
本文主要为了探究pytorch-lightning 的单精度训练模式是否真的能节省显存。
我们第一搭建一个简单的网络,保证参数量足够多,才能有明显的对比。
网络:
block = lambda f1, f2: torch.nn.Sequential(
torch.nn.Conv2d(f1, f2, kernel_size=3, padding=1),
torch.nn.ReLU(),
torch.nn.BatchNorm2d(f2),
)
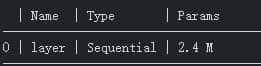
self.layer = torch.nn.Sequential(block(4, 16), *[block(16, 16) for _ in range(1000)])其参数量为:
接着构造一个随机数据集:
train_data = torch.utils.data.DataLoader(RandomDataset([4, 84, 84], 256), num_workers=12)
val_data = torch.utils.data.DataLoader(RandomDataset([4, 84, 84], 256), num_workers=12)
test_data = torch.utils.data.DataLoader(RandomDataset([4, 84, 84], 256), num_workers=12)在双精度训练下,需要将 Trainer 的 precision flag 设置成 32(这也是默认的设置)
训练所需显存为:

在单精度训练下,需要将 Trainer 的 precision flag 设置成16
训练所需显存为:

可以直观的看到,单精度训练大致只占用一半的显存。
© 版权声明
文章版权归作者所有,未经允许请勿转载。如内容涉嫌侵权,请在本页底部进入<联系我们>进行举报投诉!
THE END
















暂无评论内容