
我将为您提供一个全面、现代化且可落地的AI应用技术方案。
这个方案将采用分层架构,并特别关注成本控制、性能优化和可扩展性。我们将以一个典型的、集成了长记忆(RAG)和多种AI能力的应用为例。
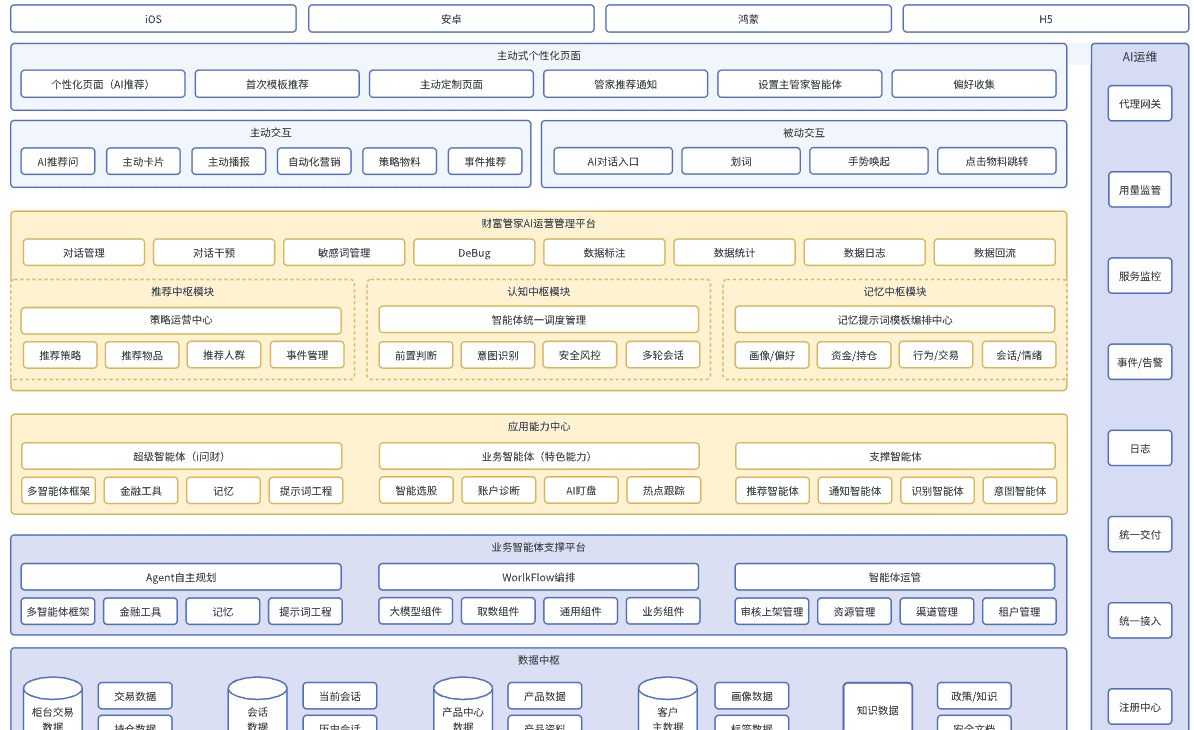
🏗️ 整体技术架构图
首先,通过下面这张图可以直观地看到整个AI应用的技术栈全貌:
📱 前端层
目标:提供流畅、响应式的用户界面,支持复杂的AI交互(如流式响应、文件上传等)。
| 技术选型 | 推荐方案 | 理由 |
|---|---|---|
| Web端 | Next.js (React) | 全栈能力、SEO友好、API Routes简化开发、优秀的流式响应支持。 |
| 移动端 | React Native 或 Flutter | 跨平台、高性能、成熟生态。如团队有React经验,首选React Native。 |
| 小程序 | 原生开发 或 Taro | 覆盖微信生态,Taro支持多端统一。 |
| 关键UI库 | Tailwind CSS + shadcn/ui | 快速构建美观、一致的界面,高度可定制。 |
| 状态管理 | Zustand 或 TanStack Query | 轻量、易用,完美处理服务器状态和异步数据。 |
前端核心特性:
流式输出:使用Server-Sent Events或WebSocket接收模型逐个Token的输出,提升用户体验。文件上传:支持文档、图片上传,并实时显示处理状态。对话界面:类ChatGPT的聊天界面,支持消息编辑、重新生成等。
⚙️ 后端与AI服务层
这是AI应用的核心,我们将其细分为几个关键部分。
1. AI网关 & 模型路由
技术选型:LiteLLM 或 OpenAI API 兼容网关
作用:
统一接口:将不同厂商的API(OpenAI, Anthropic, 国内模型)封装为统一的OpenAI格式。智能路由:根据模型类型、成本、延迟自动选择最合适的供应商。负载均衡:在多个API密钥或多个模型实例间平衡负载。限流与降级:防止超额消费,在主要供应商故障时自动切换到备用方案。成本监控:实时追踪每个请求的成本。
2. 核心后端
技术选型:Python FastAPI 或 Node.js (NestJS)
理由:
FastAPI:天生异步、自动生成API文档、高性能,是AI应用的首选。NestJS:架构清晰、TypeScript支持,适合大型团队协作。
核心模块:
用户认证:JWT或OAuth 2.0。对话管理:管理聊天会话、保存历史。RAG管道:实现“长记忆”的核心。文件处理:解析用户上传的PDF、Word、PPT等文件。计费与额度控制:管理用户的使用量。
3. 任务队列
技术选型:Celery (Python) 或 Bull (Node.js) + Redis
作用:
异步处理:将耗时的任务(如文档解析、向量化、大文件处理)放入队列,避免阻塞HTTP请求。可靠性:任务失败后可重试。
🗄️ 数据与记忆层
这是实现“长记忆”和业务持久化的基础。
| 存储类型 | 技术选型 | 用途 |
|---|---|---|
| 向量数据库 | Pinecone / Qdrant / Chroma | 存储文本嵌入向量,用于RAG的语义搜索。Pinecone是全托管服务,Qdrant可自建,Chroma轻量适合原型。 |
