
在上篇文章中,讲到了文本 text-embedding 相关模型的原理,在RAG 中选择具体模型需要思考的相关因素等,这篇文章进入到RAG 的下一个阶段——ReRank 重排序;严格来讲,我们漏掉了embedding 向量数据库选型,在向量数据库选型这块,一般需要思考元数据过滤、分布式部署、高性能检索等问题,在这里不做过多阐述,本篇文章着重讲解检索之后的重排. 主要聚焦如下几个问题,为什么要ReRank?ReRank model 型有哪些?ReRank 模型原理介绍。
1.为什么要ReRank
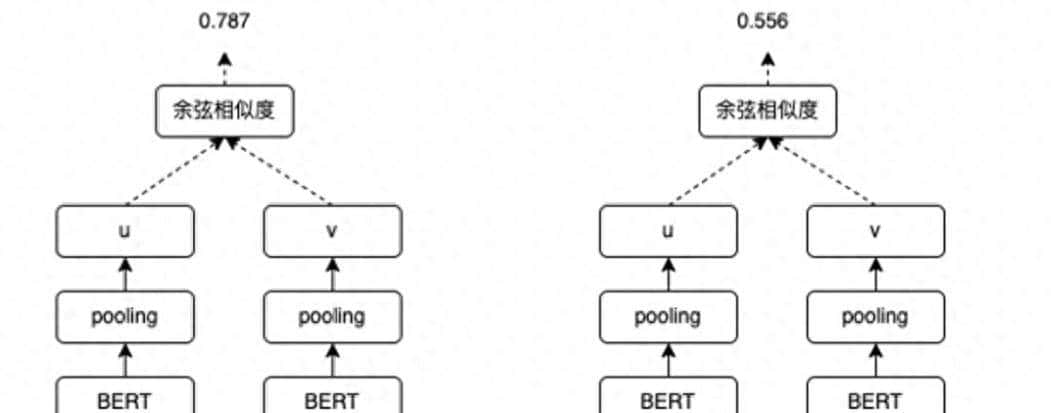
为什么需要ReRank
上面例子可以看到,由于自然语言的复杂性,基于前面text-embedding 得到的embedding 向量,可能并不是问题Query 的答案;虽然高度类似但是却和Query 不相关;即某种程度上,类似性不等于相关性。所以这时候需要一个ReRank 模型,将召回的低质量内容给过滤掉,给正确的答案腾挪空间;实际如果召回200个doc,经过ReRank 可能只选择10个左右的doc输入大模型;一些低质量模型被过滤掉,高相关性Doc 排名提升,更容易得到准确答案。
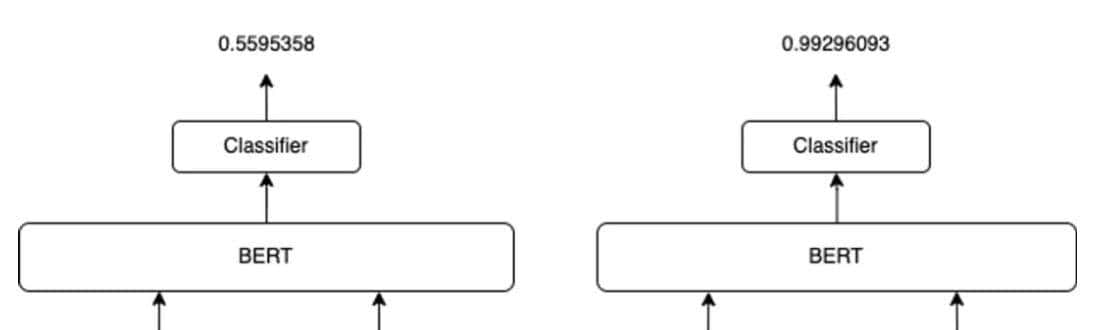
Cross-Encoder ReRank
2.ReRank 模型
国内最火的ReRank 模型有BAAI/bge-reranker-large 、BAAI/bge-reranker-v2-m3、
BAAI/bge-reranker-v2-gemma ,这三款模型底层分别基于xlm-roberta,bge-m3,gemma-2 构建,并且这些模型都是开源,可以实现私有化部署。
国外ReRank 模型有cohere-rerank-v3.5,jina-reranker-v2-base 等,但只提供API 调用。在思考免费、私有化部署、性能等因素,bge-reranker-large 是一个较好的选择。
3.ReRank model 的相关原理
一般 ReRank model 的架构和前篇文章介绍的embedding 模型均采用类似 bert 结构,并且往往是在embedding 模型的基础上再做一些微调。Reranker model 使用问题和答案作为输入,直接输出类似度而不是embedding。重排序器是基于交叉熵损失进行微调优化的。数据格式和Embedding 一样,query、pos、neg, 使用Cross Encoder 结构进行训练。
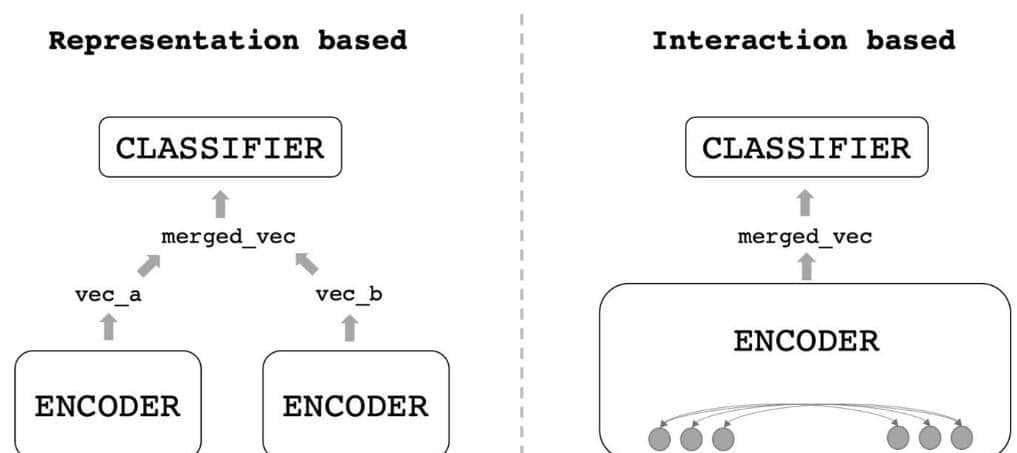
左侧 bi-encoder,右侧 cross-encoder
即将query sep pos 输入模型希望学习输出相关性为1.0,query sep neg 输入到cross-encoder 相关性为0。
这里思考一个问题,往往排序模型训练过程中,损失函数会有Pointwise、Pairwise、Listwise 等,这里排序模型为什么会转化为 Cross-Entropy Loss?这里搬运工总结如下两点缘由:
1.Rerank模型的核心任务是对检索到的候选文档进行相关性二分类(相关/不相关),而非直接生成排序分数。
2.简化训练样本的构造,pairwise,listwise 等损失函数需要构造样本对,序列样本构建排序等级
3.RAG系统中,Rerank模型一般位于检索(Retrieval)与生成(Generation)之间,主要目标是快速过滤低质量文档,找出相关性高的文档,将低质量文档快速过滤,而不过分追求排序顺序。
关于RAG 系统中ReRank 模型的分享就到这里,关注AIGC-LANDING,给您带来AI干活分享。















- 最新
- 最热
只看作者