
大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队!
我将持续分享成体系的知识以及我自身的转码经验、面试经验、架构技术分享、AI技术分享等!
愿景是带领更多人完成破局、打破信息差!我自身知道走到现在是如何艰难,因此让以后的人少走弯路!
无论你是统本CS专业出身、专科出身、还是我和一样职高毕业等。都可以跟着我学习,一起成长!一起涨工资挣钱!
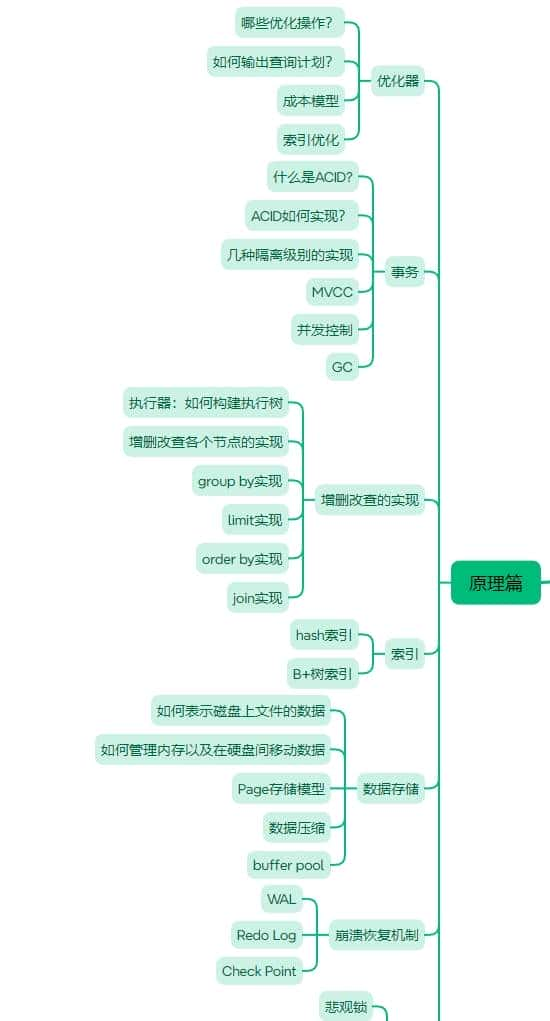
MySQL零基础教程
本教程为零基础教程,零基础小白也可以直接学习。
基础篇和应用篇已经更新完成。
接下来是原理篇,原理篇的内容大致如下图所示。
零基础MySQL教程原理篇之缓冲池原理及实现
MySQL中的
buffer pool(缓冲池)
InnoDB存储引擎
它加速了数据库的运行速度,是数据库和磁盘之间的一个中间层。如果没有缓冲池,那么所有的数据库操作都需要进行磁盘IO,有了缓冲池,就不需要频繁的IO操作了。
缓冲池重点在于两个部分
时间管理空间管理
时间管理
将数据写入磁盘的何处目标是经常被一起使用的pages放在磁盘中也是一起的地方。
空间管理
何时将pages读入内存,何时将pages写入磁盘目标是最小化的解决必须从磁盘读取数据这个事
同样的一个
内存块
page(页)
frame(帧)
一个frame其实就是一页数据。只不过这个数据是在
缓冲池
到这里有个问题了,那就是缓冲池里面都是一堆数据,可是MySQL怎么知道缓冲池的哪个frame里面有数据,哪个没有呢?frame里面的数据对应的是具体哪个page的数据呢?
