
1、超节点,SuperPod,是英伟达最早提出的概念,为了解决构建更大规模GPU集群时遇到的Scale Up和Scale Out问题。
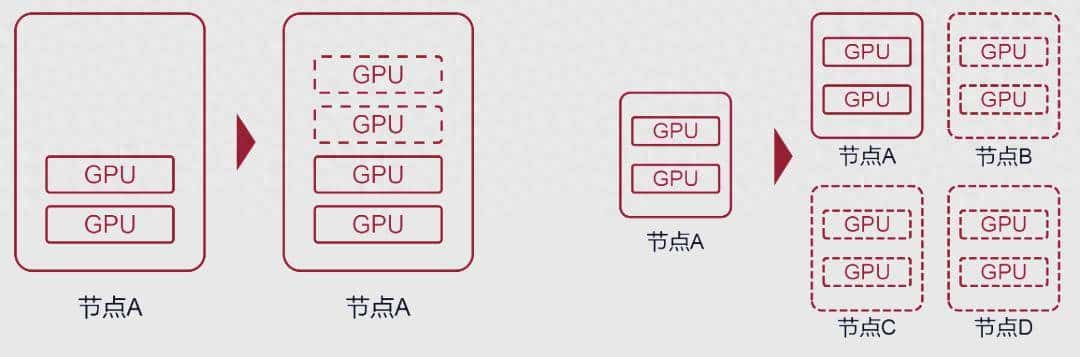
2、Scale Up是指增加单台服务器(节点)里的GPU数量,但受限于空间、功耗和散热,一般最多配8卡、16卡GPU,内部互联以PCIe协议为主,数据传输速率慢、时延高。
3、Scale Out是指增加服务器(节点)的数量,并通过网络将多台服务器(节点)连接起来,连接方式目前主要采用Infiniband(IB)和RoCEv2两种技术,相比传统以太网速率更高、时延更低、负载均衡能力更强。IB是英伟达的私有技术,性能强,价格贵;RoCEv2是开放标准,是以太网融合RDMA的产物,性价比高。
4、2014年,英伟达为了解决单台服务器(节点)Scale Up的问题,推出了私有的NVLINK协议,互联速度远高于PCIe,时延也低许多。
5、2022年,英伟达又将NVSwitch芯片拉出来做成了NVLINK交换机,用于连接服务器(节点)之间的GPU设备,也就是说节点已不再仅限于单台服务器,而是可以由多台服务器和网络设备共同组成,形成一个HBD(High Bandwidth Domain)超带宽域,英伟达将这种以超大带宽互联的Scale Up系统,称为超节点。
6、2024年3月英伟达发布的NVL72,将36个Grace CPU和72个Blackwell GPU集成到一个液冷机柜中,即是超节点典型代表,而25年上半年华为推出的Cloudmatrix384则是国产典范。
7、基于Scale Up的超节点是一个高度集成的集群系统,在带宽、时延、成本等方面相比Scale Out具备显著优势,并且超节点内Scale Up的GPU越多,Scale Out的组网就越简单,部署和运维也会更便捷。
8、AI训练时,涉及TP(张量并行)、 EP(专家并行)、PP(流水线并行)和DP(数据并行)多种并行计算方式。PP和DP的通信量较小,一般Scale Out即可搞定;而TP和EP的通信量大,需要由Scale Up即在超节点内部通过内部高速总线互联来支撑并行计算任务,加速GPU之间的参数交换、数据同步和内存读取,从而大幅缩短AI训练周期。
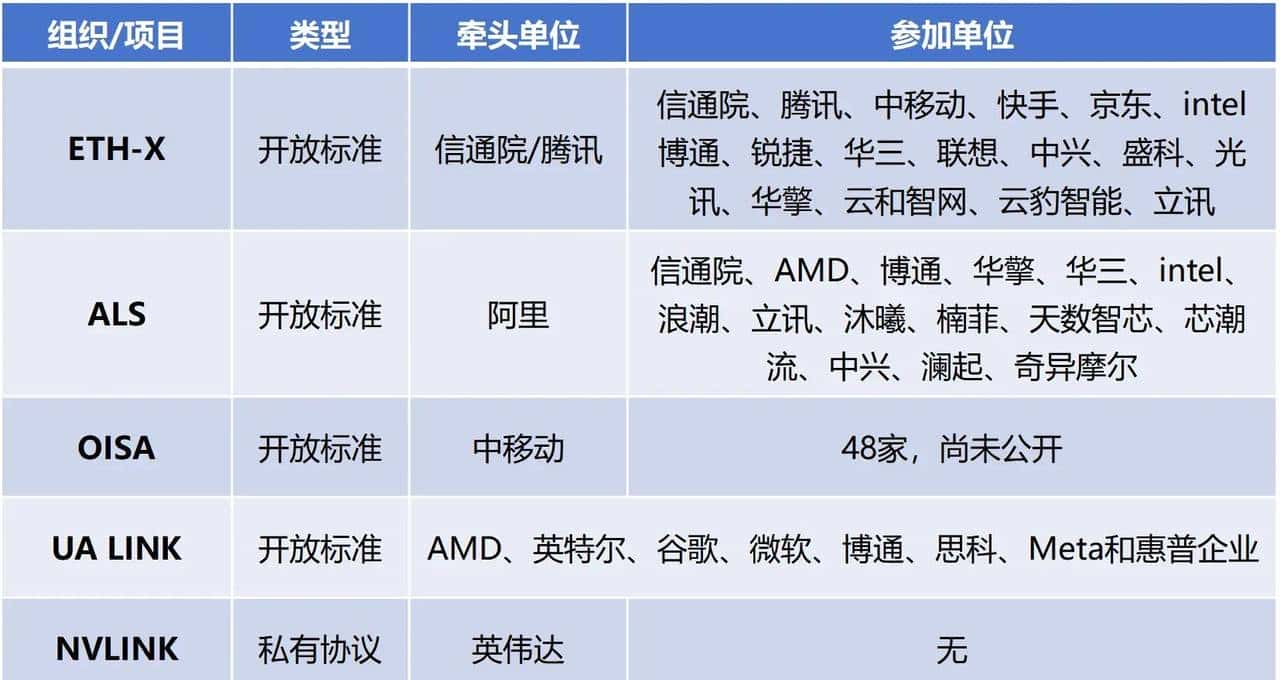
9、目前超节点方案除了以英伟达和华为为代表的私有标准外,还有一众基于以太网技术的开放标准。
#分享对AI的见解#
















- 最新
- 最热
只看作者