| 业务数据库 | PostgreSQL | 存储用户信息、聊天记录、订单等所有结构化数据。 |
| 对象存储 | AWS S3 / MinIO / 阿里云OSS | 存储用户上传的原始文件(PDF、图片等)。 |
| 缓存 | Redis | 缓存会话、频繁访问的数据、作为任务队列的中间件。 |
🚀 基础设施与运维
技术选型:Docker + Kubernetes
容器化:所有服务都打包成Docker镜像,保证环境一致性。编排:K8s提供自动扩缩容、服务发现、高可用性。对于初创项目,可以使用更简单的 Docker Compose。
监控与日志:
Prometheus + Grafana:收集和可视化指标(QPS、延迟、错误率)。Loki:收集日志。Sentry:错误追踪。
🧠 AI能力实现方案
1. 长记忆实现
这是通过 RAG 流水线实现的:
# 简化的RAG流程代码示例
def rag_pipeline(user_query, user_id):
# 1. 检索
query_embedding = get_embedding(user_query) # 使用text-embedding模型
relevant_chunks = vector_db.similarity_search(query_embedding, filter={"user_id": user_id})
# 2. 增强
context = "
".join([chunk.text for chunk in relevant_chunks])
augmented_prompt = f"""
请根据以下背景信息回答问题:
{context}
问题:{user_query}
"""
# 3. 生成
response = llm_generate(augmented_prompt) # 通过AI Gateway调用大模型
return response
文档处理流程:
加载:使用
Unstructured
PyMuPDF
LangChain
RecursiveTextSplitter
text-embedding-3-small
2. 模型选型策略
主力模型:
GPT-4o
Claude 3.5 Sonnet
GPT-3.5-Turbo
DeepSeek
text-embedding-3-small
Fine-tuning
LoRA
💰 成本控制与优化策略
这是AI应用生存的关键!
缓存:对常见问题的回答进行缓存,避免重复调用模型。模型阶梯:根据查询复杂度动态选择模型(简单问题用便宜模型)。提示词优化:设计精炼的提示词,减少不必要的Token消耗。用量限制:为用户设置每日/月度使用上限。监控告警:设置成本阈值,异常时短信/邮件告警。
🎯 总结:推荐的技术栈组合
对于大多数初创团队,我推荐这个 “黄金组合”:
前端:Next.js + Tailwind CSS + Vercel部署后端:Python FastAPI + LiteLLM数据:PostgreSQL + Redis + Qdrant基础设施:Docker + 云服务(如Vercel/Heroku用于原型,AWS/Aliyun用于生产)AI核心:OpenAI GPT-4o + text-embedding-3-small + RAG
这个方案平衡了开发效率、性能、成本和可扩展性,您可以根据团队的技术背景和具体业务需求进行调整。
















暂无评论内容