因此,就需要另外一个组件了,叫做
page table
hash map
页数据
缓冲池
page table
page id
frame
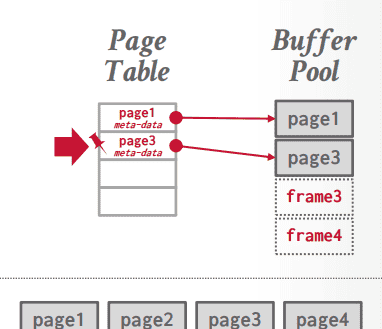
我们还需要记录一些元数据,这些数据也有着重要的作用:
dirty flag: 记录是否被修改过,也就是常说的”脏数据标记”引用计数器: 记录有多少线程在使用这个数据访问追踪信息
缓冲池和mmap
如果你学过
操作系统
没错,就是
mmap
从下面几个点来看:
事务安全:如果使用mmap,操作系统完全控制page的写入,刷新,有可能在一个事务没有完成的时候有些数据就已经写入磁盘了。IO停顿:MySQL不知道哪些page在内存中,当读取不在内存中的时候触发
page fault
SIGBUS
性能优化有两种考虑策略,分别是
全局策略
局部策略
全局策略
针对所有的查询或者事务的策略
局部策略
针对单个查询或者事务的策略可以对单个优化,虽然对全局可能不好
淘汰策略
既然MySQL自己实现了一个缓冲池作为磁盘数据的
缓存
淘汰策略有几种算法
LRU:著名的LRU算法,这里不过多介绍了。Clock:Linux使用的,把所有的page放成一个圈,每个page有一个标志位,如果为0表示没有被使用过,1被使用过,淘汰的时候淘汰0的,再把1改成0.LRU-K:记录使用的次数k,达到次数才放到缓存里面,淘汰的时候比对两次的时间间隔,间隔长的认为是最近最少使用。这个基本上是MySQL使用的一个淘汰算法。属于LRU算法的变种。PRIORITY HINTS(优先级提示):优先级提示是一种淘汰策略,用于根据缓存项的优先级或重要性做出更智能的决策。
LRU-K
LRU-K
LRU(最近最少使用)
核心理念:
跟踪每个缓存项的最近K次访问次数使用最近的第k个访问时间进行驱逐决策K=1降为标准LRU
可以这么理解,LRU就是LRU-1算法。
LRU-K算法的实现比LRU更加复杂,不能单纯考虑最近一次,而是要考虑最近K次。
与LRU相比的优点:
更好的频率检测:
区分“流行”和“暂时流行”的物品减少顺序扫描造成的缓存污染
自适应行为:
不同的K值优化不同的访问模式K=2通常提供良好的平衡
扫描阻力:
大规模的连续扫描不会永久地删除流行的项目项目需要多次访问才能确定其重要性
LRU-K在频繁随机访问和偶尔顺序扫描的环境中特别有效。
在LRU-K中,首先需要定义一个LRUK的节点,这个节点存储了frame的访问次数,是否可以淘汰等信息,还需要存储所有LRUK节点的一个map,map的key是frame id,这样可以快速获取这个frame的LRUK节点信息。而不需要循环查找。
接下来可以通过两个队列来实现算法,第一个队列存储的是
未满足K次的
满足K次
记录访问的大致代码如下:
// 访问次数决定队列分配
if (record_size == 1) {
lru_node_queue_.push_back(node.GetId()); // 首次访问 -> LRU队列
} else if (record_size == k_) {
lru_node_queue_.remove(node.GetId()); // 达到k次 -> 移到LRU-K队列
lru_k_queue_.push_back(node.GetId());
} else if (record_size > k_) {
lru_k_queue_.remove(node.GetId()); // k次后 -> 更新LRU-K队列位置
lru_k_queue_.push_back(node.GetId());
}
当缓冲池满了以后,我们需要淘汰一个page,给另外一个page让出空间。
这里会优先淘汰未满足K次的这些page,因此,直接从第一个LRU队列中进行LRU淘汰即可。
auto lru_it = std::find_if(lru_node_queue_.begin(), lru_node_queue_.end(),
[this](const auto &queue_frame_id) {
return node_store_.at(queue_frame_id).IsEvict();
});
如果大家都满足K次,就淘汰这些访问次数达到K次的page
auto lru_k_it = std::find_if(lru_k_queue_.begin(), lru_k_queue_.end(),
[this](const auto &queue_frame_id) {
return node_store_.at(queue_frame_id).IsEvict();
});
如果当有page更新的话,那么要记录这个page有更新,当淘汰的时候,需要将这个page写入磁盘中。
mysql 近似 LRU-k
MySQL使用的淘汰算法是一个
近似LRU-K
相当于K=2。有一个LRU List,但是有两个指针,分别表示
old list
young list
