
The Spectre class of hardware vulnerabilities truly is a gift that keeps on giving. New variants are still being discovered in current CPUs nearly eight years after the disclosure of this problem, and developers are still working to minimize the performance costs that come from defending against it. The masked user-space access mechanism is a case in point: it reduces the cost of defending against some speculative attacks, but it brought some challenges of its own that are only now being addressed.
Spectre 类硬件漏洞真是“源源不断的麻烦”。自从这个问题被披露近八年后,新的变种仍在现有 CPU 中被发现,开发者仍在努力降低防御这些漏洞所带来的性能损耗。掩码用户空间访问机制就是一个典型例子:它降低了防御某些推测性攻击的成本,但也带来了一些自身的挑战,而这些挑战直到现在才被解决。
The Spectre vulnerabilities can be used to exfiltrate data from the kernel in a number of ways, but the attacks usually come down to exercising a kernel path that will speculatively execute with an attacker-provided address, leaving traces of the target data that can then be recovered via a side channel. One of the most common ways to defeat such attacks is to simply prevent speculative execution of some code; it is effective, but also expensive.
Spectre 漏洞可以通过多种方式从内核中窃取数据,但攻击通常归结为利用内核路径对攻击者提供的地址进行推测性执行,从而在目标数据上留下可通过侧信道恢复的痕迹。击败此类攻击的最常见方法之一是简单地阻止某些代码的推测性执行;这种方法有效,但代价也很高。
Defending user-space access
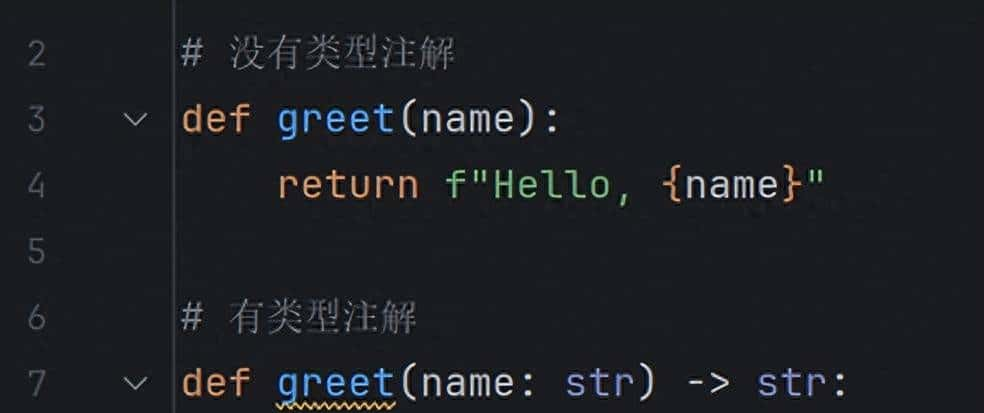
One common target for speculative attacks is accesses to user space by the kernel, since the address in question is often controlled by user space. Since the tests for the validity of an address nearly always succeed, speculative execution tends to take the “address is valid” path, even when the address is anything but. The functions used by most of the kernel for user-space access (such as copy_from_user()) are well defended, but the kernel has a number of places where faster access is required for acceptable performance. This can especially be a concern when multiple accesses to user space are required. Code in such situations tends to use a pattern like this one from the 6.10 implementation of the select() system call, which only incurs the cost for the speculation defense once but performs two reads:
防御用户空间访问
推测性攻击的一个常见目标是内核对用户空间的访问,因为相关地址通常由用户空间控制。由于地址有效性检查几乎总是通过,推测性执行往往会走“地址有效”的路径,即使实际地址根本不是有效的。大多数内核用于用户空间访问的函数(如 copy_from_user())都有良好的防护,但内核中也有一些地方需要更快的访问速度以保证性能。尤其是当需要对用户空间进行多次访问时,这可能成为一个问题。在这种情况下的代码往往采用类似 6.10 版本 select() 系统调用实现中的模式,只需支付一次推测防护的代价,但进行两次读取:
if (from) {
if (!user_read_access_begin(from, sizeof(*from)))
return -EFAULT;
unsafe_get_user(to->p, &from->p, Efault);
unsafe_get_user(to->size, &from->size, Efault);
user_read_access_end();
}
return 0;
Efault:
user_access_end();
return -EFAULT;The user_read_access_begin() call is implemented as a chain of macros before finally doing two things: enabling user-space access with a STAC instruction, and blocking speculation with an LFENCE instruction. The unsafe_get_user() macros, which include a jump to Efault on error, can then be used to access the relevant data. Finally, user_read_access_end() and user_access_end() both boil down to a CLAC instruction to re-enable supervisor mode access prevention; an important step that, if forgotten, can leave the kernel open to other attacks. The STAC/CLAC pair is unavoidable, but it would be nice to do away with the costly LFENCE if possible.
