捕捉局部特征方面有时不如CNN。
未来,我们可以期待更多优化和改善,如线性注意力机制、分层结构和更好的预训练策略,这些进步将进一步提高ViT的效率和适用性。
Vision Transformer代表了计算机视觉领域的一次范式转变,从依赖卷积操作的局部处理转向基于自注意力的全局建模。尽管面临挑战,但其卓越的性能和灵活性使其成为计算机视觉领域的重大工具。
随着计算资源的普及和架构优化的不断深入,ViT有望在更多实际应用场景中发挥重大作用,从自动驾驶到医疗影像分析,从工业检测到日常娱乐,改变我们处理和理解视觉信息的方式。
进一步学习资源:
- ViT原始论文:An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale https://arxiv.org/abs/2010.11929
- PyTor官方文档:Torchvision Models https://docs.pytorch.org/vision/stable/models.html
- Timm库:预训练视觉模型集合 https://github.com/rwightman/pytorch-image-models
希望本文能协助您理解和应用这一强劲的计算机视觉新范式。



















暂无评论内容