old list
young list

当访问 page1 的时候,需要淘汰掉
old list
old list

当再次访问 page1 的时候,将page1 插入
young list
young list
old list

PRIORITY HINTS(优先级提示)
比如B+树的根节点具有最高的优先级,所以一直放在内存中。
核心概念:
不像简单的LRU只考虑访问的近因性优先级提示包含关于项目重要性的额外元数据允许更复杂的驱逐策略
常见的实现方法:
基于优先级的LRU:
物品有优先级(高,中,低)在每个优先级中,使用LRU从最低优先级优先驱逐
加权LRU:
每个项目都有优先级权重将最近性与优先级分数结合起来驱逐最低综合分数的项目
多队列系统:
为不同的优先级分隔队列后台进程管理每个队列的回收高优先级的项目留存时间更长
对于缓冲池的一些优化
多缓冲池
通过使用多个缓冲池可以根据不同的table放入不同的缓冲池进行不同的优化。也可以通过其他的策略使用多个缓冲池由于有多个缓冲池,减少了锁争抢和锁等待的时间。mysql中通过hash确定数据是否在缓冲池,然后通过取余确定在哪个缓冲池
预取数据
顺序扫描的时候预先把后面的page取到缓冲池中。这一步mmap也可以实现索引扫描的时候预先把索引中需要用到的后面的page取到缓冲池中。这一步mmap实现不了,这也是数据库自己实现缓冲池的优势。
扫描共享
这个优化MySQL并没有实现。
共享扫描到的page内容如果查询1需要扫描page1,page2,page3,page4的内容并且已经扫描到了page3,这个时候page1已经扫描完了被从缓冲池中丢弃了这时候有一个查询2也需要扫描所有的pages,如果从page1开始扫描,就会把page1再次读入缓冲池,但是这样是低效率的,所以可以先共享查询1的page数据,先扫描page3,然后page4,这时候查询1执行完毕,在回头扫描page1,page2。
buffer pool bypass
单独开辟一个本地内存区域来用,而不是使用buffer pool可以避免操作page table带来的开销(latch锁住的开销)可以避免污染buffer pool适合数据量不大的情况mysql5.7不支持
os page cache
操作系统的文件缓存,当使用fopen,fread,fwrite的时候会先从操作系统缓存中读取文件内容。只有postgresql使用了这个。通过 direct IO可以不使用这个使用它会导致有两个缓存,buffer pool 和 os page cache。不好控制。fsync如果失败以后再次调用也不会生效,因为它会将dirty设置为false
写入磁盘策略
两种写出方案需要做权衡,取舍
如果写出dirty flag的数据然后读取新数据,就会产生2次IO。通常会有一个定时任务线程去将dirty flag的数据写入磁盘,写入之前必须要先将操作日志写入磁盘。如果直接读取新数据就只有1次IO,但是这样有可能把下次会用到的数据丢弃。
MySQL性能优化
buffer pool
建议设置内存的50%以上给buffer pool,设置的越多,就越像内存数据库
淘汰算法类似
LRU-K
默认情况下,查询读取的页面会立即移动到新的子列表中,这意味着它们在缓冲池中停留的时间更长。例如,为mysqldump操作或不带WHERE子句的SELECT语句执行的表扫描可以将大量数据带入缓冲池并驱逐等量的旧数据,即使新数据永远不会再次使用。
类似地,由预读后台线程加载且仅访问过一次的页将被移动到新列表的头部。这些情况可能会将经常使用的页面推到旧的子列表中,在那里它们会被驱逐。
在具有足够内存的64位系统上,可以将缓冲池拆分为多个部分,以最小化并发操作之间对内存结构的争用。
您可以控制如何以及何时执行预读请求,以便在预期即将需要页时将页异步预取到缓冲池中。
您可以控制何时发生后台刷新,以及是否根据工作负载动态调整刷新速率。
您可以配置InnoDB如何保留当前缓冲池状态,以避免服务器重启后的漫长预热期。
可以使用
SHOW ENGINE INNODB STATUS
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 2198863872
Dictionary memory allocated 776332
Buffer pool size 131072
Free buffers 124908
Database pages 5720
Old database pages 2071
Modified db pages 910
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 4, not young 0
0.10 youngs/s, 0.00 non-youngs/s
Pages read 197, created 5523, written 5060