user_read_access_begin() 调用通过一系列宏实现,最终完成两件事:使用 STAC 指令启用用户空间访问,以及使用 LFENCE 指令阻止推测性执行。unsafe_get_user() 宏(在出错时跳转到 Efault)随后用于访问相关数据。最后,user_read_access_end() 和 user_access_end() 都归结为 CLAC 指令,用于重新启用特权模式下的访问防护;这是一个关键步骤,如果忘记执行,可能使内核暴露于其他攻击之下。STAC/CLAC 对是不可避免的,但如果可能的话,最好能够去掉代价高昂的 LFENCE。
Defense without fences
The first commit in the 6.11 merge window was this change from Linus Torvalds adding a new mechanism that he called “user address masking”. It uses a relatively simple trick to avoid the LFENCE instruction, ensuring that any attempt at kernel-space access with a supposedly user-space address will fail. There were two new macros:
无栅栏防御
6.11 合并窗口的第一个提交是 Linus Torvalds 添加的新机制,他称之为“用户地址掩码”。它使用一个相对简单的技巧来避免使用 LFENCE 指令,从而确保任何使用所谓用户空间地址尝试访问内核空间的操作都会失败。引入了两个新宏:
#define mask_user_address(x) ((typeof(x))((long)(x)|((long)(x)>>63)))
#define masked_user_access_begin(x) ({ __uaccess_begin(); mask_user_address(x); })Passing a pointer to mask_user_address() will perform a logical OR of the address with a version of itself right-shifted by 63 bits. The sign-extension performed by the x86 CPU means that, if the address is in kernel space (the topmost bit is one), the resulting address will be all ones, which is not valid. Any speculation involving a kernel-space address will, as a result, fail on the invalid access. Since exploitable speculation can no longer happen, there is no longer any need for the LFENCE instruction.
将指针传递给 mask_user_address() 会将该地址与自身右移 63 位后的结果进行逻辑或运算。x86 CPU 的符号扩展意味着,如果地址在内核空间(最高位为 1),结果地址将全为 1,这是无效的。因此,任何涉及内核空间地址的推测性执行都会因无效访问而失败。由于无法再发生可利用的推测执行,因此 LFENCE 指令不再需要。
(For the curious, the implementation of these macros was changed in 6.14, making them quite different from the original in current kernels; amusingly, they no longer involve masking. The end result is the same, though, and the “masked access” term is still used.)
(对于好奇的人来说,这些宏的实现方式在 6.14 中发生了变化,与当前内核中的原始版本大不相同;有趣的是,它们不再涉及掩码操作。不过最终效果是相同的,“masked access”这个术语仍然被使用。)
Masked access can accelerate performance-sensitive operations, but it has a small disadvantage: it is not supported by all architectures. So code that uses this feature must be prepared to fall back to the previous method on architectures where masked access is not available. The select() code shown above is, as a result, in 6.17, written as:
掩码访问可以加速性能敏感的操作,但它有一个小缺点:并非所有架构都支持。因此,使用该特性的代码必须准备在不支持掩码访问的架构上回退到之前的方法。因此,上述 select() 代码在 6.17 中写作如下:
if (from) {
if (can_do_masked_user_access())
from = masked_user_access_begin(from);
else if (!user_read_access_begin(from, sizeof(*from)))
return -EFAULT;
unsafe_get_user(to->p, &from->p, Efault);
unsafe_get_user(to->size, &from->size, Efault);
user_read_access_end();
}
Efault:
user_access_end();
return -EFAULT;The code is faster, but has also become more complex.
代码更快了,但也变得更复杂。
Using scopes
As Thomas Gleixner pointed out in this patch series, all that code to read two user-space values is just the sort of “tedious” boilerplate that offers numerous opportunities for security-critical mistakes. As the use of the masked-access primitives grows over time, the chances of introducing new bugs will grow as well. He set out to improve this pattern using the kernel's scoped primitives to ensure that the proper cleanup is done once the access is complete. The result in the current version of the series is three new macros:
使用作用域
正如 Thomas Gleixner 在这一系列补丁中指出的,读取两个用户空间值的所有代码只是那种“繁琐”的模板代码,非常容易引入安全关键的错误。随着掩码访问原语的使用越来越多,引入新 bug 的机会也会增加。他着手使用内核的作用域原语来改进这一模式,以确保在访问完成后正确执行清理操作。目前版本中引入了三个新宏:
scoped_user_read_access(address, label)
scoped_user_write_access(address, label)
scoped_user_rw_access(address, label)Each of these starts a new block and speculation-proofs the given address, inserting a jump to the specified label in the case of an access violation. Using these macros, the select() code can now look like:
每个宏都会开启一个新的代码块,并对给定地址进行推测性保护,在访问违规的情况下跳转到指定标签。使用这些宏后,select() 代码现在可以写作如下:
if (from) {
scoped_user_read_access(from, Efault) {
unsafe_get_user(to->p, &from->p, Efault);
unsafe_get_user(to->size, &from->size, Efault);
}
}
Efault:
return -EFAULT;The end result is clearly simpler and less prone to the sorts of mistakes that developers are likely to make. The need for explicit cleanup code, in particular, has been completely removed.
最终结果显然更简单,也不容易出现开发者可能犯的错误。特别是,对显式清理代码的需求已被完全消除。
This work is in its third revision; aside from some relatively minor comments, it would appear to have reached general approval. It seems to be a likely candidate for the 6.19 merge window. This work may affect a relatively obscure corner of the kernel that few developers will see directly, but it is a good example of the ongoing effort to make kernel development a bit less error prone. Moving away from C is not in the cards for a long time, so the next best thing is to make working in C safer.
这项工作已进入第三次修订;除了一些相对小的评论外,似乎已获得普遍认可。它很可能成为 6.19 合并窗口的候选。这项工作可能影响内核中一个相对不显眼的角落,很少有开发者会直接看到,但它是不断努力使内核开发更安全、更少出错的一个很好的例子。短期内不会放弃 C 语言,因此下一步最好的办法就是让在 C 语言中工作更安全。


















暂无评论内容