0.00 reads/s, 190.89 creates/s, 244.94 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not
0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read
ahead 0.00/s
LRU len: 5720, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
change buffer
change buffer
与聚集索引不同,辅助索引通常是非唯一的,插入辅助索引的顺序相对随机。同样,删除和更新可能会影响索引树中不相邻的二级索引页。当其他操作将受影响的页读入缓冲池时,在以后合并缓存的更改可以避免将辅助索引页从磁盘读入缓冲池所需的大量随机访问I/O。
在系统大部分空闲时或缓慢关机期间运行的清除操作会定期将更新的索引页写入磁盘。与立即将每个值写入磁盘相比,清除操作可以更高效地写入一系列索引值的磁盘块。
当有许多受影响的行和许多要更新的辅助索引时,更改缓冲区合并可能需要几个小时。在此期间,磁盘I/O会增加,这可能会导致磁盘绑定查询的速度显著降低。更改缓冲区合并也可能在事务提交后继续发生,甚至在服务器关闭并重新启动后也会发生
在内存中,更改缓冲区占用缓冲池的一部分。在磁盘上,更改缓冲区是系统缓存的一部分,当数据库服务器关闭时,索引更改将在其中进行缓冲。
如果索引包含降序索引列,或者如果主键包含降序索引列,则不支持辅助索引的更改缓冲。
当对表执行INSERT, UPDATE和DELETE操作时,索引列的值(特别是辅助键的值)通常是无序的,需要大量的I/O来更新辅助索引。当相关页不在缓冲池中时,更改缓冲区将缓存对辅助索引条目的更改,从而避免了昂贵的I/O操作,因为它不会立即从磁盘阅读页。当页加载到缓冲池中时,将合并缓冲的更改,更新后的页稍后将刷新到磁盘。InnoDB主线程在服务器接近空闲时和缓慢关闭期间合并缓冲的更改。
由于更改缓冲可以减少磁盘读取和写入,因此它对于I/O受限的工作负载最有价值;例如,具有大量DML操作(如批量插入)的应用程序将受益于更改缓冲。
但是,更改缓冲区占用了缓冲池的一部分,从而减少了可用于缓存数据页的内存。如果工作集几乎适合缓冲池,或者表的辅助索引相对较少,则禁用更改缓冲可能很有用。如果工作数据集完全适合缓冲池,则更改缓冲不会产生额外的开销,因为它只应用于不在缓冲池中的页。
innodb_change_buffering
innodb_change_buffering
innodb_change_buffer_max_size
考虑在具有大量插入、更新和删除活动的MySQL服务器上增加
innodb_change_buffer_max_size
如果MySQL服务器上的静态数据用于报告,或者如果更改缓冲区占用了太多与缓冲池共享的内存空间,导致页面比预期更快地老化,请考虑减少
innodb_change_buffer_max_size
使用具有代表性的工作负载测试不同的设置以确定最佳配置。innodb_change_buffer_max_size变量是动态的,允许在不重启服务器的情况下修改设置。
要查看监视器数据,请发出
SHOW ENGINE INNODB STATUS
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 4425293, used cells 32, node heap has 1 buffer(s)
13577.57 hash searches/s, 202.47 non-hash searches/s
双写缓冲区
双写缓冲区
InnoDB
doublewrite缓冲区
虽然数据被写入两次,但双写缓冲区不需要两倍的I/O开销或两倍的I/O操作。数据以一个大的
顺序块
fsync()
双写缓冲存储区位于双写文件中。
为双写缓冲区配置提供了以下变量:
innodb_doublewrite
innodb_doublewrite
DETECT_AND_RECOVER设置与ON设置相同。通过此设置,双写缓冲区将完全启用,数据库页内容将写入双写缓冲区,在恢复期间将访问该缓冲区以修复不完整的页写入。使用DETECT_ONLY设置时,仅将元数据写入双写缓冲区。数据库页内容不写入双写缓冲区,恢复不使用双写缓冲区来修复不完整的页写入。此轻量级设置仅用于检测不完整的页写入。
innodb_doublewrite_dir
innodb_doublewrite_files
innodb_doublewrite_pages
结论
本次分享了MySQL中重要的组件
buffer pool
并根据这些内容提出了一些性能优化方案。明白了缓冲池的原理及作用以后,根据这些优化方案可以更好的进行数据库的性能优化。
但是,buffer pool也不是越大越好,根据需要来调整,调整以后可以进行一些测试,以测试出最适合自己业务的大小。


















暂无评论内容